之前对学习曲线存在误解,以为每次训练的数据量是一样,后来发现不是。正确的理解是数据量是递增的。
注意:
- 每个特定大小的训练集都会训练一个新的模型。
- 如果使用了交叉验证,那么每个训练集大小会训练出 k 个不同的模型。
学习曲线应有的结论:
学习曲线-基本思想
转 https://www.jiqizhixin.com/articles/2018-01-23
假设我们拥有一些数据,并且将它们分割成训练集和验证集。我们从训练集中拿一个例子(对,仅用一个样本)来训练模型,并用它来估计一个模型。然后我们在验证集上衡量这个基于一个训练样本的误差。在训练集上的误差是 0,因为它能够很容易地适应一个数据点。然而,在验证集上的误差会特别大。这是因为,这个模型是在一个样本上建立的,它几乎不能够准确地泛化到之前没有见过的数据上。
现在我们考虑一下不是 1 个训练样本的情况,我们取 10 个训练样本来重复上述实验。然后我们取 50 个、100 个、500 个直至使用整个训练集。随着训练集的改变,误差得分会或多或少的改变。
因此我们会监控两个误差得分:一个针对训练集,另一个针对验证集。如果我们把两个误差得分随着训练集的改变画出来,最终我们会得到两个曲线。它们被称为学习曲线。
转 https://blog.csdn.net/gracejpw/article/details/102370364
learning_curve学习曲线
运行原理
学习曲线。
确定交叉验证的针对不同训练集大小的训练和测试分数。
交叉验证生成器将整个数据集拆分为训练和测试数据中的k次。 具有不同大小的训练集的子集将用于训练估计器,并为每个训练子集大小和测试集计算分数。 之后,对于每个训练子集大小,将对所有k次运行的得分进行平均。
函数格式
sklearn.model_selection.learning_curve(estimator, X, y, groups=None, train_sizes=array([0.1, 0.33, 0.55, 0.78, 1. ]), cv=’warn’, scoring=None, exploit_incremental_learning=False, n_jobs=None, pre_dispatch=’all’, verbose=0, shuffle=False, random_state=None, error_score=’raise-deprecating’)
参数
estimator:实现“ fit”和“ predict”方法的对象类型
每次验证都会克隆的该类型的对象。
X:数组类,形状(n_samples,n_features)
训练向量,其中n_samples是样本数,n_features是特征数。
y:数组类,形状(n_samples)或(n_samples,n_features),可选
相对于X的目标进行分类或回归;无监督学习无。
groups:数组类,形状为(n_samples,),可选
将数据集拆分为训练/测试集时使用的样本的标签分组。仅用于连接交叉验证实例组(例如GroupKFold)。
train_sizes:数组类,形状(n_ticks),dtype float或int
训练示例的相对或绝对数量,将用于生成学习曲线。如果dtype为float,则视为训练集最大尺寸的一部分(由所选的验证方法确定),即,它必须在(0,1]之内,否则将被解释为绝对大小注意,为了进行分类,样本的数量通常必须足够大,以包含每个类中的至少一个样本(默认值:np.linspace(0.1,1.0,5))
cv:int,交叉验证生成器或可迭代的,可选的
确定交叉验证拆分策略。cv的可能输入是:
None,要使用默认的三折交叉验证(v0.22版本中将改为五折)
整数,用于指定(分层)KFold中的折叠数,
CV splitter
可迭代的集(训练,测试)拆分为索引数组。
对于整数/无输入,如果估计器是分类器,y是二进制或多类,则使用StratifiedKFold。在所有其他情况下,都使用KFold。
scoring:字符串,可调用或无,可选,默认:None
字符串(参阅model evaluation documentation)或带有签名scorer(estimator, X, y)的计分器可调用对象/函数。
exploit_incremental_learning:布尔值,可选,默认值:False
如果估算器支持增量学习,此参数将用于加快拟合不同训练集大小的速度。
n_jobs:int或None,可选(默认=None)
要并行运行的作业数。None表示1。 -1表示使用所有处理器。有关更多详细信息,请参见词汇表。
pre_dispatch:整数或字符串,可选
并行执行的预调度作业数(默认为全部)。该选项可以减少分配的内存。该字符串可以是“ 2 * n_jobs”之类的表达式。
verbose:整数,可选
控制详细程度:越高,消息越多。
shuffle:布尔值,可选
是否在基于``train_sizes’’为前缀之前对训练数据进行洗牌。
random_state:int,RandomState实例或无,可选(默认=None)
如果为int,则random_state是随机数生成器使用的种子;否则为false。如果是RandomState实例,则random_state是随机数生成器;如果为None,则随机数生成器是np.random使用的RandomState实例。在shuffle为True时使用。
error_score:‘raise’ | ‘raise-deprecating’ 或数字
如果估算器拟合中出现错误,则分配给分数的值。如果设置为“ raise”,则会引发错误。如果设置为“raise-deprecating”,则会在出现错误之前打印FutureWarning。如果给出数值,则引发FitFailedWarning。此参数不会影响重新安装步骤,这将始终引发错误。默认值为“不赞成使用”,但从0.22版开始,它将更改为np.nan。
返回值
train_sizes_abs:数组,形状(n_unique_ticks,),dtype int
已用于生成学习曲线的训练示例数。 请注意,ticks的数量可能少于n_ticks,因为重复的条目将被删除。
train_scores:数组,形状(n_ticks,n_cv_folds)
训练集得分。
test_scores:数组,形状(n_ticks,n_cv_folds)
测试集得分。
代码示例
学习曲线显示了针对不同数量的训练样本的估计量的有效性和训练得分。 它是一种工具,它可以了解我们从添加更多训练数据中受益多少,以及估算器是否遭受方差误差或偏差误差的影响更大。 如果验证分数和训练分数都随着训练集规模的增加而收敛到一个太低的值,那么我们将无法从更多的训练数据中受益匪浅。 在下面的曲线图中,您可以看到一个示例:朴素的贝叶斯大致收敛到较低的分数。
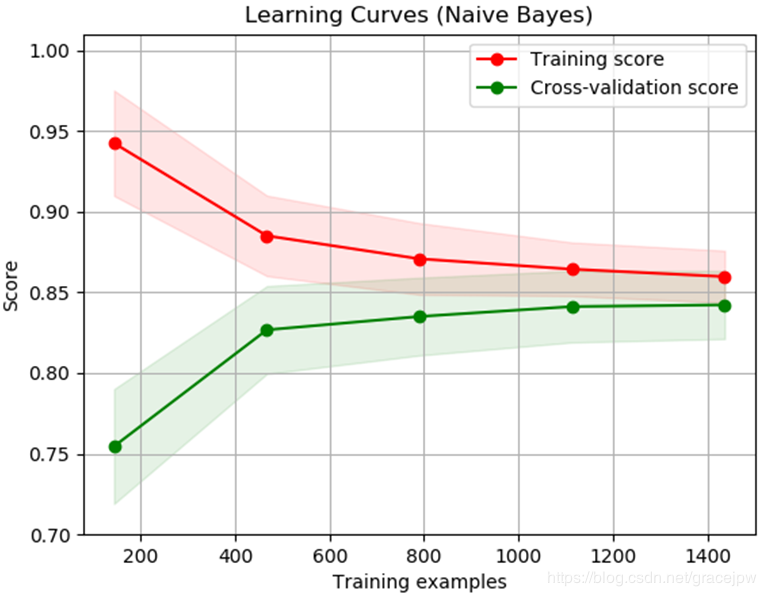
我们可能必须使用可以了解更多复杂概念(即偏差较小)的估算器或当前估算器的参数化。 如果针对最大数量的训练样本,训练分数远大于验证分数,那么添加更多训练样本将最有可能提高泛化性。 在下图中,您可以看到SVM可以从更多培训示例中受益。
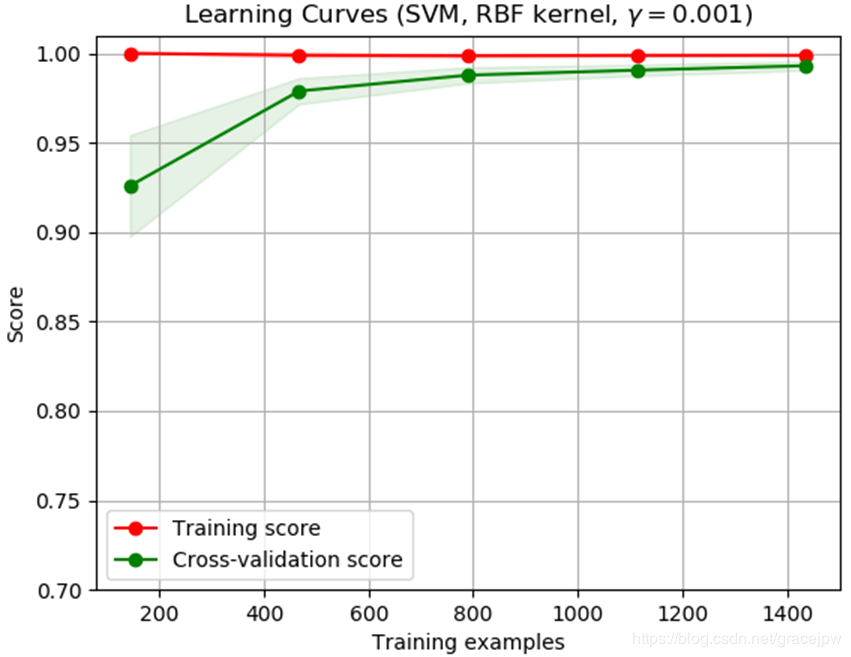
我们可以使用函数learning_curve生成绘制这样的学习曲线所需的值(已使用的样本数,训练集的平均分数和验证集的平均分数):
from sklearn.model_selection import learning_curvefrom sklearn.svm import SVCtrain_sizes, train_scores, valid_scores = learning_curve(SVC(kernel='linear'), X, y, train_sizes=[50, 80, 110], cv=5)
train_sizes :
array([ 50, 80, 110])
train_scores :
array([[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.]])
valid_scores:
array([[0.90384615, 0.73480663, 0.75487465, 0.8907563 , 0.76338028],
[0.88461538, 0.71270718, 0.77715877, 0.88795518, 0.8056338 ],
[0.88461538, 0.74309392, 0.81615599, 0.91036415, 0.82535211]])

若有收获,就点个赞吧
0 人点赞
