对于用户和商品而言:A和B两位用户的兴趣爱好很像,因此可以向A用户推荐B喜欢的东西。
问题在于,怎么确定A和B的兴趣爱好接近。 根据历史购物数据,用最近邻算法可以计算出。
1. 方法步骤
- 收集用户信息。
收集可以代表用户兴趣的信息。例如电影打分、是否举报邮件。
- 最近邻搜索
以用户为基础(User-based)的协同过滤的出发点是与用户兴趣爱好相同的另一组用户,就是计算两个用户的相似度。例如:查找n个和A有相似兴趣用户,把他们对M的评分作为A对M的评分预测。
基于用户的协同过滤算法首先要根据用户历史行为信息,寻找与新用户相似的其他用户;同时,根据这些相似用户对其他项的评价信息预测当前新用户可能喜欢的项。
给定用户评分数据矩阵R,基于用户的协同过滤算法需要定义相似度函数s:U×U→R,以计算用户之间的相似度,然后根据评分数据和相似矩阵计算推荐结果。
一般会根据数据的不同选择不同的算法,目前较多使用的相似度算法有Pearson Correlation Coefficient(皮尔逊相关系数)、Cosine-based Similarity(余弦相似度)、Adjusted Cosine Similarity(调整后的余弦相似度)。
1.1共现矩阵
共现矩阵是一个这样的矩阵,以所有用户为行,所有物品为列组成的矩阵,矩阵中的值是用户对物品的打分,这样的矩阵就叫做共现矩阵。
2. 选择合适的相似度计算方法
皮尔逊相关系数
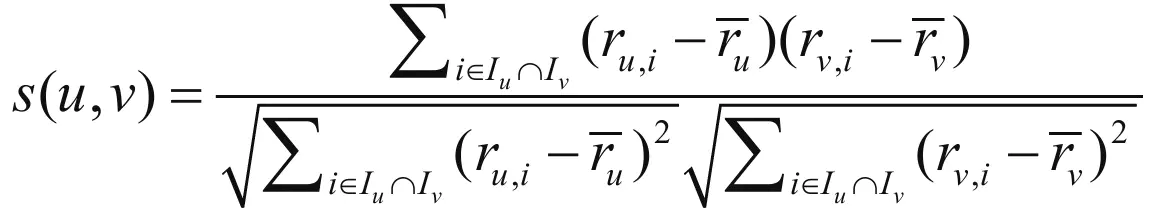
其中,i表示项,例如商品;Iu表示用户u评价的项集;Iv表示用户v评价的项集;ru,i表示用户u对项i的评分;rv,i表示用户v对项i的评分;表示用户u的平均评分;表示用户v的平均评分。
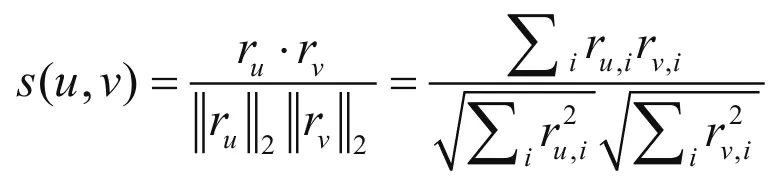
3. 计算用户u对未评分商品的预测分值
另一个重要的环节就是计算用户u对未评分商品的预测分值。首先根据上一步中的相似度计算,寻找用户u的邻居集N∈U,其中N表示邻居集,U表示用户集。然后,结合用户评分数据集,预测用户u对项i的评分,计算公式如下所示:
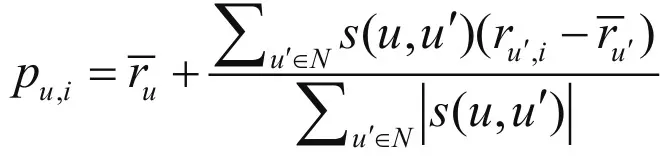
其中,s(u,u’)表示用户u和用户u’的相似度。
4. 例子
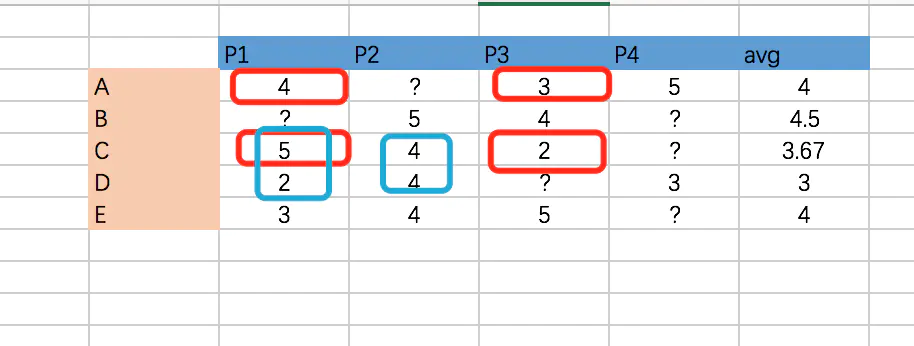
假设有如下电子商务评分数据集,预测用户C对商品4的评分。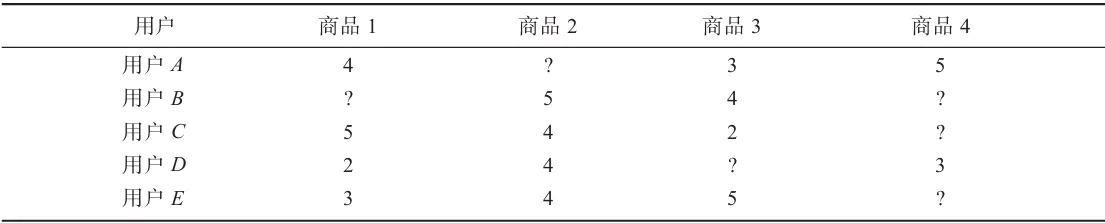
表中?表示评分未知。根据基于用户的协同过滤算法步骤,计算用户C对商品4的评分,其步骤如下所示。
(1)寻找用户C的邻居
从数据集中可以发现,只有用户A和用户D对商品4评过分,因此候选邻居只有2个,分别为用户A和用户D。用户A的平均评分为4,用户C的平均评分为3.667,用户D的平均评分为3。
<br />根据皮尔逊相关系数公式:<br />红色区域计算C用户与A用户,用户C和用户A的相似度为:<br /> 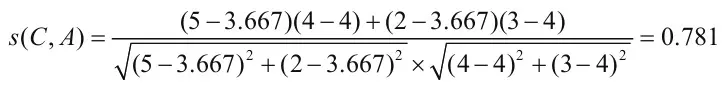
蓝色区域计算C用户与D 用户的相似度为:
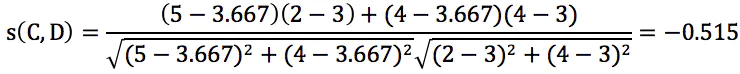
(2)预测用户C对商品4的评分
根据上述评分预测公式,计算用户C对商品4的评分,如下所示:
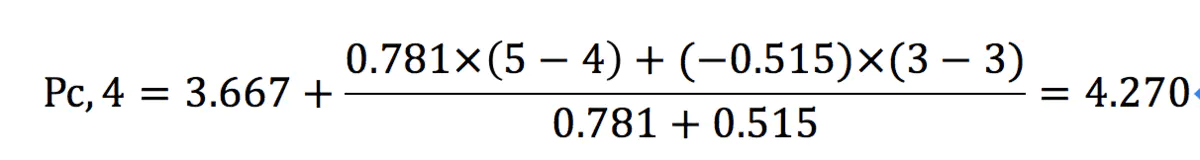
依此类推,可以计算出其他未知的评分。
5. 另一种算法
参考:https://www.jianshu.com/p/5b363c724f60
当数据集庞大时,使用 “物品—用户倒排表”
假设目前共有4个用户: A、B、C、D;共有5个物品:a、b、c、d、e。用户与物品的关系(用户喜欢物品)如下图所示:用户A喜欢物品a,b,d;用户B喜欢a,c;

物品—用户倒排表
如何一下子计算所有用户之间的相似度呢?为计算方便,通常首先需要建立“物品—用户”的倒排表,为什么需要用户-物品倒排表呢?因为当数据量巨大的时候,计算N个相似用户的时间将会非常长,但是其实我们可以预见到,数据库中的大部分用户其实和你是没有什么交集的,所没必要计算所有用户了,只需要计算和你有交集的用户就行了。
要计算和你有交集的用户,就要用到物品—用户倒排表,如下图,喜欢物品a的有用户A和B,喜欢物品b的有用户A与C……,由此可以看出,我们不用计算用户B与C的相似度,因为他们并没有交集:

然后对于每个物品,喜欢他的用户,两两之间相同物品加1。例如喜欢物品 a 的用户有 A 和 B,那么在矩阵中他们两两加1。如下图所示:
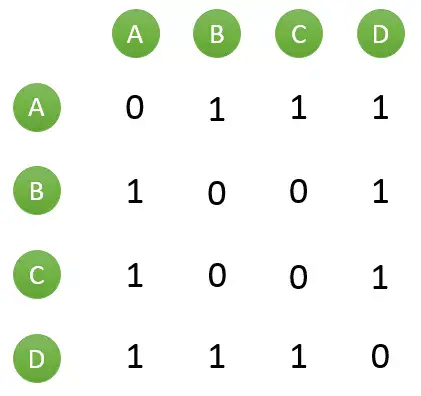
计算用户两两之间的相似度,上面的矩阵仅仅代表的是公式的分子部分。以余弦相似度为例,对上图进行进一步计算:
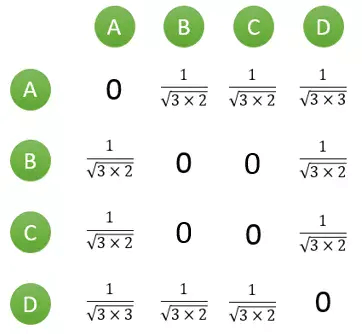
到此,计算用户相似度就大功告成,可以很直观的找到与目标用户兴趣较相似的用户。
推荐相似用户喜欢的物品:
首先需要从矩阵中找出与当前用户 u 最相似的 K 个用户,用集合 S(u, K) 表示,将 S 中用户喜欢的物品全部提取出来,并去除 u 已经喜欢的物品。对于每个候选物品 i ,用户 u 对它感兴趣的程度用如下公式计算: 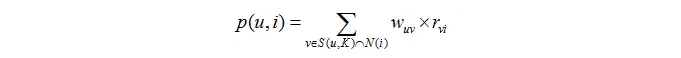
其中 rvi 表示用户 v 对 i 的喜欢程度,在本例中都是为 1,在一些需要用户给予评分的推荐系统中,则要代入用户评分。wuv是用户相似度。
举个例子,假设我们要给 A 推荐物品,选取 K = 3 个相似用户,相似用户则是:B、C、D,那么他们喜欢过并且 A 没有喜欢过的物品有:c、e,那么分别计算 p(A, c) 和 p(A, e):
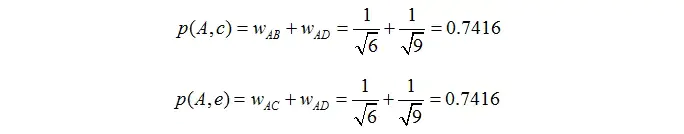
看样子用户 A 对 c 和 e 的喜欢程度可能是一样的,在真实的推荐系统中,只要按得分排序,取前几个物品就可以了。
总结一下,基于用户的协同过滤算法基本上分这么几步:
-计算其他用户和你的相似度,可以使用反排表忽略一部分用户
-根据相似度的高低找出K个与当前用户最相似的用户
-在这些相似用户喜欢的物品中,根据相似用户与当前用户的相似度算出每一件物品的推荐度
-根据每一件物品的推荐度高低给当前用户推荐物品。

若有收获,就点个赞吧
0 人点赞
