预训练语言模型的优势在于
- 近乎无限量的优质数据
- 无需人工标注
- 一次学习多次复用
- 学习到的表征可在多个任务中进行快速迁移
问题是如何利用这些预训练好的模型,Google们已经给我们提供巨人的肩膀了,那“梯子”在哪呢?我们怎么爬上去这些“巨人肩膀”?也就是如何使用这些预训练好的模型。一般来说,可以有三种方式来使用。它们分别是:
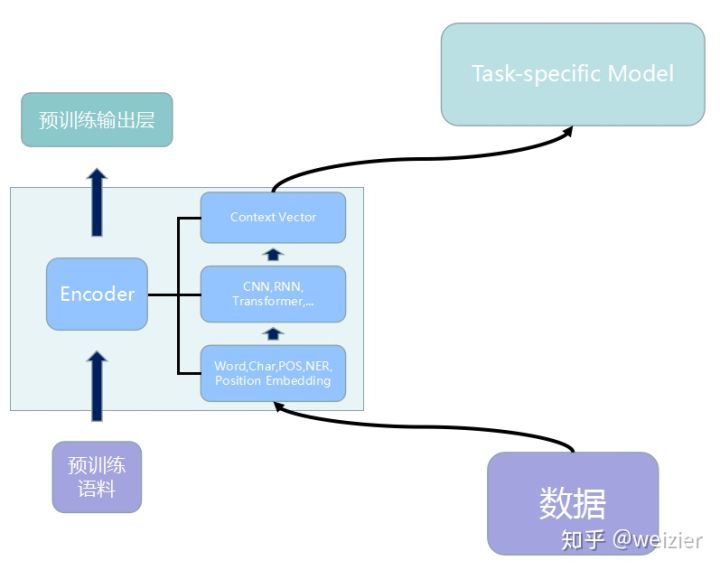
- 将预训练模型当做一个特征提取器,直接将预训练模型的输出层去掉,然后使用去掉输出层之后的最后一层输出作为特征输入到我们自己精心设计好的Task-specific模型中去,在训练过程中,作为特征提取器的部分(比如BERT Encoder)的参数是不变的。另外,特征提取器并不一定只能用最后一层的输出向量,也可以使用中间的某些层,甚至也可以借鉴ELMo的做法,在各层之间利用一个softmax来学习各自的权值,或者也可以尝试一些更为复杂的各层组合方式;
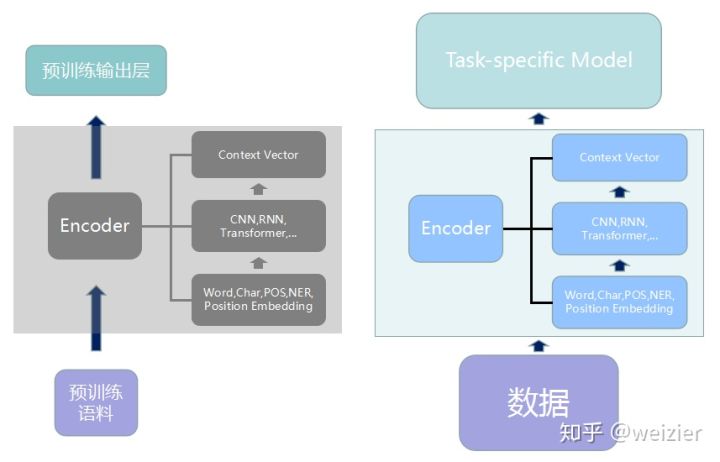
- 将预训练模型整体接入Task-specific模型,继而重新在新的数据集上整体重新训练,当然训练技巧可以有很多种,比如ULMFiT的三角学习率和逐层解冻或者是Transformer的warmup策略(上文都有提到),这些训练技巧非常重要,需要好好把控,否则很容易学崩了,甚至让原有预训练语言模型的优势都被新的finetune抹去了,因此需要实验设计一个比较好的finetune策略。此外,和特征提取器的接入方式类似,预训练模型的接入不一定只能接最后层的输出,可以尝试更复杂的接入方式,比如DenseNet;
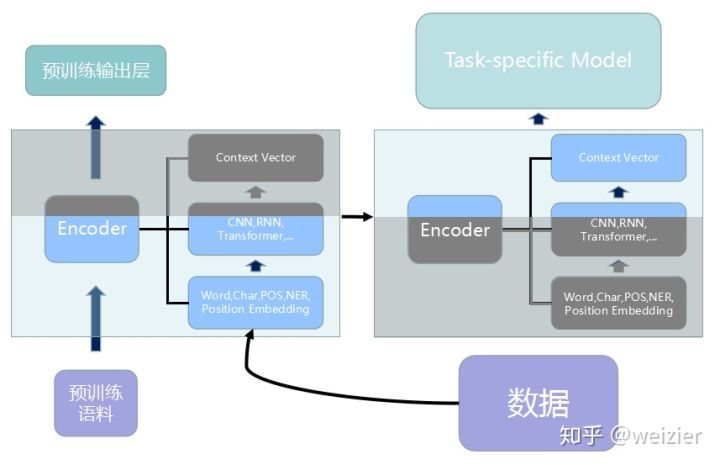
- 和上面两种极端情况相反,或者说综合了上面两种方式的方案,即保留预训练模型的一部分,另外一部分则和Task-specific模型一起finetune,在某些情况下,这可能是个比较合理的选择,比如预训练模型比较深(NLP模型通常来讲比CV模型都要浅很多),以及训练数据不算太多的情况,这个时候一方面要保证预训练模型在大规模语料上曾经学习到的表征,另一方面因为又要做新数据下的迁移,但是数据量比较少,重新finetune整个模型可能不太合适,容易导致模型的鲁棒性不高,那么似乎选择最后的一些层进行选择性的finetune会是比较好的方案。
上面这三种方案,既包括了BERT所言的feature-based使用方法, 也包括了BERT的finetune方法。另外GPT和BERT也给我们提供了很好的输入层与输出层通用包,再加上一些训练技巧,一般的NLP任务下应该是足够应付了。
然而,GPT和BERT即便刷新了十多项NLP任务,但似乎各自默契的都不曾尝试过在生成问题中大展身手,比如二者的主要征战沙场GLUE(General Language Understanding Evaluation)连名字中都直指这个“胶水”排行榜主要就是语言理解问题,除了GLUE外(GPT和BERT都去掉了GLUE的WNLI数据集,因此他们刷的GLUE是8个数据集),GPT额外刷过的数据集有4个:SNLI, SciTail, RACE和Stroy Cloze,其中SNLI和SciTail都是自然语言推断问题,本质上是一个句子级别的分类问题,RACE和Stroy Cloze是question answering或阅读理解式的问题,本质上可以认为分别是一个token级别的分类以及句子级别的打分排序问题;而BERT额外刷过的三个数据集中SQuAD本质上是一个token级别的分类问题,NER也是如此,SWAG则是从候选句子中选择正确的推断,是一个句子级别的打分排序问题。GPT刷了12项数据集(打破其中9项纪录),BERT刷了11项数据集(打破其中11项),然而无一例外的这些数据集全是Natural Language Understanding领域的问题,而对于NLP中另一个庞大领域Natural Language Generation,不约而同的选择了放弃,是未曾注意,还是选择视而不见,背后的原因我无从猜测。不过,无论GPT和BERT是什么原因没有选择在生成问题中去尝试,私以为,想要把GPT和BERT的预训练模型迁移到生成问题中,大约应该也不是一件非常困难的事情,首先GPT本质上就是一个生成模型(从其名字的Generative中就可以看出),而BERT虽然使用的是Encoder,但是把它改造成一个Decoder应该不是什么特别困难的事情,因为本质上Encoder和Decoder基本框架相同,只不过Decoder需要做好两件事情,第一件事情是Decoder中也有Self-attention层,和Encoder中的Self-attention不同的是,Decoder需要做好mask,以避免attention到未来待预测的词上去;第二件事情需要做的是Decoder中有一个交叉attention,以获取来自于Encoder侧的信息。但是,这里还涉及到Encoder-Decoder整体这种seq2seq的框架是否要保留的问题,如果使用GPT使用的T-DMCA这种仅用Decoder做生成问题的,那么改造相对会更易行,如果要保留Encoder-Decoder这种双结构,那么改造可能会相对复杂一些。
乐观一点,如果这种改造非常成功(似乎已经具备有充分的理由来相信这一点),那么NLP似乎会迎来一个阶段性的大一统时代:也就是一个基本模型做到一个闭环。其流程是:从文本到语义表征,再从语义表征重新生成文本。这样看来,至少在NLP领域(CV等其他AI领域,留给各位看官自行脑洞好了),未来大约还是很值得期待的一件事情。

若有收获,就点个赞吧
0 人点赞
