NLP任务主要分为两部分:
- 预训练(与之相关的便是 词向量和预训练模型)
- 具体下游任务(对词向量的运用,如分类,推荐等)
预训练简要发展历史
word2vec —> fasttext —> rnn —> lstm —> seq2seq —> encoder-decoder —> attention —> self attention —> transformer —> ELMo —> GPT —> bert —> GPT2.0 —> xNet
从word2vec到ELMo到BERT,做的其实主要是把下游具体NLP任务的活逐渐移到预训练产生词向量上。
- word2vec——>ELMo:
结果:上下文无关的static向量变成上下文相关的dynamic向量,比如苹果在不同语境vector不同。
操作:encoder操作转移到预训练产生词向量过程实现。
- ELMo——>BERT:
结果:训练出的word-level向量变成sentence-level的向量,下游具体NLP任务调用更方便,修正了ELMo模型的潜在问题,。
操作:使用句子级负采样获得句子表示/句对关系,Transformer模型代替LSTM提升表达和时间上的效率,masked LM解决“自己看到自己”的问题。
应用技术
另一方面是自然语言处理的应用技术,这些任务往往会依赖基础技术,包括文本聚类(Text Clustering)、文本分类(Text Classification)、文本摘要(Text abstract)、情感分析(sentiment analysis)、自动问答(Question Answering,QA)、机器翻译(machine translation, MT)、信息抽取(Information Extraction)、信息推荐(Information Recommendation)、信息检索(Information Retrieval,IR)等。
因为每一个任务都涉及的东西很多,因此在这里我简单总结介绍一下这些任务,等以后有时间(随着我的学习深入),再分专题详细总结各种技术。
- 文本分类:文本分类任务是根据给定文档的内容或主题,自动分配预先定义的类别标签。包括单标签分类和多标签文本分类,。
- 文本聚类:任务则是根据文档之间的内容或主题相似度,将文档集合划分成若干个子集,每个子集内部的文档相似度较高,而子集之间的相似度较低。
- 文本摘要:文本摘要任务是指通过对原文本进行压缩、提炼,为用户提供简明扼要的文字描述。
- 情感分析:情感分析任务是指利用计算机实现对文本数据的观点、情感、态度、情绪等的分析挖掘。
- 自动问答:自动问答是指利用计算机自动回答用户所提出的问题以满足用户知识需求的任务。
- 机器翻译:机器翻译是指利用计算机实现从一种自然语言到另外一种自然语言的自动翻译。被翻译的语言称为源语言(source language), 翻译到的语言称作目标语言(target language)。
- 信息抽取:信息抽取是指从非结构化/半结构化文本(如网页、新闻、论文文献、微博等)中提取指定类型的信息(如实体、属性、关系、事件、商品记录等),并通过信息归并、冗余消除和冲突消解等手段将非结构化文本转换为结构化信息的一项综合技术。
- 信息推荐:信息推荐据用户的习惯、 偏好或兴趣, 从不断到来的大规模信息中识别满足用户兴趣的信息的过程。
- 信息检索:信息检索是指将信息按一定的方式加以组织,并通过信息查找满足用户的信息需求的过程和技术。
下游任务使用预训练word embedding
问题是Word Embedding这种做法能算是预训练吗?这其实就是标准的预训练过程。要理解这一点要看看学会Word Embedding后下游任务是怎么用它的。
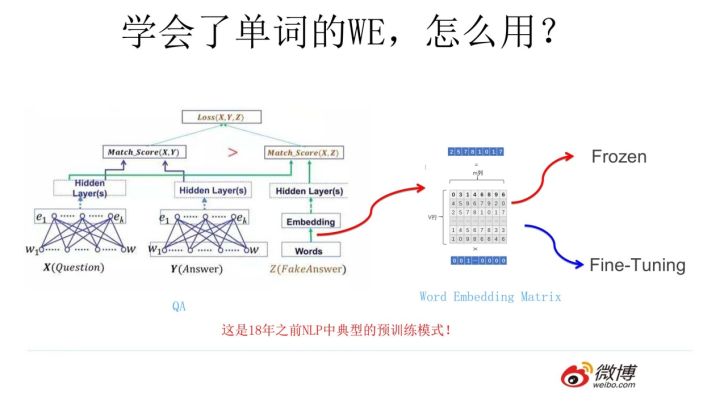
假设如上图所示,我们有个NLP的下游任务,比如QA,就是问答问题,所谓问答问题,指的是给定一个问题X,给定另外一个句子Y,要判断句子Y是否是问题X的正确答案。问答问题假设设计的网络结构如上图所示,这里不展开讲了,懂得自然懂,不懂的也没关系,因为这点对于本文主旨来说不关键,关键是网络如何使用训练好的Word Embedding的。它的使用方法其实和NNLM是一样的,句子中每个单词以Onehot形式作为输入,然后乘以学好的Word Embedding矩阵Q,就直接取出单词对应的Word Embedding了。这乍看上去好像是个查表操作,不像是预训练的做法是吧?其实不然,那个Word Embedding矩阵Q其实就是网络Onehot层到embedding层映射的网络参数矩阵。所以你看到了,使用Word Embedding等价于什么?等价于把Onehot层到embedding层的网络用预训练好的参数矩阵Q初始化了。这跟前面讲的图像领域的低层预训练过程其实是一样的,区别无非Word Embedding只能初始化第一层网络参数,再高层的参数就无能为力了。下游NLP任务在使用Word Embedding的时候也类似图像有两种做法,一种是Frozen,就是Word Embedding那层网络参数固定不动;另外一种是Fine-Tuning,就是Word Embedding这层参数使用新的训练集合训练也需要跟着训练过程更新掉。
上面这种做法就是18年之前NLP领域里面采用预训练的典型做法,之前说过,Word Embedding其实对于很多下游NLP任务是有帮助的,只是帮助没有大到闪瞎忘记戴墨镜的围观群众的双眼而已。那么新问题来了,为什么这样训练及使用Word Embedding的效果没有期待中那么好呢?答案很简单,因为Word Embedding有问题呗。这貌似是个比较弱智的答案,关键是Word Embedding存在什么问题?这其实是个好问题。

这片在Word Embedding头上笼罩了好几年的乌云是什么?是多义词问题。我们知道,多义词是自然语言中经常出现的现象,也是语言灵活性和高效性的一种体现。多义词对Word Embedding来说有什么负面影响?如上图所示,比如多义词Bank,有两个常用含义,但是Word Embedding在对bank这个单词进行编码的时候,是区分不开这两个含义的,因为它们尽管上下文环境中出现的单词不同,但是在用语言模型训练的时候,不论什么上下文的句子经过word2vec,都是预测相同的单词bank,而同一个单词占的是同一行的参数空间,这导致两种不同的上下文信息都会编码到相同的word embedding空间里去。所以word embedding无法区分多义词的不同语义,这就是它的一个比较严重的问题。
ELMO提供了一种简洁优雅的解决方案。后续就是开篇讲到的发展历史了。

若有收获,就点个赞吧
0 人点赞
