01. 高阶函数
1.1 函数嵌套
1.1.1 函数嵌套概述
- 函数嵌套与if分支嵌套、for/while循环一样,实际上就是在函数体内部再定义了一个新的函数。
如下列函数就是一个函数嵌套,其中outer()被称为外层函数,inner()被称为内层函数。
def outer():print("外部函数")def inner():print("内部函数")
1.1.2 函数亦对象(函数在内存中的形态)
Python是一门面向对象(OOP)的语言,在Python中万事万物皆对象。
- 在OOP这个大前提下,函数自然也是一个对象。既然是对象,那么函数就也可以是一个参与运算的数据,是数据的话就会在内存中有地址,就可以用来给变量赋值。
函数名()的形式是用来调用已经定义的函数,而函数名则是用来获取函数对象在内存中的地址。print(outer) # <function outer at 0x000001E722CBF0D0>
同时,也可以通过
type(函数名)来查看函数的类型,不同的函数的类型也是不同的。在01. Python函数基础中有提到,普通函数在方法池中创建并存储,在调用时压栈。
- 既然函数也是一个对象数据的话,那么内层函数实际上是在外层函数压栈后,在栈中的域场中被创建出来的,因此就如同一个局部变量一样,在全局中是无法直接调用内层函数的。
- 内部函数调用方式一:在哪定义的就在哪里调用。即在函数体内直接调用内部函数,这样在调用外部函数的同时,也调用了内部函数。
```python
def outer():
print(“外部函数”)
def inner():
inner()print("内部函数")
outer() “”” 运行结果: 外部函数 内部函数 “””
- 内部函数调用方式二:将内层函数作为返回值返回。(高阶函数之将函数当做返回值)```pythondef outer():print("外部函数")def inner():print("内部函数")return innerf = outer() # 此时f代表的就是内存函数inner()print(f, type(f))>f() # 调用f实际上就是调用内层函数inner()"""运行结果:外部函数<function outer.<locals>.inner at 0x000001AF3597C8B0> <class 'function'>内部函数"""
- 当然,也可以通过双括号的形式直接调用内层函数。
outer()()"""运行结果:外部函数内部函数"""
- 注意:方法二在返回函数时,本质上是返回函数在内存中的地址,故应该为
return 函数名,这在1.1.2中也有使用。因此返回函数时是不能带括号的,因为return 函数名()在这里实际上是在外层函数内部调用了内层函数,然后将获取到的内层函数的返回值再返回到外层函数的调用处。 ```python def outer(): def inner(): return 1 return inner()
print(outer()) # 1 print(outer()()) # 报错,TypeError: ‘int’ object is not callable
<a name="wNAjW"></a>### 1.2 高阶函数详解<a name="reinH"></a>#### 1.2.1 高阶函数介绍- 所谓高阶函数,就是把函数A当做函数B的参数或者函数B的返回值来使用,这种使用形式就称为高阶函数。- 在1.1.3的内部函数调用方式二中已经使用过了将函数当做返回值来使用,这里将介绍如何将函数当做参数使用。<a name="nXNvY"></a>#### 1.2.2 将函数作为参数使用- 基本概念之回调函数:被当做参数传递的函数称之为回调函数。回调函数被赋值后不会立即调用,而是在满足逻辑需求的位置进行调用。- 引入案例:编写三个函数分别实现获取多个数据中最大的数据、获取多个数据中个位数最大的数据,获取多个数据中十位数最大的数据。```pythondef get_max(*args):""" 获取多个数据中最大的数据 """from collections.abc import Iterableif len(args) == 1 and isinstance(args[0], Iterable):args = args[0]if len(args) < 1:raise ValueError("需要传入多个数据")max_value = args[0]for ele in args[1:]:if ele > max_value:max_value = elereturn max_valuedef get_max_by_single(*args):""" 获取多个数据中个位数最大的数据 """from collections.abc import Iterableif len(args) == 1 and isinstance(args[0], Iterable):args = args[0]if len(args) < 1:raise ValueError("需要传入多个数据")max_value = args[0]for ele in args[1:]:if ele % 10 > max_value % 10:max_value = elereturn max_valuedef get_max_by_ten(*args):""" 获取多个数据中十位数最大的数据 """from collections.abc import Iterableif len(args) == 1 and isinstance(args[0], Iterable):args = args[0]if len(args) < 1:raise ValueError("需要传入多个数据")max_value = args[0]for ele in args[1:]:if ele // 10 % 10 > max_value // 10 % 10:max_value = elereturn max_valuelst = [112, 23, 59, 41, 65, 76, 22]print(get_max(lst)) # 112print(get_max_by_single(lst)) # 59print(get_max_by_ten(lst)) # 76
- 通过观察三个函数的函数体可以发现,只有基于什么部分比较大小的if语句有变化,其他部分三个函数都是相同的,那实际上也是重复编码了。
- 函数的本质就是将代码中相同的部分抽取出来,避免重复编码,增加代码的复用性并降低代码的冗余性。那么多个函数中相同的操作,其实也可以抽取出来,不同部分的操作再用回调函数处理即可。
示例:定义一个函数
get_max(*args, key),若key不传值,则获取多个数据的最大值,若key传值,则根据key的规则获取最大值。 ```python def get_max(*args, key=None): “”” 获取多个数据中最大的数据 “”” from collections.abc import Iterable if len(args) == 1 and isinstance(args[0], Iterable):args = args[0]
if len(args) < 1:
raise ValueError("需要传入多个数据")
if key == None:
# 若key不传值,则获取多个数据的最大值。max_value = args[0]for ele in args[1:]:if ele > max_value:max_value = ele
else:
# 若key传值,则根据key的规则获取最大值。max_value = args[0]for ele in args[1:]:if key(ele) > key(max_value):max_value = ele
return max_value
def get_single(num):
# 获取个位数的数据return num % 10
def get_ten(num):
# 获取十位数的数据return num // 10 % 10
lst = [112, 23, 59, 41, 65, 76, 22] print(get_max(lst)) # 112,获取多个数据中最大的数据。
高阶函数,将函数作为参数传递进另一个函数。
传递进去的get_single()和get_ten()都是回调函数。
print(get_max(lst, key=get_single)) # 59,获取多个数据中个位数最大的数据。 print(get_max(lst, key=get_ten)) # 76,获取多个数据中十位数最大的数据。
<a name="ZtOrm"></a>#### 1.2.3 lambda表达式- 函数体十分简单(简单到一行代码就能实现),并且只用了一两次的函数都可以用lambda函数来替代。如1.2.2中的get_single()和get_ten()函数。- lambda表达式的语法格式:`[函数对象 = ]lambda 参数列表: 功能代码`- lambda表达式的功能代码只有一行,需要多行代码实现功能不能使用lambda表达式,必须使用def定义函数。- 为了节约代码行数,lambda表达式没有return,功能代码的结果是什么,表达式的返回值就是什么。- 示例1:用lambda表达式求两个数的和。(用lambda表达式定义函数)```pythonnum1 = 10num2 = 20add = lambda n1, n2: n1 + n2num3 = add(num1, num2)print(num3) # 30
示例2:用lambda表达式改写1.2.2中
get_max(*args, key=None)函数的调用。(匿名函数)- 因为lambda表达式本质上是一个函数,但是它并没有函数名,因此lambda表达式在Python中也成为匿名函数。
- lambda表达式即提高了效率,也节省了内存。
- 匿名函数基本上是调用一次的函数,这种函数若使用def的方法定义,则一次调用完成后还会在方法区方法池中保留着,但从逻辑上看这个函数在内存中保留着实际上并没有什么意义,反而还浪费的内存空间;lambda表达式则在调用完成后就直接释放掉了,不会占用什么空间。
lst = [112, 23, 59, 41, 65, 76, 22]print(get_max(lst)) # 112print(get_max(lst, key=lambda x: x % 10)) # 59print(get_max(lst, key=lambda x: x // 10 % 10)) # 76
1.3 系统中的高阶函数
1.3.1 max()获取最大值/min()获取最小值
max(数据, key=函数):可以实现按照某个标准对比获取数据中的最大值;若key不传值,则按照元素大小比较。min(数据, key=函数):可以实现按照某个标准对比获取数据中的最小值;若key不传值,则按照元素大小比较。示例1:获取列表中最大、最小的字符串。
data = ['hello', 'Good', 'Nice', 'bye', 'Zoon', 'zero', 'beautiful']max_str = max(data)min_str = min(data)print(max_str, min_str) # zero Good
示例2:获取列表中最长、最短的字符串。
data = ['hello', 'Good', 'Nice', 'bye', 'Zoon', 'zero', 'beautiful']longest_str = max(data, key=len)shortest_str = min(data, key=len)print(longest_str, shortest_str) # beautiful bye
示例3:忽略大小写的情况下获取列表中最大、最小的字符串。
data = ['hello', 'Good', 'Nice', 'bye', 'Zoon', 'zero', 'beautiful']max_str_ignore_case = max(data, key=lambda ele: ele.lower()) # 排序时将所有传入的字符串中的所有字符全部转成小写后再比较。min_str_ignore_case = min(data, key=lambda ele: ele.upper()) # 当然全部转成大写也可以。print(max_str_ignore_case, min_str_ignore_case) # Zoon beautiful
1.3.2 map()数据映射
map(func, iterable)可以按照指定函数func的功能,将序列iterable中的元素转化为指定格式。- 示例1:将数值型列表中的所有元素都转换成字符串。 ```python nums = [12, 34, 56, 78, 90] str_map = map(lambda ele: str(ele), nums) print(str_map) #
整体可以简写为:
str_list1 = list(map(str, nums)) print(str_list1) # [‘12’, ‘34’, ‘56’, ‘78’, ‘90’]
- 示例2:将数值型列表中的所有元素都乘以10。```pythonnums = [12, 34, 56, 78, 90]ele_mult_by_10 = list(map(lambda ele: ele * 10, nums))print(ele_mult_by_10) # [120, 340, 560, 780, 900]
示例3:在一行中输入年、月、日三个数据,并赋值给三个变量。
year, month, day = map(int, input().split()) # map对象也是一个序列,可直接解包print(year, month, day, sep="\n")"""运行结果:2022 08 192022819"""
1.3.3 filter()过滤器
filter(function or None, iterable)是一个过滤器,可以按照指定的要求,对序列中的元素进行过滤- 如果将函数位置设置为None的话,过滤准则是按照布尔转换规则,对元素进行过滤。(即转换后为False的过滤出去,为True的留下)
示例1:过滤出数值型数据中非0的数据。
lst = [4, 0, 1, 1, 3, 2, 0, 1, 0, 0]f = filter(None, lst)print(f) # <filter object at 0x0000024C252DC580>,是个filter过滤器对象序列no_0 = list(f) # 按照布尔类型转换规则,0为Fasle,其他为True。print(no_0) # [4, 1, 1, 3, 2, 1],可以发现0全部被过滤出去了。
如果设置的是函数,则会按照函数功能对元素进行过滤。这种形式会将iterable中每个元素都传递到函数function中,若该元素通过函数计算得到True,则会被保留,否则就被过滤出去。
示例2:过滤出以Z或者z开头的单词。
data = ['hello', 'Good', 'Nice', 'bye', 'Zoon', 'zero', 'beautiful']start_z = filter(lambda ele: ele.startswith(("Z", "z")), data)print(list(start_z)) # ['Zoon', 'zero']
示例3:过滤出80分以上的科目及其成绩。
score = {'语文': 77, '数学': 82, '英语': 96}over_80 = dict(filter(lambda x: x[1] > 80, score.items()))print(over_80) # {'数学': 82, '英语': 96}
1.3.4 reduce()累计功能
functools模块中的reduce(function, sequence)函数可以按照指定的函数function的功能,对序列sequence中的元素进行累计操作(如累加、累乘等)。- 示例一:用reduce()求1~100的和。 ```python from functools import reduce
data = range(1, 101) result = reduce(lambda x, y: x + y, data) print(result) # 5050
- 示例2:用reduce()求10!。```pythonfrom functools import reducedata = range(1, 11)result = reduce(lambda x, y: x * y, data)print(result) # 3628800
1.3.5 sorted()排序
sorted(iterable, key, reverse)可用于对序列iterable中的元素进行排序。- iterable:进行排序的序列。
- key:基于数据的何种状态排序。如要根据个位数的数据排序,则
key=lambda x: x % 10。当不指定Key时,则按照元素的字面量值进行排序。 - reverse:若为True时,则根据Key对序列iterable进行降序排序;若为False时,则根据Key对序列iterable进行升序排序。
- 参数reverse的本质是将排序好的序列进行反转。
- sorted()函数实际上是对序列进行升序操作的,当reverse=True时,实际上就是将升序排序后的序列进行反转,以此得到降序排序的效果。
- sorted()函数的注意事项:
- 所有序列中只有列表是可以排序的(字符串、元组是不可变的;集合、字典是无序的)。
- 但是所有序列都可以传入sorted()函数,只不过sorted()会先把序列转换成列表,然后将排序完成的列表返回。
- 示例1:对字符串
s = "4hgvghds4567vgh"中的字符元素去重,然后按照每个字符的字面量值进行升序排序,并得到排完序的字符串。 ```python s = “4hgvghds4567vgh” distinct = set(s) # 用set()对字符串序列中的字符元素进行去重 print(distinct) # {‘4’, ‘v’, ‘g’, ‘d’, ‘6’, ‘7’, ‘h’, ‘s’, ‘5’}
sorted_dis = sorted(distinct) # 对distinct序列进行升序排序 print(sorted_dis) # [‘4’, ‘5’, ‘6’, ‘7’, ‘d’, ‘g’, ‘h’, ‘s’, ‘v’]
result = “”.join(sorted_dis) # 将处理完成的数据组合成字符串 print(result) # 4567dghsv
- 示例2:对字符串列表分别按照原值字面量、忽略大小写后的字面量、字符串长度进行降序排序。```pythonwords = ['good', 'hello', 'nice', 'bye', 'lucky', 'beautiful', 'Zoom']# 按照字面量对字符串列表进行降序排序。sorted_by_value = sorted(words, reverse=True)print(sorted_by_value) # ['nice', 'lucky', 'hello', 'good', 'bye', 'beautiful', 'Zoom']# 按照忽略大小写后的字面量对字符串列表进行降序排序。sorted_by_ignore_value = sorted(words, key=lambda ele: ele.lower(), reverse=True)print(sorted_by_ignore_value) # ['Zoom', 'nice', 'lucky', 'hello', 'good', 'bye', 'beautiful']# 按照字符串长度对字符串列表进行降序排序。sorted_by_len = sorted(words, key=lambda ele: len(ele), reverse=True)print(sorted_by_len) # ['beautiful', 'hello', 'lucky', 'good', 'nice', 'Zoom', 'bye']
对字典列表进行排序:(首先了解字典的组成结构,接着根据字典中的某一个键值对进行排序)
现在有一个student列表,其中的每个元素都是一个字典,如下:
students = [{'name': '乐乐', 'age': 18},{'name': '倩倩', 'age': 16},{'name': '翠翠', 'age': 19},{'name': '欢欢', 'age': 17}]
字典列表是不支持直接排序的,因为两个字典是无法比较大小的。
sorted(students) # 报错:TypeError: '<' not supported between instances of 'dict' and 'dict'
但是,实际上可以通过参数key,指定基于字典中的那部分内容进行排序,那字典列表也是可以排序的。
# 如指定按照年龄进行降序排序sorted_by_age = sorted(students, key=lambda ele: ele["age"], reverse=True)print(sorted_by_age) # [{'name': '翠翠', 'age': 19}, {'name': '乐乐', 'age': 18}, {'name': '欢欢', 'age': 17}, {'name': '倩倩', 'age': 16}]
对字典进行排序:
字典是一个无序序列,但是直接
sorted(dict_obj)是可以的,只不过它的本质是sorted([i for i in dict_obj.keys()])score = {"语文": 98, "数学": 76, "英语": 87, "政治": 72}print(sorted(score)) # ['政治', '数学', '英语', '语文']print(sorted([i for i in score.keys()])) # ['政治', '数学', '英语', '语文']
若要求对字典进行排序,排序后的结果还是原来的字典(即字典中还是原来那些元素,只是元素的先后顺序发生了改变),则可以先用
dic_obj.items()获取由字典中所有键值对构成的二元组列表,然后再指定是根据所有的键进行排序还是所有的值进行排序。- 排序得到的是一个个排好序的二元组,再用dict()函数将这些二元组列表构建成字典,即可获得一个排好序的字典。 ```python score = {“语文”: 98, “数学”: 76, “英语”: 87, “政治”: 72}
获取字典中的每个键值对,然后根据值进行降序排序。
sorted_score = sorted(score.items(), key=lambda ele: ele[1], reverse=True) print(sorted_score) # [(‘语文’, 98), (‘英语’, 87), (‘数学’, 76), (‘政治’, 72)]
result = dict(sorted_score) print(result) # {‘语文’: 98, ‘英语’: 87, ‘数学’: 76, ‘政治’: 72}
- 知识点补充:列表自带的sort()函数也支持key和reverse。只不过`list_obj.sort()`会直接操作列表list_obj本身,而sorted()则不会操作序列,而是将序列中的元素排序完成后形成的列表进行返回,即原序列不会发生任何改变。```pythonwords = ['good', 'hello', 'nice', 'bye', 'lucky', 'beautiful', 'Zoom']words.sort(key=lambda ele: len(ele), reverse=True)print(words) # ['beautiful', 'hello', 'lucky', 'good', 'nice', 'Zoom', 'bye']
1.3.6 zip()组合序列
zip(seq1, seq2, ……, seqN)用于将多个序列中相同索引位上的元素组合在一起,形成新的二维序列。data1 = "ABCD"data2 = [97, 98, 99, 100]data3 = ('a', 'b', 'c', 'd')zip_data1to3 = zip(data1, data2, data3)print(zip_data1to3) # <zip object at 0x000001800B996E00>,结果是一个zip对象list_data1to3 = list(zip_data1to3) # 构造成二维数组print(list_data1to3) # [('A', 97, 'a'), ('B', 98, 'b'), ('C', 99, 'c'), ('D', 100, 'd')]
多个序列之间的长度可以不一样,最后生成二维序列时内层序列的个数就由长度最短的序列决定。
l = list(zip("ABCDEFGH", [95, 96, 97, 98, 99, 100], ('a', 'b', 'c', 'd')))print(l) # [('A', 95, 'a'), ('B', 96, 'b'), ('C', 97, 'c'), ('D', 98, 'd')]"""因为:len("ABCDEFGH") = 8len([95, 96, 97, 98, 99, 100]) = 6len(('a', 'b', 'c', 'd')) = 4所以:len(l) = min(8, 6, 4) = 4"""
zip()的常见应用:将字典中的键值颠倒,即键变成值,值变成键。 ```python dic = {‘a’: 97, ‘b’: 98}
获取字典中的所有的键和所有的值。
key = dic.keys() value = dic.values()
将所有的键和值按照(value, key)的形式进行zip()组合。
list_zip = list(zip(value, key)) print(list_zip) # [(97, ‘a’), (98, ‘b’)]
将得到的二元组列表转换成字典。
new_dic = dict(list_zip) print(new_dic) # {97: ‘a’, 98: ‘b’}
<a name="GW0yr"></a>### 1.4 闭包<a name="gVOCR"></a>#### 1.4.1 闭包的概念- 闭包是指能够读取其他函数内部的局部变量的函数。- 在Python中只有嵌套函数的内层函数可以读取外层函数中的局部变量,因此闭包实际上是1.1 函数嵌套中的知识。- 准确来说,嵌套函数中内层函数就是闭包。- 示例:外层函数中有一个局部变量`a = 10`,当内层函数被调用时,会打印外层函数的局部变量a。```pythondef outer():a = 10def inner(): # 内层函数inner()就被称之为闭包print(f"内层函数:{a}")inner() # 想让内层函数执行,必须得调用outer() # 内层函数:10
1.4.2 nonlocal关键字
- 内层闭包函数可以访问外层函数的变量,但无法修改外层函数的变量。
```python
def outer():
a = 10
def inner():
inner() print(f”outer: {a}”)a = 20print(f"inner: {a}")
outer() “”” 运行结果: inner: 20 outer: 10 # 外层函数的变量a的值并没有被改变。 “””
- 回顾global关键字,当函数体中要修改或创建全局变量时,需要用global关键字声明一次全局变量。```pythonname = "杜波"def change_name():global namename = "杜小波"change_name()print(name) # 杜小波
- Python中有一个与global关键字类似的关键字nonlocal,当内层闭包函数要修改外层函数的变量时,也要用nonlocal关键字声明一下变量。
```python
def outer():
a = 10
def inner():
inner() print(f”outer: {a}”)nonlocal aprint(f"inner: {a}")a = 20
outer() “”” 运行结果: inner: 10 outer: 20 “””
<a name="qpw2I"></a>### 1.5 装饰器<a name="NdjbS"></a>#### 1.5.1 装饰器产生流程- 现有一个需求,要求定义两个函数,一个用来打印九九乘法表,一个用来打印三三乘法表,并且每打印一行休眠1秒;函数定义完成后调用这两个函数,并记录这两个函数运行所需要的时间。```pythonimport time# 三三乘法表def table_three():for i in range(1, 4):time.sleep(1)for j in range(1, i + 1):print(f"{j} * {i} = {i * j}", end="\t")print()# 九九乘法表def table_nine():for i in range(1, 10):time.sleep(1)for j in range(1, i + 1):print(f"{j} * {i} = {i * j}", end="\t")print()# 调用函数并记录时间start_3 = time.time()table_three()end_3 = time.time()print(f"三三乘法表打印所花费时间:{end_3 - start_3}s")start_9 = time.time()table_nine()end_9 = time.time()print(f"九九乘法表打印所花费时间:{end_9 - start_9}s")
- 此时可以试着再定义一个五五乘法表函数,调用并记录时间。
```python
def table_five():
for i in range(1, 6):
time.sleep(1)for j in range(1, i + 1):print(f"{j} * {i} = {i * j}", end="\t")print()
start_5 = time.time() table_five() end_5 = time.time() print(f”五五乘法表打印所花费时间:{end_5 - start_5}s”)
- 可以发现很明显的一点就是记录函数运行时间的程序在重复,因此可以将这部分代码封装成一个函数。```pythondef get_time(func):""":param func: 要被调用并计时的函数:return: None"""start_time = time.time()func()end_time = time.time()print(f"函数运行所需的时间为:{end_time - start_time}s")get_time(func=table_three)get_time(func=table_five)get_time(func=table_nine)
现在有一个新需求:在调用table_three()时,既要打印三三乘法表,又要打印函数执行时间。(即在全局不调用get_time()函数)
- 通过分析发现,只调用table_three()函数,仅凭其目前自身的代码是无法实现这个需求的,因此需要想办法对函数的工具进行扩展。
- 就目前看来,全局中的所有函数中只有get_time()函数能够做到即运行函数,又获取时间。
因此如果想要完成需求,就需要让table_three()函数等价于get_time()函数,但是若直接将get_time()函数的地址赋值给table_three(),那么table_three()函数的功能就没有了。因此需要先将table_three()函数的功能保留下来,再将get_time()函数的地址赋值给table_three()。
other = table_three # 保留三三乘法表的函数功能。table_three = get_time # 将get_time()函数的地址赋值给table_three()。
此时再调用table_three()函数(本质上是调用get_time()函数),并在函数内部调用执行三三乘法表的逻辑(即调用other())即可实现即打印三三乘法表,又获取时间。
table_three(func=other)
同理,五五乘法表和九九乘法表都可以用这种方法完成功能的扩展。 ```python
扩展五五乘法表
other_5 = table_five table_five = get_time table_three(func=other_5)
扩展三三乘法表
other_9 = table_nine table_nine = get_time table_nine(func=other_9)
- 此时可以发现,给table_three、table_three、table_nine这些函数进行扩展的代码逻辑又重复了,因此又可以将重复的逻辑封装成函数。- 首先,这个函数应该要传入一个other_x(这个other_x实际上就是table_xxx函数),然后将table_xxx函数转换成get_time函数。(简单来说就是定义一个中间变量other_x,接收要被修改之前的原功能table_xxx,然后返回此次转换想要得到的功能函数get_time)```pythondef transfer(other):return get_timetable_nine = transfer(other=table_nine)
- 此时,table_xxx原有的功能就被transfer函数中的形参other_x记录着了。此时要想调用table_xxx原有的功能,就只能在transfer函数中调用其形参other了。
若此时要调用转换后的table_nine函数,则就无法获取到table_nine原有的功能并传递给func参数了,因为table_nine原有的功能只在transfer的other参数中存在。
table_nine(func=?????)
可以尝试将get_time()函数的定义写在transfer(other)函数内部,这样在内部函数get_time()中就可以用闭包的特性直接调用到table_nine函数原有的功能了。
def transfer(other):def get_time():start_time = time.time()other()end_time = time.time()print(f"函数运行所需的时间为:{end_time - start_time}s")return get_time
此时转换后得到的函数是transfer(other)内部的空参get_time()函数,而非get_time(func),故只需要在转换时将原table_xxx函数的功能传入即可,调用时无需再传值。 ```python table_nine = transfer(other=table_nine) table_nine()
table_three = transfer(other=table_three) table_three()
table_five = transfer(other=table_five) table_five()
<a name="ZJV8y"></a>#### 1.5.2 @语法糖- 对于1.5.1最后的`table_nine = transfer(other=table_nine)`转换操作,Python支持使用`@外层函数`这样的语法糖进行转换。```python## 原定义:========================================================def table_nine():for i in range(1, 10):time.sleep(1)for j in range(1, i + 1):print(f"{j} * {i} = {i * j}", end="\t")print()def transfer(other):def get_time():start_time = time.time()other()end_time = time.time()print(f"函数运行所需的时间为:{end_time - start_time}s")return get_timetable_nine = transfer(other=table_nine)table_nine()## 等价于:========================================================def transfer(other):def get_time():start_time = time.time()other()end_time = time.time()print(f"函数运行所需的时间为:{end_time - start_time}s")return get_time@transferdef table_nine():for i in range(1, 10):time.sleep(1)for j in range(1, i + 1):print(f"{j} * {i} = {i * j}", end="\t")print()table_nine()
在def定义函数上面写
@转换函数的外层函数名这样结构就是Python中的装饰器结构。1.5.3 装饰器总结
装饰器用于在不改变原有功能的基础上,增加额外的功能,是编程中“封闭开放式原则”的体现。
- 封闭:函数的原始功能不再发生变化。
- 开放:在函数原有功能的基础上,再增加额外功能。
- 装饰器的格式:装饰器的本质就是闭包。
```python
def 外层函数名(形参名):
def 内层函数():
return 内层函数新增的功能原有的功能
@外层函数名 def 需要进行功能扩展的函数(): 函数体
- 注意:被`@`修饰的函数已经失去了原有的功能,变成了装饰器的内层函数功能。这就是为什么用装饰器修饰后就会既有原有功能,又有新功能的本质。<a name="t61PM"></a>### 1.6 装饰器完善<a name="IXaNZ"></a>#### 1.6.1 完善参数- 现已拥有的结构:- 通过前面的推导,得出一个用于计时的装饰器函数可以写成如下形式:```pythonimport timedef get_time(func):def wrapper():start = time.time()func()end = time.time()print(f"{func.__name__}的运行时间为:{end - start}秒。") # func.__name__用于获取函数名return wrapper
- 此时要计算如一个打印三三乘法表的函数运行所需要的时间,就可以用如下的方式实现:
```python
@get_time
def table_three():
for i in range(1, 4):
time.sleep(1)
for j in range(1, i + 1):
print()print(f"{j} * {i} = {i * j}", end="\t")
table_three()
- 带参数的函数使用装饰器:- 此时,有一个新的函数`add(num1, num2)`用于求两数和的函数定义如下:```pythondef add(num1, num2):return num1 + num2
- 若要计算add()函数运行所需要的时间,则也需要用
@get_time进行装饰。 ```python @get_time def add(num1, num2): return num1 + num2
此时add()等价于get_time()执行后的结果,即add()函数等价于wrapper()函数,并且用func记录了原有add()函数的功能。
即add = get_time(func=add)
- 被装饰后add()在内存中的结构实际上就变成了如下形式。可以很明显的发现在装饰器函数的内层函数wrapper()中调用add()函数时,根本没有办法对实参进行传值。```pythondef get_time(func):def wrapper():start = time.time()func(num1, num2) # 参数num1和num2没有传值入口。end = time.time()print(f"{func.__name__}的运行时间为:{end - start}秒。")return wrapper
通过分析可以得出,此时add()函数的调用在wrapper()函数中,而wrapper函数又等价于add()函数,因此若要给函数传参,则只需要在内层函数中加上形参即可。
def get_time(func):def wrapper(num1, num2):start = time.time()func(num1, num2)end = time.time()print(f"{func.__name__}的运行时间为:{end - start}秒。")return wrapper
由于装饰器可以用来装饰各种各样的函数,而每个函数的形参是不确定的,因此为了可以兼容各种函数,wrapper()传入的也应该是可变形参而不是固定的参数列表。
def get_time(func):def wrapper(*args, **kwargs):start = time.time()func(*args, **kwargs) # 在调用函数时需要进行解包end = time.time()print(f"{func.__name__}的运行时间为:{end - start}秒。")return wrapper
此时,不同形参列表的函数就都可以被调用了。 ```python @get_time def table_three(): for i in range(1, 4): time.sleep(1) for j in range(1, i + 1):
print(f"{j} * {i} = {i * j}", end="\t")
print()
@get_time def add(num1, num2): return num1 + num2
table_three() result = add(1, 2) print(result)
- 完善后的装饰器总结:```pythondef 外层函数名(形参名):def 内层函数(*args, **kwargs):新增的功能原有函数的调用(*args, **kwargs)return 内层函数@外层函数名def 需要进行功能扩展的函数(形参列表(可为空)):函数体
1.6.2 完善返回值
1.6.1中的代码还存在一个明显的BUG,就是用
@get_time装饰后的add()函数无法得到计算结果,即:result = add(1, 2)print(result)"""运行结果:add的运行时间为:0.0秒。None"""
此时只需要在内层函数wrapper()中获取原函数运行的结果,然后在wrapper()末尾将这个结果返回即可。
def get_time(func):def wrapper(*args, **kwargs):start = time.time()result = func(*args, **kwargs) # 得到原有功能的计算结果end = time.time()print(f"{func.__name__}的运行时间为:{end - start}秒。")return result # 将原有功能的计算结果返回。return wrapper
此时再调用add()函数,就即可以获取到函数的运行时间,又可以获取到返回值了。
add的运行时间为:0.0秒。3
完善后的装饰器总结: ```python def 外层函数名(形参名): def 内层函数(args, *kwargs):
新增的功能调用结果 = 原有函数的调用(*args, **kwargs)return 调用结果
return 内层函数
@外层函数名 def 需要进行功能扩展的函数(形参列表(可为空)): 函数体
- 当然,或确定装饰器装饰的都是无返回值函数,那么则不需要return也可以,因为没有return语句就等价于`return None`。<a name="WaPaG"></a>## 02. 递归算法<a name="cgq9Y"></a>### 2.1 递归基础<a name="L5dBj"></a>#### 2.1.1 递归方法概述- 所谓递归函数,就是指在一个函数内调用其自身的函数。- 函数递归包含了一种隐式的循环,它会重复执行某段代码,但这种重复执行无须循环控制。- 递归层次不能太深(Python支持的最大递归深度为995层),主要有如下几点原因:- 若层次太深则意味着循环次数过多,会造成程序卡顿的现象(感官上的卡顿);- 每一层递归都意味着会调用函数本身,调用的函数会压栈,若递归的层次过深,就代表着有较多的函数会压栈,又因为栈是先进后出的,这就导致层次过深的递归会给内存带来不小的压力;- 同时,一个程序所分配的内层空间是有限的,若压栈的函数达到甚至超过了阈值,就会造成Stack Overflow栈溢出,Python为了避免这种情况,会对这种递归进行报错:`RecursionError: maximum recursion depth exceeded in comparison`,即:`递归错误:比较时超过最大递归深度`。- 递归一定要向一个方向递归,并且在该方向上有一个确定的出口(该出口称之为基例),否则这种递归就变成了无穷递归,类似于死循环。<a name="CFbi9"></a>#### 2.1.2 递归程序示例- 计算1~100之间所有自然数的和。```javadef sum(num):if num == 1:return 1 # 出口即为num=1else:return num + sum(num - 1) # 递归方向:n -> 1负方向递归。res = sum(100)print(res)
-
2.2 斐波那契数列
2.2.1 斐波那契数列概述
斐波那契数列(Fibonacci sequence) 又称为兔子数列、黄金分割数列。
- 数列形式:
1、1、2、3、5、8、13、21、34、…… -
2.2.2 斐波那契数列的代码实现
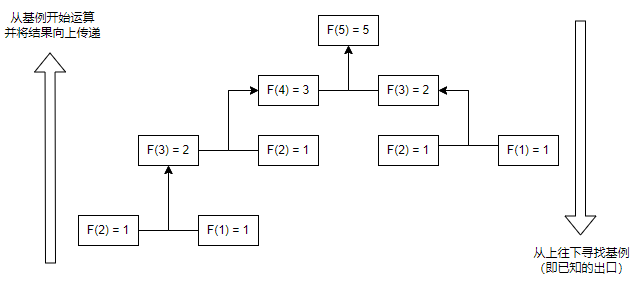
设需要获取斐波那契数列的第n(n >= 0)位数据,则需要从n -> 0进行负方向递归。 ```python def fibonacci(n): if 1 <= n <= 2:
return 1
elif n >= 3:
return fibonacci(n - 1) + fibonacci(n - 2)
else:
raise ValueError("n为大于等于1的正数")

f5 = fibonacci(5) print(f5) # 5 ```
流程图解:

若有收获,就点个赞吧
0 人点赞
