youtube推荐架构
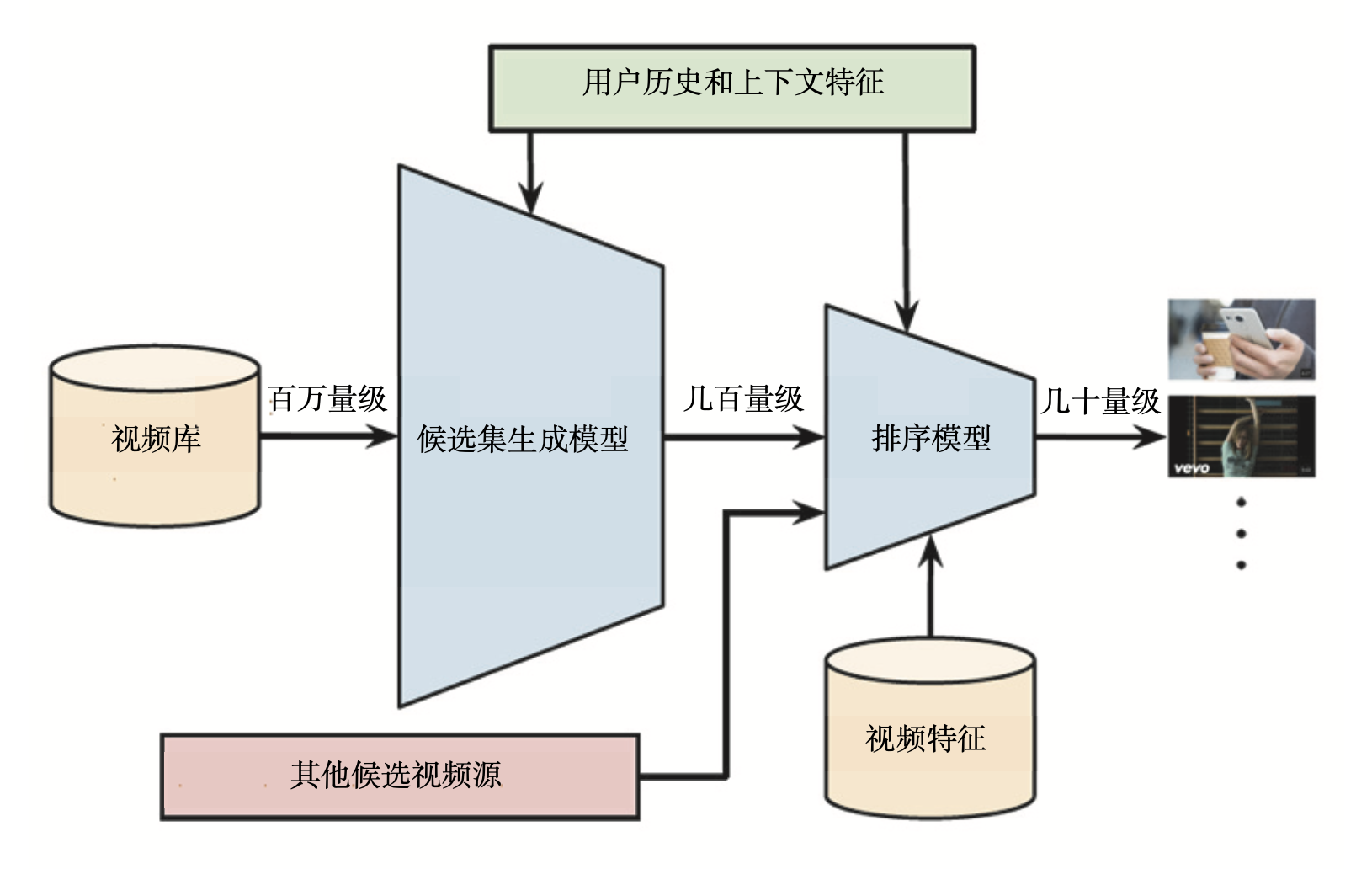
为了对海量的视频进行快速、准确的排序,YouTube 也采用了经典的召回层 + 排序层的两级推荐系统架构。
第一级是用候选集生成模型(Candidate Generation Model)完成候选视频的快速筛选。把候选视频集合从百万降到几百量级,这就相当于经典架构中的召回层。
第二级是用排序模型(Ranking Model)完成几百个候选视频的精排,这相当于经典架构中的排序层。
① 候选集生成模型
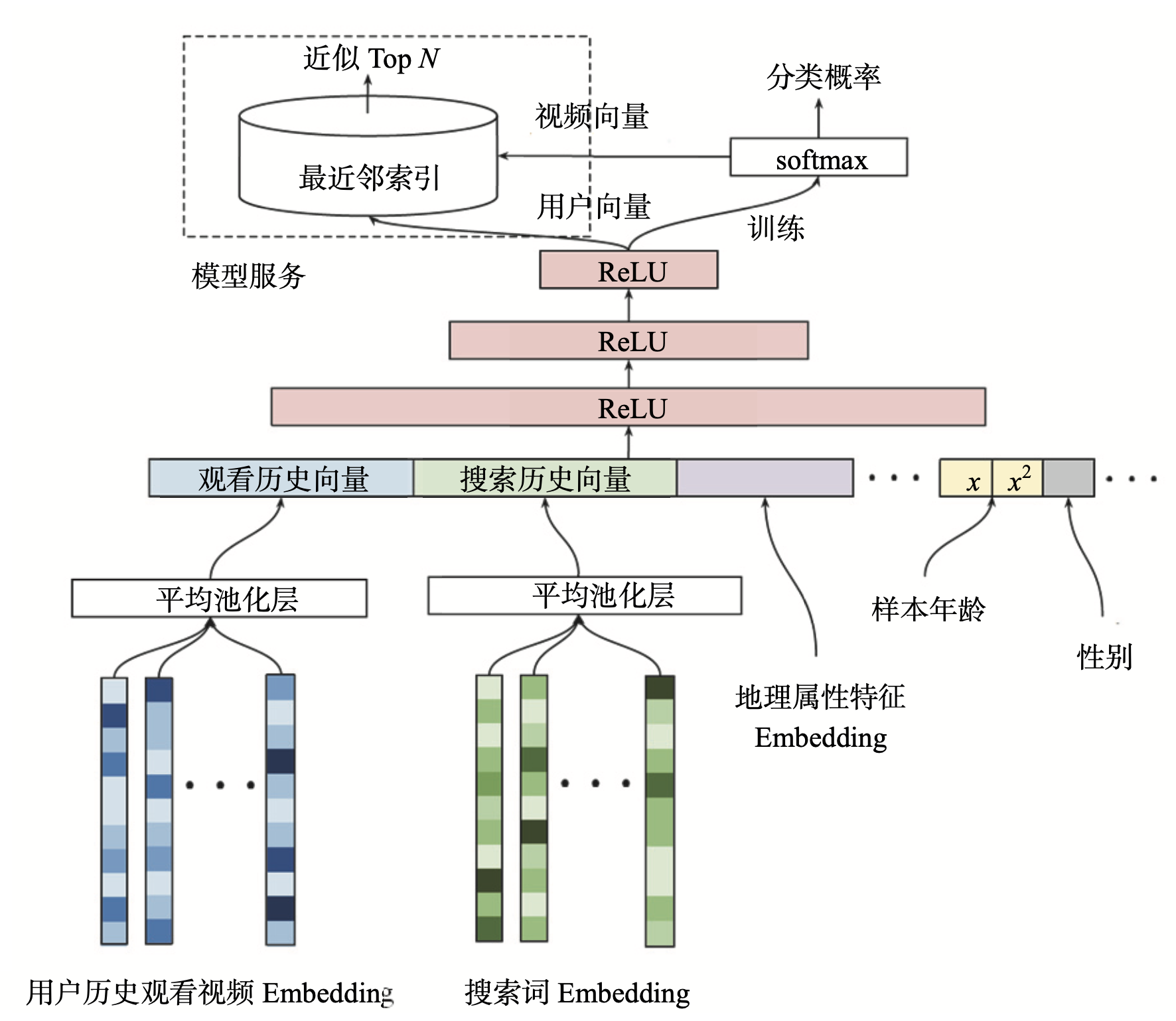
最底层是输入层,输入的特征包括用户历史观看视频的 Embedding 向量,以及搜索词的 Embedding 向量。YouTube利用用户的观看序列和搜索序列,采用Item2vec方法预训练生成Embedding(附录介绍item2vec)。当然也完全可以用 Embedding 跟模型在一起 End2End 训练的方式来训练模型。
除了视频和搜索词 Embedding 向量,特征向量中还包括用户的地理位置 Embedding、年龄、性别等特征。对于样本年龄这个特征,YouTube 不仅使用了原始特征值,还把经过平方处理的特征值也作为一个新的特征输入模型,这个操作是为了挖掘特性的非线性信息。这种对连续型特征的处理方式不仅限于平方,其他诸如开方、Log、指数等操作都可以用于挖掘特性的非线性信息。
所有特征使用concat连接起来后送入MLP进行训练,最后输出层使用softmax函数,预测的是用户会点击哪个视频。假设YouTube上有100万个视频,那么sofmax就有100万个输出,用于表示用户对所有视频的点击概率,因此模型的最终输出就是一个在所有候选视频上的概率分布。目的是为了更好、更快地进行线上服务。接下来看下线上服务是怎么做的。
② 候选集生成模型的线上服务方法
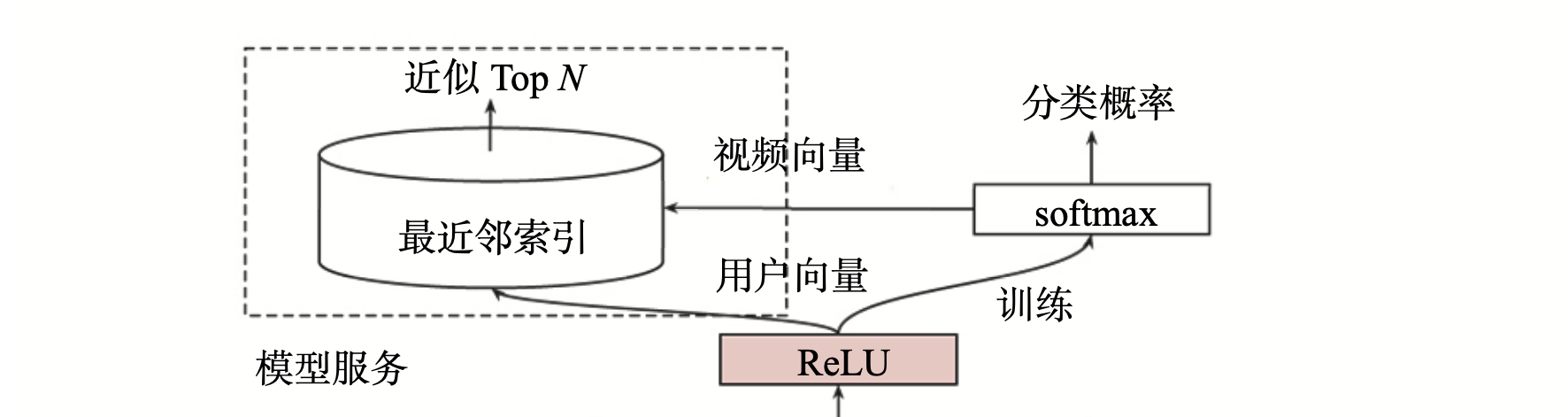
候选集生成模型架构图左上角的模型服务方法与实际的训练方法完全不同。在线上服务过程中,YouTube 并没有直接采用训练时的模型进行预测,而是采用了一种最近邻搜索的方法。为什么呢?
因为候选集生成模型可以得到全量的用户和视频的Embedding,服务时通过Embedding最近邻搜索的方法可以大大提高在线服务效率。因为只需要把所有的用户和视频Embedding存到特征数据库就行了。
视频Embedding是怎么得到的呢?架构图中从softmax向模型服务模块画了个箭头,用于代表视频 Embedding 向量的生成。此处的softmax层指的是激活函数是softmax的全连接层。全连接层的权重是m x n的矩阵,其中m指的是最后一层带ReLU激活函数的全连接层的权重维度,n指的是分类(YouTube所有视频)的总数。因此所有视频 Embedding就是这个m x n维矩阵的各列向量。这个思想参考的是Word2vec的词向量生成方法。
用户Embedding又是怎么得到的呢?因为输入的特征向量都是与用户相关的特征,一个物品和场景特征都没有,所以最后一层带ReLU层的输出向量就可以当作该用户u的Embedding向量。待模型训练完成后,逐个输入所有用户的特征向量,就得到了所有用户的Embedding向量,之后就可以预存到线上的特征数据库中了。
在预测某用户的视频候选集时,先从特征数据库中查询用户的 Embedding 向量,再在视频 Embedding 向量空间中,利用局部敏感哈希等方法搜索该用户 Embedding 向量的 K 近邻,这样就可以快速得到 K 个候选视频集合。这就是整个候选集生成模型的训练原理和服务过程。
③ 排序模型
通过候选集生成模型,已经得到了几百个候选视频的集合了,下一步就是利用排序模型进行精排序。
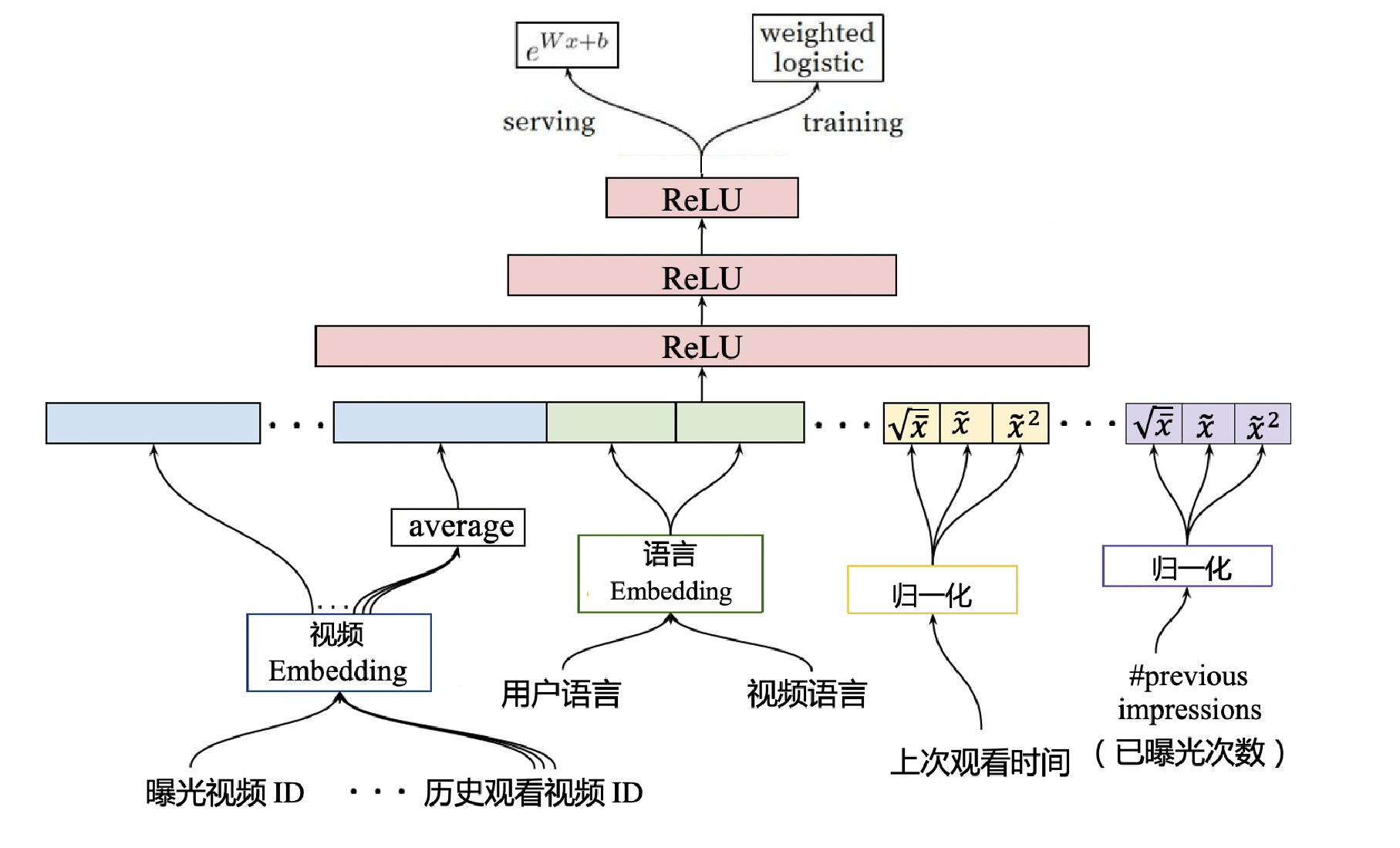
排序模型的网络结构与候选集生成模型在结构上看起来没有太大区别,它们都遵循 Embedding+MLP 的模型架构。但是观察其细节,值得注意的是它的预测目标是视频的平均观看时长(点击率观看时长),特别是*输入层和输出层的部分,它们跟候选集生成模型区别很大。先看下输入特征:
| 序号 | 原文特征名称 | 含义 |
|---|---|---|
| 1 | impression video ID embedding | 当前候选视频的 Embedding |
| 2 | watched video IDs average embedding | 用户观看过的最后 N 个视频 Embedding 的平均值 |
| 3 | language embedding | 用户语言的 Embedding 和当前候选视频语言的 Embedding |
| 4 | time since last watch | 表示用户上次观看同频道视频距今的时间 |
| 5 | #previous impressions | 该视频已经被曝光给该用户的次数 |
前3个特征的含义很好理解,重点看下第4和第5个。
第 4 个特征是用户观看同类视频的间隔时间。如果从用户的角度出发,假如某用户刚看过“DOTA比赛经典回顾”这个频道的视频,那他很大概率会继续看这个频道的其他视频,该特征就可以很好地捕捉到这一用户行为。
第 5 个特征说的是这个视频已经曝光给该用户的次数。如果一个视频已经曝光给了用户 10 次,都没有被点击,那大概率用户对这个视频不感兴趣。所以previous impressions这个特征的引入就可以很好地捕捉到用户这样的行为习惯,避免让同一个视频对同一用户进行持续的无效曝光,尽量增加用户看到新视频的可能性。
把这 5 类特征连接起来之后,再经过MLP进行充分的特征交叉,最后经过Weighted LR输出。需要注意:排序模型的输出层与召回模型有所不同。主要是:召回模型输出层的激活函数是softmax,预测的是用户“会点击哪个模型”;而排序模型的输出层激活函数是weighted logistic regression(加权逻辑回归),预测的是用户“要不要点击当前视频”。
其实根本原因是YouTube想要更精确地预测用户的观看时长,因为观看时长才是 YouTube 最看中的商业指标,而使用加权逻辑回归可以实现这样的目标。就是在加权逻辑回归的训练中,为每个样本设置一个权重,代表这个样本的重要程度。为了预估观看时长,可以把正样本的权重设置为用户观看这个视频的时长。换个角度考虑就是观看时长长的样本被预测的为正样本的概率更高,这个概率与观看时长成正比,所以得到的预测结果可以认为是观看时长。
④ 排序模型服务方法
服务时采用的函数形式是: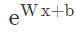 ,和训练的加权逻辑回归又不一样,这也能表示用户观看时长吗?逻辑回归如果还没有清晰的认识,可以看下《Logistic回归中的Logit函数和sigmoid函数》。
,和训练的加权逻辑回归又不一样,这也能表示用户观看时长吗?逻辑回归如果还没有清晰的认识,可以看下《Logistic回归中的Logit函数和sigmoid函数》。
线性回归解决的是回归问题,也就是用直线拟合数据,因此其值域是(−∞,+∞),形式如下: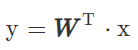
逻辑回归应用于分类问题时,因变量y的值只有0和1,连续的线性模型无法拟合,因此需要选择一个比较合适的激活函数:能够把值域(−∞,+∞)连续且单调地映射到(0, 1)。先来看个logit函数的公式和图像: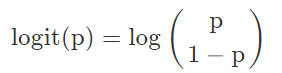


训练和测试样本的处理
① 候选集生成模型训练时,输出是所有视频个数,数量非常庞大,因此YouTube采用了Word2vec中用的负采样训练方法。
② 在训练集的预处理过程中,YouTube没有采用原始的用户日志,而是对每个用户提出等量的样本,是为了减少高度活跃的用户对模型损失的过度影响。因为这会使得模型更倾向于活跃用户,而忽略了长尾用户。
③ 在处理测试集时,YouTube没有采用经典的随机留一法(random holdout),而是选择用户最近一次观看的行为,是为了避免引入未来信息(future information)。
④ 如何处理用户对新视频的偏好呢?在特征中引入了Example Age,含义是训练样本产生的时刻距离当前时刻的时间,单位是小时。模型服务时,这个特征直接设置为0。YouTube通过实验验证了Example Age的重要性。
问答经典
- 请问召回模型中,输入层已经有了视频的预训练的Embedding向量,最后softmax 的参数也会作为视频的embedding向量。一开始不是都有了视频的Embedding向量了吗?最后ANN的为什么只用训练视频向量,而不用预训练的呢?
答:因为只有最后的视频Embedding是跟用户Embedding在一个向量空间内。预训练和Embedding和最后relu层生成的user Embedding没有直接关系。
- YouTube 的排序模型和候选集生成模型,都使用了平均池化这一操作,来把用户的历史观看视频整合起来。你能想到更好的方法来改进这个操作吗?
- 在召回层,对用户历史观看的序列,按照时间衰减因子,对用户观看Embedding序列进行加权求平均,加强最近观看视频的影响力
- 在排序层,可以加入注意力机制,类似DIN模型中,计算候选Embedding与用户行为序列中视频Embedding的权重,然后在进行加权求平均,得到用户行为序列的Embedding
- 之前讲Embedding近邻搜索,需要用户Embedding和物品Embedding在同一向量空间。那么在召回层relu中提取的用户Embedding和softmax提取的物品Embedding,是在同一向量空间的,为什么?
答:relu隐藏层的输出是用户向量,正好是softmax层的输入x,根据前向计算wi*x+b计算得到了物品i 节点值,这里的wi也就能代表物品向量了。也就是说由用户向量参与计算生成了最后的物品向量,跟前面利用电影向量 sum pooling出用户向量逻辑一致。所以他们在同一向量空间。
- 实际 Weighted LR 具体训练过程吗,比如 videoid1 labels=1 weights=15 , 实际中是把这个样本 重复抽样weights 次,放入训练样本吗,还是更改LR 的loss?
答:两种方式都可以。有一些细微的差别,但我觉得无伤大雅,选一种就行。
- 为什么不一开始就使用item2vec训练视频embedding,平均为用户的embedding呢?是因为维度对不上还是因为不在同一个向量空间?而且这时候输入的视频embedding可以finetune的。
答:做法上当然是可以的,YouTube仅仅是把所有的模型结构都画在这里,至于怎么实现,说实话那是每个人自己的事情。个人而言,候选集生成模型的输入用户embedding完全可以像你说的一样预训练生成,没有一点问题。
- 文中把推荐问题转换成多分类问题,在预测next watch的场景下,每一个备选video都会是一个分类,因此总共的分类有数百万之巨,这在使用softmax训练时无疑是低效的,这个问题YouTube是如何解决的?
答:简单说就是进行了负采样(negative sampling)并用importance weighting的方法对采样进行calibration。文中同样介绍了一种替代方法,hierarchical softmax,但并没有取得更好的效果。
- 在candidate generation model的serving过程中,YouTube为什么不直接采用训练时的model进行预测,而是采用了一种最近邻搜索的方法?
答:这个问题的答案是一个经典的工程和学术做trade-off的结果,在model serving过程中对几百万个候选集逐一跑一遍模型的时间开销显然太大了,因此在通过candidate generation model得到user 和 video的embedding之后,通过最近邻搜索的方法的效率高很多。我们甚至不用把任何model inference的过程搬上服务器,只需要把user embedding和video embedding存到redis或者内存中就好了。
- Youtube的用户对新视频有偏好,那么在模型构建的过程中如何引入这个feature?
答:为了拟合用户对fresh content的bias,模型引入了“Example Age”这个feature,文中其实并没有精确的定义什么是example age。按照文章的说法猜测的话,会直接把sample log距离当前的时间作为example age。比如24小时前的日志,这个example age就是24。在做模型serving的时候,不管使用那个video,会直接把这个feature设成0。大家可以仔细想一下这个做法的细节和动机,非常有意思。
- 在对训练集的预处理过程中,YouTube没有采用原始的用户日志,而是对每个用户提取等数量的训练样本,这是为什么?
答:理由很简单,这是为了减少高度活跃用户对于loss的过度影响。
- YouTube为什么不采取类似RNN的Sequence model,而是完全摒弃了用户观看历史的时序特征,把用户最近的浏览历史等同看待,这不会损失有效信息吗?
答:这个原因应该是YouTube工程师的“经验之谈”,如果过多考虑时序的影响,用户的推荐结果将过多受最近观看或搜索的一个视频的影响。YouTube给出一个例子,如果用户刚搜索过“tayer swift”,你就把用户主页的推荐结果大部分变成tayer swift有关的视频,这其实是非常差的体验。为了综合考虑之前多次搜索和观看的信息,YouTube丢掉了时序信息,讲用户近期的历史纪录等同看待。
但RNN到底适不适合next watch这一场景,其实还有待商榷,@严林 大神在上篇文章的评论中已经提到,youtube已经上线了以RNN为基础的推荐模型, 参考论文如下: https://static.googleusercontent.com/media/research.google.com/en//pubs/archive/46488.pdf
看来时隔两年,YouTube对于时序信息以及RNN模型有了更多的掌握和利用。
- 在处理测试集的时候,YouTube为什么不采用经典的随机留一法(random holdout),而是一定要把用户最近的一次观看行为作为测试集?
答:只留最后一次观看行为做测试集主要是为了避免引入future information,产生与事实不符的数据穿越。
- 在确定优化目标的时候,YouTube为什么不采用经典的CTR,或者播放率(Play Rate),而是采用了每次曝光预期播放时间(expected watch time per impression)作为优化目标?
答: 这个问题从模型角度出发,是因为 watch time更能反应用户的真实兴趣,从商业模型角度出发,因为watch time越长,YouTube获得的广告收益越多。而且增加用户的watch time也更符合一个视频网站的长期利益和用户粘性。
这个问题看似很小,实则非常重要,objective的设定应该是一个算法模型的根本性问题,而且是算法模型部门跟其他部门接口性的工作,从这个角度说,YouTube的推荐模型符合其根本的商业模型,非常好的经验。
- 在进行video embedding的时候,为什么要直接把大量长尾的video直接用0向量代替?
答:这又是一次工程和算法的trade-off,把大量长尾的video截断掉,主要还是为了节省online serving中宝贵的内存资源。当然从模型角度讲,低频video的embedding的准确性不佳是另一个“截断掉也不那么可惜”的理由。
- 针对某些特征,比如#previous impressions,为什么要进行开方和平方处理后,当作三个特征输入模型?
答: 这是很简单有效的工程经验,引入了特征的非线性。从YouTube这篇文章的效果反馈来看,提升了其模型的离线准确度。
- 为什么ranking model不采用经典的logistic regression当作输出层,而是采用了weighted logistic regression?
答: 已经知道模型采用了expected watch time per impression作为优化目标,所以如果简单使用LR就无法引入正样本的watch time信息。因此采用weighted LR,将watch time作为正样本的weight,在线上serving中使用e(Wx+b)做预测可以直接得到expected watch time的近似,完美。
附录
item2vec
参照了google的word2vec方法,应用到推荐场景的i2i相似度计算中,但实际效果看还有有提升的。主要做法是把item视为word,用户的行为序列视为一个集合(类比word2vec中一句话),item间的共现为正样本,并按照item的频率分布(类比词频)进行负样本采样,缺点是相似度的计算还只是利用到了item共现信息,1).忽略了user行为序列信息; 2).没有建模用户对不同item的喜欢程度高低。
但作为神经网络的输入足够了,就像word2vec的在bert中的作用。
参考
https://www.notlate.net/posts/2c4e9dc8.html
https://zhuanlan.zhihu.com/p/52504407

若有收获,就点个赞吧
0 人点赞
