参考:https://zhuanlan.zhihu.com/p/96382982
建议先阅读 假设检验(一)
背景
试想我想知道发5元券相比发3元券对于新用户的冒泡率是否有提升。针对这个例子,随机选取了10000个用户做实验,5000个用户分到「对照组-得到3元券」,5000个用户为「实验组-拿到5元券」,经过一周的的观察,得到对照组转化率为40%,实验组为41%。那么能否认为5元券起到了更好的拉新效果呢?如果简单粗暴来看,41% 明显优于40%,我们可以认为对于这10000个用户来说,实验组方案确实起到了更好的拉新效果。但需要注意的是,这10000个用户仅是这个实验中的样本,样本永远不可能是总体的完美代表,用样本估计总体是有偏的,那么这次估计可不可信,多大程度可信,这就是统计需要解决的问题。也是假设检验应用的场景。
理想状态中,样本能够完美的代表总体。例如,总体有10000个用户,有1000个用户成功转化,那么转化率为10%。理想状态中,抽取100个用户做实验,那么一定有10个用户转化。在这个例子中,样本的转化率10%是严格等于总体转化率10%的。
但是现实没有这么完美。现实情况下,在这1个样本中(样本量100人),也许只有2个人转化,也许有20个人转化。这就是样本之间的波动。由于样本的随机性,样本的观测值(如转化率)和总体的真实参数(如总体转化率)存在差距。这种差距能用「抽样误差」衡量。抽样误差越大,用样本估计总体的结果就越不准确。正因为抽样误差的存在,我们用样本观测值直接作为总体参数的估计值是不可取的。因此,直接比较实验组和对照组转化率的大小还不足以支撑一个有力的决策。我们需要更多的信息来描述这次抽样用样本估计总体的准确程度,「置信区间」和「 p-value」正起到了这个作用。
基础知识
- 点估计与区间估计
- 中心极限定理
- 二项分布与正态分布
- 置信度、置信区间、抽样误差、p-value
- 最小样本量
基础概念
- 总体(Population) : 我们最终关注的全部对象。例如,如果我们的实验对象是10%的用户,那么它与剩下90%用户组成的全部用户是总体;如果我们的对象是这10%的用户产生的订单,那么全部用户产生的全部订单是总体。
- 样本(Sample) : 总体中的小部分用户,这是我们的实验对象。例如,如果我们的实验对象是10%的用户,那么样本就是这10%的用户;如果我们的对象是这10%的用户产生的订单, 那么样本就是这10%的用户产生的订单。
- 样本量(Sample Size) : 样本的总个数。例如,如果一个实验的核心指标是冒泡发单用户转化率(发单用户数/冒泡用户数),那么这个实验的实验对象是用户,实验周期内有过冒泡的用户数是这个实验的样本量;如果一个实验的核心指标是冒泡发单率(发单数/冒泡数), 那么实验周期内的总冒泡数是这个实验的样本量,这里需要特别注意。
- 样本统计量 : 它本身是个很宽泛的概念,可以是样本均值,可以是比率或方差,或其他通过样本计算出来的某个关系式。但是在A/B Test中,由于我们目标是了解实验组和对照组方案的好坏,样本统计量特指这两组的转化率(如发单率)的差异,用 [
 ] 表示 ( [p] 代表比率),或均值指标(如平均订单数)的差异。
] 表示 ( [p] 代表比率),或均值指标(如平均订单数)的差异。 - 抽样 (Sampling) : 采用某种特定的方法,如随机抽取,从总体中选取一部分有代表性样本的方法。
- 分布(Distribution) : 你可以把分布想象成一个横轴为观测值,纵轴为出现频率的图。
点估计与区间估计
- 点估计:用一个样本估计总体。用样本均值和方差估计(作为)总体均值和方差。
- 衡量点估计的标准
- 无偏性:样本容量n确定的情况下,样本参数估计值的数学期望等于被估计的总体参数值。足够多次采样,则有

- 有效性:当一个参数有多个无偏估计时,估计方差越小则越有效。
- 相合性:样本容量n趋于无穷大时,估计量的期望等于估计参数,估计量的方差为0。
- 无偏性:样本容量n确定的情况下,样本参数估计值的数学期望等于被估计的总体参数值。足够多次采样,则有
- 区间估计
区间估计是常用的估计方式,也是假设检验的基础。
与点估计的区别在于:点估计是直接将样本参数当做总体参数,结果是唯一一个确定的值;而区间估计是一个数值区间,但有一定把握说总体的参数在这个区间内。
以相同的抽样方式,获得K组抽样样本,样本大小是n,每组样本按某一置信度,比如说95%,计算出置信区间,那么将会有0.95*K组所计算出来的置信区间中包含有总体待估计参数值。
对于标准正态分布,0.95置信度的区间半径是 是标准误差(SE),公式看出,样本足够大时,区间半径就变得很小。
是标准误差(SE),公式看出,样本足够大时,区间半径就变得很小。
形象地说,区间估计就像在池塘撒网捕鱼,网的半径就是区间,半径大小由置信度、样本大小、样本方差共同决定。样本大小和方差一定时,0.99的置信区间比0.95要大,对于0.95置信区间,一百次网下去,可能会有95次网到我想要的鱼,但是我们并不知道是不是现在这一网捕到的这条。
大数定理与中心极限定理
- 大数定理。不管是强大数定理还是弱大数定理,都表达着这样一个意思:当样本数量足够大时,这些样本的均值无限接近总体的期望。
- 中心极限定理。不管样本总体服从什么分布,当样本数量足够大时,样本的均值以正态分布的形式围绕总体均值波动。
中心极限定理
随着抽样次数增多,样本均值的抽样分布趋向于服从正态分布。这里需要注意的是,抽样次数并不是样本量,一次实验只是一次抽样,只能得到一个样本均值。
中心极限定理是概率论的重要定理,它是接下来谈到的显著性检验的基础。 如果一组数据属于正态分布,我们可以根据正态分布的概率密度函数推算出置信区间或 ,当一组数据不属正态分布时,我们仍然可以依据中心极限定理和正态分布的函数推导出置信区间和对应的
,当一组数据不属正态分布时,我们仍然可以依据中心极限定理和正态分布的函数推导出置信区间和对应的 。
。
置信度(置信水平)、显著性水平、置信区间、抽样误差、p-value
有了以上背景知识铺垫,可以深入了。
简要:
- 显著性水平:
 ,概率,人为给定,一般选0.05 。与正态分布的二倍标准差有关。【用于假设检验】
,概率,人为给定,一般选0.05 。与正态分布的二倍标准差有关。【用于假设检验】 - 置信度(置信水平):
 ,概率,人为给定,一般选0.95 (95%)。与正态分布的二倍标准差有关。【用于参数估计】
,概率,人为给定,一般选0.95 (95%)。与正态分布的二倍标准差有关。【用于参数估计】 - 置信区间:绝对差异±抽样误差
- 抽样误差:95%置信度
 下的抽样误差是1.96*样本标准差
下的抽样误差是1.96*样本标准差 - p-value:概率,是计算出来的。表示实验数据(样本、观测结果)出现的概率。
问题重述
为比较实验组和对照组的转化率差异,我们需要首先收集实验组和对照组的转化率数据,经过7天的观察,对照组的转化率为40%,实验组为41%,是否实验组转化率优于对照组?
你也许会说因为实验组转化率比对照组高了1%,所以实验组能实现更高的转化率。但是由于抽样误差的存在,这样的描述也许并不准确。更smart的表述可能是这样的:
我认为实验组转化率相比对照组转化率高0.8-1.2%(1% ± 0.2 %), 置信度为95%。
在这句话中,1%是实验组和对照组的绝对差异(即41%-40%), ± 0.2 % 是抽样误差,绝对差异±抽样误差给出了置信区间的范围为0.8%-1.2%。
置信度95%说的是我们有95%的自信能说出“实验组转化率相比对照组转化率高0.8-1.2%”这句话。从概率论的角度解释,就是在其他参数不变的情况下,如果我们重复做同样的实验100次,那么有95次得出的实验组和对照组的转化率差异都在0.8%-1.2%这个区间内。
因此,置信区间是一个区间,使得重复实验n次具有一定概率(这个概率就是置信度)的结果都落在此区间内。而置信度是人为给定的,我们需要在实验开始前选定一个置信度(常用90%、95%和99%, 95%在A/B Test中最常用),它会影响这个实验所需的样本量大小和显著性检验的结果。
如果我们想知道在这个世界上有多少人喜欢吃橘子,我们不可能去调查世界上所有人的喜好,只能通过抽样的方法用样本来推断总体。假设在这个世界上有50%的人真正喜欢吃橘子,但是否真的是50%我们是不确定的。于是我们试图通过随机抽样来检验这个值到底对不对,于是我们每次随机抽取100个人,并且重复抽样n次,得到n个样本(样本量为100)。如果用  来表示每次抽样喜欢吃橘子的人的比例,那么重复抽样n次会得到n个
来表示每次抽样喜欢吃橘子的人的比例,那么重复抽样n次会得到n个  。不管
。不管  落在距离总体均值多么远的地方, 总有68.2%个落在距离总体均值一个标准差 (
落在距离总体均值多么远的地方, 总有68.2%个落在距离总体均值一个标准差 (  ) 的范围内,95.4%个落在距离总体均值两个标准差 (
) 的范围内,95.4%个落在距离总体均值两个标准差 (  ) 的范围内,99.7%个落在距离总体均值三个标准差 (
) 的范围内,99.7%个落在距离总体均值三个标准差 (  ) 的范围内(中心极限定理和正态分布的运用)。 特别的,有95%个落在距离总体均值1.96倍个标准差 (
) 的范围内(中心极限定理和正态分布的运用)。 特别的,有95%个落在距离总体均值1.96倍个标准差 (  ) 的范围内。
) 的范围内。
反过来思考,以一次抽样的观测值  为中心,往前和往后推大约1.96
为中心,往前和往后推大约1.96  的区间,就有可能抓住那个真实的
的区间,就有可能抓住那个真实的  。如果重复抽样无数次,构成无数个这样的区间,有95%个区间会包含真实的
。如果重复抽样无数次,构成无数个这样的区间,有95%个区间会包含真实的 ,只有5%个区间不包含。在这个例子里,如果一次随机抽样的结果是80%的人喜欢吃橘子,标准差为sqrt(0.20.8/100)=0.04,抽样误差为1.960.04, 那么可以说我们95%肯定这个世界上爱吃橘子的人的比率在[80%±1.960.04] 这个区间内。
,只有5%个区间不包含。在这个例子里,如果一次随机抽样的结果是80%的人喜欢吃橘子,标准差为sqrt(0.20.8/100)=0.04,抽样误差为1.960.04, 那么可以说我们95%肯定这个世界上爱吃橘子的人的比率在[80%±1.960.04] 这个区间内。
通过上面的例子,我们知道置信区间的上界是样本均值+抽样误差,下界是样本均值-抽样误差,95%置信度下的抽样误差是1.96样本标准差。
当得到了一个置信区间后,我们需要通过统计上的假设检验来判断这次抽样的结果是否具有统计上的显著性。在这个例子中,由于[80%±1.96*0.04]这个区间不包含我们事先的假设0.5,并且我们已经95%肯定这个区间包含真实的值,那么先前的假设的0.5是非常值得怀疑的,是我们应该拒绝的。
最小样本量
这里以t检验作为实例解释,可以看完假设检验篇节再看这部分。
假设检验是用来判断样本与样本、样本与总体的差异是由抽样误差引起还是本质差别造成的统计推断方法。如果能通过假设检验方式,验证样本和总体差异不大,那么就可以说样本量足够多了。
针对小样本问题,也可以用t检验来处理,t检验用于检测样本平均数与总体平均数差距是否显著。t检验适应于:
1,已知总体均值,未知总体标准差;
2,已知样本均值,标准差;
3,总体满足或近似正态分布。
t检验公式:





那么据此可以求最小样本量
上面的t检验的例子中,我们已知样本量,检验样本是否跟总体一致。那么,我们也可以假设样本跟总体一致,来反推临界样本量值。至于总体分布,如前所述,根据中心极限定理,0-1分布在样本足够多时服从正态分布,设总体 服从
服从

其中,σ是样本标准差,err是误差。
试看下面的例子:
举例:某电商app中某个广告位最近1小时的行为数据120条,其中点击行为18条,样本点击率15%,请问该点击率是否能反映真实点击率?
1,假设置信度95%,边际误差3%(也就是点击率置信区间 [12%,18%]),查t分布表,当样本趋于无穷大时,t=1.96,也就是标准正态分布N(0,1)分布的95%置信区间对应的x值。
2,带入最小样本公式:
也就是至少需要544个样本,统计的点击率15%才比较可信,显然120个样本是不够的。
假设检验
参数检验(parameter test)全称参数假设检验,是指对参数平均值、方差进行的统计检验。参数检验是推断统计的重要组成部分。当总体分布已知(如总体为正态分布),根据样本数据对总体分布的统计参数进行推断。
先由测得的样本数据计算检验统计量,若计算的统计量值落入约定显著性水平a 时的拒绝域内,说明被检参数之间在所约定的显著性水平a 下在统计上有显著性差异;反之, 若计算的统计量值落入约定显著性水平a 时的接受域内,说明被检参数之间在统计上没有显著性差异,是同一总体的参数估计值。
个人理解:全称应该是 统计参数假设检验。假设总体分布为正态分布,此时总体的统计参数(平均值与方差就已经知道)。在这种情况下,有一个随机样本,我们要检验的是这个样本是否属于这个总体。直接用样本是无法判断的,因为没有对比对象(牢记样本是一个向量,不是一个值)。我们需要一个值来做比较,这个值称为统计量——构造一个统计量函数应用在样本上,如平均值。这样就可以利用样本均值与总体均值做比较。进而引出如何比较才是有效的问题。可以利用两个均值的差来看差异,但这个差异大小如何断定是随机误差的且可以接受的。这就需要置信区间、置信度和p值了。
扩大一些范围:样本是由多个数据组成的,不便得出一个概率值。为了便于计算,我们需要选取一个统计量,即样本数据的某种函数。而这个函数根据总体的假设服从某种分布,比如T分布、卡方分布、F分布等等。有了这个统计量及其分布,就可以计算出当前样本该统计量的概率。 如果这个概率小于显著性水平,则说明假设不成立。有时为了计算方便,也可以先算出达到显著性水平时的统计量值,进而得出一个假设成立时的统计量区间。如果根据样本计算处的统计量在这个区间内,则接受假设,否则就拒绝假设。
在生活中,往往会对一些事情有自己的看法(这就是假设,也就是原假设),那么如何知道自己的看法(假设)对不对呢?这时候就会做实验来验证。验证是需要有数据支撑的,这个数据就来源于我们的实验,称为实验数据(观测数据)。现在我们有了假设,也有了数据,剩下的问题就是,如何使用数据来验证假设的真假(术语就是:能否拒绝原假设)。方法就是“假设检验”。整个思想产生的过程要牢记:“先有假设,才有检验”。
区别参数估计
概念
参数估计是指用样本统计量去估计总体参数。
假设检验是指对总体参数所做的一个假设开始,然后搜集样本数据,计算出样本统计量,进而运用这些数据测定假设的总体参数在多大程度上是可靠的,并作出接受假设还是拒绝假设的判断。假设检验运用的是小概率原理。
联系
1.都是根据样本信息对总体的数量特征进行推断;
2.都是以抽样分布为理论依据,建立在概率论基础之上的统计推断。
区别
1.参数估计是以样本资料估计总体参数的真值,而假设检验是以样本资料对总体的先验假设是否成立;
2.参数估计中的区间估计是以样本统计量为中心的双侧之心区间,假设检验既有单侧检验又有双侧检验;
3.参数估计中的区间估计是以大概率为标准,通常以较大的把握度1-  去保证总体参数的置信区间,而假设检验是以小概率原理为标准,通常给定很小的显著性水平
去保证总体参数的置信区间,而假设检验是以小概率原理为标准,通常给定很小的显著性水平  去检验样本对总体参数的先验假设是否成立。
去检验样本对总体参数的先验假设是否成立。
4.用统计量推断参数时,如果参数未知,则这种推断叫参数估计——用统计量估计未知的参数;如果参数已知(或假设已知),需要利用统计量检验已知的参数是否靠谱,此时的统计推断即为假设检验。
例子
推断全校学生的平均每天上网时间。因为参数未知,要靠抽样的数据进行推断,此时进行的就是参数估计,用抽样得到的统计量——样本平均上网时间(比如说3小时)来估计全校学生平均上网时间。【参数估计】
如果先前有人已得出得出论断,学生平均上网时间为5小时,而你不知该参数可不可信,这时做的就是假设检验,通过样本得到的平均3小时的上网时间告诉你,先前关于总体的平均上网时间为5小时这一信息很可能是不靠谱的,无法通过检验。【假设检验】
假设检验概念
1. 假设检验
- 原假设(零假设):把要检验的假设称为原假设,记为H0
- 对立假设(备择假设):与原假设完全对立的假设,记为H1
原假设与对立假设设反了,会导致不同结论。那如何设置原假设呢?参考下面惯例:
将不宜轻易加以否定的假设作为原假设。 H0:样本与总体或样本与样本间的差异是由抽样误差引起的; H1:样本与总体或样本与样本间存在本质差异;
第一类错误:俗称“误判”,指的是将正确的看成错误的。术语为:如果原假设是正确的,但检验结果劝我放弃原假设(拒绝原假设)。通常把第一类错误出现的最大概率记为α.
- 第二类错误:俗称“漏判”,指的是将错误的看成正确的。术语为:如果原假设是错误的,但检验结果劝我接受原假设。通常把第二类错误出现的最大概率记为β.
- 做检验,都是用观测样本来对“统计量”进行计算,因此,选用“统计量”也是一个知识点。
注意:我们都不希望犯错误,即希望α与β都小。但事与愿违,α与β无法同时变小。生活中,犯第一类错误造成的影响要大于犯第二类错误,因此,我们一般控制α保持在一个足够小的值,这也就是显著性检验了。
2. 显著性检验
显著性检验是统计检验的一种,用于检验“两组数据是否有差异”与“差异是否显著”的办法。显著性检验即在假设检验的基础上,主要控制犯第一类错误出现概率α。但α因为不能过小,会导致β过大。所以常用α=0.05、0.10、0.01
- 两组数据:实验组数据(观测值)与对照组数据(期望值)
- 差异:两组数据的差别。如果两组数据完成相同,显然是无差别的。可以说,只要两组数据不完成相同,那一定存在差异。那么这个差异是由随机变化导致的还是其他因素引起的呢?这个差异明显(显著)吗?会怎么样影响实验结果呢?这些都需要进行验证。
- 显著:个人理解为“明显”,1与1.01的差异是不明显的,但1与100的差异是很明显的。
- 显著区别:一般来说,我们观测的是由随机变化导致的差异,所以当观测差异大于随机差异时,称之为“统计学意义上的显著区别”。通俗地说,就是实验数据与对照数据差异很大。如何判断这个差异大还是小呢?
显著性差异:对数据差异性的评价,用bool值来表达,通过显著性水平α值和p值对比。解决“判断差异大小”的问题。
当数据之间具有了显著性差异,就说明参与比对的数据不是来自于同一总体(Population),而是来自于具有差异的两个不同总体,这种差异可能因参与比对的数据是来自不同实验对象的,比如一些一般能力测验中,大学学历被试组的成绩与小学学历被试组会有显著性差异。也可能来自于实验处理对实验对象造成了根本性状改变,因而前测后测的数据会有显著性差异。 显著性差异是一种有量度的或然性评价。比如,我们说A、B两数据在0.05水平上具备显著性差异,这是说两组数据具备显著性差异的可能性为95%。两个数据所代表的样本还有5%的可能性是没有差异的。这5%的差异是由于随机误差造成的。
显著性水平:一个概率——当原假设为正确时,我们把它拒绝了的最大概率(或者粗略视为允许观测样本出现的最小概率)。很像α的概念,其实就是α。在检验中,选定α时(如α=0.05),我们称该检验为“显著性水平为α(α=0.05)的显著性检验”,简称“水平为α的检验”。
p值:(为了解决拒绝域问题而诞生)也是一个概率——当原假设为正确时,实验数据(样本、观测结果)出现的概率。如果p值很小,说明原假设是正确的概率很小,而如果出现了,根据小概率原理,我们就有理由拒绝原假设。p值越小,我们拒绝原假设的理由越充分。
3. 显著性差异、显著性水平与p值的关系
显著性水平α是人为规定的,而P值是实验数据算出来的。通过对比α与p值的大小来判断是否接受原假设,进而判断是否有显著性差异。
检验中,依据显著性水平α大小把概率划分为二个区间,小于给定标准的概率区间称为拒绝区间,大于这个标准则为接受区间。计算p值,对比显著性水平α。【脑海中应浮现一个横坐标,以α的值画一条竖线,左边为拒绝区间,右边为接受区间。然后看看p值落在左边还是右边。】如果p>α,则说明p值落在竖线右边,是接受区间,即接受原假设;如果p<α,则说明p值落在竖线左边,是拒绝区间,即拒绝原假设。p值越大(小),越有充分的理由接受(拒绝)原假设。
例子:如果α=0.05,p=0.3
显然,p>α ,即是说,当原假设是正确时,观测样本能够出现的概率为p=0.3,比允许观测样本出现的最小概率(α=0.05)要高,(说明了原假设正确时,出现这个观测样本是正常的)。可以接受原假设,但不能说明原假设是正确的。同时可以说,样本间无显著性差异。
- 如果α=0.05,p=0.03
显然,p<α ,即是说,当原假设是正确时,观测样本能够出现的概率为p=0.03,比允许观测样本出现的最小概率(α=0.05)还低,(也就是说,原假设正确时,不应该出现这个观测样本)。反证了原假设是错误的,应该拒绝原假设。同时可以说,样本间有显著性差异。
检验的类型
参数检验和非参数检验。参数检验要求样本来源于正态总体(服从正态分布), 且这些正态总体拥有相同的方差,在这样的基本假定(正态性假定和方差齐性假定)下检验各总体均值是否相等,属于参数检验。或者说,如果假设可以用一个参数的集合来表示,则为参数检验。否则为非参数检验——如对假设“总体为正态分布”做出检验的问题。
在开始检验前,先了解下统计学中的术语:因素与元。“因素”:自变量;“元”:因变量。在统计假设检验中,把待检验的未知变量称之为“元”,而把影响未知变量的行为 (事件)称之为“因素”。类似于机器学习中的features(因素)和labels(元)。拥有多个特征便是“多因素”,而拥有多个标签便是“多元”。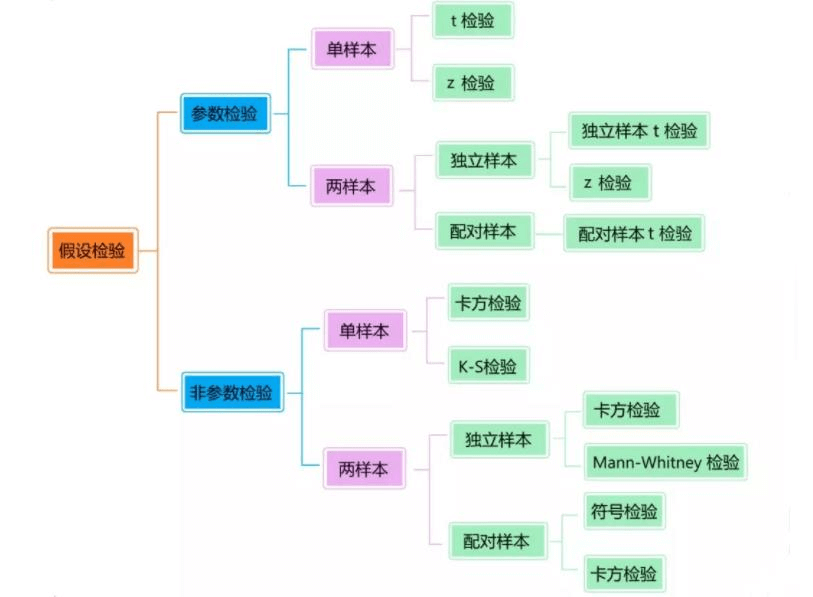
1. 参数检验及步骤
牢记:参数检验一定满足正态分布,所有的检验都依赖正态分布。检验的东西永远是观测样本,看看它在某个正态分布下,产生这个观测样本的概率。
1、提出检验假设又称无效假设,符号是H0;备择假设的符号是H1。
H0:样本与总体或样本与样本间的差异是由抽样误差引起的;
H1:样本与总体或样本与样本间存在本质差异;
预先设定的检验水准为0.05;当检验假设为真,但被错误地拒绝的概率,记作α,通常取α=0.05或α=0.01。
2、选定统计方法,由样本观察值按相应的公式计算出统计量的大小,如X2值、t值等。根据资料的类型和特点,可分别选用Z检验,T检验,秩和检验和卡方检验等。
3、根据统计量的大小及其分布确定检验假设成立的可能性P的大小并判断结果。若P>α,结论为按α所取水准不显著,不拒绝H0,即认为差别很可能是由于抽样误差造成的,在统计上不成立;如果P≤α,结论为按所取α水准显著,拒绝H0,接受H1,则认为此差别不大可能仅由抽样误差所致,很可能是实验因素不同造成的,故在统计上成立。P值的大小一般可通过查阅相应的界值表得到。
教学中的做法:
1.根据实际情况提出原假设和备择假设;
2.根据假设的特征,选择合适的检验统计量;
3.根据样本观察值,计算检验统计量的观察值(obs);
4.选择许容显著性水平,并根据相应的统计量的统计分布表查出相应的临界值(ctrit);
5.根据检验统计量观察值的位置决定原假设取舍。
2 各种检验
具体统计量和分布意义详看四大统计量与其抽样分布,这里只给出公式和检验案例。
- t检验
判断两类样本在某一变量上的均值差异是否显著。
- 卡方检验(Chi-square test)
用于检验两个(或多个)率或构成比之间差别是否有统计学意义,配对卡方检验检验配对计数资料的差异是否有统计学意义。检验实际频数(A)和理论频数(T)的差别是否由抽样误差所引起的。也就是由样本率(或样本构成比)来推断总体率或构成比。
- F检验
F检验是看F分布,而F value是SSB/SSE,组间平方和(SSB)和组内平方和(SSE),如果我们把组间平方和理解为两组之间的差异,组内平方和理解为两组内部不同数据的差异的话,那么简单点说,两个数据在有差异的前提下,究竟是组间的差异大,还是组内的差异大呢?如果是组间的差异大,那么这两组数据本身不一致的概率就非常大了,对应F值比较大.
应用在机器学习上的特征选择基本思想: 按照不同的标签类别将特征划分为不同的总体,我们想要检验的是不同总体之间均值是否相同 (或者是否有显著性差异)。方差分析可用于控制一个或多个自变量来检验其与因变量的关系,进而检测某种实验效果, 就一般的特征选择问题而言,和卡方检验一样,我们依然比较关心的是特征的相对重要性,所以可以按每个特征 F 值的大小进行排序,去除F值小的特征。

若有收获,就点个赞吧
0 人点赞
