stacking
stacking的过程有一张图非常经典,如下:
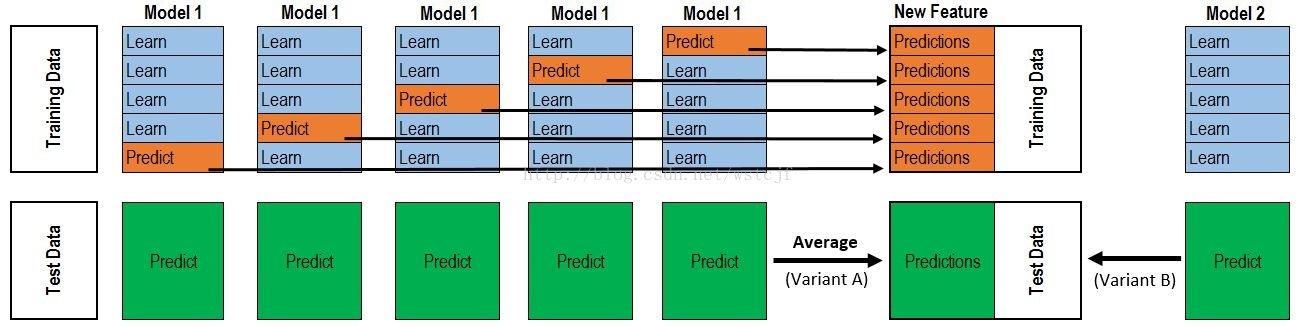
虽然他很直观,但是没有语言描述确实很难搞懂。
上半部分是用一个基础模型进行5折交叉验证,如:用XGBoost作为基础模型Model1,5折交叉验证就是先拿出四折作为training data,另外一折作为Validation data。注意:在stacking中此部分数据会用到整个traing set。如:假设我们整个training set包含10000行数据,testing set包含2500行数据,那么每一次交叉验证其实就是对training set进行划分,在每一次的交叉验证中training data将会是8000行,Validation data是2000行。
每一次的交叉验证包含两个过程,1. 基于training data训练模型;2. 基于training data训练生成的模型对Validation data进行预测。在整个第一次的交叉验证完成之后我们将会得到关于当前Validation data的预测值,这将会是一个一维2000行的数据,记为a1。注意!在这部分操作完成后,我们还要对数据集原来的整个testing set进行预测,这个过程会生成2500个预测值,这部分预测值将会作为下一层模型testing data的一部分,记为b1。因为我们进行的是5折交叉验证,所以以上提及的过程将会进行五次,最终会生成针对Validation set数据预测的5列2000行的数据a1,a2,a3,a4,a5,对testing set的预测会是5列2500行数据b1,b2,b3,b4,b5。
在完成对Model1的整个步骤之后,我们可以发现a1,a2,a3,a4,a5其实就是对原来整个training set的预测值,将他们拼凑起来,会形成一个10000行一列的矩阵,记为A1。而对于b1,b2,b3,b4,b5这部分数据,我们将各部分相加取平均值,得到一个2500行一列的矩阵,记为B1。
以上就是stacking中一个模型的完整流程,stacking中同一层通常包含多个模型,假设还有Model2: LR,Model3:RF,Model4: GBDT,Model5:SVM,对于这四个模型,我们可以重复以上的步骤,在整个流程结束之后,我们可以得到新的A2,A3,A4,A5,B2,B3,B4,B5矩阵。
在此之后,我们把A1,A2,A3,A4,A5并列合并得到一个10000行五列的矩阵作为training data,B1,B2,B3,B4,B5并列合并得到一个2500行五列的矩阵作为testing data。让下一层的模型,基于他们进一步训练。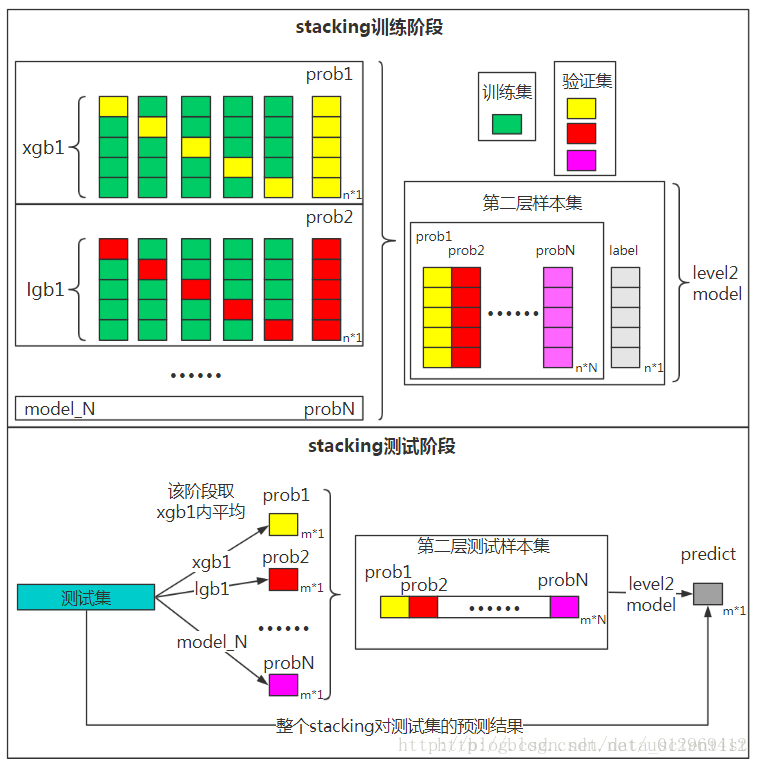
以上即为stacking的完整步骤!
Stacking注意事项
做Stacking模型融合时需要注意以下个点,我们拿2层stacking模型融合来举例子:
- 第一层的基模型最好是强模型,而第二层的基模型可以放一个简单的分类器,防止过拟合。
- 第一层基模型的个数不能太小,因为一层模型个数等于第二层分类器的特征维度。大家可以把勉强将其想象成神经网络的第一层神经元的个数,当然这个值也不是越多越好。
- 第一层的基模型必须准而不同”,如果有一个性能很差的模型出现在第一层,将会严重影响整个模型融合的效果(笔者在实验过程中就遇到这样的坑)。
通过上述的描述,大家没有发现其实2层的stacking 其实和两层的神经网络有些相像,只不过stacking将神经网络第一层的神经元换成了强大的机器学习模型。
实验部分
数据准备
from sklearn.datasets import make_classificationfrom sklearn.model_selection import StratifiedKFoldfrom sklearn.model_selection import train_test_splitfrom sklearn.ensemble import GradientBoostingClassifier as GBDTfrom sklearn.ensemble import ExtraTreesClassifier as ETfrom sklearn.ensemble import RandomForestClassifier as RFfrom sklearn.ensemble import AdaBoostClassifier as ADAfrom sklearn.linear_model import LogisticRegressionfrom sklearn.metrics import roc_auc_scoreimport numpy as npx,y = make_classification(n_samples=6000)X_train, X_test, y_train, y_test = train_test_split(x, y, test_size=0.5)
定义第一层模型
由于Stacking的第一层最后选择比较强的模型,所以这里笔者选了四个本身就是集成模型的强模型,GBDT,RandomForest,ExtraTrees,和 Adaboost。
### 第一层模型clfs = [ GBDT(n_estimators=100),RF(n_estimators=100),ET(n_estimators=100),ADA(n_estimators=100)]X_train_stack = np.zeros((X_train.shape[0], len(clfs)))X_test_stack = np.zeros((X_test.shape[0], len(clfs)))
数据输入第一层模型,输出即将喂给第二层模型特征
6折交叉验证,同时通过第一层的强模型训练预测生成喂给第二层的特征数据。
### 6折stackingn_folds = 6skf = StratifiedKFold(n_splits=n_folds, shuffle=True, random_state=1)for i,clf in enumerate(clfs):# print("分类器:{}".format(clf))X_stack_test_n = np.zeros((X_test.shape[0], n_folds))for j,(train_index,test_index) in enumerate(skf.split(X_train,y_train)):tr_x = X_train[train_index]tr_y = y_train[train_index]clf.fit(tr_x, tr_y)#生成stacking训练数据集X_train_stack [test_index, i] = clf.predict_proba(X_train[test_index])[:,1]X_stack_test_n[:,j] = clf.predict_proba(X_test)[:,1]#生成stacking测试数据集X_test_stack[:,i] = X_stack_test_n.mean(axis=1)
用第一层模型的输出特征,训练第二层模型
为了防止过拟合,第二层选择了一个简单的Logistics回归模型。输出Stacking模型的auc得分。
###第二层模型LRclf_second = LogisticRegression(solver="lbfgs")clf_second.fit(X_train_stack,y_train)pred = clf_second.predict_proba(X_test_stack)[:,1]roc_auc_score(y_test,pred)#0.9946
GBDT分类器性能
###GBDT分类器clf_1 = clfs[0]clf_1.fit(X_train,y_train)pred_1 = clf_1.predict_proba(X_test)[:,1]roc_auc_score(y_test,pred_1)#0.9922
随机森林分类器性能
###随机森林分类器clf_2 = clfs[1]clf_2.fit(X_train,y_train)pred_2 = clf_2.predict_proba(X_test)[:,1]roc_auc_score(y_test,pred_2)#0.9944
ExtraTrees分类器性能
###ExtraTrees分类器clf_3 = clfs[2]clf_3.fit(X_train,y_train)pred_3 = clf_3.predict_proba(X_test)[:,1]roc_auc_score(y_test,pred_3)#0.9930
AdaBoost分类器性能
###AdaBoost分类器clf_4 = clfs[3]clf_4.fit(X_train,y_train)pred_4 = clf_4.predict_proba(X_test)[:,1]roc_auc_score(y_test,pred_4)#0.9875
最终结果如下图所示:其中Stacking集成模型得分最高为0.9946,而且笔者做了多次实验,性能也比较稳定。

实验结果
Blending
Blending与Stacking大致相同,只是Blending的主要区别在于训练集不是通过K-Fold的CV策略来获得预测值从而生成第二阶段模型的特征,而是建立一个Holdout集,例如10%的训练数据,第二阶段的stacker模型就基于第一阶段模型对这10%训练数据的预测值进行拟合。说白了,就是把Stacking流程中的K-Fold CV 改成 HoldOut CV。
Blending的优点在于:
1.比stacking简单(因为不用进行k次的交叉验证来获得stacker feature)
2.避开了一个信息泄露问题:generlizers和stacker使用了不一样的数据集
3.在团队建模过程中,不需要给队友分享自己的随机种子
而缺点在于:
1.使用了很少的数据
2.blender可能会过拟合(其实大概率是第一点导致的)
3.stacking使用多次的CV会比较稳健

若有收获,就点个赞吧
0 人点赞
