01. Cookie
1.1 会话技术
1.1.1 会话技术简介
- 一般来说,一个网站或者一个应用在后台都会有一个服务器,而这台服务器每天需要承载则大量用户(客户端)的正常运行。
- 此时,客户端和服务器就形成了一种多对一的关系(一个客户端对应一台服务器,一台服务器对应多个客户端)。那么服务器是如何区分谁是谁的呢?
- 以用户登录为例,用户在输入用户名和密码之后,这些登录信息会被送到后台服务器进行验证。
- 若验证通过(一般来说就是用户名和密码正确)后,服务器会给客户端返回一个唯一标识(Cookie),这个唯一标识就类似于人的身份证。
- 此时客户端这边已经登录成功了,并且在之后的操作中,客户端向服务器发送的请求一般都会带上这个唯一标识,这样服务器就知道谁是谁了。
- 这也是为什么有些好一点网站登陆过一次后再打开不需要重复登陆的原因。
- 会话技术的重要性:
- 客户端和服务器的关系就是请求和响应的关系。比如客户端发送登录请求,服务器验证响应完成后,客户端和服务器之间就没关系了。
- 此时当客户端再发起一次请求,服务器会把它当成一个全新的客户端处理。
- 此时若没有这个Cookie,客户端在登陆完成后给服务器发请求,服务器依旧不知道这个客户端是谁,再登录一遍。那这刚登录完又要登录,这不明显BUG嘛。
此外,HTTP是一种无状态/无记忆的协议,因此需要会话技术来记录状态。
1.1.2 三种会话技术介绍
会话技术共有Cookie、Session、Token三种。
- Cookie:浏览器专用,数据都存储再浏览器中。
- Session:浏览器专用,核心数据会存储在服务器中,服务器数据的唯一标识存储在Cookie中。
- Cookie的数据都存储在浏览器中,有人认为这样不安全,因此就出现了Session这种会话技术。
- Session是依赖于Cookie的。还是以1.1.1中的登录例子来讲,由于HTTP是没有记忆的,若数据都存在服务器中,那么用户登录成功了后续还是要登录的。因此服务器在用户登录成功时必须给浏览器一个Cookie,否则浏览器根本不认识浏览器是谁。因此说Session依赖于Cookie,Seesion没法单独工作。
- Token:可以认为是一种自定义的Session。
- 因为客户端肯定不止浏览器一种,还有App、小程序等一大堆,那这种就没法用Cookie和Seesion了,此时Token就以一种替代品的角色出现了。
- Token的数据存储策略由开发者设计,比如手机应用开发中Token一般会存储在手机的数据库中,Windows应用的Token则可能存在一个Windows的文件中。
- Token可以看作是一种自定义的Session,在用户登录成功后会发送用户唯一标识给客户端,由客户端自行保存。在使用时客户端给服务器发送的请求必须带上Token,否则服务器根本不知道客户端是谁。
由于现在是大前端的时代,所有很多业务场景一般都在浏览器上,因此Cookie/Session的比重远远大于Token。
1.1.3 会话技术的过期时间
从安全角度考虑,会话技术一般都会有过期时间。
- 过期时间即指一个Cookie或者一个Token不是一直都能用的。
比如一些安全性高的网站,你五分钟没有操作,那么Cookie就过期了,此时网站就会要求你重新登陆。
1.2 使用Cookie实现自动登录
1.2.1 获取登录后的Cookie
以B站为例, 我们可以用Selenium程序打开B站,然后手动登录,接着再用程序把Cookie存下来。
- 构造浏览器并打开B站。 ```python from selenium import webdriver
browser = webdriver.Chrome() browser.get(“https://www.bilibili.com/“)
- 接着手动登录B站的账号。- 登陆完成后,使用`浏览器.get_cookies()`函数获取当前页面的Cookie。```pythoncookies = browser.get_cookies()
- 最后,把获取到的Cookie保存到本地。 ```python import json
with open(‘cookies.txt’, ‘w’, encoding=’utf-8’) as file: file.write(json.dumps(cookies))
<a name="Fza1A"></a>#### 1.2.2 使用Cookie实现登录- 1.2.1中已经获取到了登陆后的Cookie,那么此时就可以用获取到的Cookie数据实现自动化登录了。- 首先第一步,还是打开B站的首页。```pythonfrom selenium import webdriverbrowser = webdriver.Chrome()browser.get("https://www.bilibili.com/")
- 接着,把1.2.1中保存到cookies.txt文件中的Cookie数据读取出来。 ```python import json
with open(‘cookies.txt’, ‘r’, encoding=’utf-8’) as file: content = file.read()
cookies = json.loads(content)
- 然后使用`浏览器.add_cookie(cookie)`函数将Cookie添加注入到浏览器中。- 注意:1.2.1中获取到的cookies是个列表,里面由多条Cookie。- Selenium目前只有`add_cookie()`函数,一次只能注入一条Cookie。因此需要用一个循环一条一条的注入。- 在注入过程中可能会因此有些Cookie无法注入而报错,但是极个别Cookie不会影响最后的结果,因此可以用`try-except`简单捕获处理即可。```pythonfor cookie in cookies:try:browser.add_cookie(cookie)except Exception as e:print(cookie)
最后,刷新浏览器。发现已经登陆成功了。
browser.refresh()
1.2.3 登录失败的原因
若使用Cookie无法实现自动登录,那么可能有如下一些原因:
- 获取Cookie的时机不对,导致获取到的Cookie并不是登陆后的,导致登陆失败。
-
1.3 自动刷粉
现在很多“买粉丝”的实现方式实际上就是卖家那边有很多Cookie,然后用程序循环登录这些Cookie后面的ID,然后点了个关注而已。
- 示例:现有一个B站UP主的首页为:https://space.bilibili.com/146668655?spm_id_from=333.337.0.0,用Cookie技术为这个UP主点个关注。 ```python import json
from selenium import webdriver from selenium.webdriver.common.by import By
打开B站。
browser = webdriver.Chrome() browser.get(“https://www.bilibili.com/“)
读取Cookie。
with open(‘cookies.txt’, ‘r’, encoding=’utf-8’) as file: content = file.read() cookies = json.loads(content)
注入Cookie。
for cookie in cookies: try: browser.add_cookie(cookie) except Exception as e: print(cookie)
访问目标UP主的首页(访问后就是已登录状态了)。
browser.get(“https://space.bilibili.com/146668655?spm_id_from=333.337.0.0“) browser.refresh()
点击关注按钮,实现关注操作。
attention_btn = browser.find_element(by=By.CLASS_NAME, value=”h-follow”) attention_btn.click()
- 一般来说,卖粉丝的无非也就是有很多个Cookie,然后遍历一下完成以上操作而已。- 扩展:买的Cookie一般就是一个txt的文本文件,文件里一行就是一个Cookie。然后`for cookie in file.readlines()`即可遍历得到每一个Cookie。<a name="NBNVq"></a>## 02. JSON与网络接口<a name="wJ3ZQ"></a>### 2.1 网络接口<a name="quxuo"></a>#### 2.1.1 API介绍- 应用程序编程接口(Application Programming Interface,API),又称为应用编程接口。- 在程序中调用一个本地的函数,那是调用本地的应用程序接口。- 在程序中调用一个网络地址,那么调用的是网络接口。- 每一个可以获取资源的网络地址都是一个网络接口。- 网络接口的本质是请求哪一个地址、给定什么样的参数,可以获取哪些数据。- 网络接口返回的数据一般来说都是JSON数据。<a name="fAkr5"></a>#### 2.1.1 面向接口编程- 到目前已经接触过的编程范式有:- 面向过程编程:核心是方法、模块、函数。- 面向对象编程:核心是对象,有封装、继承、多态三大特性。- 除此之外,网络中最常用的还有一种面向接口编程。- 所谓的面向接口编程:- 比如现在想要给一个无序列表排序,使其变成一个有序列表,那么用面向接口变成就可以创建一个`Sort`模块,模块中有一个`sort_list()`方法,这个方法需要传入一个无序列表,它会返回这个列表元素排序后对应的有序列表。- 那么在使用`Sort.sort_list()`时,只需要直接调用即可,至于这个接口里使用的是冒泡排序、还是选择排序、还是希尔排序、……,调用者其实根本不用关心。- 总的来说:面向接口编程需要关注的只有这个接口在哪、这个接口有什么功能、它的输入/输出是什么;至于功能是怎么实现的,不用管。- 面向接口编程的核心:输入、输出、调用位置。<a name="QlTpj"></a>### 2.2 网络接口数据<a name="dUzCj"></a>#### 2.2.1 获取网络接口数据- 示例:获取[https://www.xinpianchang.com/a11954490](https://www.xinpianchang.com/a11954490)该网站的所有评论。- 首先,这些评论一般都是动态加载的,直接从网页中找是肯定找不到的。- 如可以先保存这个网页的HTML代码。```pythonimport requestsresp = requests.get("https://www.xinpianchang.com/a11954490")with open('page.html', 'w', encoding='utf-8') as file:file.write(resp.text)
- 接着,随便找一条评论。
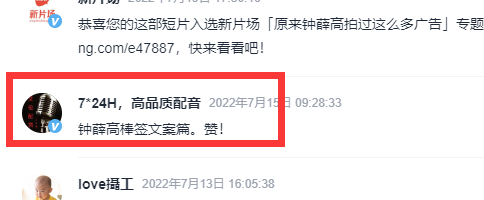
- 接着到page.html文件中去找这条评论,发现根本找不到。
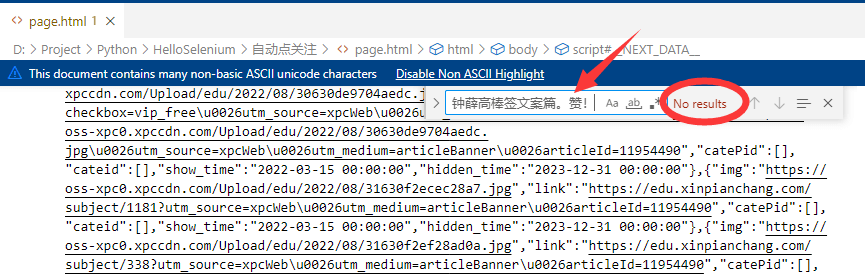
- 说明这些评论是通过网络接口动态加载到页面中的,而并不是直接存储在网页源代码中的。
- 因此为了顺利获取到这些评论,我们需要去找这些评论的网络接口。
- 可以先刷新这个界面,让所有资源都恢复到最初的模式,然后打开F12 >> Network >> Fetch/XHR,准备抓取动态数据。
- 接着,向下滑动这个页面,当新评论被加载进来后,可以发现Fetch/XHR中捕获到了这条数据。
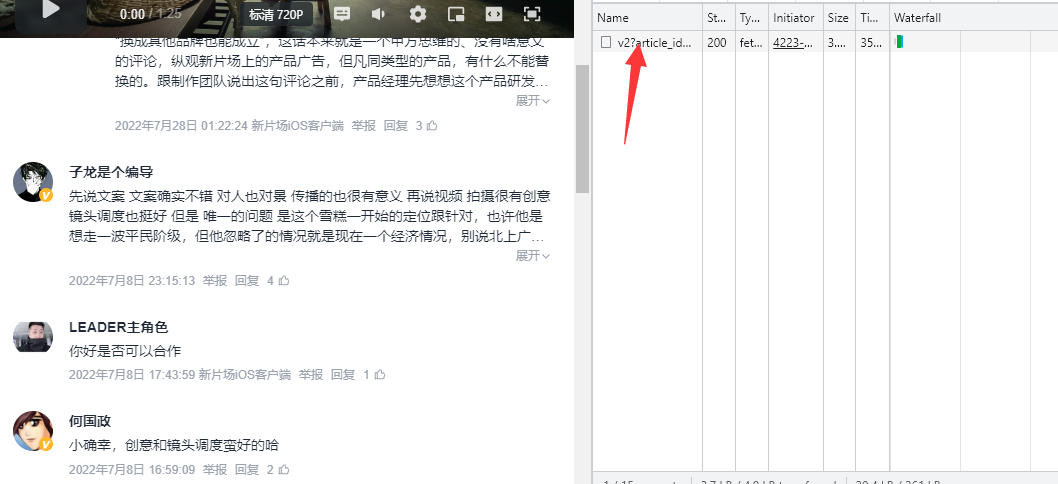
- 在请求头中可以找到请求的URL地址为:https://www.xinpianchang.com/api/xpc/comments/article/v2?article_id=11954490&page=2。
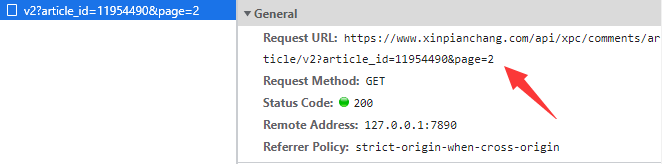
- 在浏览器中访问这个URL,即可获取到这个网络API返回的数据。(JSON格式的)

2.2.2 JSONView插件
- JSONView是一款非常实用的格式化和语法高亮JSON格式数据查看器jQuery插件,它是查看JSON数据的神器。
- 在线安装:
- 离线安装:JSONView-for-Chrome-master.zip
- 下载并解压JSONView-for-Chrome-master.zip文件。
- 打开Google Chrome浏览器,点击右上角菜单选项 >> 更多工具 >> 扩展程序。
- 打开开发者模式。然后点击“加载已解压的扩展程序”按钮,选中JSONView-for-Chrome-master中的WebContent目录,点击选择文件夹。
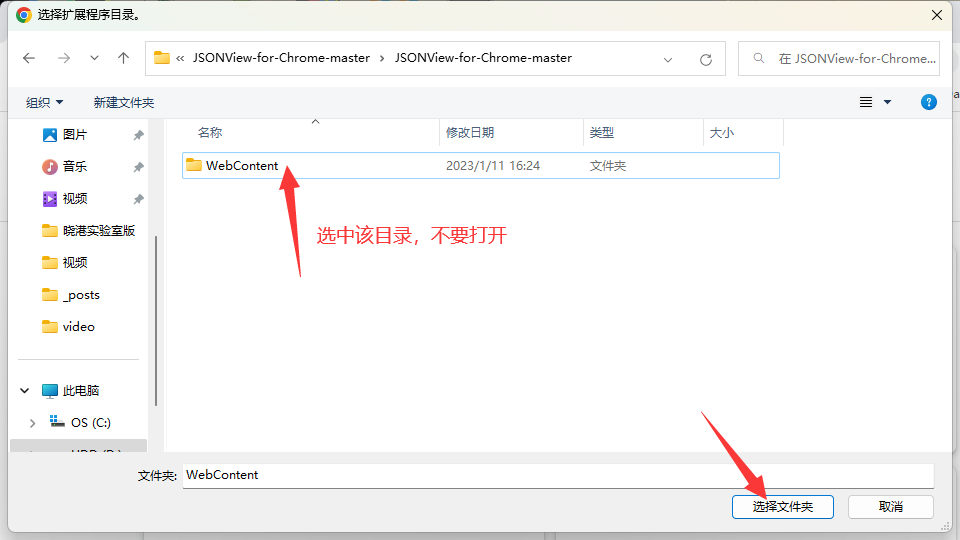
- 此时JSONView插件就安装成功了。
- 安装完成后,再次打开网络接口地址https://www.xinpianchang.com/api/xpc/comments/article/v2?article_id=11954490&page=2。即可发现该接口响应的JSON数据经过格式化处理了:

2.3 通过API获取所有评论
2.3.1 现有资源分析
- 当目前为止,已经获取到的资源有:
- 通过分析API地址我们可以发现,首先URL中有一个参数page=2,它代表的是第二页评论;有一个atricle_id=11954490,它代表的是视频的ID。
进入API地址,我们可以发现在data字段中有一个next_page_url字段,这个字段中存储的可能是下一页评论的API地址。
{"status": 0,"code": "_200","message": "OK","data": {"total": 143,"page_size": 12,"next_page_url": "/comments/article/v2?article_id=11954490&page=3",……}……}
2.3.2 获取所有评论页地址
所有评论页API地址分析:
- 通过观察可以很容易发现,next_page_url的值实际上是:
/comments/article/v2?article_id={movie_id}&page={page_no}。 - 然后电影的评论API地址可以通写为:
https://www.xinpianchang.com/api/xpc/next_page_url - 要获取所有的评论页,那么page_no肯定是从1开始的,所以电影的起始评论页面为:
https://www.xinpianchang.com/api/xpc/next_page_url/comments/article/v2?article_id={movie_id}&page=1。 - 至于page_no到什么时候结束,这个其实谁也不知道,理论上只要next_page_url有值(即部不为空),就可以一直获取下去。
- 通过观察可以很容易发现,next_page_url的值实际上是:
- 接着上述分析的逻辑,可以编码实现获取目标电影的所有API地址。 ```python import requests import json
movie_url = “https://www.xinpianchang.com/a11954490“
movie_id = movie_url[movie_url.rfind(“a”) + 1:] next_page_url = f”/comments/article/v2?article_id={movie_id}&page=1” # 起始页面page_no肯定为1
循环请求所有的评论页API地址,直到next_page_url的值为空。
while True:
# 请求并获取API的数据。api_url = f"https://www.xinpianchang.com/api/xpc/{next_page_url}"resp = requests.get(api_url)json_data = json.loads(resp.text)# 获取next_page_url的值。next_page_url = json_data['data']['next_page_url']print(next_page_url)# 若next_page_url的值为空,则不再继续请求下一页的数据,即跳出循环。if next_page_url == None:break
<a name="s0FWm"></a>#### 2.3.3 解析JSON获取评论信息- 一页的评论放在`json_data['data']['list']`中,是一个列表,可以遍历获取每一条评论的信息。- 一条评论的数据也是一个JSON,如下:```json{"id": 1540107,"resource_id": 11954490,"userid": 12597114,"content": "你好是否可以合作","addtime": 1657273439,"count_approve": 1,"referid": 0,"from": 7,"top_time": 0,"is_top": false,"ip_location": "","userInfo": {"id": 12597114,"url": "newstudios://app.xinpianchang.com/user/12597114","web_url": "https://www.xinpianchang.com/u12597114","username": "LEADER主角色","avatar": "https://cs.xinpianchang.com/user_center_xpc_line/user_avatar_12597114.jpg","about": "拍摄每次的主角光环","verify_description": "","sex": 1,"is_vmovier_migrate_user": false,"is_stock_creator": false,"is_edu_supplier": false,"vip_flag": 0,"count": {"count_followee": 0,"count_follower": 1,"count_collected": 0,"count_article_viewed": 0,"count_liked": 0,"count_article": 0,"count_popularity": 0},"is_administrator": false,"is_realname_auth": true,"author_type": 0,"location": {"country": {"id": "CN","name": "中国"},"province": {"id": "310000","name": "上海"},"city": null,"area": null},"addtime": 1641570667,"birthday": "19930318","user_groups": ["UC001"],"realnameStatus": 0,"realnameType": 0,"is_freelancer": false,"vip_status": 0},"is_approved": false}
- 因此,我们想要获取评论的评论者ID、评论者用户名、评论内容只需要从这个JSON中提取对于的数据即可。 ```python import requests import json
movie_url = “https://www.xinpianchang.com/a11954490“
movie_id = movie_url[movie_url.rfind(“a”) + 1:] next_page_url = f”/comments/article/v2?article_id={movie_id}&page=1” # 起始页面page_no肯定为1
循环请求所有的评论页API地址,直到next_page_url的值为空。
while True:
# 打印页标题。page_no = next_page_url[next_page_url.rfind("e") + 2:]print(f"\n\n正在获取第{page_no}页的数据。")# 请求并获取API的数据。api_url = f"https://www.xinpianchang.com/api/xpc/{next_page_url}"resp = requests.get(api_url)json_data = json.loads(resp.text)# 解析JSON,获取评论信息for comment_info in json_data['data']['list']:commentator_id = comment_info.get('id')commentator_username = comment_info.get('userInfo').get('username')content = comment_info.get('content')print(f'评论者ID:{commentator_id},评论者用户名:{commentator_username},评论内容:{content}')# 获取next_page_url的值。next_page_url = json_data['data']['next_page_url']# 若next_page_url的值为空,则不再继续请求下一页的数据,即跳出循环。if next_page_url == None:break
<a name="ad2jk"></a>## 03. POST请求<a name="KhAQO"></a>### 3.1 POST请求概述<a name="XK87W"></a>#### 3.1.1 POST请求的基本认识- 网络请求的方式有很多种,其中最常用的是GET请求(之前requests模块发送的所有请求都是GET请求),其次就是POST请求。- POST请求一般用于提交数据,因此POST请求基本都会加密。- 比如你要登录微博,就要在微博的登录页面中输入你自己的用户名、密码等信息,然后用POST请求提交给微博的服务器。- 假如微博的POST请求没有加密,那么你输入的用户名、秘密等私密信息在网络中就是明文传输的。- 此时,黑客只需要进行简单的抓包,就可以获取到你向微博服务器发送的POST请求,然后从中就可以很轻易的获取到你的用户名、密码等数据。- 总的来说,就是POST是客户端用于向服务器提交数据的,为了避免数据泄露,POST提交的数据需要进行加密。- 网络中的POST请求是极其难抓的,就是因为POST请求中的数据是被加密了的。<a name="mF8gZ"></a>#### 3.1.2 发送POST请求- 可以通过requests模块中的`post()`函数发送一个POST请求,`post()`函数有以下三个常用参数:- url:服务器地址/资源路径。- headers:请求头,以字典形式定义。- data:请求数据,以字典形式定义。- 除了请求数据的形参名是data外,其余与`get()`完全一致。<a name="EnZN9"></a>### 3.2 使用POST请求发送短信验证码- 借助平台:网易云信([https://netease.im/](https://netease.im/))- 说明:这里以新注册用户的角度编写教程文档,新注册用户有20条免费短信可以发送。<a name="CQCmd"></a>#### 3.2.1 网易云信应用创建(实验环境准备)- 在用户创建并登录完成后,进入网易云信的控制台界面([https://app.yunxin.163.com/overview](https://app.yunxin.163.com/overview))。- 点击应用旁边的创建按钮。- 然后简单填写一下表单,点击创建。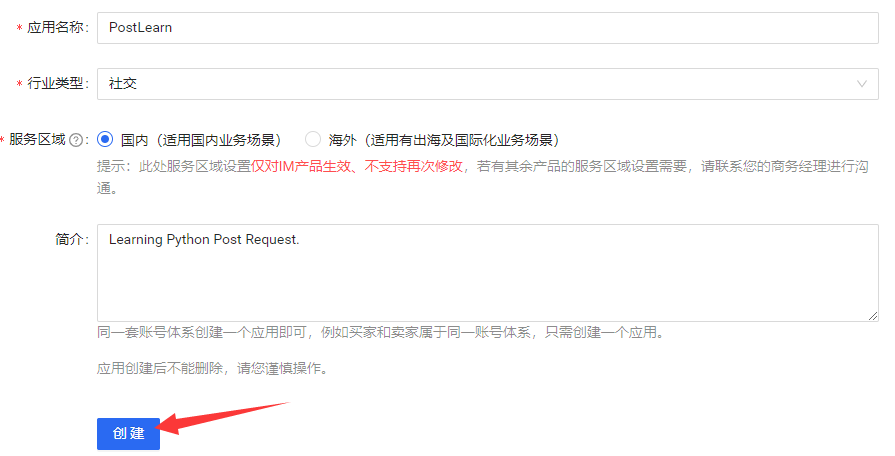- 此时,应用会默认为我们开通IM免费版。- IM(Instant Messaging),即时通讯。- 常见的IM软件如QQ、微信等。- 在这个实验中,我们还需要开通短信功能。但是新用户可以申请试用,会送20条的短信额度。<br />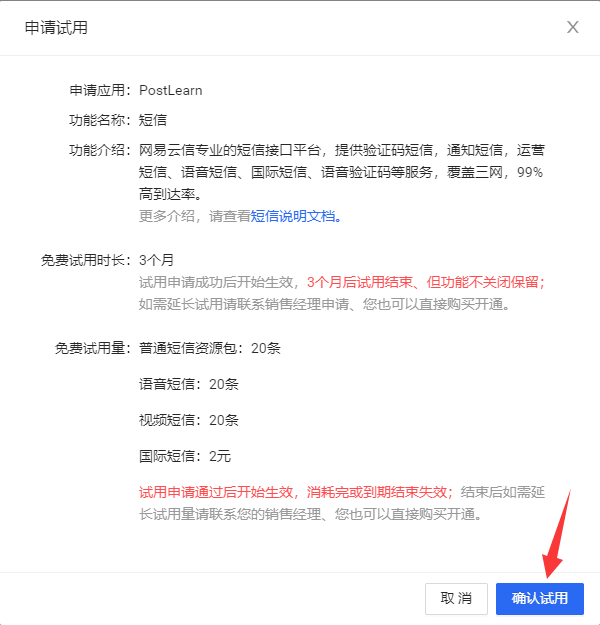- 此时实验环境就已经准备好了。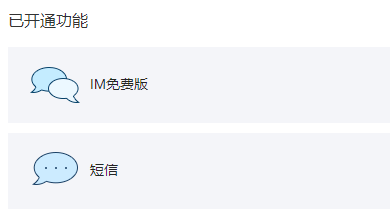<a name="UBfpk"></a>#### 3.2.2 构建请求头- 拿到一个新的东西,程序员肯定是不知道怎么开发的,因此第一步首先就是要去阅读开发手册。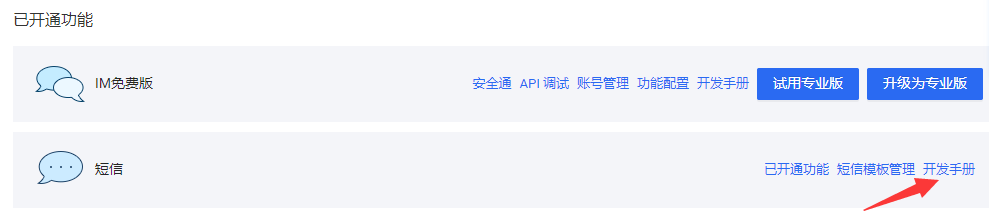- 在开发者中心 >> IM即时通讯 >> API参考 >> API调用方式 >> 请求头(Header)中描述了请求头的四个参数,若没有正确配置会报错`{"desc":"bad http header","code":414}`。- AppKey:云信控制台上您的应用对应的appkey。获取AppKey,AppSecret的方式:点击应用 >> 应用实例 >> App Key管理。<br />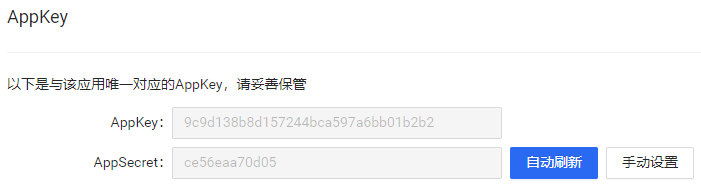- Nonce:随机数(最大长度128个字节)。- CurTime:当前UTC时间戳,需要时String类型的。(当前时间戳的有效范围是指发起请求瞬间的前后5分钟内)- CheckSum:将AppSecret、Nonce、CurTime拼接成一个长字符串,然后用SHA1加密算法计算,最后转换成十六进制字符。- 出于安全性考虑,每个CheckSum的有效期为5分钟(用CurTime计算),建议每次请求都生成新的CheckSum,同时请确认发起请求的服务器是与标准时间同步的,比如有NTP服务。- CheckSum检验失败时会返回414错误码,更多错误码信息请参见[状态码](https://doc.yunxin.163.com/docs/TM5MzM5Njk/TM5NTk2Mzc?platformId=60353)。- 在Python中的实现即为:```pythonimport randomimport timeimport hashlib# 系统指定的密钥数据,直接复制过来即可。app_key = "9c9d138b8d157244bca597a6bb01b2b2"app_secret = "ce56eaa70d05"# 随机数(字符串类型)。# 范围可以自己指定,在128个字符内即可。nonce = str(random.randint(100, 999))# time.time()获取的是毫秒数的当前时间戳。# 接口需要的是秒数的UTC时间戳,因此转换成整型即可。# 最后需要的是字符串类型的数据。cur_time = str(int(time.time()))# 根据官网指定的算法构建CheckSum。check_sum = hashlib.sha1((app_secret + nonce + cur_time).encode("utf-8")).hexdigest()headers = {"AppKey": app_key,"Nonce": nonce,"CurTime": cur_time,"CheckSum": check_sum}
3.2.3 构建数据与发送验证码
在开发手册 >> 开发指南 >> 短信接口指南 >> 发送短信/语音短信验证码 >> 请求说明中给了如下一段样式。
- 说明请求的方式为POST请求。
- 请求的地址为
https://api.netease.im/sms/sendcode.action。POST https://api.netease.im/sms/sendcode.action HTTP/1.1Content-Type:application/x-www-form-urlencoded;charset=utf-8
接着,在开发手册 >> 开发指南 >> 短信接口指南 >> 发送短信/语音短信验证码 >> 参数说明中可以看到,只有mobile(手机号码)是必须的,其他都是可选参数。

- 因此,就可以用Python程序发送一段验证码了。 ```python import random import time import hashlib import requests
构建请求头。
app_key = “9c9d138b8d157244bca597a6bb01b2b2” app_secret = “ce56eaa70d05” nonce = str(random.randint(100, 999)) cur_time = str(int(time.time())) check_sum = hashlib.sha1((app_secret + nonce + cur_time).encode(“utf-8”)).hexdigest()
headers = { “AppKey”: app_key, “Nonce”: nonce, “CurTime”: cur_time, “CheckSum”: check_sum }
URL与请求数据。
url = “https://api.netease.im/sms/sendcode.action“ data = { “mobile”: “13214461568” }
发送POST请求。
resp = requests.post(url=url, headers=headers, data=data) print(resp.json()) # {‘code’: 200, ‘msg’: ‘2001’, ‘obj’: ‘6553’},手机接收到的验证码为6553。 ```
从上述开发中,可以体会到POST请求的加密性:
由于POST请求构建时的加密性,想要成功发送一条POST请求,基本只有两种方式:
- 文档:靠着官方给的开发文档,根据其中提到的加密算法,实现POST请求的构建。
- 逆向:使用逆向破解加密信息,实现POST请求的构建,但是这种方法很难。

若有收获,就点个赞吧
0 人点赞
