转 https://github.com/fuqiuai/learning_notes/blob/master/sklearn%E5%AD%A6%E4%B9%A0.md
目录
sklearn 模型选择官方图 https://scikit-learn.org/stable/tutorial/machine_learning_map/
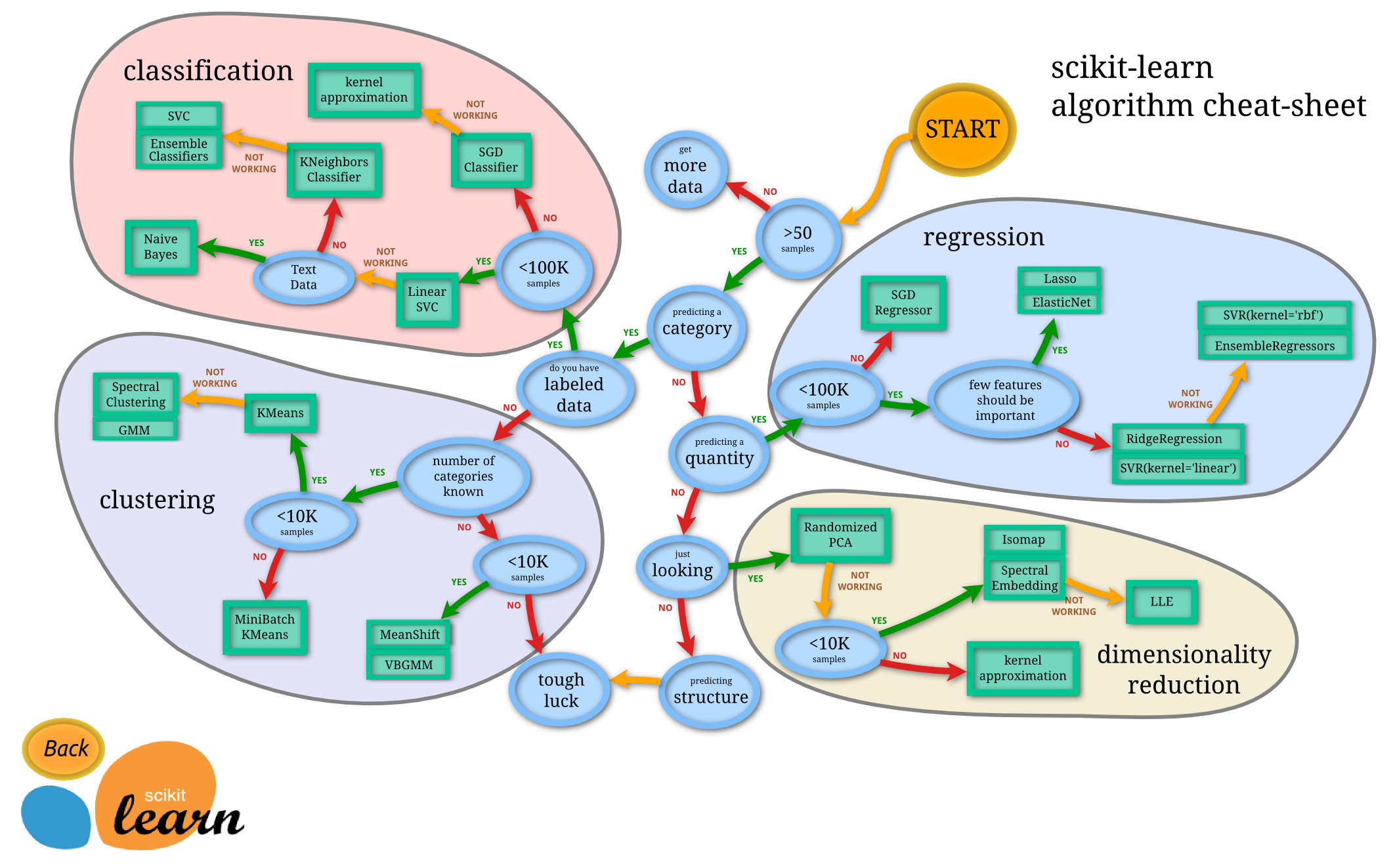
1. 分类、回归
2. 降维
3. 模型评估与选择
4. 数据预处理
| 大类 | 小类 | 适用问题 | 实现 | 说明 |
|---|---|---|---|---|
| 分类、回归 | ||||
| 1.1 广义线性模型 | 1.1.1 普通最小二乘法 | 回归 | sklearn.linear_model.LinearRegression | |
| 注:本节中所有的回归模型皆为线性回归模型 | 1.1.2 Ridge/岭回归 | 回归 | sklearn.linear_model.Ridge | 解决两类回归问题: 一是样本少于变量个数 二是变量间存在共线性 |
| 1.1.3 Lasso | 回归 | sklearn.linear_model.Lasso | 适合特征较少的数据 | |
| 1.1.4 Multi-task Lasso | 回归 | sklearn.linear_model.MultiTaskLasso | y值不是一元的回归问题 | |
| 1.1.5 Elastic Net | 回归 | sklearn.linear_model.ElasticNet | 结合了Ridge和Lasso | |
| 1.1.6 Multi-task Elastic Net | 回归 | sklearn.linear_model.MultiTaskElasticNet | y值不是一元的回归问题 | |
| 1.1.7 Least Angle Regression(LARS) | 回归 | sklearn.linear_model.Lars | 适合高维数据 | |
| 1.1.8 LARS Lasso | 回归 | sklearn.linear_model.LassoLars | (1)适合高维数据使用 (2)LARS算法实现的lasso模型 |
|
| 1.1.9 Orthogonal Matching Pursuit (OMP) | 回归 | sklearn.linear_model.OrthogonalMatchingPursuit | 基于贪心算法实现 | |
| 1.1.10 贝叶斯回归 | 回归 | sklearn.linear_model.BayesianRidge sklearn.linear_model.ARDRegression |
优点: (1)适用于手边数据(2)可用于在估计过程中包含正规化参数 缺点:耗时 |
|
| 1.1.11 Logistic regression | 分类 | sklearn.linear_model.LogisticRegression | ||
| 1.1.12 SGD(随机梯度下降法) | 分类 /回归 |
sklearn.linear_model.SGDClassifier sklearn.linear_model.SGDRegressor |
适用于大规模数据 | |
| 1.1.13 Perceptron | 分类 | sklearn.linear_model.Perceptron | 适用于大规模数据 | |
| 1.1.14 Passive Aggressive Algorithms | 分类 /回归 |
sklearn.linear_model. PassiveAggressiveClassifier sklearn.linear_model. PassiveAggressiveRegressor |
适用于大规模数据 | |
| 1.1.15 Huber Regression | 回归 | sklearn.linear_model.HuberRegressor | 能够处理数据中有异常值的情况 | |
| 1.1.16 多项式回归 | 回归 | sklearn.preprocessing.PolynomialFeatures | 通过PolynomialFeatures将非线性特征转化成多项式形式,再用线性模型进行处理 | |
| 1.2 线性和二次判别分析 | 1.2.1 LDA | 分类/降维 | sklearn.discriminant_analysis. LinearDiscriminantAnalysis |
|
| 1.2.2 QDA | 分类 | sklearn.discriminant_analysis. QuadraticDiscriminantAnalysis |
||
| 1.3 核岭回归 | 简称KRR | 回归 | sklearn.kernel_ridge.KernelRidge | 将核技巧应用到岭回归(1.1.2)中,以实现非线性回归 |
| 1.4 支持向量机 | 1.4.1 SVC,NuSVC,LinearSVC | 分类 | sklearn.svm.SVC sklearn.svm.NuSVC sklearn.svm.LinearSVC |
SVC可用于非线性分类,可指定核函数; NuSVC与SVC唯一的不同是可控制支持向量的个数; LinearSVC用于线性分类 |
| 1.4.2 SVR,NuSVR,LinearSVR | 回归 | sklearn.svm.SVR sklearn.svm.NuSVR sklearn.svm.LinearSVR |
同上,将”分类”变成”回归”即可 | |
| 1.4.3 OneClassSVM | 异常检测 | sklearn.svm.OneClassSVM | 无监督实现异常值检测 | |
| 1.5 随机梯度下降 | 同1.1.12 | |||
| 1.6 最近邻 | 1.6.1 Unsupervised Nearest Neighbors | — | sklearn.neighbors.NearestNeighbors | 无监督实现K近邻的寻找 |
| 1.6.2 Nearest Neighbors Classification | 分类 | sklearn.neighbors.KNeighborsClassifier sklearn.neighbors.RadiusNeighborsClassifier |
(1)不太适用于高维数据 (2)两种实现只是距离度量不一样,后者更适合非均匀的采样 |
|
| 1.6.3 Nearest Neighbors Regression | 回归 | sklearn.neighbors.KNeighborsRegressor sklearn.neighbors.RadiusNeighborsRegressor |
同上 | |
| 1.6.5 Nearest Centroid Classifier | 分类 | sklearn.neighbors.NearestCentroid | 每个类对应一个质心,测试样本被分类到距离最近的质心所在的类别 | |
| 1.7 高斯过程(GP/GPML) | 1.7.1 GPR | 回归 | sklearn.gaussian_process. GaussianProcessRegressor |
与KRR一样使用了核技巧 |
| 1.7.3 GPC | 分类 | sklearn.gaussian_process. GaussianProcessClassifier |
||
| 1.8 交叉分解 | 实现算法:CCA和PLS | — | — | 用来计算两个多元数据集的线性关系,当预测数据比观测数据有更多的变量时,用PLS更好 |
| 1.9 朴素贝叶斯 | 1.9.1 高斯朴素贝叶斯 | 分类 | sklearn.naive_bayes.GaussianNB | 处理特征是连续型变量的情况 |
| 1.9.2 多项式朴素贝叶斯 | 分类 | sklearn.naive_bayes.MultinomialNB | 最常见,要求特征是离散数据 | |
| 1.9.3 伯努利朴素贝叶斯 | 分类 | sklearn.naive_bayes.BernoulliNB | 要求特征是离散的,且为布尔类型,即true和false,或者1和0 | |
| 1.10 决策树 | 1.10.1 Classification | 分类 | sklearn.tree.DecisionTreeClassifier | |
| 1.10.2 Regression | 回归 | sklearn.tree.DecisionTreeRegressor | ||
| 1.11 集成方法 | 1.11.1 Bagging | 分类/回归 | sklearn.ensemble.BaggingClassifier sklearn.ensemble.BaggingRegressor |
可以指定基学习器,默认为决策树 |
| 注:1和2属于集成方法中的并行化方法,3和4属于序列化方法 | 1.11.2 Forests of randomized trees | 分类/回归 | RandomForest(RF,随机森林): sklearn.ensemble.RandomForestClassifier sklearn.ensemble.RandomForestRegressor ExtraTrees(RF改进): sklearn.ensemble.ExtraTreesClassifier sklearn.ensemble.ExtraTreesRegressor |
基学习器为决策树 |
| 1.11.3 AdaBoost | 分类/回归 | sklearn.ensemble.AdaBoostClassifier sklearn.ensemble.AdaBoostRegressor |
可以指定基学习器,默认为决策树 | |
| 号外:最近特别火的两个梯度提升算法,LightGBM和XGBoost (XGBoost提供了sklearn接口) |
1.11.4 Gradient Tree Boosting | 分类/回归 | GBDT: sklearn.ensemble.GradientBoostingClassifier GBRT: sklearn.ensemble.GradientBoostingRegressor |
基学习器为决策树 |
| 1.11.5 Voting Classifier | 分类 | sklearn.ensemble.VotingClassifier | 须指定基学习器 | |
| 1.12 多类与多标签算法 | — | — | — | sklearn中的分类算法都默认支持多类分类,其中LinearSVC、 LogisticRegression和GaussianProcessClassifier在进行多类分类时需指定参数multi_class |
| 1.13 特征选择 | 1.13.1 过滤法之方差选择法 | 特征选择 | sklearn.feature_selection.VarianceThreshold | 特征选择方法分为3种:过滤法、包裹法和嵌入法。过滤法不用考虑后续学习器 |
| 1.13.2 过滤法之卡方检验 | 特征选择 | sklearn.feature_selection.chi2,结合sklearn.feature_selection.SelectKBest | ||
| 1.13.3 包裹法之递归特征消除法 | 特征选择 | sklearn.feature_selection.RFE | 包裹法需考虑后续学习器,参数中需输入基学习器 | |
| 1.13.4 嵌入法 | 特征选择 | sklearn.feature_selection.SelectFromModel | 嵌入法是过滤法和嵌入法的结合,参数中也需输入基学习器 | |
| 1.14 半监督 | 1.14.1 Label Propagation | 分类/回归 | sklearn.semi_supervised.LabelPropagation sklearn.semi_supervised.LabelSpreading |
|
| 1.15 保序回归 | — | 回归 | sklearn.isotonic.IsotonicRegression | |
| 1.16 概率校准 | — | — | — | 在执行分类时,获得预测的标签的概率 |
| 1.17 神经网络模型 | (待写) | |||
| 降维 | ||||
| 2.5 降维 | 2.5.1 主成分分析 | 降维 | PCA: sklearn.decomposition.PCA IPCA: sklearn.decomposition.IncrementalPCA KPCA: sklearn.decomposition.KernelPCA SPCA: sklearn.decomposition.SparsePCA |
(1)IPCA比PCA有更好的内存效率,适合超大规模降维。 (2)KPCA可以进行非线性降维 (3)SPCA是PCA的变体,降维后返回最佳的稀疏矩阵 |
| 2.5.2 截断奇异值分解 | 降维 | sklearn.decomposition.TruncatedSVD | 可以直接对scipy.sparse矩阵处理 | |
| 2.5.3 字典学习 | — | sklearn.decomposition.SparseCoder sklearn.decomposition.DictionaryLearning |
SparseCoder实现稀疏编码,DictionaryLearning实现字典学习 | |
| 模型评估与选择 | ||||
| 3.1 交叉验证/CV | 3.1.1 分割训练集和测试集 | — | sklearn.model_selection.train_test_split | |
| 3.1.2 通过交叉验证评估score | — | sklearn.model_selection.cross_val_score | score对应性能度量,分类问题默认为accuracy_score,回归问题默认为r2_score | |
| 3.1.3 留一法LOO | — | sklearn.model_selection.LeaveOneOut | CV的特例 | |
| 3.1.4 留P法LPO | — | sklearn.model_selection.LeavePOut | CV的特例 | |
| 3.2 调参 | 3.2.1 网格搜索 | — | sklearn.model_selection.GridSearchCV | 最常用的调参方法。可传入学习器、学习器参数范围、性能度量score(默认为accuracy_score或r2_score )等 |
| 3.2.2 随机搜索 | — | sklearn.model_selection.RandomizedSearchCV | 参数传入同上 | |
| 3.3 性能度量 | 3.3.1 分类度量 | — | — | 对应交叉验证和调参中的score |
| 3.3.2 回归度量 | — | — | ||
| 3.3.3 聚类度量 | — | — | ||
| 3.4 模型持久性 | — | — | — | 使用pickle存放模型,可以使模型不用重复训练 |
| 3.5 验证曲线 | 3.5.1 验证曲线 | — | sklearn.model_selection.validation_curve | 横轴为某个参数的值,纵轴为模型得分 |
| 3.5.2 学习曲线 | — | sklearn.model_selection.learning_curve | 横轴为训练数据大小,纵轴为模型得分 | |
| 数据预处理 | ||||
| 4.3 数据预处理 | 4.3.1 标准化 | 数据预处理 | 标准化: sklearn.preprocessing.scale sklearn.preprocessing.StandardScaler |
scale与StandardScaler都是将将特征转化成标准正态分布(即均值为0,方差为1),且都可以处理scipy.sparse矩阵,但一般选择后者 |
| 数据预处理 | 区间缩放: sklearn.preprocessing.MinMaxScaler sklearn.preprocessing.MaxAbsScale |
MinMaxScaler默认为0-1缩放,MaxAbsScaler可以处理scipy.sparse矩阵 | ||
| 4.3.2 非线性转换 | 数据预处理 | sklearn.preprocessing.QuantileTransformer | 可以更少的受异常值的影响 | |
| 4.3.3 归一化 | 数据预处理 | sklearn.preprocessing.Normalizer | 将行向量转换为单位向量,目的在于样本向量在点乘运算或其他核函数计算相似性时,拥有统一的标准 | |
| 4.3.4 二值化 | 数据预处理 | sklearn.preprocessing.Binarizer | 通过设置阈值对定量特征处理,获取布尔值 | |
| 4.3.5 哑编码 | 数据预处理 | sklearn.preprocessing.OneHotEncoder | 对定性特征编码。也可用pandas.get_dummies实现 | |
| 4.3.6 缺失值计算 | 数据预处理 | sklearn.preprocessing.Imputer | 可用三种方式填充缺失值,均值(默认)、中位数和众数。也可用pandas.fillna实现 | |
| 4.3.7 多项式转换 | 数据预处理 | sklearn.preprocessing.PolynomialFeatures | ||
| 4.3.8 自定义转换 | 数据预处理 | sklearn.preprocessing.FunctionTransformer | ||
代码实例(浓缩的精华)
集合了
- 数据构造
- 数据划分
- 特征选择
- 模型融合
- 交叉验证
- 管道
- 网格搜索
- AUC、PR、混淆矩阵、学习曲线、验证曲线 ```python from sklearn.datasets import make_classification from sklearn.preprocessing import Normalizer,StandardScaler, MinMaxScaler, OneHotEncoder from sklearn.model_selection import train_test_split
from sklearn.feature_selection import VarianceThreshold, f_regression, chi2, SelectKBest, SelectFromModel from sklearn.decomposition import PCA from sklearn.compose import ColumnTransformer, make_column_transformer
from sklearn.svm import SVC from sklearn.ensemble import RandomForestClassifier as RF from sklearn.ensemble import GradientBoostingClassifier as GBDT from sklearn.ensemble import StackingClassifier from sklearn.linear_model import LogisticRegression as LR
from sklearn.model_selection import validation_curve, learning_curve from sklearn.model_selection import KFold, cross_val_score, GridSearchCV from sklearn.pipeline import make_pipeline
from sklearn.metrics import f1_score, auc, precision_score, recall_score,accuracy_score from sklearn.metrics import plot_confusion_matrix, plot_precision_recall_curve,plot_roc_curve from server.until.dataprocess import draw
import numpy as np import matplotlib.pyplot as plt
X, y =make_classification(n_samples=10**3, n_features=20, n_classes=2, random_state=0) X_train, X_test, y_train, y_test = train_test_split(X, y , test_size=0.3) preprocess_pipe = make_pipeline( ColumnTransformer( [(“norm1”, Normalizer(norm=’l1’), [0, 1]), (“norm2”, Normalizer(norm=’l1’), slice(2, 10))] ) )
estimators = [ (‘rf’, RF(n_estimators=10, random_state=0)), (‘svc’, make_pipeline(StandardScaler(),SVC(random_state=0))), (‘gbdt’, make_pipeline(make_column_transformer((‘passthrough’, [1,2,3])), GBDT(n_estimators=50, random_state=0))) ]
clf = make_pipeline(preprocess_pipe, StackingClassifier(estimators=estimators, final_estimator=LR(), cv=5))
“”” 结合网格搜索: pipe = make_pipeline(preprocess_pipe, StackingClassifier(estimators=estimators, final_estimator=LR())) N_FEATURES_OPTIONS = [20, 40, 80] C_OPTIONS = [1, 10] param_grid = { ‘stackingclassifierrfn_estimators’:N_FEATURES_OPTIONS, ‘stackingclassifiersvcsvc__C’: C_OPTIONS }
grid = GridSearchCV(pipe, param_grid=param_grid, cv=5)
grid.get_params().keys() # 注意:param_grid中的参数命名随着pipe加深而比较复杂,调用这个函数来确定正确的参数命名写法
cv_keys = (‘mean_test_score’, ‘std_test_score’, ‘params’)
for r, in enumerate(grid.cv_results[‘meantest_score’]): print(“%0.3f +/- %0.2f %r” % (grid.cv_results[cvkeys[0]][r], grid.cv_results[cvkeys[1]][r] / 2.0, grid.cv_results[cv_keys[2]][r]))
print(‘Best parameters: %s’ % grid.bestparams) print(‘Accuracy: %.2f’ % grid.bestscore) “””
clf.fit(X_train, y_train) accuracy_score(y_test, clf.predict(X_test))
for label,clf in estimators: clf_pipe = make_pipeline(preprocess_pipe, clf) scores = cross_val_score(clf_pipe, X, y, cv=3, scoring=’accuracy’) print(“Accuracy: %0.2f (+/- %0.2f) [%s]” % (scores.mean(), scores.std(), label))
plt.figure(figsize=(20, 5)) ax1 = plt.subplot(1,3,1) plot_roc_curve(clf, X_test, y_test, ax=ax1) # roc曲线 ax1 = plt.subplot(1,3,2) plot_precision_recall_curve(clf, X_test, y_test, ax=ax1) # PR曲线 ax1 = plt.subplot(1,3,3) plot_confusion_matrix(clf, X_test, y_test, ax=ax1) # 混淆矩阵
draw.plot_learning_curve(estimator=clf, title=”none”, X=X, y=y ) # 学习曲线
C_OPTIONS = list(range(10)) param={‘param_name’:’stackingclassifiersvcsvc__C’, ‘param_range’:C_OPTIONS} draw.plot_validation_curve(estimator=clf, X=X, y=y,param=param ) # 验证曲线 ```

若有收获,就点个赞吧
0 人点赞
