- https://www.cnblogs.com/cx2016/p/12818527.html
2019 年年底,华为诺亚方舟实验室语音语义团队开源了 TinyBERT 模型,这是一个通过知识蒸馏方法获得的 BERT 模型。相比原版 BERT 模型,TinyBERT 体积小了 7.5 倍,推理速度则快了 9.4 倍。无论是在预训练阶段还是特定任务学习阶段,TinyBERT 的性能表现都好于之前的其他 Bert 压缩方法。TinyBERT 背后的模型压缩方法在技术上有哪些创新?模型压缩在实际部署时可能面临哪些挑战?模型压缩技术是否存在理论与应用间的脱节?针对这些问题,InfoQ 近期采访了华为诺亚方舟实验室研究员蒋欣,深入了解华为模型压缩技术的研究和实践进展,以及对于模型压缩技术现状与未来发展的思考。另外,蒋欣还将在 AICon 全球人工智能与机器学习技术大会(上海站)2020 带来主题为《华为预训练语言模型及小型化技术探索》的演讲分享,感兴趣的读者可以关注。">转 https://www.cnblogs.com/cx2016/p/12818527.html
2019 年年底,华为诺亚方舟实验室语音语义团队开源了 TinyBERT 模型,这是一个通过知识蒸馏方法获得的 BERT 模型。相比原版 BERT 模型,TinyBERT 体积小了 7.5 倍,推理速度则快了 9.4 倍。无论是在预训练阶段还是特定任务学习阶段,TinyBERT 的性能表现都好于之前的其他 Bert 压缩方法。TinyBERT 背后的模型压缩方法在技术上有哪些创新?模型压缩在实际部署时可能面临哪些挑战?模型压缩技术是否存在理论与应用间的脱节?针对这些问题,InfoQ 近期采访了华为诺亚方舟实验室研究员蒋欣,深入了解华为模型压缩技术的研究和实践进展,以及对于模型压缩技术现状与未来发展的思考。另外,蒋欣还将在 AICon 全球人工智能与机器学习技术大会(上海站)2020 带来主题为《华为预训练语言模型及小型化技术探索》的演讲分享,感兴趣的读者可以关注。 - 理解模型压缩
- 我们真的需要模型压缩吗?
- 华为的模型压缩技术探索和实践
- TinyBERT的创新点
华为诺亚方舟开源哪吒、TinyBERT模型,可直接下载使用。
项目地址:https://github.com/huawei-noah/Pretrained-Language-Model
BERT 的效果好,但是模型太大且速度慢,因此需要有一些模型压缩的方法。TinyBERT 是一种对 BERT 压缩后的模型,由华中科技和华为的研究人员提出。TinyBERT 主要用来模型蒸馏的方法进行压缩,在 GLUE 实验中可以保留 BERT-base 96% 的性能,但体积比 BERT 小了 7 倍,速度快了 9 倍。
转 https://www.cnblogs.com/cx2016/p/12818527.html
2019 年年底,华为诺亚方舟实验室语音语义团队开源了 TinyBERT 模型,这是一个通过知识蒸馏方法获得的 BERT 模型。相比原版 BERT 模型,TinyBERT 体积小了 7.5 倍,推理速度则快了 9.4 倍。无论是在预训练阶段还是特定任务学习阶段,TinyBERT 的性能表现都好于之前的其他 Bert 压缩方法。TinyBERT 背后的模型压缩方法在技术上有哪些创新?模型压缩在实际部署时可能面临哪些挑战?模型压缩技术是否存在理论与应用间的脱节?针对这些问题,InfoQ 近期采访了华为诺亚方舟实验室研究员蒋欣,深入了解华为模型压缩技术的研究和实践进展,以及对于模型压缩技术现状与未来发展的思考。另外,蒋欣还将在 AICon 全球人工智能与机器学习技术大会(上海站)2020 带来主题为《华为预训练语言模型及小型化技术探索》的演讲分享,感兴趣的读者可以关注。
理解模型压缩
神经网络模型的压缩技术并非新技术,它一直伴随着深度学习技术在发展,最早的神经网络压缩技术甚至可以追溯到上个世纪九十年代,那时候学术界就已经提出了对网络进行剪枝的工作(例如 Optimal Brain Damage 和 Optimal Brain Surgeon)。如今随着深度模型的普及,在实际应用的驱动下,模型压缩或者小型化技术的研究和工程实践越来越多。
所谓模型压缩,目标是在保证现有模型的性能和精度基本不变的前提下,尽可能地减少计算量、缩小模型的体积。
深度学习模型能够被压缩,本质上是因为参数的冗余,因此可以采用参数更少、结构更稀疏或者更低精度的运算来代替。但模型压缩技术并不总是能保持精度,特别是当压缩比很大的时候。事实上很多压缩后的模型相比大模型还是有明显的差距。蒋欣表示,模型的容量和精度之间一般存在一个 trade-off。以量化为例,有的时候二值化一个网络会导致精度损失很大,这时就需要考虑是否需要提高到三值化或者更高比特的量化。关键挑战就在于如何找到合适的小模型架构和精度,运用更好优化算法来进行小模型的学习。
目前业界主流的模型压缩及加速方法包括人工或自动的网络架构设计、剪枝、参数共享、低秩分解、量化、知识蒸馏等。不同的方法各有优劣势:
- 人工的网络结构设计通常是直接有效的,因为设计者会综合考虑模型的精度、大小、时延、功耗、更底层软硬件的适配等因素。不足之处在于一般只会考虑有限的领域(比如视觉)或网络(比如 CNN),其设计不一定能迁移到其他的领域或网络上。
- 自动网络设计(NAS)的技术相对更通用,很有前景,但目前无论在搜索空间设计、优化方法还是模型的评估上,都还需要持续的探索和改进。并且,搜索出来的网络结往往不如人工设计的那么规整,这对在硬件平台上的部署带来了挑战。最近也有研究表明,自动网络设计搜索出来的模型在泛化性能上有时会有欠缺。
- 量化是一种比较普适的方法,能显著降低模型的内存占用,但低比特量化通常会损失模型精度。同时,需要配合底层的软硬件设计,才能实现推理的加速。
- 剪枝的意义在于探索适合某种任务的稀疏的模型结构,非结构化的剪枝需要有底层支持才能够减少计算量,结构化稀疏则能在现有框架内直接使用并见效。
- 蒸馏是一种训练过程中使用迁移学习的通用方法,在很多情况下能够提升小模型的精度(相比于单独从头训练),但并不总是能够奏效(例如当老师模型和学生模型规模相差较大时)。蒸馏机制的理论还需要进一步探索。
上述方法在工业界均有应用,而且使用时通常会多种方法结合,而不是孤立地只是用某一种。除去模型架构设计,蒸馏和量化是华为诺亚方舟实验室 NLP 团队在工作中使用比较多的技术。
我们真的需要模型压缩吗?
很多人可能会产生疑问:模型压缩只是“大模型”的后续处理,并不能让我们玩转大模型,为什么我们不能直接训练出一个效果好的小模型?
蒋欣表示,有些模型压缩方法的确是直接训练“小模型”(例如人工设计网络结构、一些低秩分解和量化的方法),但很多蒸馏、剪枝类的方法依赖于先训练一个大模型,再进行处理或训练得到小模型。其中可能有几个原因:
1)大模型容易训练,效果好。近年来一些关于神经网络过参数化(Over-parameterization)的理论表明,冗余参数无论对于优化还是最终模型的泛化性能都有帮助。而在实践中,直接训练小模型的效果通常不够好,这可能与没有找到合适的优化方法有关;
2)小模型的结构无法预先确定,通过从大模型剪枝或者使用神经架构搜索(NAS)的方法才能确定。当然,这方面的研究还在继续,也许大模型并不总是必要,寻找到合适的小模型结构以及训练方法可能才是关键。例如,ICLR 2019 的一篇论文“Rethinking the Value of Network Pruning”中表明,在计算机视觉的一些任务中,对同样的结构,直接训练出的小模型并不比通过从大模型剪枝得到的小模型效果差。
当前模型压缩技术仍是机器学习、机器视觉、自然语言处理等领域重点关注的方向之一。在蒋欣看来,大规模模型和边缘计算都是未来的趋势,深度学习模型在各种边缘设备上的落地,离不开模型压缩技术。随着深度学习模型规模以及能力的不断增长,目前最大的模型参数量已经突破百亿,但部署这样的模型成本很高。所以大模型和小模型一定会长期并存,模型压缩技术作为连接他们之间的桥梁,会是非常重要的技术方向。
模型压缩和加速技术也已经在工业界广泛落地,目前主流的深度学习平台(如 TensorFlow)都提供了不同程度的支持,也出现了很多开源的跨平台深度推理框架(如 Tensorflow Lite、百度的 Paddle Lite、腾讯的 NCNN、阿里的 MNN、华为的 Bolt 等)。
华为的模型压缩技术探索和实践
华为诺亚方舟实验室在几年前就开始研究模型小型化技术。和业界一样,先从计算视觉领域的模型和应用入手,迄今为止已经做出了很多有影响力的工作,如最近的在 CVPR 2020 上发表的 GhostNet 和 AdderNet,就是探索计算高效的视觉网络。在自然语言处理领域,预训练语言模型 BERT 于 2018 年底发表,华为诺亚方舟实验室 NLP 团队随后开始了预训练模型的压缩研究,并于去年推出了 TinyBERT 模型。
TinyBERT 是知识蒸馏技术在预训练语言模型压缩上的应用,技术创新之处在于:1)注意力蒸馏机制,使得学生模型能更好地模拟老师的推理过程;2)预训练和微调两个阶段的蒸馏,并在微调阶段加入数据增强的机制。
面向 Transformer 的蒸馏
现有的预训练语言模型大多基于 Transformer 结构,蒋欣团队提出了一种新的面向 Transformer 的知识蒸馏算法。通过均匀选层的策略,新的蒸馏算法从老师模型中选择若干层与学生模型各层进行相对应的知识蒸馏(如下图 a)。面向 Transformer 结构的蒸馏综合考虑了不同类型层,包括嵌入层 Embedding Layer、转换层 Transformer Layer 和预测层 Prediction Layer。其中 Transformer 层的蒸馏尤其关键,其包含了基于注意力矩阵和基于隐状态的蒸馏(如下图 b)。通过这种新的蒸馏算法,原始的老师 BERT 模型中编码的大量知识可以有效地迁移到学生 TinyBERT 模型中去。另一方面,在学生模型构建上,TinyBERT 在深度(层数)和宽度(隐状态维度)的选择相比之前蒸馏算法会更加灵活。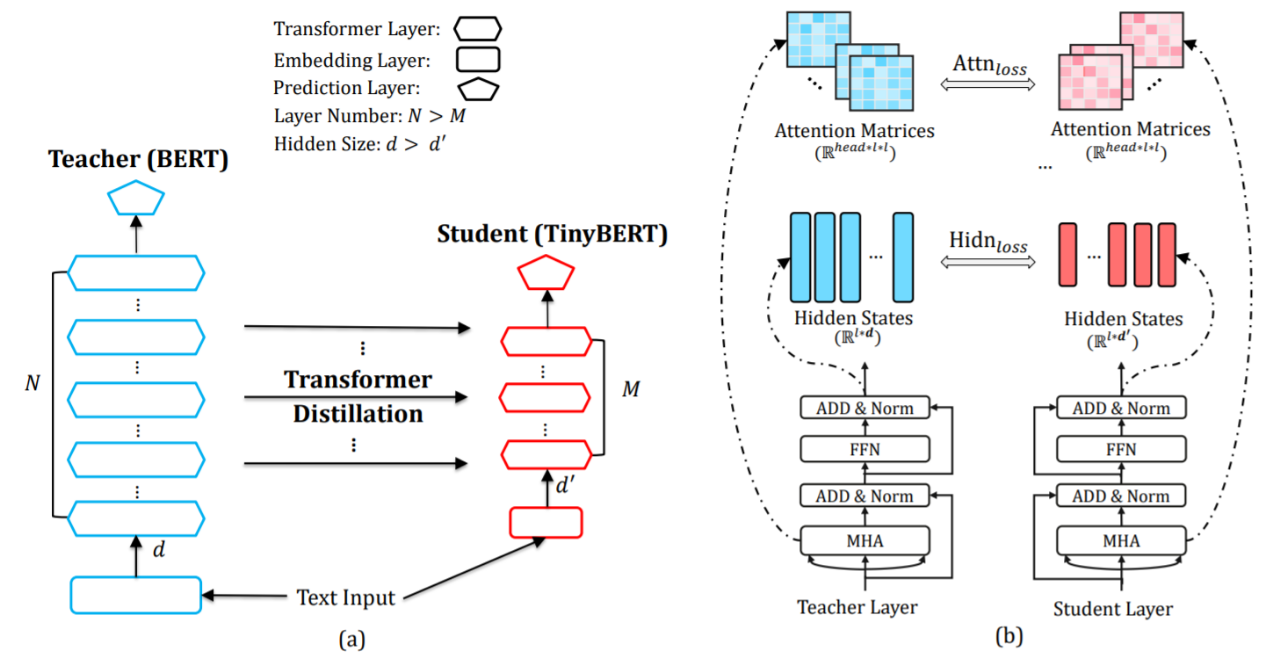
两阶段知识蒸馏
为了充分迁移老师模型的语义知识,TinyBERT 学习包含通用性蒸馏(general distillation)和任务相关性蒸馏(task-specific distillation)两个阶段,分别在预训练学习阶段和任务学习阶段执行面向 Transformer 的蒸馏算法(如下图)。通用性蒸馏阶段使用预训练得到的 BERT-base 为老师模型,在大规模文本语料上进行知识蒸馏得到通用性的 TinyBERT。此阶段的蒸馏让 TinyBERT 学习到丰富的语义知识,提升了小模型的泛化能力。任务相关蒸馏阶段使用在任务数据上微调好的 BERT-base 模型作为老师,在增强的训练数据集上进行面向 transformer 的知识蒸馏算法,获得任务相关的 TinyBERT。在数据增强方面,提出了基于预训练语言模型 BERT 和词向量模型 GloVe 的词替换方法,让 TinyBERT 在更多的语料上学习,进一步提升其泛化能力。两阶段的蒸馏起到相互辅助的作用:通用性的蒸馏为任务相关性蒸馏提供了一个好的模型初始;通过学习任务相关的知识,任务相关性蒸馏可以进一步提升 TinyBERT 的效果。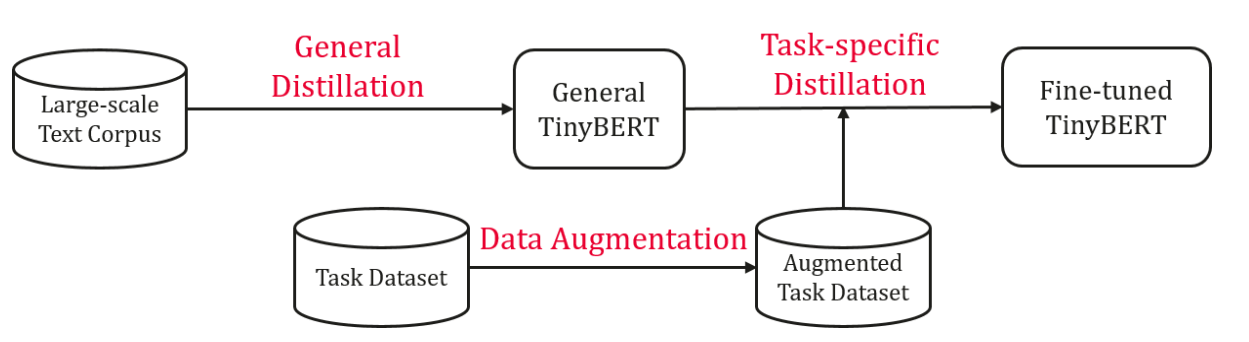
实验结果表明, TinyBERT 在只有原始 BERT 模型 13% 参数量的情况下,推断加速达到 9 倍,同时在自然语言处理标准评测 GLUE 上获得原始 BERT 模型 96% 的效果;另一方面,对比当前其他主流蒸馏方法,TinyBERT 在只有 28% 的参数和 31% 的推断时间情况下,平均提升 3 个点以上。
除了效果上的提升,TinyBERT 有多种规格,可以适应云侧和端侧的不同硬件平台(CPU/GPU/NPU)。配合诺亚自研的端侧推理平台 Bolt ,TinyBERT 在手机芯片上实现了进一步加速,在手机端侧的推理速度可以做到低于 5ms。TinyBERT 目前已经应用于华为手机的语音助手中,支持多种语言。
此外,华为诺亚方舟实验室还在不断拓展预训练模型压缩的更多可能性。例如最近推出了一种宽度和深度可伸缩的动态预训练模型 DynaBERT ,在该模型中,可以选择不同深度和宽度的子模型进行推理,可以达到“一次训练、多端部署”的效果。
模型压缩是工程问题
模型压缩本身就是为了解决超大模型在实际落地部署中遇到的问题而生,因此它更应该被看作一个工程问题,而非学术科研问题。但现阶段模型压缩技术的落地尚未达到“理想阶段”,引发了一些吐槽,有观点认为目前学术界对部分模型压缩的研究成果在实际场景中使用效果很差,因为很多方法没有考虑实际部署条件。当前在学术界和工业界之间,模型压缩技术是否存在理论与应用间的脱节?
对此蒋欣表示,学术研究中的一篇论文,可能只关注了某种方法的创新,以及在某个指标(例如模型大小)上的评估,确实可能会无法适配当前的硬件和计算架构。但他认为这并不是脱节,如果这个方法有足够的收益,那么可能会牵引未来的硬件设计,特别是 AI 专用硬件。当然,为了更好的牵引学术研究,工业界和学术界应该合作建立更加可信和全面的评估基准,使得研究成果能被公平和全面的验证。总体上,蒋欣认为模型压缩方向工业界和学术界的 gap 不算大,甚至好于其他很多领域。
当然,模型压缩从科研到落地仍然面临不少挑战:研究者需要对底层的计算软硬件有一定程度的了解,例如矩阵运算的机制、不同操作的功耗等;在实际场景部署时,需要熟悉部署设备的计算架构,才能进行充分的优化。只有算法团队与熟悉深度学习模型和压缩方法的硬件和系统工程团队共同合作,才能使得模型落地变得容易。
TinyBERT的创新点
新型蒸馏方式
不同于普通的知识蒸馏(knowledge distillation,KD)方法只针对输出层logits的soft label进行student模型的学习,TinyBERT应用的KD方法还对embedding层、每个transformer layer中的多头注意力层、以及每个transformer layer输出的hidden states和最后一层预测层这四部分进行蒸馏。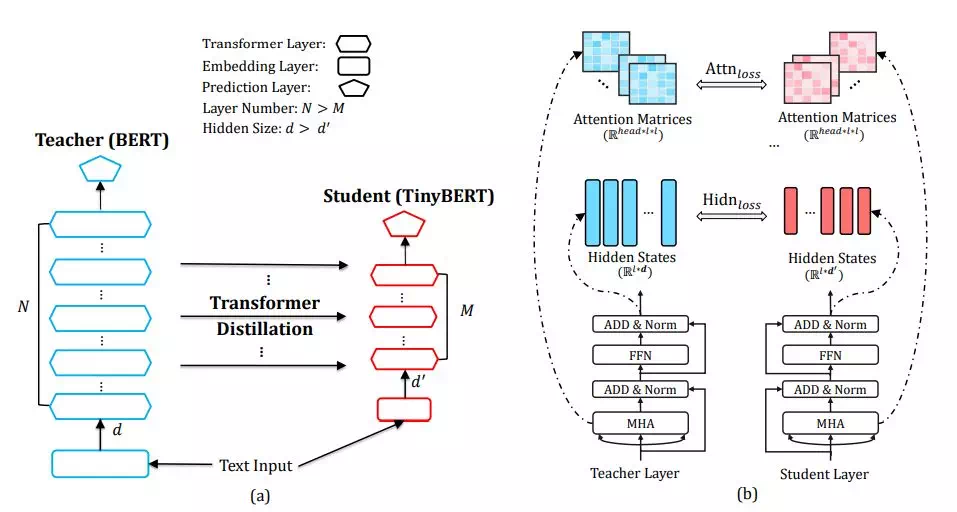
TinyBERT蒸馏概览
通过以上几个蒸馏目标,可以整合 teacher 和 student 网络之间对应层的蒸馏损失(具体每个目标的loss见转载原文):
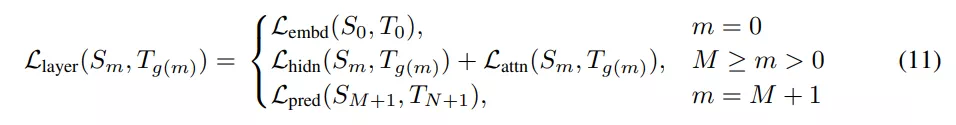
两段式学习框架
BERT 的应用通常包含两个学习阶段:预训练和微调。BERT 在预训练阶段学到的大量知识非常重要,并且迁移的时候也应该包含在内。因此,研究者提出了一个两段式学习框架,包含通用蒸馏和特定于任务的蒸馏,(说白了就是预训练阶段也进行蒸馏)如下图所示:
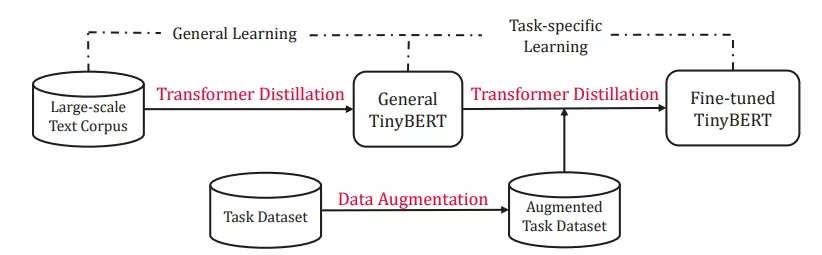
TinyBERT 的两段式学习图示
通用蒸馏可以帮助 student TinyBERT 学习到 teacher BERT 中嵌入的丰富知识,对于提升 TinyBERT 的泛化能力至关重要。特定于任务的蒸馏赋予 student 模型特定于任务的知识。这种两段式蒸馏可以缩小 teacher 和 student 模型之间的差距。
- 通用蒸馏。在通用蒸馏中,研究者使用原始 BERT 作为 teacher 模型,而且不对其进行微调,利用大规模文本语料库作为学习数据。通过在通用领域文本上执行 Transformer 蒸馏,他们获取了一个通用 TinyBERT,可以针对下游任务进行微调。然而,由于隐藏/嵌入层大小及层数显著降低,通用 TinyBERT 的表现不如 BERT。
- 针对特定任务的蒸馏。研究者提出通过针对特定任务的蒸馏来获得有竞争力的微调 TinyBERT 模型。而在蒸馏过程中,他们在针对特定任务的增强数据集上(如图 2 所示)重新执行了提出的 Transformer 蒸馏。具体而言,微调的 BERT 用作 teacher 模型,并提出以数据增强方法来扩展针对特定任务的训练集。
- 数据增强。使用BERT和Glove对句子序列进行词的替换,即通过BERT预测mask住的词,再使用Glove选择和这个词最相近的词(cosine similarity),进行替换,从而达到数据增强的目的。

若有收获,就点个赞吧
0 人点赞
