以下参考 https://zhuanlan.zhihu.com/p/50443871 值得一读
基础知识:
- Bi-LSTM
-
预训练模型
首先我们要了解一下什么是预训练模型,举个例子,假设我们有大量的维基百科数据,那么我们可以用这部分巨大的数据来训练一个泛化能力很强的模型,当我们需要在特定场景使用时,例如做文本相似度计算,那么,只需要简单的修改一些输出层,再用我们自己的数据进行一个增量训练,对权重进行一个轻微的调整。
预训练的好处在于在特定场景使用时不需要用大量的语料来进行训练,节约时间效率高效,bert就是这样的一个泛化能力较强的预训练模型。三者对比
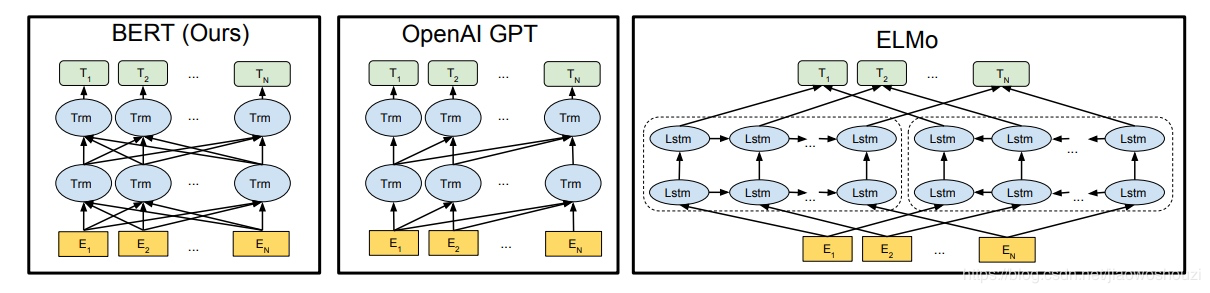
1. ELMO(Embeddings from language model)
本质思想就是:事先用语言模型学习到字符集别的embedding,再根据字符级别的embedding得到word embedding,此时多义词依旧是无法区别的。最后根据上下文对word embedding 进行动态调整,这里使用的是一个双向的lstm网络模型。
缺点在于:特征提取LSTM比Transformer逊色一些, 双向特征融合的能力弱
2.GPT
也是第一个阶段是利用语言模型进行预训练,第二阶段通过 Fine-tuning 的模式解决下游任务。区别在于,首先,特征抽取器不是用的 RNN,而是用的 Transformer,GPT 的预训练虽然仍然是以语言模型作为目标任务,但是采用的是单向的语言模型,所谓“单向”的含义是指:语言模型训练的任务目标是根据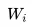 单词的上下文去正确预测单词
单词的上下文去正确预测单词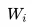 ,
,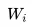 之前的单词序列 Context-before 称为上文,之后的单词序列 Context-after 称为下文。ELMO 在做语言模型预训练的时候,预测单词
之前的单词序列 Context-before 称为上文,之后的单词序列 Context-after 称为下文。ELMO 在做语言模型预训练的时候,预测单词 同时使用了上文和下文,而 GPT 则只采用 Context-before 这个单词的上文来进行预测,而抛开了下文。简言之,只用上文预测下文,没有反向。也是其缺点所在了。
同时使用了上文和下文,而 GPT 则只采用 Context-before 这个单词的上文来进行预测,而抛开了下文。简言之,只用上文预测下文,没有反向。也是其缺点所在了。
3.Bert
谷歌提出的预训练+微调的NLP任务框架,可以解决目前NLP四大任务中的大部分。本次建立标准样本库选择的文本分类算法。Bert 其实和 ELMO 及 GPT 存在千丝万缕的关系,比如如果我们把 GPT 预训练阶段换成双向语言模型,那么就得到了 Bert;而如果我们把 ELMO 的特征抽取器换成 Transformer,那么我们也会得到 Bert。所以你可以看出:Bert 最关键两点,一点是特征抽取器采用 Transformer;第二点是预训练的时候采用双向语言模型。
每个单词有三个 embedding: 位置信息 embedding,这是因为 NLP 中单词顺序是很重要的特征,需要在这里对位置信息进行编码;
- 单词 embedding, 这个就是我们之前一直提到的单词 embedding;
- 句子 embedding,因为前面提到训练数据都是由两个句子构成的,那么每个句子有个句子整体的 embedding 项对应给每个单词。把单词对应的三个 embedding 叠加,就形成了 Bert 的输入。
总结起来优点就是:
- 首先是两阶段模型,第一阶段双向语言模型预训练,这里注意要用双向而不是单向,第二阶段采用具体任务 Fine-tuning 或者做特征集成;
- 第二是特征抽取要用 Transformer 作为特征提取器而不是 RNN 或者 CNN;
- 第三,双向语言模型可以采取 CBOW 的方法去做(当然我觉得这个是个细节问题,不算太关键,前两个因素比较关键)。
现在的Bert预训练模型也由有语言版本,对于大部分语言,都可以直接适用于训练模型,普适较好,微调训练的时间还在接受范围内,但是在predict阶段,速度真是感人了。。。。。华为最近开源的TinyBert和哪吒,是大部分公司和大厂在做实时任务时需要考虑的。
ELMO
2018年的早些时候,AllenNLP的Matthew E. Peters等人在论文《Deep contextualized word representations》(该论文同时被ICLR和NAACL接受,并且还获得了NAACL最佳论文奖,可见这篇论文的含金量)中首次提出了ELMo,它的全称是Embeddings from Language Models,从名称上可以看出,ELMo为了利用无标记数据,使用了语言模型,我们先来看看它是如何利用语言模型的。
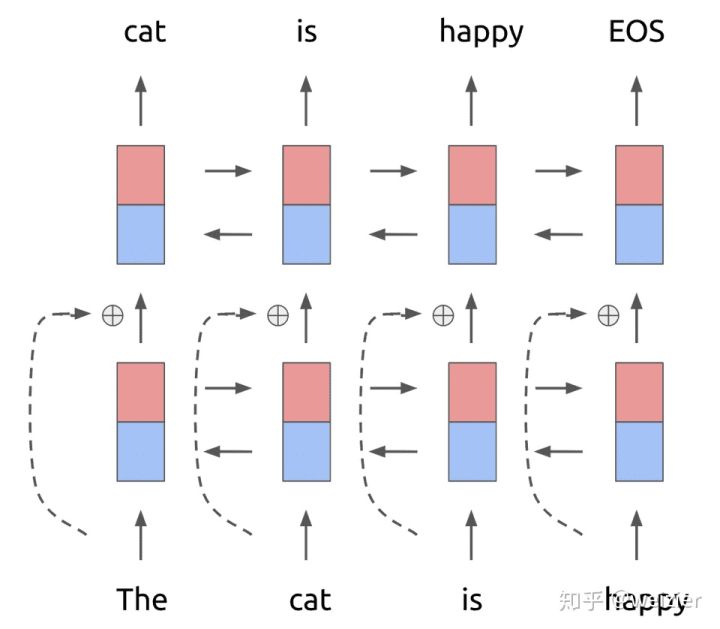<br />基本框架是一个**双层双向**的Bi-LSTM,每层都有前向(forward pass)和后向(backward pass)两种迭代。详细的结构如下图。<br />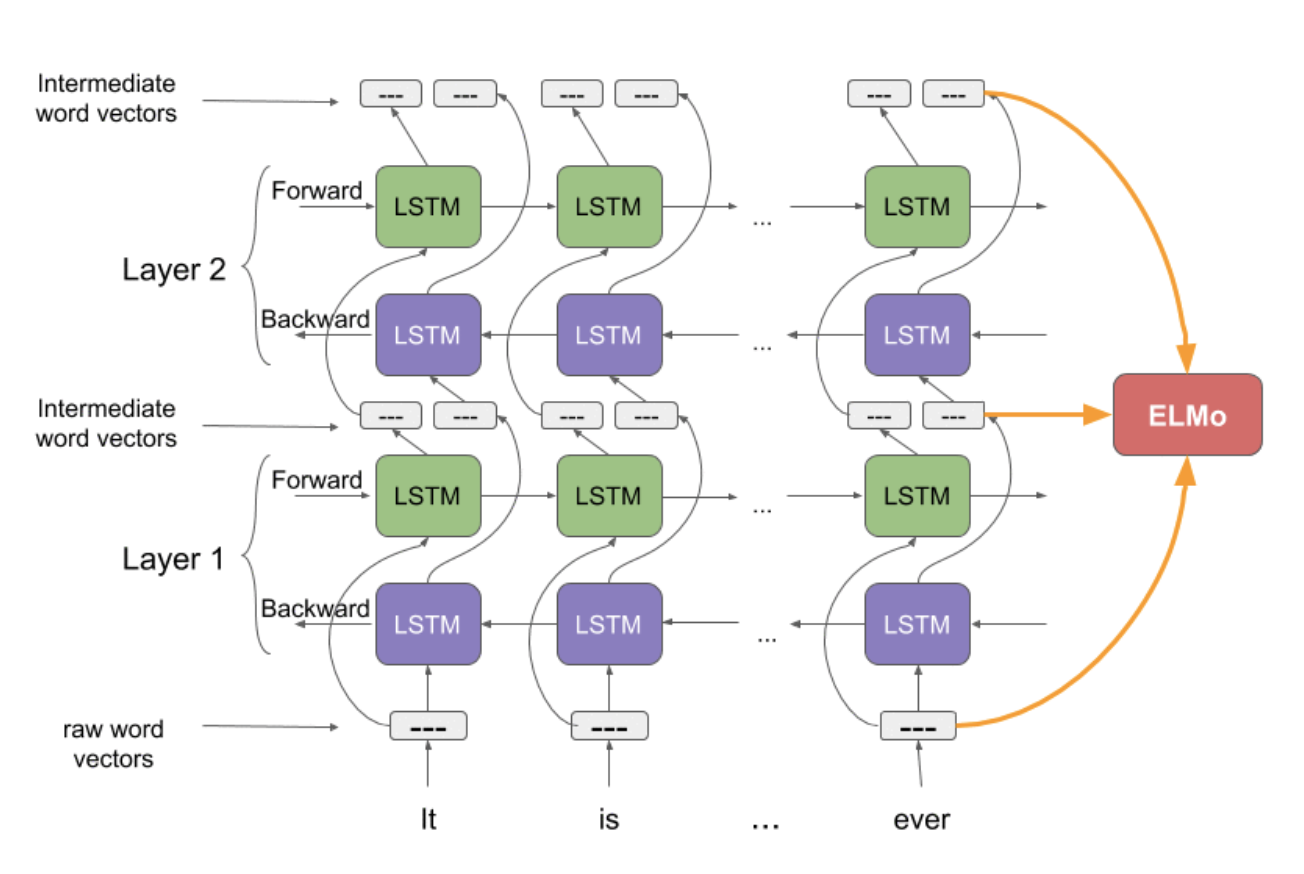
- 上图中的结构使用字符级卷积神经网络(convolutional neural network, CNN)来将文本中的词转换成原始词向量(raw word vector)。CNN结构在下面展示。
- 将这些原始词向量输入双向语言模型中第一层
- 前向迭代中包含了该词以及该词之前的一些词汇或语境的信息
- 后向迭代中包含了该词之后的信息
- 这两种迭代的信息组成了中间词向量(intermediate word vector)
- 这些中间词向量被输入到模型的下一层
- 最终表示(ELMo)就是原始词向量和两个中间词向量的加权和
因为双向语言模型的输入度量是字符而不是词汇,该模型能捕捉词的内部结构信息。比如beauty和beautiful,即使不了解这两个词的上下文,双向语言模型也能够识别出它们的一定程度上的相关性。
在第一层和第二层之间加入了一个残差结构(一般来说,残差结构能让训练过程更稳定)。做预训练的时候,ELMo的训练目标函数为
这个式子很清晰,前后有两个概率,第一个概率是来自于正向的由左到右的RNN结构,在每一个时刻上的RNN输出(也就是这里的第二层LSTM输出),然后再接一个Softmax层将其变为概率含义,就自然得到了  ;与此类似,第二个概率来自反向的由右到左的RNN结构,每一个时刻RNN的输出经过Softmax层后也能得到一个概率大小,表示从某个词的下文推断该词的概率大小。
;与此类似,第二个概率来自反向的由右到左的RNN结构,每一个时刻RNN的输出经过Softmax层后也能得到一个概率大小,表示从某个词的下文推断该词的概率大小。
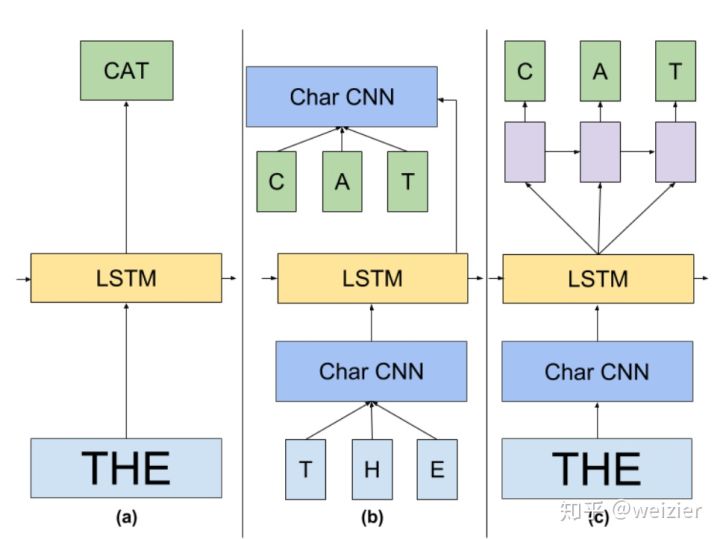
ELMo的基本框架便是2-stacked biLSTM + Residual的结构,不过和普通RNN结构的不同之处在于,ELMo借鉴了2016年Google Brain的Rafal Jozefowicz等人发表的一篇论文《Exploring the Limits of Language Modeling》,其主要改进在于输入层和输出层不再是word,而是变为了一个char-based CNN结构,ELMo在输入层和输出层考虑了使用同样的这种结构,该结构如下图示

这样做有什么好处呢?因为输入层和输出层都使用了这种CNN结构,我们先来看看输出层使用这种结构怎么用,以及有什么优势。我们都知道,在CBOW中的普通Softmax方法中,为了计算每个词的概率大小,使用的如下公式的计算方法
说白了,也就是先通过向量点乘的形式计算得到logits,然后再通过softmax变成概率意义,这本质上和普通的分类没有什么区别,只不过是一个较大的|V|分类问题。现在我们假定char-based CNN模型是现成已有的,对于任意一个目标词都可以得到一个向量表示  ,相应的当前时刻的LSTM的输出向量为h,那么便可以通过同样的方法得到目标词的概率大小
,相应的当前时刻的LSTM的输出向量为h,那么便可以通过同样的方法得到目标词的概率大小
在原论文中,把这种先经过CNN得到词向量,然后再计算Softmax的方法叫做CNN Softmax,而利用CNN解决有三点优势值得注意,第一是,CNN能够减少普通做Softmax时全连接层中的必须要有的|V|_h的参数规模,只需要保持CNN内部的参数大小即可,而一般来说,CNN中的参数规模都要比|V|_h的参数规模小得多;另一方面,CNN可以解决OOV (Out-of-Vocabulary)问题,这个在翻译问题中尤其头疼;最后一方面,在预测阶段,CNN对于每一个词向量的计算可以预先做好,更能够减轻inference阶段的计算压力。补充一句:普通Softmax在大词典上的计算压力,都是因为来自于这种方法需要把一个神经网络的输出通过全连接层映射为单个值(而每个类别需要一个映射一次,就是一次h大小的计算规模,|V|次映射便需要总共|V|h这么多次的映射规模),对于每个类别的映射参数都不同,而CNN Softmax的好处就在于能够做到对于不同的词,映射参数都是共享的,这个共享便体现在使用的CNN中的参数都是同一套,从而大大减少参数的规模。
同样的,对于输入层,ELMo也是用了一样的CNN结构,只不过参数不一样而已,和输出层中的分析类似,输入层中CNN的引入同样可以减少参数规模(不过《Exploring the Limits of Language Modeling》文中也指出了训练时间会略微增加,因为原来的look-up操作可以做到更快一些),对OOV问题也能够比较好的应对,从而把词典大小不再限定在一个固定的词典大小上。最终ELMo的主要结构便如下图(b)所示,可见输入层和输出层都是一个CNN,中间使用Bi-LSTM框架,至于具体细节便如上两张图中所示。
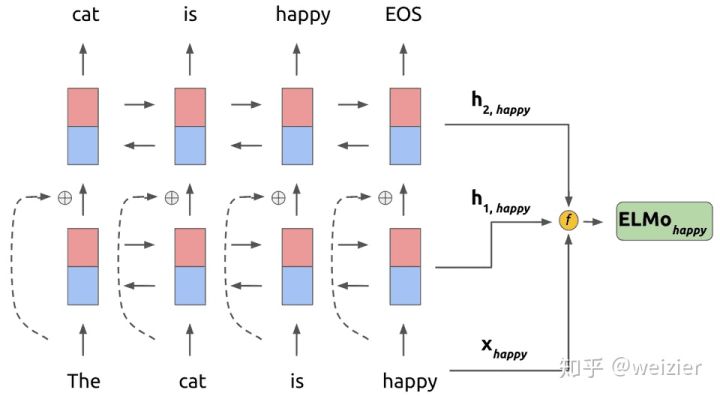
最后,在大规模语料上训练完成的这种CNN-BIG-LSTM模型(原文如此叫法),怎么用呢?其实,如果把每一层的输出结果拿出来,这里大概有三层的词向量可以利用:输入层CNN的输出,即是LSTM的输入向量,第一层LSTM的输出和第二层的输出向量。又因为LSTM是双向的,因此对于任意一个词,如果LSTM的层数为L的话,总共可获得的向量个数为2L+1,表示如下
到这里还只是把ELMo的向量给抽取出来了,具体用的话,对于每一个词,可以根据下面的式子得到它的向量,其中  是一个scale因子,加入这个因子主要是想要将ELMo的向量于具体任务的向量分布拉平到同一个分布水平,这个时候便需要这么一个缩放因子了。另外,
是一个scale因子,加入这个因子主要是想要将ELMo的向量于具体任务的向量分布拉平到同一个分布水平,这个时候便需要这么一个缩放因子了。另外,  便是针对每一层的输出向量,利用一个softmax的参数来学习不同层的权值参数,因为不同的任务需要的词语意义的粒度也不一致,一般认为浅层(bi-lstm第一层)的表征比较倾向于句法,而高层(bi-lstm第二层)输出的向量比较倾向于语义信息,因此通过一个softmax的结构让任务自动去学习各层之间的权重,自然也是比较合理的做法。
便是针对每一层的输出向量,利用一个softmax的参数来学习不同层的权值参数,因为不同的任务需要的词语意义的粒度也不一致,一般认为浅层(bi-lstm第一层)的表征比较倾向于句法,而高层(bi-lstm第二层)输出的向量比较倾向于语义信息,因此通过一个softmax的结构让任务自动去学习各层之间的权重,自然也是比较合理的做法。
前面我们说过,无论是基于传统统计的N-gram还是普通神经网络的NNLM结构,都会有一个很严重的问题,那就是计算复杂度随着上下文窗口N大小的增大急剧上升(其中N-gram是指数上升,NNLM是以  的形式增加,|d|是词向量的维度,虽然NNLM已经改观了很多,但依然是一个斜率很大的线性增加关系),后来CBOW和Skip-gram以及再后来的GloVe等等终于做到了计算复杂度与所选窗口大小无关,只与词典大小和词向量维度相关(不过需要指出的是,这里讨论的计算复杂度只是预测单个词的计算时间复杂度,如果是求整个输入序列的话,还是避免不了要与序列长度相关,在这一点上和下面要分析的RNN在横向的时间序列上有一个时间复杂度,其原因是一致的),并且近些年得益于硬件持续的摩尔定律发挥威力,机器的计算能力也有长足的进步,因此在这两方面因素的作用下,以word2vec为代表的方法大放光彩,引领了一波NLP的发展浪潮。
的形式增加,|d|是词向量的维度,虽然NNLM已经改观了很多,但依然是一个斜率很大的线性增加关系),后来CBOW和Skip-gram以及再后来的GloVe等等终于做到了计算复杂度与所选窗口大小无关,只与词典大小和词向量维度相关(不过需要指出的是,这里讨论的计算复杂度只是预测单个词的计算时间复杂度,如果是求整个输入序列的话,还是避免不了要与序列长度相关,在这一点上和下面要分析的RNN在横向的时间序列上有一个时间复杂度,其原因是一致的),并且近些年得益于硬件持续的摩尔定律发挥威力,机器的计算能力也有长足的进步,因此在这两方面因素的作用下,以word2vec为代表的方法大放光彩,引领了一波NLP的发展浪潮。
然而,在今天看来,无论word2vec中的模型,还是GloVe的模型,模型都过于简单,它们都受限于所使用的模型表征能力,某种意义上都只能得到比较偏上下文共现意义上的词向量,并且也很少考虑过词序对于词的意义的影响(比如CBOW从其名称来看就是一个bag-of-words,在模型的输入中没有词序的概念)。理论上,RNN结构的计算复杂度,跟两个方向上都有关系,一方面是纵向上,另一方面是横向上,纵向上主要是RNN结构本身的时间复杂度,这个复杂度只与RNN结构内部的hidden state维度以及模型结构的复杂度,在ELMo中的话还跟词典大小相关(因为最后一层还是一个词典大小上的分类问题,以及输入也需要维护一个词典大小的loop up操作);在横向上的计算复杂度,就主要是受制于输入序列的长度,而RNN结构本身因为在时间序列上共享参数,RNN本身的计算复杂度这一部分不变,因而总的ELMo结构计算复杂度主要有词典大小、隐藏层输出维度大小、模型的结构复杂度以及最后的输入序列长度,前三者可以认为和之前的模型保持一致,最后的输入序列长度,也只是与其保持线性关系,虽然系数是单个RNN单元的计算复杂度,斜率依然很大(通常RNN结构的训练都比较费时),但是在机器性能提升的情况下,这一部分至少不是阻碍词向量技术发展的最关键的因素了。
因此,在新的时代下,机器性能得到更进一步提升的背景下,算法人员都急需一种能够揭示无论词还是句子更深层语义的方法出现,我想ELMo正是顺应了这种时代的需要而华丽诞生。
*ELMo的思想足够简单,相比它的前辈们,可以说ELMo并没有本质上的创新,连模型也基本是引用和拼接别人的工作(这似乎从反面证明了真正漂亮的工作从来不是突出各自的模型有多么绚丽,只有无其他亮点的论文,才需要依靠描摹了高清足够喜人眼球的图片去吸引评审人的注意力,因此从这个角度去看,似乎可以得出一个啼笑皆非的结论:论文的漂亮程度与论文图的漂亮程度呈反比),它的思想在很多年前就已经有人在用,并没有特别新奇的地方。
但同时它的效果又足够惊艳,它的出现,在2018年年初,这个也许在NLP历史上并没有多么显眼的年头,掀起了一阵不小的波澜,至少在6项NLP任务上横扫当时的最好结果,包括question answering(SQuAD), textual entailment(SNLI), semantic role labelling(SRL), named entity extraction(NER), coreference resolution(Coref), and sentiment analysis(SST-5)。
而后来的故事以及可预见的将来里,这或许仅仅只是一个开始,就如山洪海啸前的一朵清秀的涟漪。
GPT
大规模语料集上的预训练语言模型这把火被点燃后,整个业界都在惊呼,原来预训练的语言模型远不止十年前Bengio和五年前Mikolov只为了得到一个词向量的威力。然而,当大家还在惊呼,没过几个月,很快在2018年6月的时候,不再属于“钢铁侠”马斯克的OpenAI,发了一个大新闻(相关论文是《Improving Language Understanding by Generative Pre-Training》),往这把火势正猛的烈焰上加了一剂猛料,从而将这把火推向了一个新的高潮。
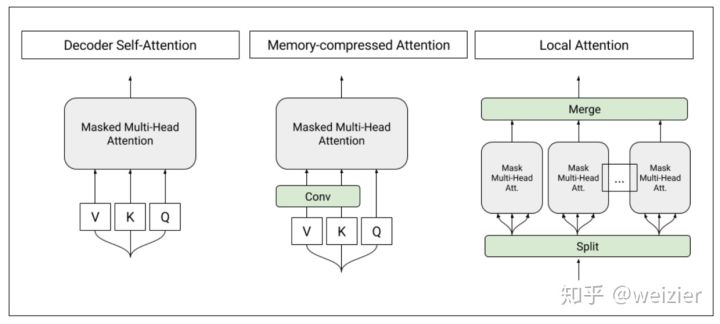
来看看GPT中的是怎么用Transformer的。按照论文中的说法,GPT中使用的Transformer是只用了Decoder,因为对于语言模型来讲,确实不需要Encoder的存在,而具体模型,他们参考了2018年早些时候谷歌发表的一篇论文《Generating Wikipedia by Summarizing Long Sequences》(而GPT名称中的Generative该词便是来自于这篇文章,因为这二者都有用到生成式的方法来训练模性,也就是生成式的Decoder),关于这篇论文中提到的T-DMCA(Transformer Decoder with Memory-Compressed Attention),实际上就是一个Decoder,只不过这篇文章中要做超长的序列输入(可以长达11000个词),为了能够高效节省时间和内存的处理如此长的序列,做了一些Memory-Compressed的工作,主要是两方面:一方面是把一个batch内部的序列按长度进行分组,然后分别在每个组内部进行self-attention操作,这样可以避免将一些很短的句子也padding到整个语料的最大长度;另一方面,通过CNN的操作,把K和V压缩到序列长度更小的一个矩阵,同时保持Q不变,这样也能相当程度上减少计算量。
除了这些具体的模型细节外,GPT本质上就是用了语言模型的目标函数来优化和训练Transformer-Decoder,这个和上文提到过的语言模型保持一致。利用语言模型的目标函数预训练完成后,进阶这便可以在具体的任务上进行finetune,和ULMFiT中的finetune分为两个阶段的方法不一样的是,GPT直接把这两个过程糅合到一个目标函数中,如
其中  是task-specific的目标函数,
是task-specific的目标函数,  则是语言模型的目标函数。论文中说这种联合学习的方式能够让训练效果更好。而在具体如何做迁移学习的方面,GPT大概也同样借鉴了上面提到的《Generating Wikipedia by Summarizing Long Sequences》论文中的做法,非常巧妙的将整个迁移学习的框架做到非常的精简和通用。分类问题中,直接在原序列的开始和末尾添加表示开始和末尾的符号,在Text Entailment问题中(比如Natural Language Inference),将Premise和Hypothesis通过一个中间分隔符“$”连接起来成为一个序列,尔后同样在开头和末尾添加标记符号,文本相似问题中,因为序列1和序列2没有先后关系,因此将先后关系相反的两个序列作为输入,在Question Aswering中,将query和每一个候选的answer都分别连接成一个序列作为输入,最后按各自的打分进行排序。因此,这套输入的表示方法,基本可以使用同一个输入框架来表征许多文本问题(以至于后来的BERT直接借用了这套做法)。除此之外,在输出层,只需要接入一个很简单的全连接层或者MLP便可以,根本不需要非常复杂的模型设计。而整个finetune阶段,新加入的参数极少,只有输出层以及输入层中添加的一些特殊标记(比如分隔符)。
则是语言模型的目标函数。论文中说这种联合学习的方式能够让训练效果更好。而在具体如何做迁移学习的方面,GPT大概也同样借鉴了上面提到的《Generating Wikipedia by Summarizing Long Sequences》论文中的做法,非常巧妙的将整个迁移学习的框架做到非常的精简和通用。分类问题中,直接在原序列的开始和末尾添加表示开始和末尾的符号,在Text Entailment问题中(比如Natural Language Inference),将Premise和Hypothesis通过一个中间分隔符“$”连接起来成为一个序列,尔后同样在开头和末尾添加标记符号,文本相似问题中,因为序列1和序列2没有先后关系,因此将先后关系相反的两个序列作为输入,在Question Aswering中,将query和每一个候选的answer都分别连接成一个序列作为输入,最后按各自的打分进行排序。因此,这套输入的表示方法,基本可以使用同一个输入框架来表征许多文本问题(以至于后来的BERT直接借用了这套做法)。除此之外,在输出层,只需要接入一个很简单的全连接层或者MLP便可以,根本不需要非常复杂的模型设计。而整个finetune阶段,新加入的参数极少,只有输出层以及输入层中添加的一些特殊标记(比如分隔符)。
正是因为有了输入层和输出层的这种通用化设计考虑,一旦中间的Transformer(当然,正如前文所说,这里的Transformer在使用语言模型进行预训练的时候只有Decoder部分,然而在将其当做文本特征提取器的时候,相应的也可以很便利的将其变成Encoder)表征能力足够强大,迁移学习在NLP任务中的威力也会变得更为强大。
果不其然,GPT在其公布的结果中,一举刷新了12项NLP任务中的9项榜单,效果不可谓不惊艳。然而对于OpenAI来讲,GPT底层模型使用的是谷歌提出的Tranformer,正是依靠了Transformer的强大表征能力,使得最终的效果有了一个坚实的基础,然而仅仅过了四个月之后的BERT横空出世,同样也是用了Transformer,同样是谷歌,甚至很多思想也是直接借鉴GPT,GPT作为与BERT气质最为接近的工作,同时也是BERT的前辈,得到的待遇差别如此之大,不知道GPT是否有些可惜和遗憾,相比BERT,GPT并没有带来特别巨大的反响,他的惊艳亮相,迅速变为水里的一声闷响,掀起了一阵涟漪后迅速消散,将整个舞台让位于正值青春光艳照人的BERT,颇有点“成也萧何败也萧何”的味道。
GPT 结构图: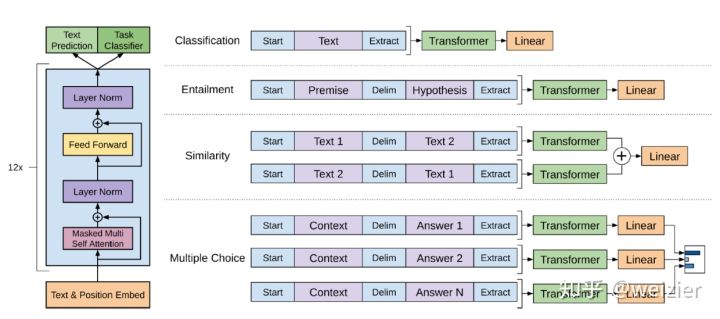
BERT
Bidirectional Encoder Representations from Transformers
BERT模型,本质可以把其看做是新的word2Vec。对于现有的任务,只需把BERT的输出看做是word2vec,在其之上建立自己的模型即可了。
Google AI把他们已经预训练好的BERT模型公布出来,包括英语的base和large模型,另外针对其他语言也放出了中文(仅有的一个非英语的单个模型)和一个102种语言的混合语言预训练模型,这再次触发和引爆了NLP界的集体高潮。
不过,为何BERT能如此引人注目,不妨来一探究竟。私以为,BERT最主要的几个特征分别是
- 利用了真双向的Transformer
- 为了利用双向信息,改进了普通语言模型成为完形填空式的Mask-LM(Mask-Language Model)
- 利用Next Sentence Prediction任务学习句子级别信息
- 进一步完善和扩展了GPT中设计的通用任务框架,使得BERT能够支持包括:句子对分类任务、单句子分类任务、阅读理解任务和序列标注任务
为了更深入理解BERT,我们分别来看看他的这些特征。
首先看看BERT如何使用的双向Transformer,其实很好理解,可以用一句话来回答为什么BERT使用的是双向Transformer,那就是:BERT用了Transformer的Encoder框架。但是,我想这样的答案自然是要扣分的,更“求生欲”一点的答案是:因为Encoder中用了Self-attention机制,而这个机制会将每一个词在整个输入序列中进行加权求和得到新的表征,更通俗的说法是每一个词在经过Self-attention之后,其新的表征将会是整个输入序列中所有词(当然也包括它本身)的加权求和,每一个词都达到了“我中有你,你中有我”的境界,如果经过更多的transformer的block(意味着经过更多Self-attention),那么互相交融的程度将会更高,类似于BERT这样深的结构(Base模型是12层,Large模型是24层),经过所有block后,彼时,遑论“我中有你,你中有我”了,一切早已是“我在哪里”和“我是谁”这样的哲学式命题了,也就是连“你我”的界限都早已混沌的状态了。因此,说BERT是双向的语言模型结构,不仅丝毫不过分,它实质上是一种将序列中每一个词之间无比交融在一块的模型,更可贵的是,交融的姿势还可以多种多样,这可从Large版本BERT的多头机制中的Head个数多达16个,体会出这种交融的程度,可谓丝丝入扣。这里仅给出一例,下图只是两个head学习到的交融模式,如果多达16个head,这样的交融模式还要重复16次,可见一斑。 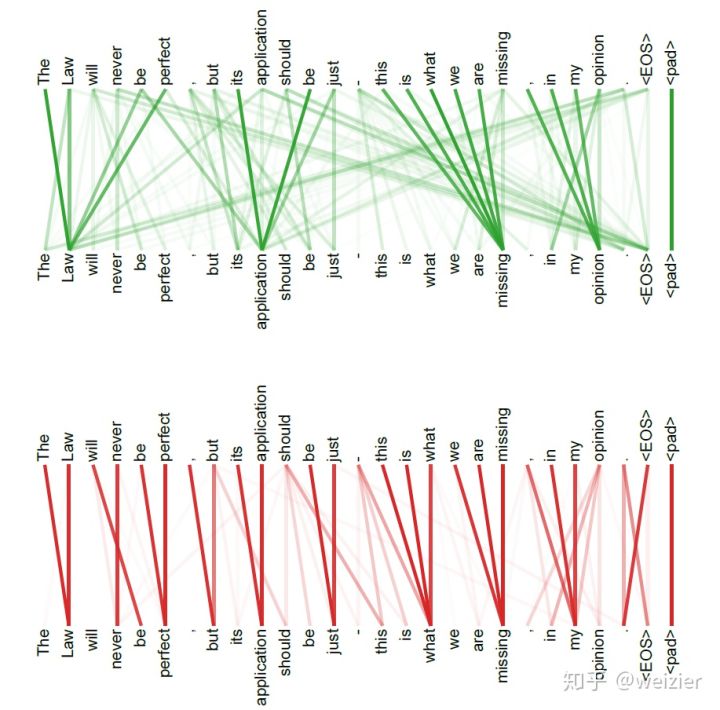
而相应的在ELMo与GPT中,它们并没有用上这种交融模式,也就是它们本质上还是一个单向的模型,ELMo稍微好一点,将两个单向模型的信息concat起来,GPT则只用了单向模型,这是因为它没有用上Transformer Encoder,只用了Decdoer的天生基因决定的,其实,很多人就把这种left-to-right的Transformer框架叫做Decoder,因为事实上Decoder就是如此(具体做的时候需要提前把未来待生成的词做好mask,细节上通过上三角矩阵来实现),这也是OpenAI把他们的模型叫做”Generative”的原因所在。
Masked-LM (MLM)
然而,使用双向Transformer会有一个问题,正如上面的分析,即便对于Base版BERT来说,经过12个block,每一个block内部都有12个多头注意力机制,到最后一层的输出,序列中每个位置上对应的词向量信息,早已融合了输入序列中所有词的信息,而普通的语言模型中,是通过某个词的上下文语境预测当前词的概率,如果直接把这个套用到Transformer的Encoder中,会发现待预测的输出和序列输入已经糅合在一块了,说白了就是Encoder的输入已经包含了正确的监督信息了,相当于给模型泄题了,如此说来普通语言模型的目标函数无法直接套用。那么,如何解决Self-attention中带来了表征性能卓越的双向机制,却又同时带来了信息泄露的这一问题?
BERT的作者很快联想到了,如果我把原来要预测整个句子的输出,改为只预测这个句子中的某个词,并且把输入中这个词所在位置挖空,这样一来,岂不就不会存在泄露真题的问题了?Jacob是这样想的(实际上是参考了很早之前提出的Cloze问题),这位以单人徒手搭建大工程著称的牛人,行动力超强,立马就把这一方法吸收和实现到BERT中,他们的想法也特别简单。
- 输入序列依然和普通Transformer保持一致,只不过把挖掉的一个词用”[MASK]”替换
- Transformer的Encoder部分按正常进行
- 输出层在被挖掉的词位置,接一个分类层做词典大小上的分类问题,得到被mask掉的词概率大小
正是因为加了mask,因此BERT才把这种方法叫做Masked-LM,整个过程如下所示

而这就直接把普通语言模型中的生成问题(正如GPT中把它当做一个生成问题一样,虽然其本质上也是一个序列生成问题),变为一个简单的分类问题,并且也直接解决了Encoder中多层Self-attention的双向机制带来的泄密问题(单层Self-attention是真双向,但不会带来泄密问题,只有多层累加的Self-attention才会带来泄密问题),使得语言模型中的真双向机制变为现实。
不过,BERT针对如何做“[MASK]”,做了一些更深入的研究,它做了如下处理
- 选取语料中所有词的15%进行随机mask
- 选中的词在80%的概率下被真实mask
- 选中的词在10%的概率下不做mask,而被随机替换成其他一个词
- 选中的词在10%的概率下不做mask,仍然保留原来真实的词
至于为什么要这么做,BERT也给出了足够感性的解释。对于要做mask,这个原因上面已经分析了,就是为了解决双向机制的泄密问题而设计的;而为什么还要有一部分概率不做真正的mask,而是输入一个实际的词,这样做的好处是尽量让训练和finetune的时候输入保持一致,因为finetune的时候输入中是没有“[MASK]”标记的,,对于保留为原来的真实词,也就是真的有10%的情况下是泄密的(占所有词的比例为15% * 10% = 1.5%),作者说这样能够给模型一定的bias,相当于是额外的奖励,将模型对于词的表征能够拉向词的真实表征(个人理解是:因为输入层是待预测词的真实embedding,在输出层中的该词位置得到的embedding,是经过层层Self-attention后得到的,这部分embedding里肯定多多少少依然保留有部分输入embedding的信息,而这部分的多多少少就是通过输入一定比例的真实词所带来的额外奖励,最终会使得模型的输出向量朝输入层的真实embedding有一个偏移,而如果全用mask的话,模型只需要保证输出层的分类准确,对于输出层的向量表征并不关心,因此可能会导致最终的向量输出效果并不好);最后,BERT对选中的词在10%的概率下不做mask,而是被随机替换成为一个其他词,这样做的目的,BERT也给出了他们的解释:因为模型不知道哪些词是被mask的,哪些词是mask了之后又被替换成了一个其他的词,这会迫使模型尽量在每一个词上都学习到一个全局语境下的表征,因而也能够让BERT获得更好的语境相关的词向量(这正是解决一词多义的最重要特性)。其实这样做的更感性解释是,因为模型不知道哪里有坑,所以随时都要提心吊胆,保持高度的警惕。正如一马平川的大西北高速公路,通常认为都是路线直,路面状况好,但如果掉以轻心,一旦有了突发情况,往往也最容易出事故,鲁棒性不高;而反倒是山间小路,明确告诉了每一位司机路面随时都有坑,并且没法老远就提前知道,所以即便老司机也只能小心翼翼的把稳方向盘慢慢的开,这样做反倒鲁棒性更高。正所谓《左传》中所言“居安思危,思则有备,有备无患,敢以此规”,BERT的这种设计又何尝不是“居安思危”的典范,Jacob给出的原文解释如下:
The Transformer encoder does not know which words it will be asked to predict or which have been replaced by random words, so it is forced to keep a distributional contextual representation of every input token. 此外在引用19中,作者也从直觉上解释了这样做的可行性,
- If we used [MASK] 100% of the time the model wouldn’t necessarily produce good token representations for non-masked words. The non-masked tokens were still used for context, but the model was optimized for predicting masked words.
- If we used [MASK] 90% of the time and random words 10% of the time, this would teach the model that the observed word is never correct.
- If we used [MASK] 90% of the time and kept the same word 10% of the time, then the model could just trivially copy the non-contextual embedding.
然而可惜的是,Jacob并没有在论文中做更细致的实验,来证明这些言论的正确性,因此可能会存在其他的更优的比例组合。
除了用上Mask-LM的方法使得双向Transformer下的语言模型成为现实,BERT还利用和借鉴了Skip-thoughts方法中的句子预测问题,来学习句子级别的语义关系,具体做法则是将两个句子组合成一个序列,当然组合方式会按照下面将要介绍的方式,然后让模型预测这两个句子是否是先后近邻的两个句子,也就是会把”Next Sentence Prediction”问题建模成为一个二分类问题。训练的时候,数据中有50%的情况这两个句子是先后关系,而另外50%的情况下,这两个句子是随机从语料中凑到一起的,也就是不具备先后关系,以此来构造训练数据。句子级别的预测思路和之前介绍的Skip-thoughts基本一致,当然更本质的思想来源还是来自于word2vec中的skip-gram模型。
在预训练阶段,因为有两个任务需要训练:Mask-LM和Next Sentence Prediction,因此BERT的预训练过程实质上是一个Multi-task Learning,具体说来,BERT的损失函数由两部分组成,第一部分是来自于Mask-LM的单词级别的分类任务,另一部分是句子级别的分类任务,通过这两个任务的联合学习,可以使得BERT学习到的表征既有token级别的信息,同时也包含了句子级别的语义信息。具体的损失函数如下
其中 是BERT中Encoder部分的参数,
是BERT中Encoder部分的参数,  是Mask-LM任务中在Encoder上所接的输出层中的参数,
是Mask-LM任务中在Encoder上所接的输出层中的参数,  则是句子预测任务中在Encoder上接上的分类器中的参数。因此,在第一部分的损失函数中,如果被mask的词集合为M,因为它是一个词典大小|V|上的多分类问题,那么具体说来有
则是句子预测任务中在Encoder上接上的分类器中的参数。因此,在第一部分的损失函数中,如果被mask的词集合为M,因为它是一个词典大小|V|上的多分类问题,那么具体说来有
相应的在句子预测任务中,也是一个分类问题的损失函数
因此,两个任务联合学习的损失函数是
至于具体的预训练工程实现细节方面,BERT还利用了一系列策略,使得模型更易于训练,比如对于学习率的warm-up策略(和上文提到的ULMFiT以及Transformer中用到的技巧类似),使用的激活函数不再是普通的ReLu,而是GeLu,也是用了dropout等这些比较常见的训练技巧。此外,BERT使用的语料比GPT也要大得多(GPT用的是BooksCorpus,800 million个词,而BERT除了BooksCorpus之外,还加入了Wikipedia数据集,2500 million个词,总共有3.3 billion个词)。
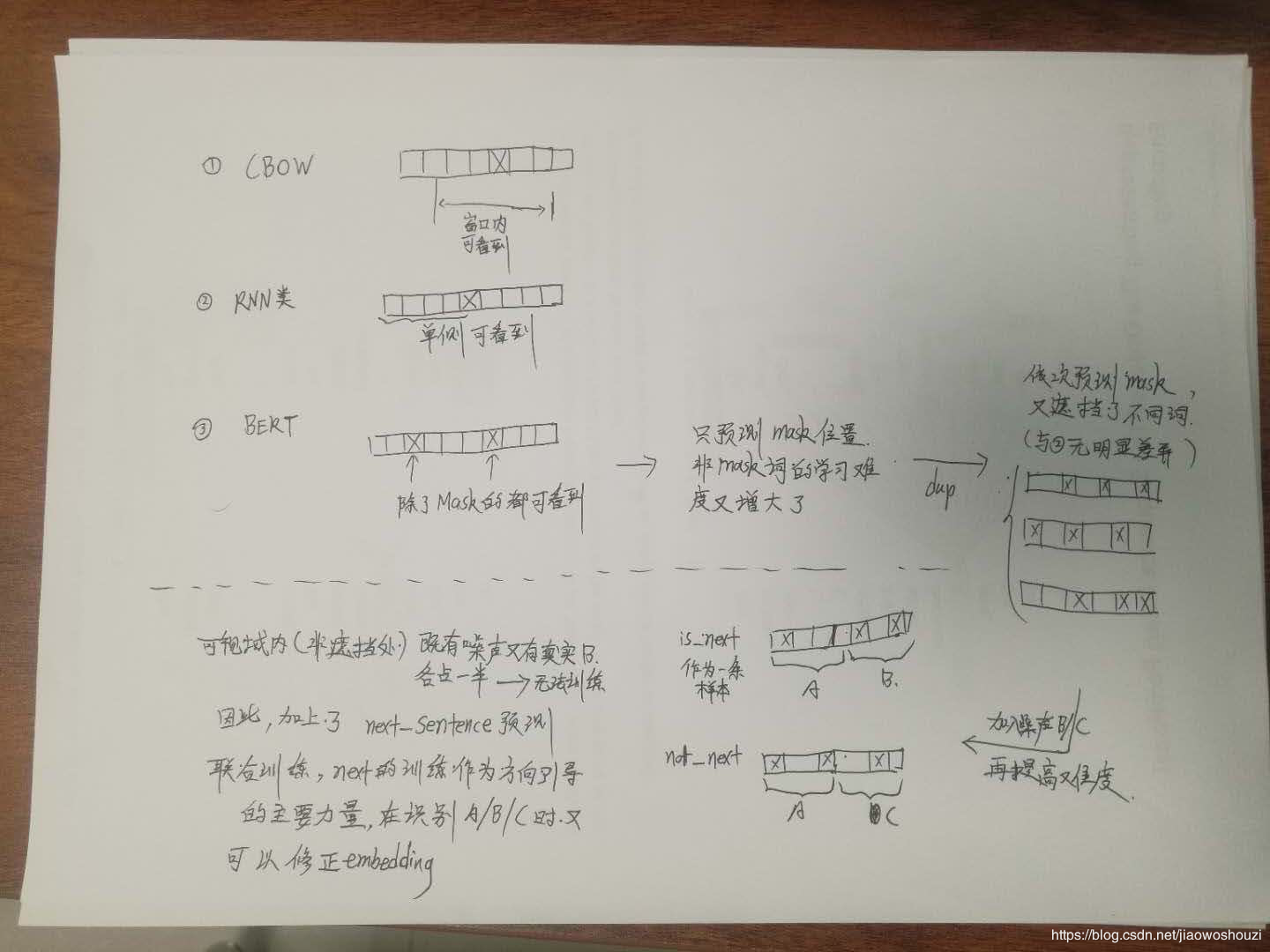
最后,当BERT的预训练完成后,针对如何利用预训练好的模型,迁移到特定任务背景下,BERT在GPT的基础上,将这一个非常重要的工作进行了更深入的设计,因为中间的Encoder对于几乎所有任务而言,都可以直接利用,因此这部分的设计主要分为两个方面:输入层和输出层。
输入层
在输入层方面,思路和GPT基本类似,如果输入只有一个句子的话,则直接在句子的前后添加句子的起始标记位和句子的结束符号,在BERT中,起始标记都用“[CLS]”来表示,结束标记符用”[SEP]”表示,对于两个句子的输入情况,除了起始标记和结束标记之外,两个句子间通过”[SEP]”来进行区分。除了这些之外,BERT还用了两个表示当前是句子A还是句子B的向量来进行表示,对于句子A来说,每一词都会添加一个同样的表示当前句子为句子A的向量,相应的,如果有句子B的话,句子B中的每一个词也都会添加一个表示当前句子为句子B的向量。当然,和Transformer中一样,为了引入序列中词的位置信息,也用了position embedding,因此,最终的输入层大概是
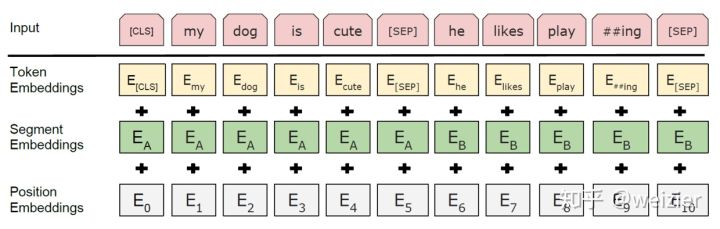
bert的输入可以是单一的一个句子或者是句子对,实际的输入值是segment embedding与position embedding相加,具体的操作流程可参考上面的transformer讲解。
BERT的输入词向量是三个向量之和:
- Token Embedding:WordPiece tokenization subword词向量。
- Segment Embedding:表明这个词属于哪个句子(NSP需要两个句子)。
Position Embedding:学习出来的embedding向量。这与Transformer不同,Transformer中是预先设定好的值。
输出层
除了输入层要尽量做到通用之外,根据不同任务设计不同的输出层也变得尤为重要,BERT主要针对四类任务考虑和设计了一些非常易于移植的输出层,这四类任务分别是:单个序列文本分类任务(SST-2, CoLA)、两个序列文本分类任务(MNLI, QQP, QNLI, STS-B, MRPC, RTE)、阅读理解任务(SQuAD)和序列标注任务(CoNLL-2003 NER),句子或答案选择任务(SWAG等,这里我把SWAG单独划分一个类别,因为具体做法和普通的文本分类任务不完全一致,只不过BERT因为它和其他分类任务都只需要利用”[CLS]”位置的向量,所以才把它一起归入到句子对分类任务中)。
对于单序列文本分类任务和序列对的文本分类任务使用框架基本一致,只要输入层按照上面提到的方法做好表示即可,然后这两个分类任务都是利用BERT的Encoder最后一层的第一个时刻“[CLS]”对应的输出作为分类器的输入,文中的解释是这个时刻可以得到输入序列的全局表征,并且因为监督信号从这个位置反馈给模型,因而实际上在finetune阶段也可以使得这一表征尽量倾向于全局的表征。当然,即便如此,同样也是可以通过一些很简单易行的办法将其他时刻甚至其他层内的表征拿来用的,个人认为并不需要局限在这一个时刻上的表征。另外,finetune阶段,在BERT Encoder基础上,这些分类任务因为只需要接一个全连接层,因此增加的参数只有 ,其中H是Encoder输出层中隐状态的维度,K是分类类别个数。
,其中H是Encoder输出层中隐状态的维度,K是分类类别个数。
对于SQuAD 1.1任务来说,需要在给定的段落中找到正确答案所在的区间,这段区间通过一个起始符与终止符来进行标记,因此只需要预测输入序列中哪个token所在位置是起始符或终止符即可,因此这个过程只需要维护两个向量,分别是起始符的向量和终止符的向量,不过与其说是向量,还不如说是两个对应的全连接层,只不过这两个全连接有些特殊,在这两个全连接层中,输入层的节点个数为BERT Encoder输出的节点个数,也就是H,而这两个全连接层的输出层都只有一个节点,而这两个全连接层的作用就是要把序列输出的每一个向量通过这两个全连接层映射为一个实数值,可以等同于打分,然后再根据这个打分在序列的方向上选取最大值作为起始符和终止符,因此这个过程实际上只增加了 的参数量,可谓比分类任务的参数增加还要少(至少和2分类任务的参数一致)。这里有两个需要注意的地方:其一,无论对于起始符和终止符也好,它们的判断和普通的分类任务不一样,不是直接针对每一个token进行一个是否是起始符的分类(如果是这样的话,参数量要增加
的参数量,可谓比分类任务的参数增加还要少(至少和2分类任务的参数一致)。这里有两个需要注意的地方:其一,无论对于起始符和终止符也好,它们的判断和普通的分类任务不一样,不是直接针对每一个token进行一个是否是起始符的分类(如果是这样的话,参数量要增加  ),这里有些类似于在全体输入序列上进行排序的一个工作,因此针对起始符的判断来讲只需要一个
),这里有些类似于在全体输入序列上进行排序的一个工作,因此针对起始符的判断来讲只需要一个  的全连接就可以了。第二个需要注意的是,训练的时候无须担心终止符是否在起始符后面这一点,因为即便模型训练的时候预测是终止符在起始符前面了,这一错误现象会通过损失函数反馈给模型,然而在做inference的时候,就必须要保证终止符一定要在起始符后面这一点了。
的全连接就可以了。第二个需要注意的是,训练的时候无须担心终止符是否在起始符后面这一点,因为即便模型训练的时候预测是终止符在起始符前面了,这一错误现象会通过损失函数反馈给模型,然而在做inference的时候,就必须要保证终止符一定要在起始符后面这一点了。
在序列标注任务上进行finetune
BERT也考虑了如何在序列标注任务上进行finetune,对于序列中的每一个token而言,实际上就是一个分类任务,只不过和前面提到的普通分类任务不一样的地方在于,这里的分类是需要针对序列中的每一个词做分类,参数增加在
 ,这里的K是序列标注中标注的种类个数。
,这里的K是序列标注中标注的种类个数。
最后对于SWAG(Situations Adversarial Generations)任务来讲,因为需要在给定一个句子后,从四个候选句子中选择一个最有可能是该句子的下一个句子,这里面通常包含了一些常识推理。BERT的做法是将前置句子和四个候选句子分别进行组合成一个句子对,并按照之前讨论过的方法输入到Encoder,这样便可以得到四个pair的句子表征,然后只需要维护一个向量(或者说是一个多到1的全连接层),便可以给每一个候选句子进行打分,从而得到四个候选句子中最有可能是下一个的句子。这个全连接只需要增加 的参数量,这一点和SQuAD 1.1任务中使用BERT的情况类似,此外,这种做法和GPT对于Question Selection的做法也比较类似,因此理论上应该也是可以应用到WikiQA这种数据集上的,finetune阶段同样只需要增加
的参数量,这一点和SQuAD 1.1任务中使用BERT的情况类似,此外,这种做法和GPT对于Question Selection的做法也比较类似,因此理论上应该也是可以应用到WikiQA这种数据集上的,finetune阶段同样只需要增加  的参数量。
的参数量。
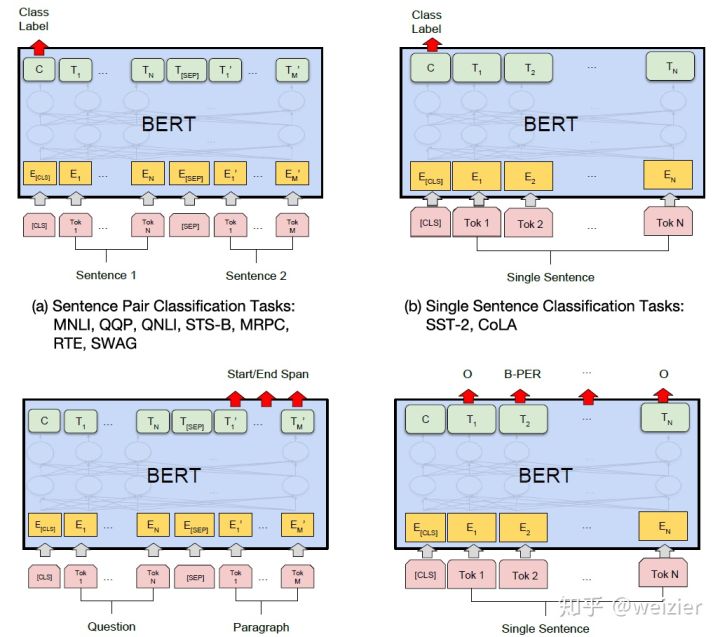
最后,我们再次总结下BERT的几个主要特点:Transformer Encoder因为有Self-attention机制,因此BERT自带双向功能
- 因为双向功能以及多层Self-attention机制的影响,使得BERT必须使用Cloze版的语言模型Masked-LM来完成token级别的预训练
- 为了获取比词更高级别的句子级别的语义表征,BERT加入了Next Sentence Prediction来和Masked-LM一起做联合训练
- 为了适配多任务下的迁移学习,BERT设计了更通用的输入层和输出层
然后,我们再来看看BERT的工作都站在了哪些“巨人肩膀”上:
- 针对第一点,双向功能是Transformer Encoder自带的,因此这个“巨人肩膀”是Transformer
- 第二点中Masked-LM的巨人肩膀是语言模型,CBOW以及Cloze问题
- 第三点中Next Sentence Prediction的“巨人肩膀”是Skip-gram,Skip-thoughts和Quick-thoughts等工作
- 第四点中,对输入层和输出层的改造,借鉴了T-DMCA以及GPT的做法
再来看看预训练使用的数据方面,ELMo使用的是1B Word Benchmark数据集,词数为10亿,然而句子间的顺序是随机打乱的,无法建模句子级别的依赖关系,所以GPT和BERT都弃用这个数据集;GPT使用的是BooksCorpus,词数为8亿;BERT除了使用BooksCorpus之外,还加入了25亿级别的 Wikipedia数据集,因此整体使用的数据集为33亿个词。可见BERT使用的数据集是最大的。
再来看看模型方面,ELMo使用的是一个Bi-LSTM结构,输入层和输出层使用CNN来进行建模。而GPT使用了12个block,隐藏层节点数为768,多头为12,这也是BERT的base版本(因为base版本就是为了跟GPT做对比的),参数量按照BERT base版本估计为110M。而BERT再一次把模型变得更大了,使用24个block,并且隐藏层节点数与多头都有相应扩大,按照Jacob在论文中自己的说法,言下之意似乎想要表明他们设计的这个模型应该是有史以来的最大的模型之一。
在计算资源比拼方面,GPT模型在8块GPU上预训练了一个月时间(参数规模和GPT差不多的BERT base版本,在16块TPU上只花了4天时间,为此BERT在论文中提到这个训练时间的时候,还不失时机的给它们家的TPU放了个链接,打了一波广告),对于参数规模为GPT三倍之多的BERT large版本,在64块TPU上训练耗时也依然达到4天之久。
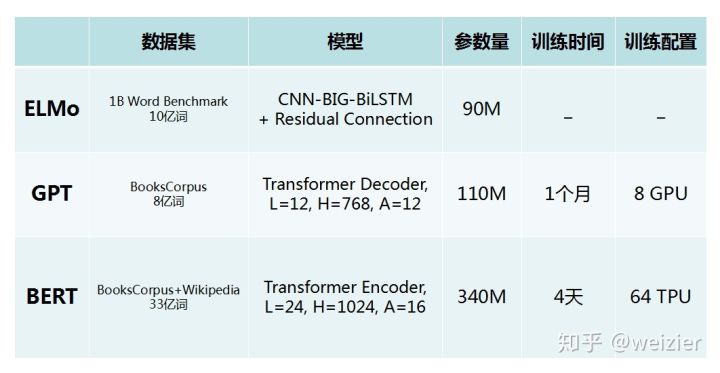<br />因此,总结来看,BERT的出现既踩在了一众前辈们的“巨人肩膀”上,通过精心设计和一些训练技巧造出了一个庞大的模型,最后又舍得花钱砸下巨大资源,给众人上演了一场炫目无比的烟花秀。所以,与其说BERT带来了一次翻天覆地的革新,不如说BERT团队糅合能力超群,以及还有一点也非常重要:有钱。<br />然而,和普通的烟花秀不一样,普通烟花易逝,而BERT说不定可真是将一朵烟花怒放在每一位NLP算法人员心中,它先是让我们看了一场横扫11项任务的表演秀(也是实力秀),宣告世人这场烟花不一般,而更为可贵的是,当众人惊魂甫定之时,很快,BERT又把他们排练烟花秀的一切设备(模型)全都公之于众,甚至把排练得到的效果最好的布景(预训练参数)和点火器(finetune超参数)也全都奉献了出来,似乎愿景也足够伟大:让每个人都可以上演一场自己的烟花秀,将预训练好的模型在复杂任务上简单进行一次finetune,便立马能够得到一个非常高的baseline。<br />沉寂了五年之久的NLP界,似乎迎来了一个新的时代。
实现案例
https://github.com/kyzhouhzau/BERT-NER
https://github.com/Separius/BERT-keras

若有收获,就点个赞吧
0 人点赞
