- 01. 函数的基本认识
- 当然,也可以将get_factorial(10)的返回值直接传递给print()函数进行打印输出。
- 使用\n连接两次print()
- 使用自定义内容,如—连接两次print()
- 运行结果:Hello—World
- 2.2 数学相关函数
- 默认只保留整数部分。
- 可以指定第二个参数,用于指定结果的小数点位数。
- 2.3 进制转换函数
- 2.4 字符与字符串相关函数
- 提取运算表达式
- 提取列表
- 对所有数据求和返回
- 先判断函数调用时传进来的是否是一个序列并进行相应的处理。
- 求数据最大值的业务逻辑代码。
- 函数内解包
- 首先将全局变量pi所在.py文件作为模块导入到当前文件中来
- 通过模块调用全局变量pi
- 4.3 数据内存图解
- 4.4 global关键字
01. 函数的基本认识
1.1 函数的概念
- 在开发过程中,经常会发现有些功能实现起来有着相同的逻辑。
- 比如要求2的平方是
2 ** 2,求3的平方是3 ** 2,求100的平方是100 ** 2。 - 我们不难得出结论,求一个数num的平方实际上就是
num ** 2,因此我们可以定义一个square(num)函数,将数字作为参数传递给函数,函数就会帮我们计算出值。 - 在这个例子中,求一个数num的平方的操作是比较简单的,因此即使对每个数直接
** 2好像也没什么,但是当这个操作十分复杂时,那就会编辑许多重复的代码。 - 此时我们就可以将复杂的操作封装成一个函数,然后需要时调用即可,大大简化了开发,提升了效率。
总结:当一些功能的逻辑是一样的,但这个逻辑的代码写了好多次,这就出现了重复编码的问题。为了避免重复编码,可以将逻辑相同的代码封装成函数。
1.2 函数的定义与调用
1.2.1 函数的定义
基本语法:
- def:定义函数的关键字。
- 函数名:自定义的名字,需要符合标识符规范(英文字母小写,单词和单词之间使用下划线隔开)。
- ():括号内部用于定义形参列表。括号内可以没有任何形参,但是小括号必须存在。
- 形参:全称为形式参数,是由外部传入,用来接受参与函数体功能运算的具体值。形参可以没有,可以有一个,也可以有多个。
- return:结束函数,并把函数的运行结果返回到调用的位置。return可以省略,表示函数没有返回值(即return None)。
def 函数名(形参1, 形参2, 形参3, ……, 形参n):函数体[return 返回值]
示例:定义一个函数,其作用是求n的阶乘。(n的阶乘:1 × 2 × 3 × …… × n)
def get_factorial(n): # 传进来的值是待计算阶乘的值# 求阶乘的代码实现factorial_n = 1for i in range(1, n + 1):factorial_n *= ireturn factorial_n # 将计算得到的阶乘返回
1.2.2 函数的调用
函数定义时,函数内函数体的代码不会运行;只有当函数被调用时,函数体中的代码才会执行计算。
基本语法:
- 实参列表:实参即实际参与运算的数据,称为实际参数,简称实参。函数定义时形参有几个,实参就有几个,且声明位置要与定义时保持一致。
- 当函数有返回值时,可以有一个变量去接收;如果函数没有返回值,则直接使用
函数名(实参列表)的方式调用即可。[接收返回值的变量 = ]函数名(实参列表)
示例:用1.2.1中定义的get_factorial(n)函数求10的阶乘。 ```python result = get_factorial(10) print(result)
当然,也可以将get_factorial(10)的返回值直接传递给print()函数进行打印输出。
print(get_factorial(10))
<a name="fCn2M"></a>## 02. 系统函数- Python中的函数分为系统函数和自定义函数。- 系统函数即官方提供的函数,是系统自带的。安装完Python环境后,系统函数可以直接拿来使用。<a name="jpEWi"></a>### 2.1 输入输出与类型函数<a name="Zuwk1"></a>#### 2.1.1 print()输出函数- print():把括号内的参数输出到控制台。```pythonprint("Hello") # Hello,输出一个参数print("Hello", 123, "World") # Hello 123 World,输出多个参数
- end参数:其值用作两次print()之间的连接符,默认为\n(即换行)。
```python
使用\n连接两次print()
print(“Hello”) print(“World”) “”” 运行结果: Hello World “””
使用自定义内容,如—连接两次print()
print(“Hello”, end=”—“) print(“World”)
运行结果:Hello—World
- sep参数:当一个print()函数要输出多个参数时,每个参数之间使用sep的值作为分隔符,默认为" "(即一个空格)。```python# 使用空格作为多个参数之间的分隔符print("Hello", "World", "Hello", "Python") # Hello World Hello Python# 使用自定义内容,如--作为多个参数之间的分隔符。print("Hello", "World", "Hello", "Python", sep="--") # Hello--World--Hello--Python
2.1.2 input()输入函数
input():由控制台从键盘中获取数据,并传入程序。
s = input("请输入一些内容:")print(s)
2.1.3 type()类型函数
type():参数参数的数据类型。
print(type("ABC"), type(123)) # <class 'str'> <class 'int'>
2.1.4 isinstance()类型判断函数
isinstance(data, type):判断数据data是否是指定的类型type的对象。
print(isinstance(3.14, int)) # Falseprint(isinstance(3.14, float)) # True
2.2 数学相关函数
2.2.1 abs()绝对值函数
abs():获取数值型数据的绝对值。
print(abs(123)) # 123print(abs(-456)) # 456
2.2.2 round()四舍五入函数
round():对数据进行四舍五入。 ```python
默认只保留整数部分。
print(round(4.4)) # 4 print(round(4.6)) # 5
可以指定第二个参数,用于指定结果的小数点位数。
print(round(4.123, 2)) # 4.12 print(round(4.123987, 3)) # 4.124
- 注意:在Python3中round()并不是绝对的四舍五入,如:```pythonprint(round(2.5)) # 2,正常来说应该是3print(round(3.5)) # 4print(round(4.5)) # 4,正常来说应该是5
对于这种情况,Python 3.x的文档是这样描述的:
For the built-in types supporting round(), values are rounded to the closest multiple of 10 to the power minus ndigits; if two multiples are equally close, rounding is done toward the even choice (so, for example, both round(0.5) and round(-0.5) are 0, and round(1.5) is 2). Any integer value is valid for ndigits (positive, zero, or negative). The return value is an integer if ndigits is omitted or None. Otherwise the return value has the same type as number.
可以看到,Python 3.x在处理类似
round(2.5)的情况时,2.5与2和3的差值相等,都是0.5,此时会返回偶数,也就是2。对于round(3.5),3.5与3和4的差值相等,返回偶数4。总结来说Python3中的
round()函数舍入规则为:四舍六入,0.5偶数截断。2.2.3 pow()幂函数
pow(x,y):求次幂,即
 。
。print(pow(2, 3)) # 8
2.2.4 max()/min()最大小值函数
max():获取多个数据的最大值。
print(max(19, 27, 38, 41, 29, 36))
min():获取多个数据的最小值。
print(min(19, 27, 38, 41, 29, 36))
max()/min()还可以获取一个序列中的最大/最小的元素。
lst = [48, 44, 24, 27, 40, 33, 25]print(f"max element = {max(lst)}") # max element = 48print(f"min element = {min(lst)}") # min element = 24
2.2.5 sum()求和
sum(seq):对序列seq中所有元素进行累加求和。
seq = [1, 2, 3, 4, 5]print(sum(seq)) # 15
2.3 进制转换函数
2.3.1 bin()二进制转换函数
bin():将数值参数转换为二进制。
print(bin(19)) # 0b10011,十进制转二进制print(bin(0o543)) # 0b101100011,八进制转二进制print(bin(0x3A)) # 0b111010,十六进制转二进制
2.3.2 oct()八进制转换函数
oct():将数值参数转换为八进制。
print(oct(0b10111)) # 0o27,二进制转八进制print(oct(19)) # 0o23,十进制转八进制print(oct(0x3A)) # 0o72,十六进制转八进制
2.3.3 hex()十六进制转换函数
hex():将数值参数转换为十六进制。
print(hex(0b10111)) # 0x17,二进制转十六进制print(hex(0o72)) # 0x3a,八进制转十六进制print(hex(19)) # 0x13,十进制转八进制
2.3.4 int()十进制转换函数
int():将数值参数转换为十进制。
print(int(0b10011)) # 19,二进制转十进制print(int(0o23)) # 19,八进制转十进制print(int(0x3a)) # 58,十六进制转十进制
2.4 字符与字符串相关函数
2.4.1 ord()字符转十进制数据
ord():获取字符对应的十进制数据。(转换格式对应UTF-8编码集,因为Python使用UTF-8编码)
print(ord("A")) # 65
2.4.2 chr()十进制数据转字符
chr():获取编码下十进制数据对应的字符数据。
print(chr(103)) # g
2.4.3 eval()解析字符串
eval(str):会提取字符串str中包含的数据,即去掉字符串str外层的引号,显示数据原本的形态。 ```python
提取运算表达式
s = “27 + 19” print(f”{s} = {eval(s)}”) # 27 + 19 = 46
提取列表
l = eval(“[1, 3, 4, 5]”) print(l) # [1, 3, 4, 5]
<a name="yAQjO"></a>## 03. 函数的参数<a name="tv3uk"></a>### 3.1 位置参数- 位置参数又称为必须参数,普通函数的形参在定义时使用的就算位置参数。- 函数定义时声明了几个形参,就得传入几个实参(默认参数除外),并且实参的位置与形参也要一一对应。- 示例:定义一个函数,传入年份和月份,返回该月份对应的参数。```pythondef get_month_day(year, month):if month not in range(1, 13):raise ValueError(f"the month needs to be between 1 and 12, but got {month}")if month in (1, 3, 5, 7, 8, 10, 12):return 31elif month in (4, 6, 9, 11):return 30else:return 29 if year % 4 == 0 and year % 100 != 0 or year % 400 == 0 else 28
这种函数就是典型的位置参数,有以下几个特点:
- 在调用时不能不传实参,也不能少传实参,更不能多传实参;以get_month_day()函数为例,比如传入两个参数,否则报错。
- 实参传入时的位置必须与形参定义时的位置保持一致,否则得到结果很有可能不正确,严重的会导致程序报错;以get_month_day()函数为例,第一个参数必须传入年份,第二个参数必须传入月份。
print(get_month_day(2020, 7)) # 31,正确调用print(get_month_day(7)) # 缺少一个参数,报错:TypeError: get_month_day() missing 1 required positional argument: 'month'print(get_month_day(7, 2020)) # 由于实参传递的位置与形参不匹配导致的报错:ValueError: the month needs to be between 1 and 12, but got 2020
3.2 关键字参数
3.2.1 普通关键字参数
调用函数传值的时候, 可以通过
形参名=值的形式,将数据传递给函数。这种方式传值时形参传入的顺序与函数定义的顺序可以不一样,因为这时是通过形参名来定位形参给形参赋值的。
print(get_month_day(month=12, year=1998)) # 31
注意:虽然关键字参数在传值时不用在意传值顺序,但是关键字传值必须在位置传值之后。
print(get_month_day(month=12, 1998)) # 报错,SyntaxError: positional argument follows keyword argument"""位置参数的实参在位置上是与形参一一对应的。在这个例子中,先给month用关键字参数传递了值:12然后在第二位参数位置上,传递了值1998,但是根据位置参数一一对应的原则,第二个参数位置上的参数还是month也就是说在关键字参数传值12后,位置参数又给month传值了1998此时year参数根本没有获取到任何值,Python程序也报错。"""
3.2.2 命名关键字参数
在定义函数时,形参名使用星号
*分割,*后面的就是命名关键字参数。def 函数名(普通参数1, 普通参数2, ……, *, 命名关键字参数1, 命名关键字参数2, ……)
示例:用命名关键字参数定义get_month_day()函数。
def get_month_day(year, *, month):if month not in range(1, 13):raise ValueError(f"the month needs to be between 1 and 12, but got {month}")if month in (1, 3, 5, 7, 8, 10, 12):return 31elif month in (4, 6, 9, 11):return 30else:return 29 if year % 4 == 0 and year % 100 != 0 or year % 400 == 0 else 28
命名关键字参数在调用时必须以关键字参数传值。
print(get_month_day(1998, month=12)) # 31,正确调用print(get_month_day(1998, 12)) # 报错,TypeError: get_month_day() takes 1 positional argument but 2 were given"""get_month_day(year, *, month)函数中只有一个year是位置参数但是get_month_day(1998, 12)这样的调用方式传入了两个位置参数,故报错因此命名关键字参数month必须以关键字参数传值。"""print(get_month_day(year=1998, month=12)) # 31,位置关键字参数year依旧可以使用任意一种传值方式。
3.3 默认参数
3.3.1 默认参数基础
当一个函数中的某个参数在大多数场景下都为一个值,只有在特定场景下值才会发生变化时,就可以将这个值定义为这个参数的默认值。
- 当函数中的某一个参数有了默认值,则在函数调用时可以不给这个参数传值,此时此次调用将使用默认值;也可以给这个参数传值,此时则正常使用传入的值。
默认参数的定义:参数默认值的指定需要在声明函数时就完成,具体语法格式为:
# 默认参数可以有多个,但是默认参数需要定义在非默认参数之后。def 函数名(其他形参, 默认形参=默认值):函数体[return 返回值]
- 示例:定义一个函数用于求x的y次方,且默认求x的平方。
def my_pow(x, y=2):return x ** y
默认参数函数的调用:在函数调用时,有默认值的参数可以不传值,此时使用默认值进行运算。
print(my_pow(4)) # 16,使用默认值y=2,则4 ** 2 = 16。
当默认参数为可变容器时,若没有给容器显示赋值,则调用的都是公用的一个容器。 ```python def add_data(data, values=[]): values.append(data) print(values)
add_data(10) # [10] add_data(20) # [10, 20],虽然values不是全局的,但是它确是公用的,因此不管怎么调用,访问都是同一块地址。 add_data(30, values=[88, 77, 66]) # [88, 77, 66, 30] add_data(40) # [10, 20, 40],由于没有显示赋值,则values还是共用的容器
- 默认参数为可变容器的内存解析:(内存的结构在4.2.3中有详细介绍)- 当函数定义时,即`def add_data(data, values=[])`时,首先会在方法区的方法池中存储函数结构。- 接着,因为形参中定义了容器类型的默认参数,因此Python会在堆中为values分配内存空间0x1101。(为什么共用的本质)- 此时随着`add_data(10)`和`add_data(20)`的两次调用,0x1101中就添加了两个元素。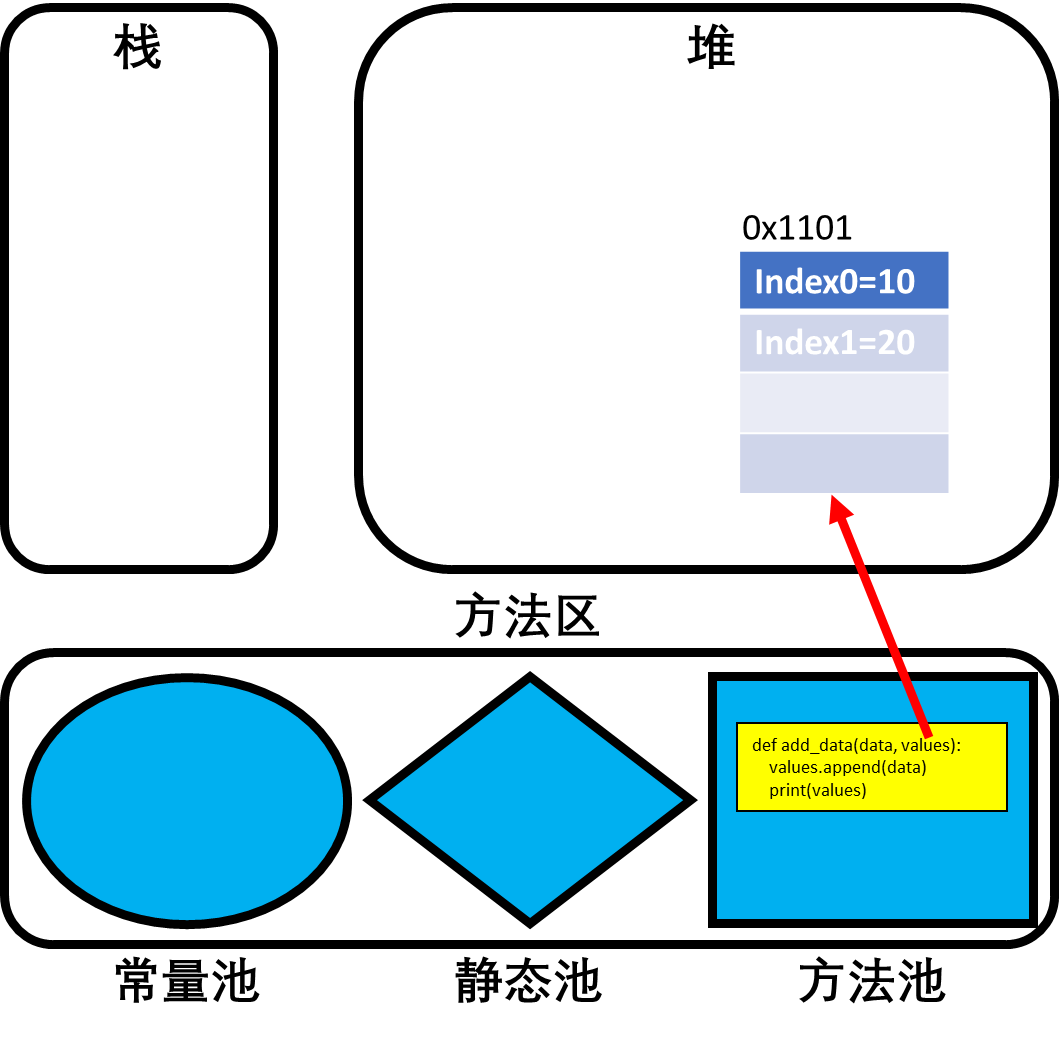- 但是第三次调用`add_data(30, values=[88, 77, 66])`手动传递了一个列表,因此此时会到指定的内存地址中添加元素30。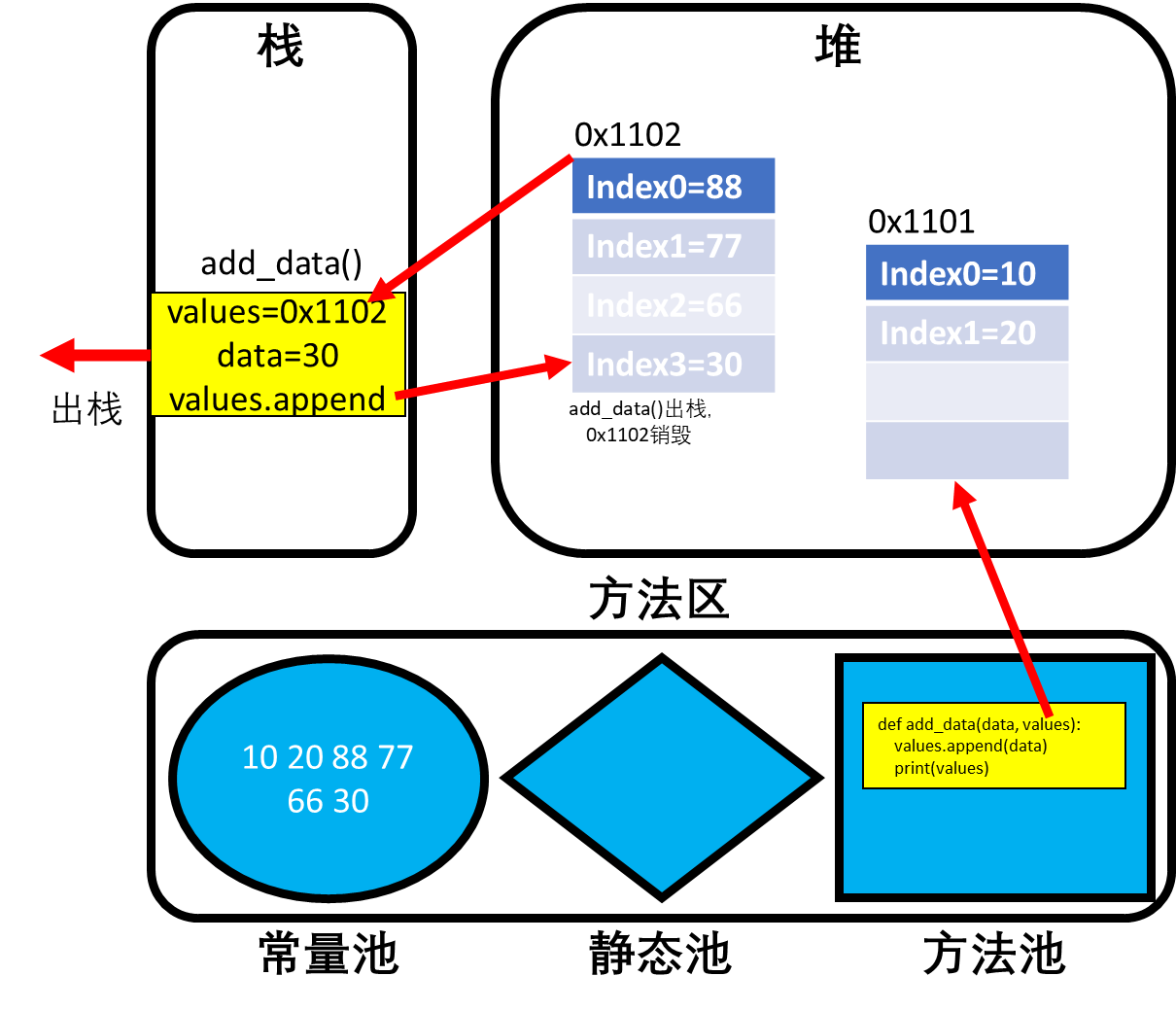- 而第四次调用`add_data(40)`使用的又是默认参数,故元素40又会被添加到0x1101中。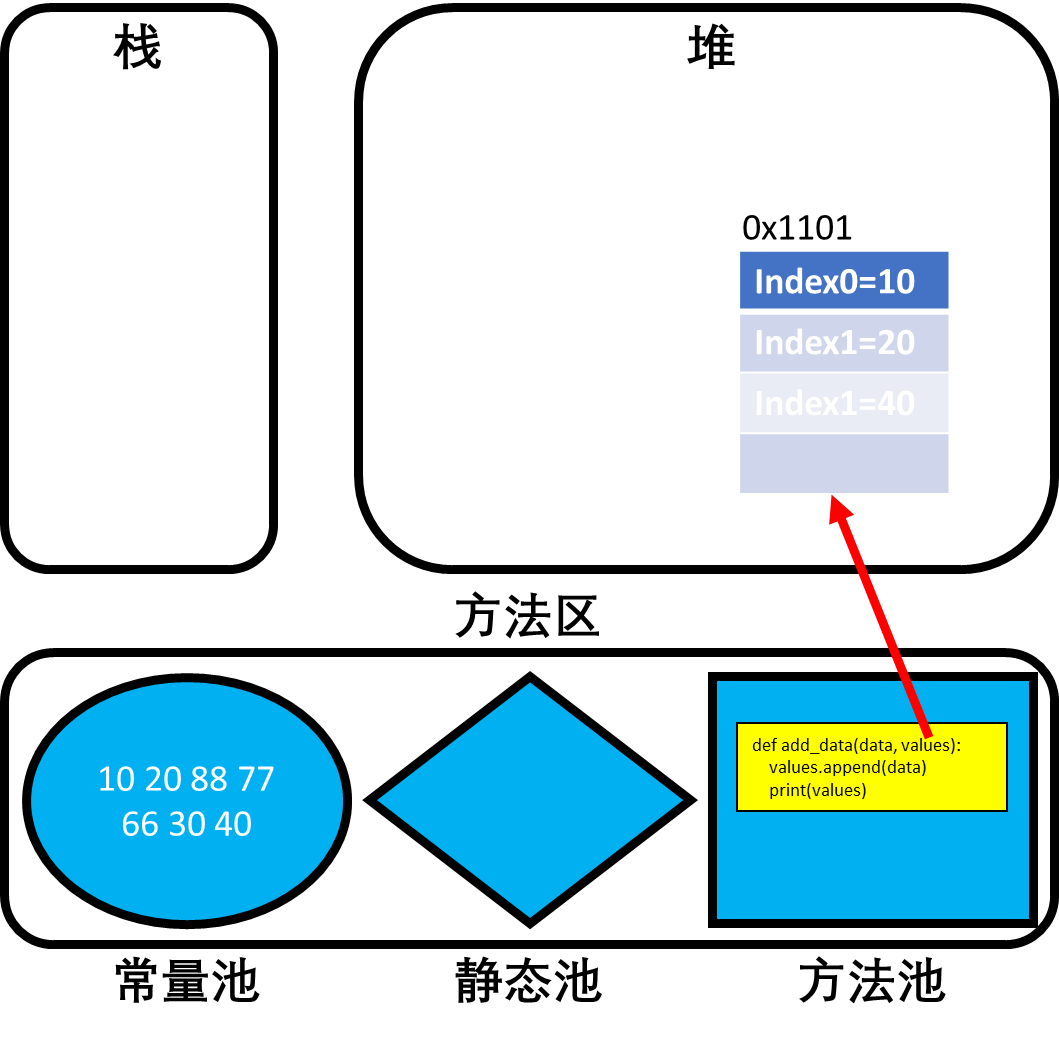<a name="FHe9a"></a>### 3.4 可变参数<a name="ghWhp"></a>#### 3.4.1 可变参数的概念- 在之前的学习中,参数(动态数据)的个数是根据具体的需求分析得出的,如定义一个函数求两数之和,那么这个函数的参数就有两个。- 但是在有些需求中,是无法分析出参数的具体个数的,如需要定义一个函数求多个数据的最大值,分析需求我们无法确定这多个数据到底是几个数据,这样一来函数到底有几个参数我们也就不得而知了。- 为了解决这种问题,Python使用星号表达形成可变参数。- 所谓可变参数,就是在调用时可以传入0个或任意多个实参(参数之间使用逗号隔开即可),Python会将这任意个实参组合成一个元组进行计算。- 可变参数函数的定义格式:```pythondef 函数名(其他参数, *可变参数):
示例:定义一个函数,传入任意多个数据,打印数据在函数中的形式与数据类型,并对所有数据求和后返回。 ```python def get_multiple_sum(*nums): print(nums, type(nums)) # 打印数据在函数中的形式与数据类型
对所有数据求和返回
total = 0 for i in nums:
total += i
return total
print(get_multiple_sum(10, 20, 30))
“””
(10, 20, 30)
<a name="qCzU2"></a>#### 3.4.2 可变参数的实参为序列时- 当向get_multiple_sum()传入的不是一堆分散的数据,而是一个数据序列时,程序会报错。```pythonprint(get_multiple_sum([10, 20, 30]))"""([10, 20, 30],) <class 'tuple'>TypeError: unsupported operand type(s) for +=: 'int' and 'list'"""
- 报错原因分析:(总的来说就是要将列表中的元素传递给函数,而不是将整个列表传递给函数)
[10, 20, 30]传递到get_multiple_sum()函数中后,根据可变参数的特性,会将实参数据组成和元组(注意是组合成元组而非转换为元组),因此列表组合成元组后得到的结果为([10, 20, 30], )这样的一元组。- 接着get_multiple_sum()函数将会遍历一元组中的所有数据,故遍历得到列表
[10, 20, 30],然后与total相加得到计算表达式total = 0 + [10, 20, 30]。 - 因为Python不支持整型数据与列表类型的数据进行算数运算,因此报错。
解决方式:在列表
[10, 20, 30]传递给get_multiple_sum()函数之前,对列表进行解包,让其以一堆散数据的形式传入函数。print(get_multiple_sum(*[10, 20, 30])) # 使用星号表达式解包,相当于get_multiple_sum(10, 20, 30)"""(10, 20, 30) <class 'tuple'>60"""
-
3.4.3 在函数中对序列进行解包
基础知识:
collections.abc模块中的Iterable表示可迭代的类型(可以进行遍历的类型)。- 实现思路:
- 函数开始时先判断函数调用时传进来的是否是一个序列:
- 若是一个序列,则可变参数args为(seq, ),故args[0]为一个可迭代的序列,此时需要把序列提出来,即args = seq。
- 若不是序列,则可变参数args为(data1, data2, ……),因此可以直接进行计算,不需要处理。
- 对基本数据处理完成之后,就可以实现之后的业务逻辑了。
- 函数开始时先判断函数调用时传进来的是否是一个序列:
示例:求数据中的最大值,要求可以接收散数据和序列数据。 ```python def get_max(*args):
先判断函数调用时传进来的是否是一个序列并进行相应的处理。
from collections.abc import Iterable if len(args) == 1 and isinstance(args[0], Iterable):
args = args[0]
求数据最大值的业务逻辑代码。
max_value = args[0] # 假设第一个数据是最大的 for i in args[1:]: # 从第二个数据开始遍历,若发现还要大的数据,则进行替换
if i > max_value:max_value = i
return max_value # 最后将最大的数据返回
print(get_max(28, 33, 45, 62, 18, 49)) # 62 print(get_max([28, 33, 45, 62, 18, 49])) # 62
<a name="BnC6L"></a>#### 3.4.4 双星表达式- 根据参数传值有位置参数(形参实参位置一一对应进行传值)和关键字参数(形参名=值)两种方式。- 位置参数对应的可变参数就前面介绍的普通单星号表达式,而关键字参数对应的可变参数则是双星号表达式。- 示例:虽然test()函数没有参数a、‘b、c,但是以关键字的形式依旧可以将值传进去。这些参数就由双星表达式`**kwargs`所接收,并将所有的数据都封装成了一个字典。```pythondef test(**kwargs):return kwargsprint(test(a=10, b=20, c=30)) # {'a': 10, 'b': 20, 'c': 30}
- 一个函数在调用时很有可能同时有多个位置传值参数以及多个关键字参数,因此Python支持同时声明单星号和双星号表达式。 ```python def test(args, *kwargs): print(args) print(kwargs)
test(1, 2, 3, 4, a=10, b=20, c=30, d=40) “”” (1, 2, 3, 4) # 由单星号表达式args所接收。 {‘a’: 10, ‘b’: 20, ‘c’: 30, ‘d’: 40} # 由双星号表达式*kwargs所接收。 “””
<a name="JDvBM"></a>#### 3.4.5 双星表达式传入字典时的解包操作- 与单星号表达式一样,双星号表达式若接收的是一个字典,则也要进行解包操作。- 若有单星号表达式但不解包,则字典数据会作为单星号表达式元组中最后一个数据出现。- 若即没有单星号表达式又不解包,则会直接报错。```pythontest(1, 2, 3, 4, {'a': 10, 'b': 20, 'c': 30, 'd': 40})"""(1, 2, 3, 4, {'a': 10, 'b': 20, 'c': 30, 'd': 40}){}字典传递给了单星号表达式*args,双星号表达式**kwargs中没有获取到任何值。"""
在调用时可以直接对字典数据进行解包,单星号表达式使用单星号解包,双星号表达式则用双星号解包。
test(1, 2, 3, 4, **{'a': 10, 'b': 20, 'c': 30, 'd': 40})"""(1, 2, 3, 4){'a': 10, 'b': 20, 'c': 30, 'd': 40}"""
同样,也可以在函数中对这样的情况进行处理。 ```python
函数内解包
def test(args, *kwargs): if isinstance(args[-1], dict):
kwargs = args[-1]args = args[:-1]
print(args) print(kwargs)
test(1, 2, 3, 4, {‘a’: 10, ‘b’: 20, ‘c’: 30, ‘d’: 40}) “”” (1, 2, 3, 4) {‘a’: 10, ‘b’: 20, ‘c’: 30, ‘d’: 40} “””
<a name="k53tV"></a>#### 3.4.6 可变参数的声明规则与命名规范- 在声明函数时,位置参数的声明要在关键字参数之前;同样的,单星号表达式的声明也要在双星号表达式之前。- 虽然任何参数都只是一个标识符,可以在符合命名规则的前提下随便取名,但是Python习惯将单星号表达式声明为`*args`,将双星号表达式声明为`**kwargs`。<a name="QEh22"></a>## 04. 局部变量与全局变量<a name="o7uLY"></a>### 4.1 全局变量的概念- 全局变量就是直接定义在`.py`文件中的变量,其作用域是整个应用程序的任何位置。- 示例:在global_variable_test.py文件中声明一个变量。```python# 定义一个全局变量pi = 3.14# 在py文件内可以直接调用print(pi)# 在函数内可以调用def test():print(pi)# 在类中可以调用class Test:def class_test(self):print(pi)
- 另外,还可以在应用程序的其他
.py文件中使用这个变量。 ```python首先将全局变量pi所在.py文件作为模块导入到当前文件中来
import global_variable_test as gvt
通过模块调用全局变量pi
print(gvt.pi)
“”” 运行结果: 3.14 # 这个3.14是在导入global_variable_test模块时运行的global_variable_test.py中的print(pi)的结果。 3.14 # 这个3.13是当前文件第五行print(gvt.pi)运行的结果。 “””
<a name="OJKDr"></a>### 4.2 局部变量的概念<a name="WfvkF"></a>#### 4.2.1 局部变量的基本概念- 作用域:所谓作用域就是变量的作用范围,即一个变量在哪些地方有用,如全局变量的作用域就是整个应用程序。- Python中的函数代码块有自己独立的域场,在函数自身的域场中定义的变量就是局部变量(形参、函数内部定义的变量)。- 局部变量的作用域为函数体内部,出了函数体,该变量将没有任何意义。```pythondef show_e():e = 12.34print(e)show_e() # 12.34,函数内部可以访问并打印eprint(e) # NameError: name 'e' is not defined,说明出了函数体内存中并没有e这个变量。
4.2.2 定位查找变量的规则
- 在全局中使用变量,只会在全局中进行变量的定位与查找,因此4.2.1中代码的第7行
print(e)在全局中找不到变量e,故报错。 - 在函数中使用变量的时候,会先在函数自身的域场中定位查找变量;若找不到目标变量,则再到全局中进行查找,因此在函数内部既可以访问函数自己的局部变量,也可以访问全局变量。
总结:Python中定位查找变量会先从自身所在的域场开始,往大范围查找,但不会往比当前自身所在域场更小的范围中查找。即小域通大域,大域不通小域。
4.2.3 内存与数据的存储关系
内存的内部分为一些不同的区域,数据在不同区域中的形态与生命周期都是不同的。
- 方法区:方法区又可以细分为方法池、常量池和静态池。方法区整体的生命周期是数据从声明定义时开始产生,到程序运行结束时销毁。
- 方法池:用于存放程序中声明定义的函数和类结构。
- 常量池:用于存放字符串(又称字符串常量池)和
 这部分数值型数据(这部分数据准确来说应该是在缓存区中的)。
这部分数值型数据(这部分数据准确来说应该是在缓存区中的)。- 常量池中的这两部分数据有一个共同的特点:在数据使用时,会先去常量池中查找数据,若在常量池中成功查找到目标数据,则会将该数据在常量池中的地址返回到调用处,并不会再去创建一个相同的数据对象;若在常量池中没有找到目标数据,则会先在常量池中创建一个数据对象,然后再将该数据对象的地址返回到调用处进行赋值或运算操作,后续再要使用该数据时,就不需要再查找了,直接将常量池中的数据地址返回。
- 这样的特点好处在于:不会重复创建相同数据的对象,也不会缓存太多无用的数据,这两点好处都会节省内存空间。
- 静态池:用于存储全局变量和类属性。
堆:堆用来存放非字符串类型的数据对象以及非
[-5, 256]的数值对象。- 堆中的数据定义一次,就会产生一个新的数据对象,故即便是对象字面量相同,内存地址也不同。
- 堆采用引用计数的原则来管理内存空间。即堆会为地址引用设置一个计数器,地址被引用一次计数器就会进行+1,失去一个引用计数器就会进行-1,当计数器为0时,该数据对象就会在内存中被释放。
l1 = [1, 2, 3] # 引用计数器+1,为1。l2 = l1 # 引用计数器+1,为2。l1 = None # 引用计数器-1,为1l2 = None # 引用计数器-1,为0,此时列表[1, 2, 3]被释放
栈:用于存放局部变量和调用的函数。
代码部分一:
示例代码:
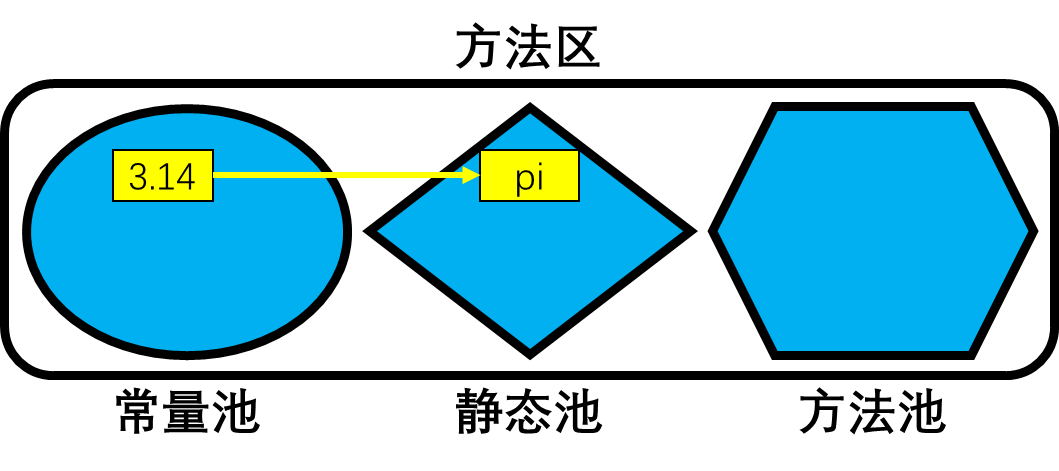
pi = 3.14print(pi)
内存结构分析:
- 3.14是
 范围内的数据,因此会被缓存到方法区常量池中,pi是全局变量,因此在方法区静态池中被创建并存储。
范围内的数据,因此会被缓存到方法区常量池中,pi是全局变量,因此在方法区静态池中被创建并存储。 - 当这两个结构在内存中被创建完成后,数据对象3.14的内存地址会被赋值给全局变量pi。
- 因此第二行代码
print(pi)可以正常执行。
- 3.14是
- 代码部分二:
- 示例代码: ```python def show_pi(): print(pi)
show_pi()
- 内存结构分析:- 当函数show_pi()被定义时,其结构会在方法区的方法池中被创建并存储。- 当函数show_pi()被调用时,方法池中show_pi()的结构会被复制并压栈到栈结构中,并开始运行show_pi()函数。- show_pi()函数在运行过程中,会现在自己的域场中查找变量pi,但很明显并没有这个变量,此时show_pi()函数会方法区静态池中查找全局变量。- 当show_pi()函数执行完成后,栈中的show_pi()会出栈(即函数结构会从栈中被删除),但是静态池中的全局变量pi和方法池中的show_pi()函数依旧存在。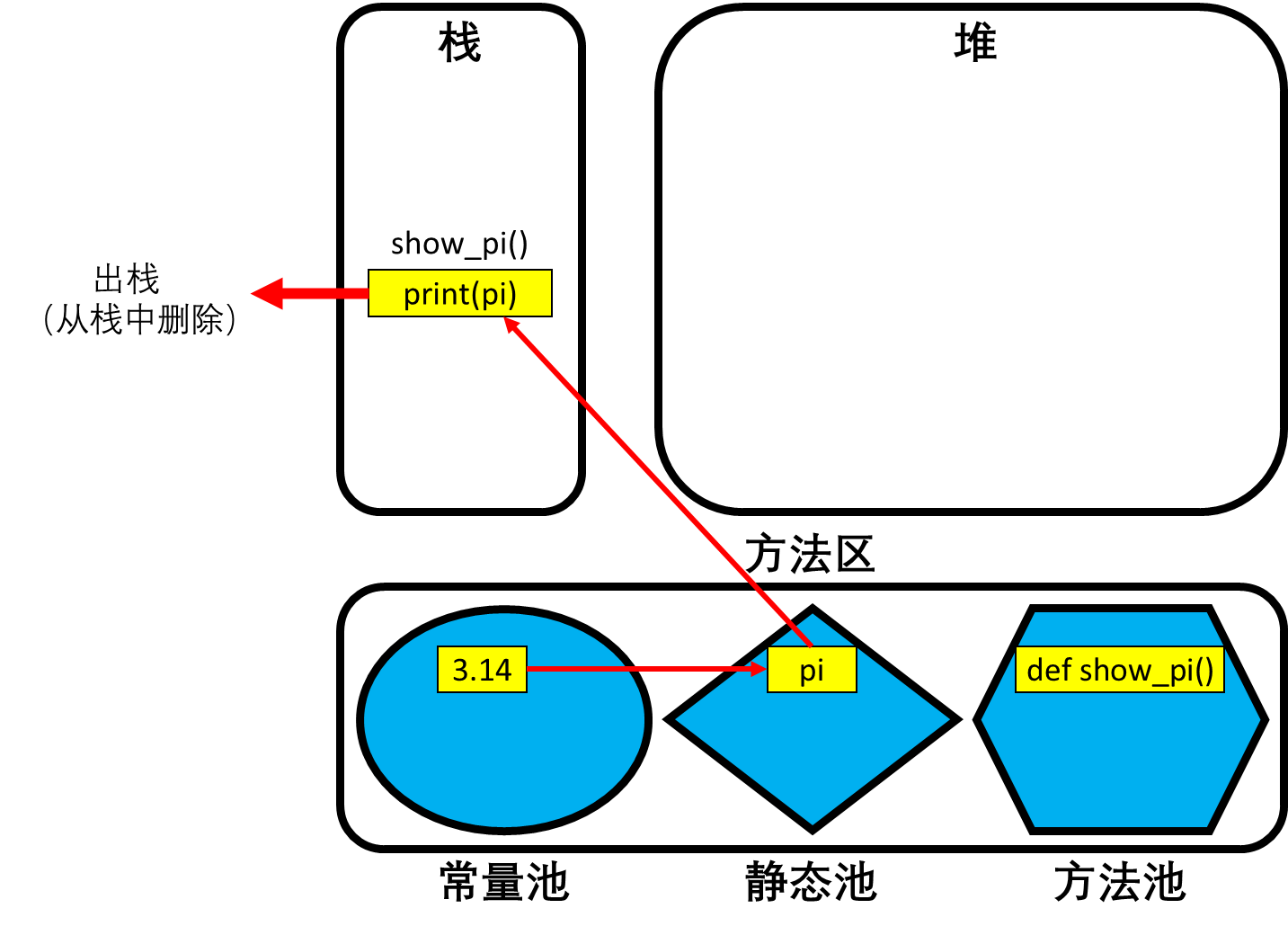- 代码部分三:- 示例代码:```pythondef show_e():e = 2.71print(e)show_e()print(e)
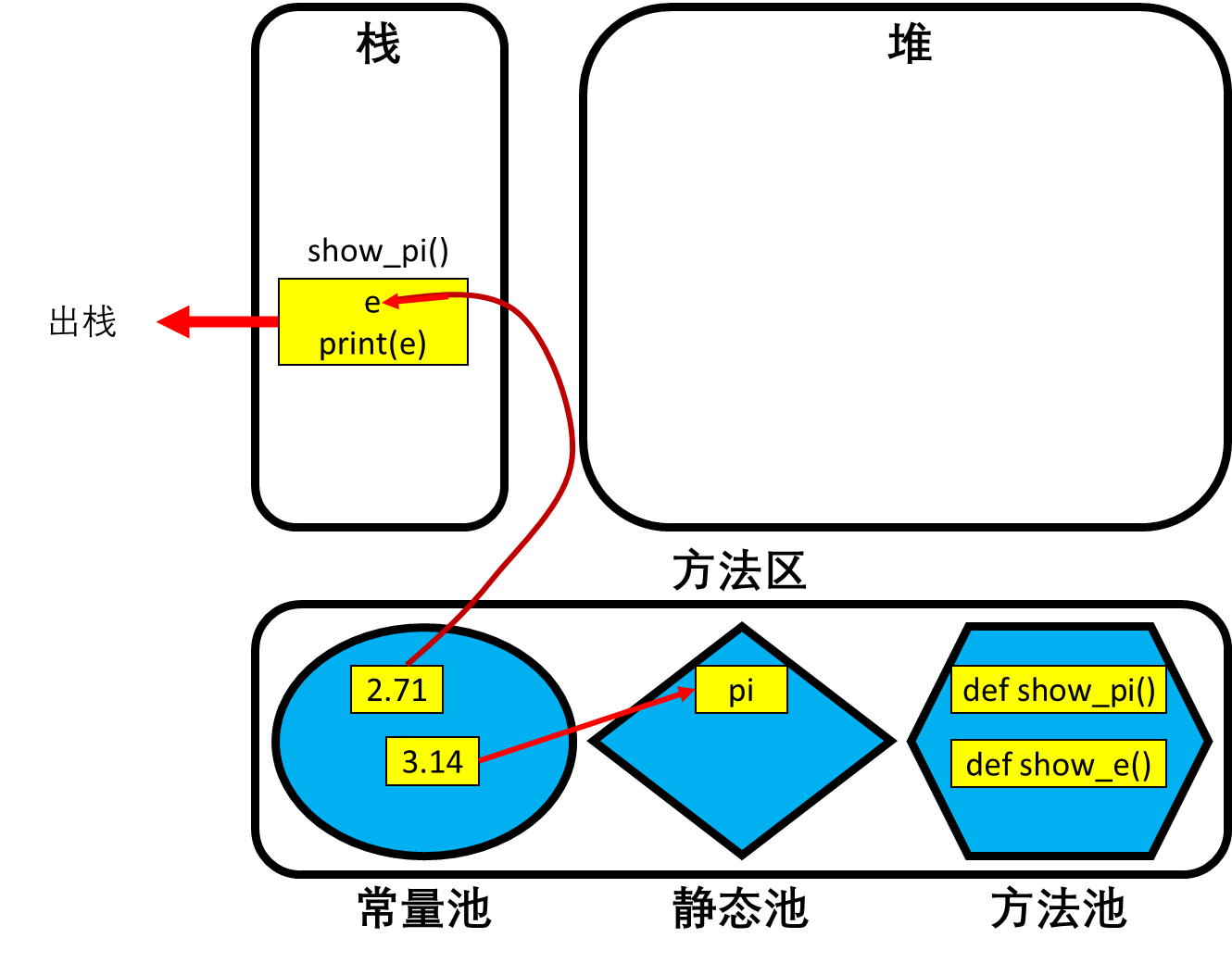
- 内存结构分析:
- 当函数show_e()被定义时,其结构会在方法区的方法池中被创建并存储。
- 当函数show_e()被调用时,方法池中show_e()的结构会被复制并压栈到栈结构中,并开始运行show_e()函数。
- show_e()函数在运行过程中,会在栈中(栈中,且是函数自己的域场中)创建变量e,并且2.71也是
 范围内的数据,故先在常量池中缓存2.71,再将数据地址赋值给栈中的变量e。
范围内的数据,故先在常量池中缓存2.71,再将数据地址赋值给栈中的变量e。 - 当show_e()函数要打印变量e时,在函数自己的域场中就直接找到了变量e,因此直接打印,不会再去全局中查找变量。
- 当打印完成后,show_e()函数整体运行结束,出栈(包含变量e在内的整个函数体都将被删除)。
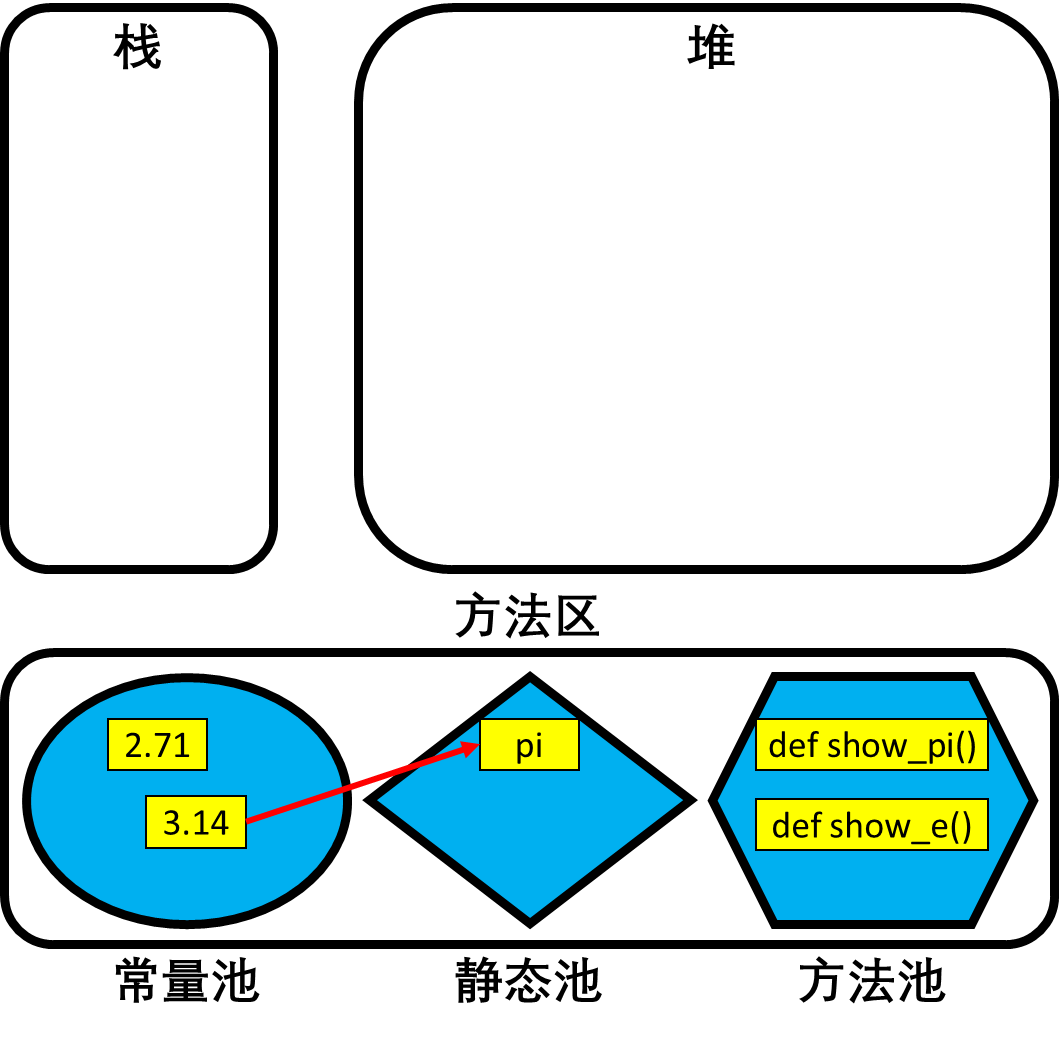
- 程序运行到这里,内存中的结构如下图所示。此时,虽然数据2.71还在常量池中,但是变量e已经不存在了。因此此时运行第六行代码`print(e)`将报错:`NameError: name 'e' is not defined`。
4.3.2 堆部分
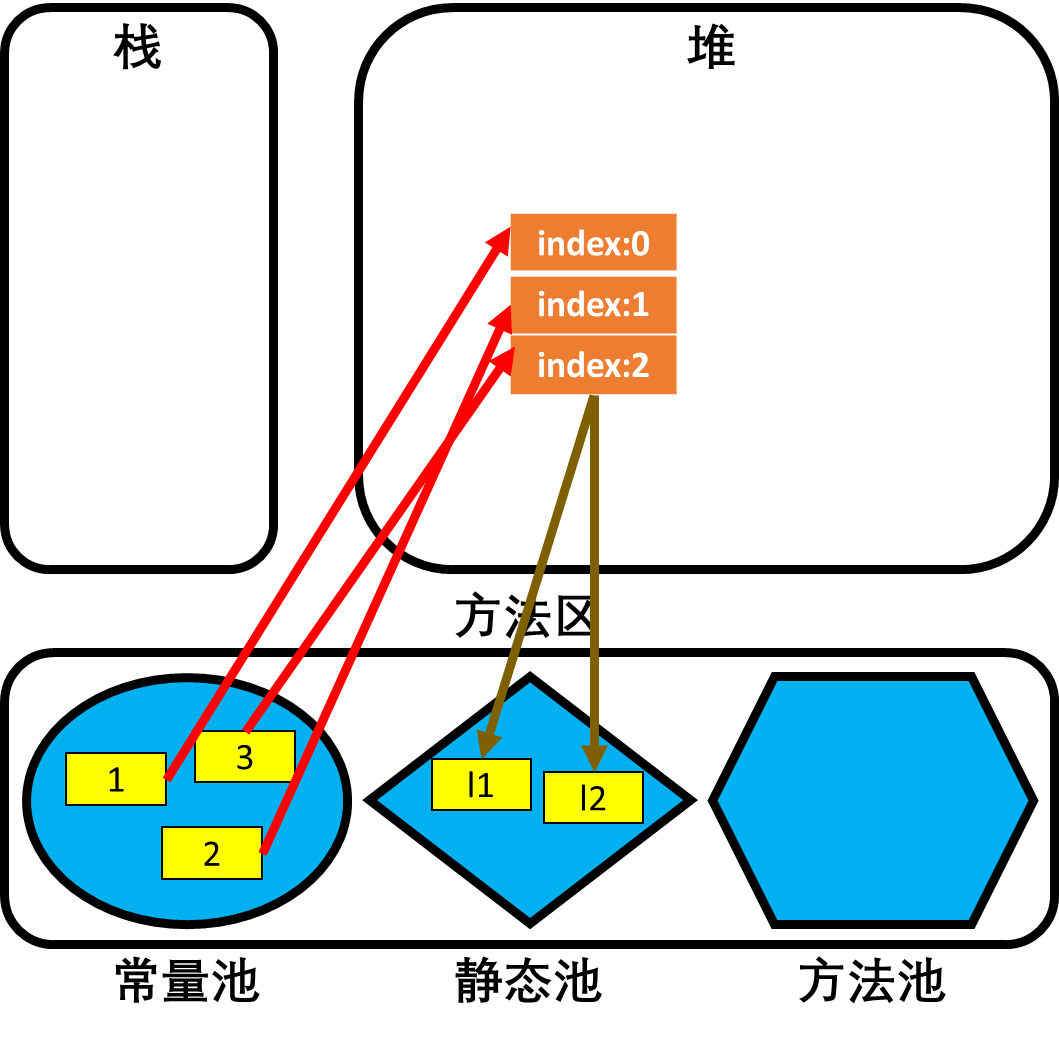
代码部分一:
示例代码:
l1 = [1, 2, 3]l2 = l1
内存结构分析:
- 首先列表中的三个元素1、2、3都是
 范围内的数据,因此会先被缓存到方法区常量池中。
范围内的数据,因此会先被缓存到方法区常量池中。 - 接着在堆中开辟三个连续的地址,并且按照索引值将常量池中数据的地址一一赋值。同时,列表是堆中的数据对象,在创建时会初始化地址引用计数器0。
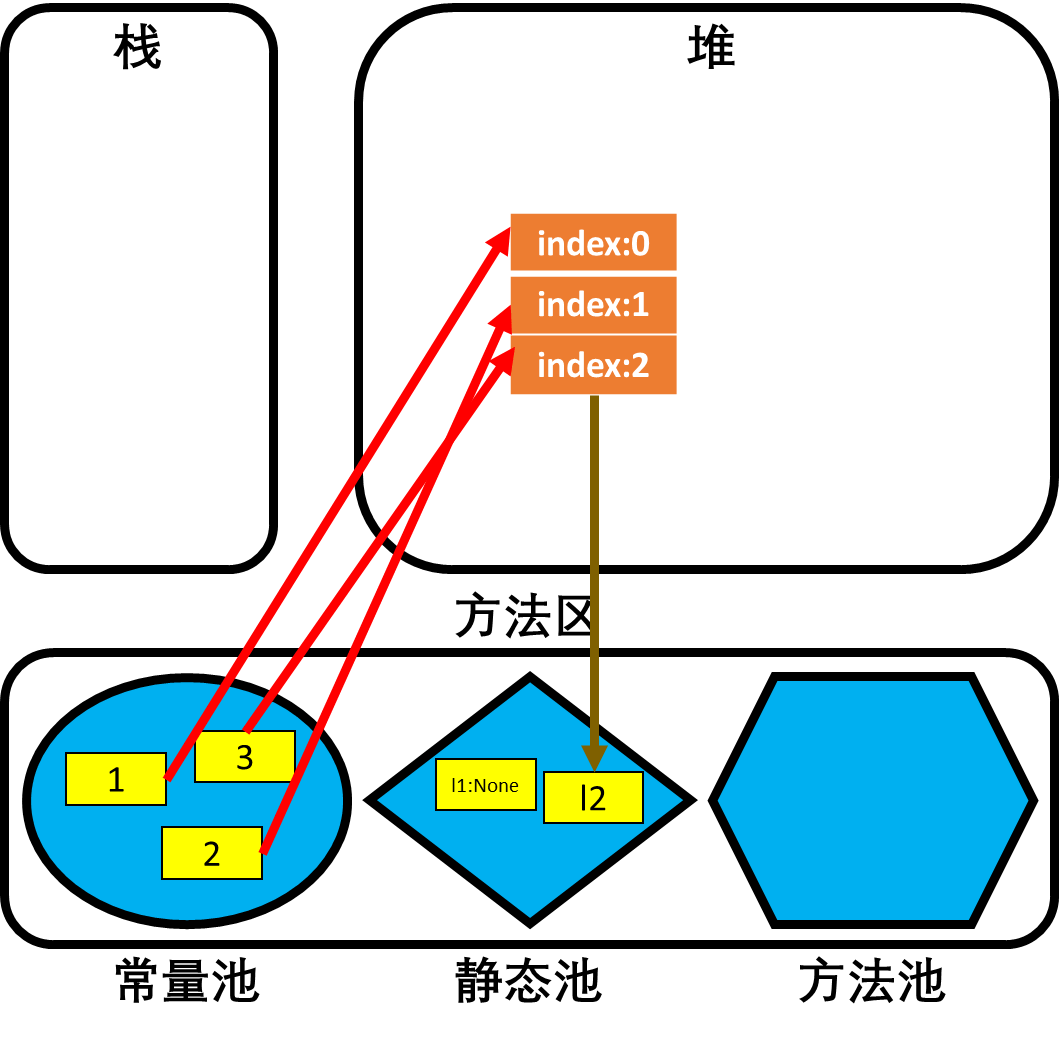
- 接着l1是全局变量,因此在方法区静态池中创建变量,并将堆中列表的地址赋值给l1,此时地址引用计数器会增1,为1。
- 最后再在静态池中创建一个全局变量l2,并将l1指向的列表地址赋值给l2,故此时l1和l2都指向这堆中的列表对象,且列表的地址引用计数器会再增1,为2。
- 首先列表中的三个元素1、2、3都是
代码部分二:
示例代码:
l1 = None
内存结构分析:当l1被赋值为None时,变量l1将不再指向堆中的列表地址,此时列表的地址引用计数器会减1,为1。
代码部分三:
示例代码:
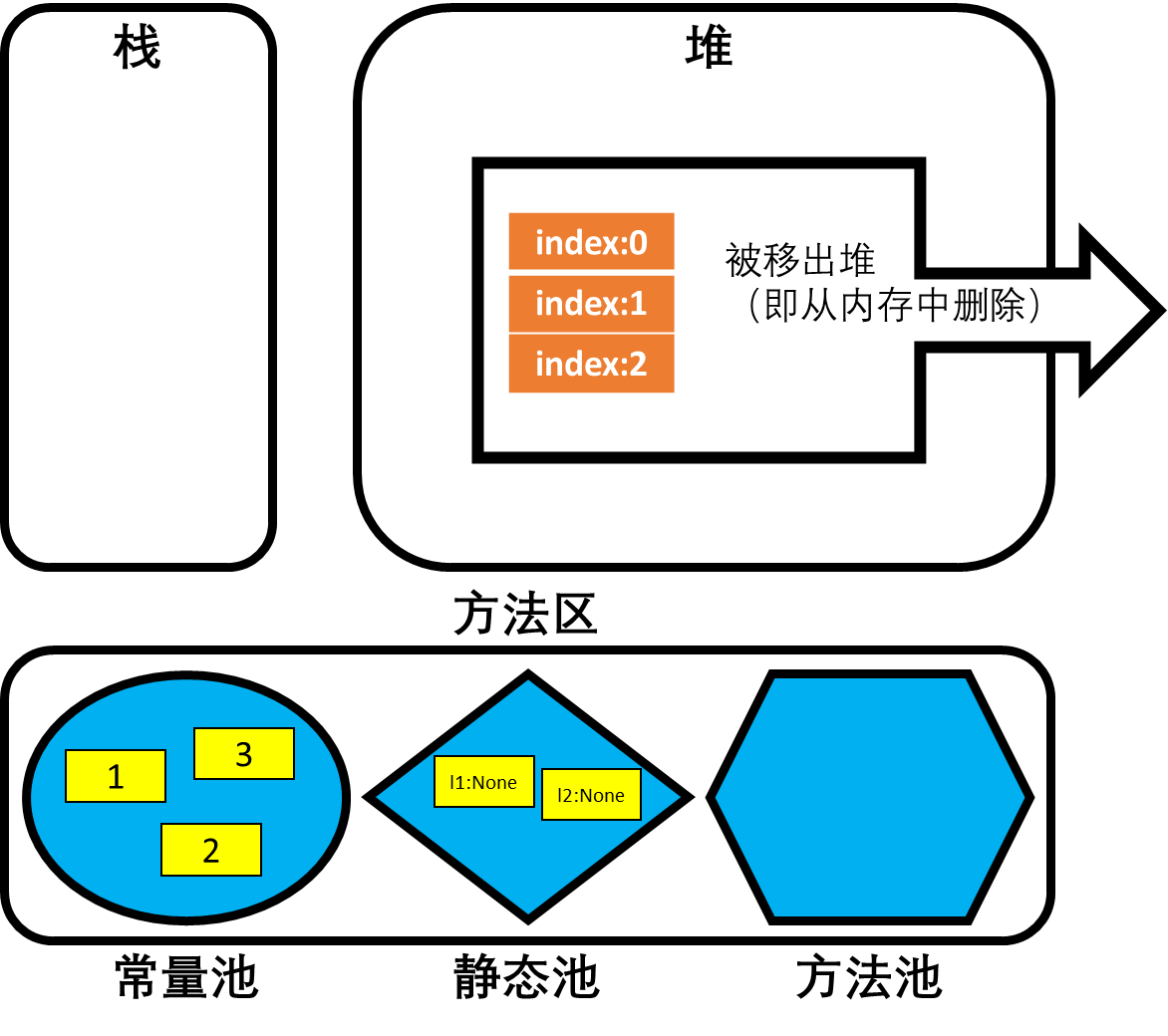
l2 = None
内存结构分析:当l2被赋值为None时,变量l2将也不再指向堆中的列表地址,此时列表的地址引用计数器会减1,为0,因此该列表对象将会从堆空间中被删除。
4.4 global关键字
- 正常来说,函数中定义的变量都是局部变量,并且函数中只能访问全局变量,不能对全局变量进行修改或定义。
- 示例:定义一个全局变量
name = "杜波",再定义一个change_name()函数,将全局变量name的值改为杜小波。 ```python name = “杜波”
def change_name(): name = “杜小波”
change_name() print(name) # 杜波
- 从函数的执行结果来看,全局变量name的值并未被改变,原因如下:- 第一行`name = "杜波"`会在常量池中缓存字符串“杜波”,然后在静态池中创建全局变量name,并将字符串“杜波”的地址赋值给全局变量name。- 接着就是在方法池中定义change_name()的函数结构。- 再然后第六行`change_name()`就将方法池中的函数结构压栈,并且在栈中创建函数的局部变量name(因为两个变量的作用域不同,所以不冲突)。然后先在常量池中缓存字符串“杜小波”,再将字符串“杜小波”的内存地址赋值给局部变量name。- 当函数change_name()执行完成后,会带着局部变量name一起出栈。- 因此整个过程下来,实际上change_name()函数操作的始终是局部变量name,并没有对全局变量name做任何改变。因此第七行`print(name)`的结果依旧是“杜波”。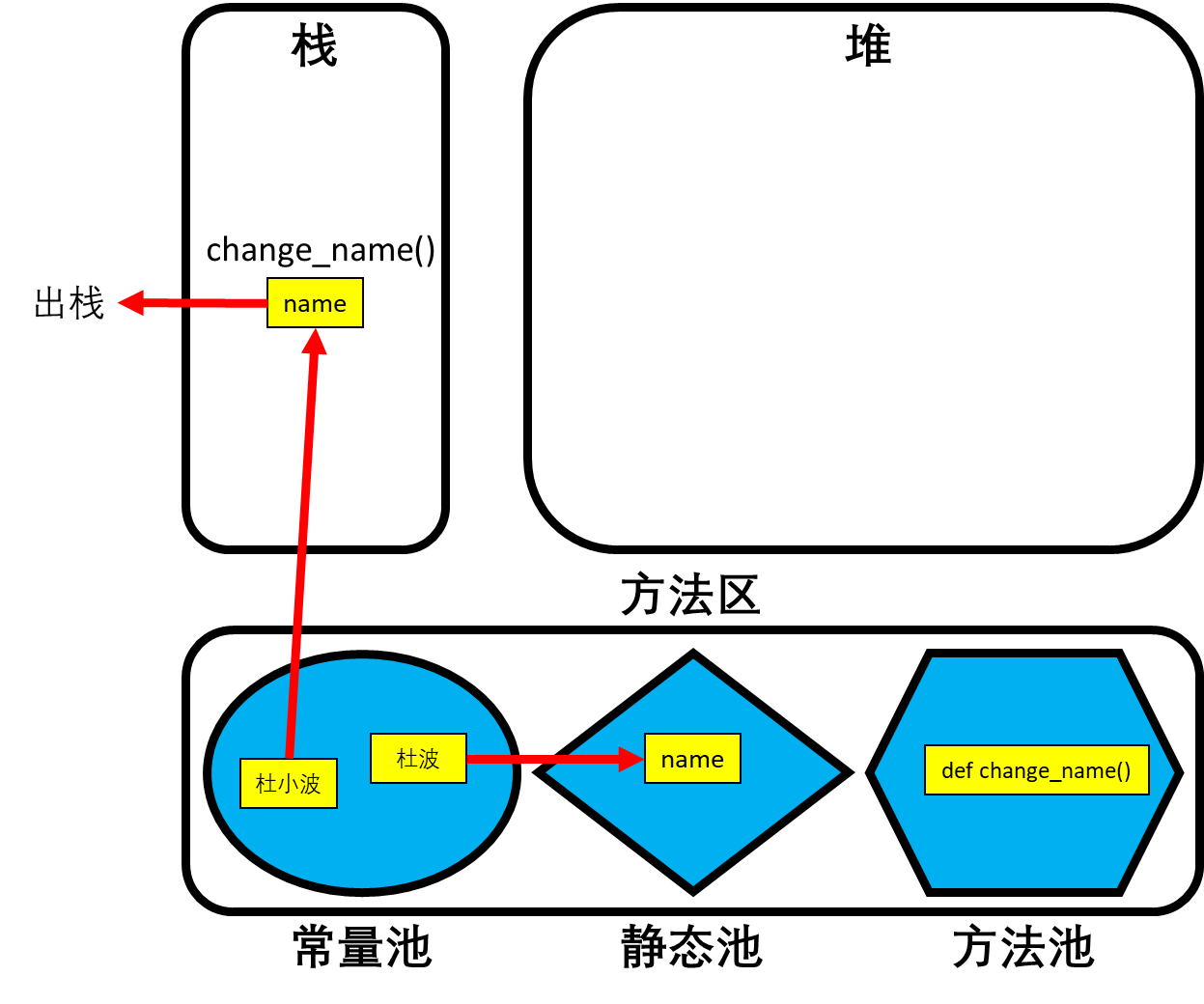- 但是有时候函数内部需要对全局变量进行修改或者定义,这时候就要用到`global`关键字。```pythonname = "杜波"def change_name_and_get_age():global name, age # 操作静态池中的全局变量name,并在静态池中定义一个新的全局变量age。name = "杜小波"age = 21change_name_and_get_age()print(name, age) # 杜小波 21

若有收获,就点个赞吧
0 人点赞
