TinyBERT(官网介绍)
https://github.com/huawei-noah/Pretrained-Language-Model/tree/master/TinyBERT
TinyBERT比BERT-base小7.5倍,推理速度快9.4倍,在自然语言理解任务中表现出色。它在训练前和任务特定的学习阶段执行一种新的transformer蒸馏。TinyBERT学习概述如下:
细节看论文:TinyBERT: Distilling BERT for Natural Language Understanding
安装依赖
python版本:python3
pip install -r requirements.txt
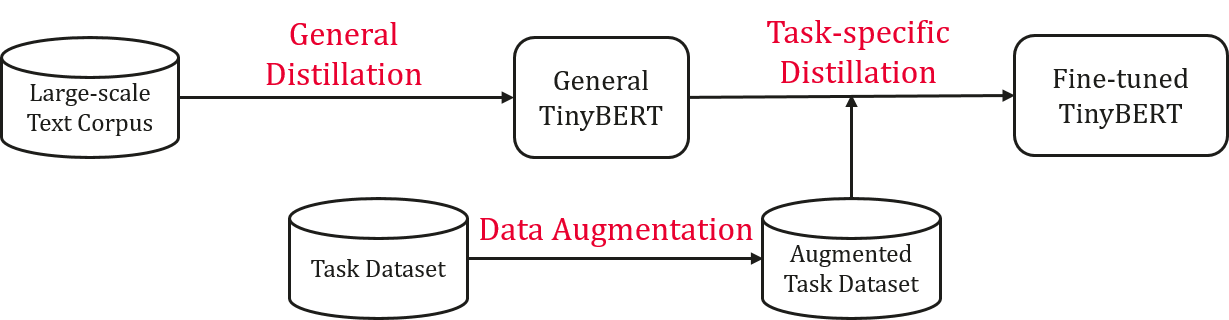
一般蒸馏方法:
一般来说,我们使用未经微调的原始bert模型作为教师,使用大型文本语料库作为学习数据。通过对一般域的文本进行变压器蒸馏,我们得到了一个一般的TinyBERT,它为特定任务的蒸馏提供了一个良好的初始化。
一般蒸馏方法分为两个步骤:(1)生成json格式的语料库;(2)运行变压器蒸馏;
步骤1:使用pregenerate_training_data.py。生成json格式的语料
# ${BERT_BASE_DIR}$ includes the BERT-base teacher model.python pregenerate_training_data.py --train_corpus ${CORPUS_RAW} \--bert_model ${BERT_BASE_DIR}$ \--reduce_memory --do_lower_case \--epochs_to_generate 3 \--output_dir ${CORPUS_JSON_DIR}$
第二步:使用general-distill.py来进行一般的蒸馏
# ${STUDENT_CONFIG_DIR}$ includes the config file of student_model.python general_distill.py --pregenerated_data ${CORPUS_JSON}$ \--teacher_model ${BERT_BASE}$ \--student_model ${STUDENT_CONFIG_DIR}$ \--reduce_memory --do_lower_case \--train_batch_size 256 \--output_dir ${GENERAL_TINYBERT_DIR}$
我们还提供了一般的TinyBERT模型,用户可以跳过一般的蒸馏。
=================第一个版本, 我们在论文中所使用的结果 ===========================
General_TinyBERT(4layer-312dim)
General_TinyBERT(6layer-768dim)
=================第二版(2019/11/18)使用更多(book+wiki)和没有“[MASK]”语料库进行训练 =======
General_TinyBERT_v2(4layer-312dim)
General_TinyBERT_v2(6layer-768dim)
数据扩张
数据扩充的目的是扩展任务特定的训练集。学习更多的任务相关的例子,可以进一步提高学生模型的泛化能力。我们结合一个预先训练好的语言模型BERT和手套嵌入来做单词级的替换来增加数据。
使用data_augmentation.py 运行数据扩充和扩充数据集,结果会自动保存到${GLUE_DIR/TASK_NAME}$/train_aug.tsv :
python data_augmentation.py --pretrained_bert_model ${BERT_BASE_DIR}$ \--glove_embs ${GLOVE_EMB}$ \--glue_dir ${GLUE_DIR}$ \--task_name ${TASK_NAME}$
在运行GLUE任务的数据扩充之前,您应该通过运行这个脚本下载GLUE数据,并将其解压缩到GLUE_DIR目录。TASK_NAME可以是CoLA,SST-2, MRPC, STS-B, QQP, MNLI, QNLI, RTE的任意一个。
特定于任务的蒸馏
在任务特定精馏中,我们重新执行提出的变压器精馏,通过重点学习任务特定的知识来进一步改进TinyBERT。
具体任务精馏包括两个步骤:(1)中间层精馏;(2)预测层蒸馏。
- 第一步:使用’
task_distill .py。运行中间层蒸馏。
# ${FT_BERT_BASE_DIR}$ contains the fine-tuned BERT-base model.python task_distill.py --teacher_model ${FT_BERT_BASE_DIR}$ \--student_model ${GENERAL_TINYBERT_DIR}$ \--data_dir ${TASK_DIR}$ \--task_name ${TASK_NAME}$ \--output_dir ${TMP_TINYBERT_DIR}$ \--max_seq_length 128 \--train_batch_size 32 \--num_train_epochs 10 \--aug_train \--do_lower_case
- 第二步:使用
task_distill.py运行预测层蒸馏。
python task_distill.py --pred_distill \--teacher_model ${FT_BERT_BASE_DIR}$ \--student_model ${TMP_TINYBERT_DIR}$ \--data_dir ${TASK_DIR}$ \--task_name ${TASK_NAME}$ \--output_dir ${TINYBERT_DIR}$ \--aug_train \--do_lower_case \--learning_rate 3e-5 \--num_train_epochs 3 \--eval_step 100 \--max_seq_length 128 \--train_batch_size 32
我们还提供了所有GLUE任务的蒸馏TinyBERT(4layer-312dim和6layer-768dim)供评估。每个任务都有自己的文件夹,其中保存了相应的模型。
TinyBERT(4layer-312dim)
TinyBERT(6layer-768dim)
评估
task_distill.py 也提供了评估运行以下命令:
${TINYBERT_DIR}$ includes the config file, student model and vocab file.python task_distill.py --do_eval \--student_model ${TINYBERT_DIR}$ \--data_dir ${TASK_DIR}$ \--task_name ${TASK_NAME}$ \--output_dir ${OUTPUT_DIR}$ \--do_lower_case \--eval_batch_size 32 \--max_seq_length 128
改进
根据transformers修改了数据预处理流程,增加了保存特征的代码,使得程序运行更加顺畅

若有收获,就点个赞吧
0 人点赞
