本质
- 训练两个模型,一个大模型,一个小模型。
- 大模型是正常的算法训练过程。训练完大模型后,才训练小模型。
- 小模型训练需要结合大模型的预测结果。最核心的地方是loss。
- 大模型可以很复杂(vgg16),小模型可以很简单(vgg3)。这是两个不同结构的模型。
- 蒸馏其实就是对大模型的预测结果进行一次softmax操作,只是这个softmax除以了一个温度参数T。然后小模型将蒸馏结果和自身预测结果结合,作为loss去训练。
- 蒸馏本质是正则,因为已经知道了拟合的函数结果。
名词解释
- teacher:大而笨重的模型
- student:小而紧凑的模型
- transfer set:用于小模型训练的数据,也是获得teacher模型soft target输出的输入数据集
- hard target: 样本原始标签
- soft target:teacher模型输出的预测结果
- temperature: softmax函数中的超参数
knowledge:可以理解为从输入向量到输出向量学习到的映射
符号定义
zzz: logit,模型去除输出层的输出
- ppp: probability,每个类的概率
基本思想
知识蒸馏的目的是将一个高精度且笨重的teacher转换为一个更加紧凑的student。具体思路是:提高teacher模型softmax层的temperature参数获得一个合适的soft target集合,然后对要训练的student模型,使用同样的temperature参数值匹配teacher模型的soft target集合,作为student模型总目标函数的一部分,以诱导student模型的训练,实现知识的迁移。蒸馏
论文 Distilling the Knowledge in a Neural Network 这是Hinton大神在15年做的一个黑科技技术,Hinton在一些报告中称之为Dark Knowledge,技术上一般叫做知识蒸馏(Knowledge Distillation)。核心思想是通过迁移知识,从而通过训练好的大模型得到更加适合推理的小模型。这个概念最早在06年的Paper: Model Compression中, Caruana提出一种将大模型学习到的函数压缩进更小更快的模型,而获得可以匹敌大模型结果的方法。
重点idea就是提出用soft target来辅助hard target一起训练,而soft target来自于大模型的预测输出。这里有人会问,明明true label(hard target)是完全正确的,为什么还要soft target呢?
hard target 包含的信息量(信息熵)很低,soft target包含的信息量大,拥有不同类之间关系的信息(比如同时分类驴和马的时候,尽管某张图片是马,但是soft target就不会像hard target 那样只有马的index处的值为1,其余为0,而是在驴的部分也会有概率。)
这样的好处是,这个图像可能更像驴,而不会去像汽车或者狗之类的,而这样的soft信息存在于概率中,以及label之间的高低相似性都存在于soft target中。但是如果soft targe是像这样的信息[0.98 0.01 0.01],就意义不大了,所以需要在softmax中增加温度参数T(这个设置在最终训练完之后的推理中是不需要的)
一般来说,神经网络都是通过一个“softmax”输出层来计算每个类的概率。softmax函数为:
参数T为温度temperature,一般情况下,T值设置为1。当把T值设置为一个更大的数,将会得到一个更加‘soft’的概率分布。在最后使用小模型进行预测时,将T设置为1。就像是在化学提纯操作中,先升高温度,再降低温度,此时就可以提纯出我们想要的东西。下面给出一个例子有助于理解何为“softer”。
| 类别一 | 类别二 | 类别三 | 类别四 | 类别5 | |
|---|---|---|---|---|---|
| 1 | 0 | 0 | 0 | 0 | hard target |
| 2 | 0.1 | 0.5 | 0.001 | 0.001 | logits |
| 0.608 | 0.09 | 0.136 | 0.08 | 0.082 | soft target(T=1) |
| 0.266 | 0.182 | 0.197 | 0.178 | 0.178 | soft target(T=5) |
| 0.231 | 0.191 | 0.199 | 0.189 | 0.189 | soft target(T=10) |
soft target的作用
soft target相对于hard target,携带更多更多有用的信息。对分类来说,物体的标定都是离散的,一个物体只有一个特定的类别,但是大多数情况下,很多类别之间有很大的相似性,(譬如动物与动物之间相似性,植物与植物之间的相似性),但是这些相似性不能被离散的标定表示出来。如上表所示,one-hot编码的hard target信息熵低,只在类别一处取值为1;soft target信息熵高,每一类别都有相应的概率,这个概率值能够能够更好地展示出不同类别之间的相似性,可看做对原始的标定空间进行了“数据扩增”。在论文中,给出了在soft target的帮助下,仅仅使用3%的数据去拟合85M参数量级的语音识别模型,并且能够避免未使用soft target时,3%的数据量训练模型时候的过拟合问题。具体数据参照下图所示。
目标函数

目标函数为两个目标函数的加权平均,一是与soft target的交叉熵,二是与hard target的价差上, 具体介绍如下:
- 第一个目标函数是与soft target的交叉熵,要求student模型与teacher模型softmax层计算时使用相同的temperature
- 第二个目标函数是与hard target的交叉熵,student模型的softmax层计算,temperature取值为1
一般来说,给第二个目标函数赋值一个更低的权重将会得到更好的结果。
训练
上述我们已经描述了知识蒸馏的基本原理,那么,对于要如何实际应用知识蒸馏这一理念,要如何训练网络呢?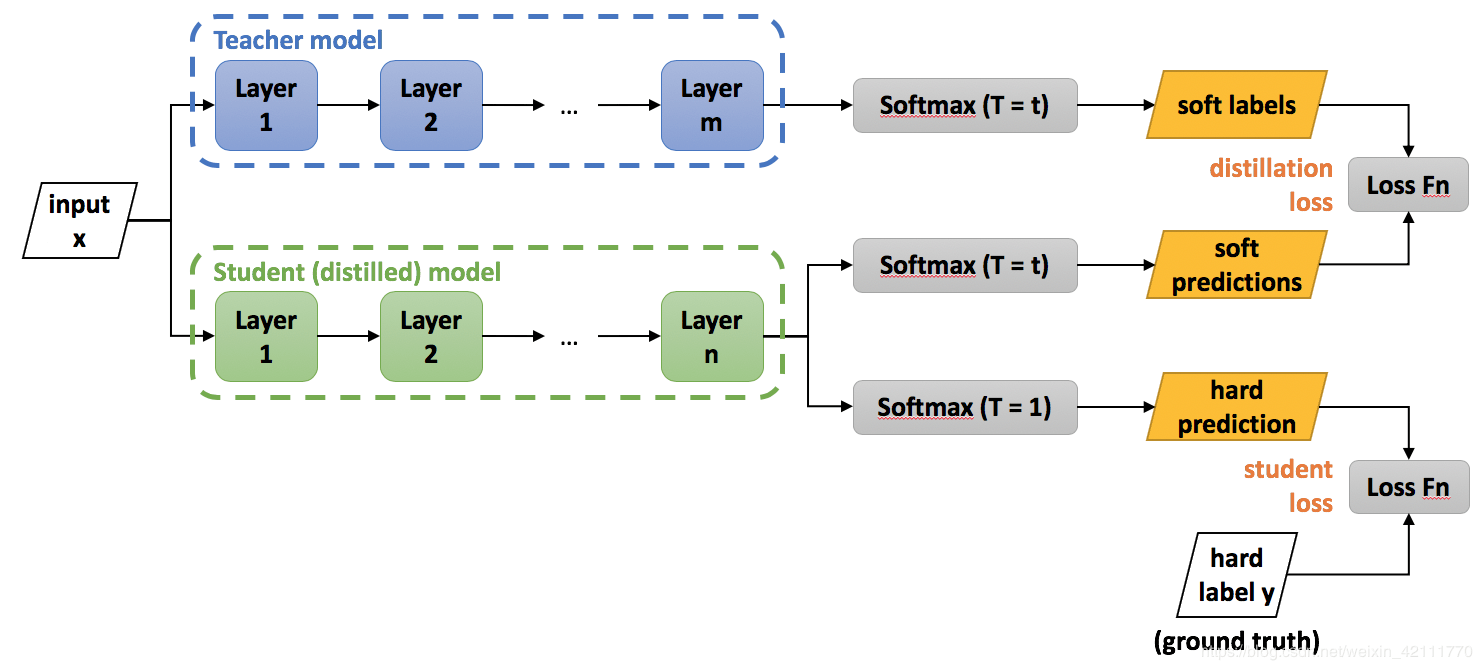
- 获得已经训练好的teacher模型
- 选择transfer set数据集,将teacher模型的logits输出除以temperature参数之后做softmax计算,得到soft target值
- student模型的训练:输入经过student模型得到输出logits输出,而后分成两步计算:一是除以与teacher模型相同的temperature参数之后做softmax计算,此输出与soft target比较;二是做softmax计算,得出预测值,此预测值与hard target进行比较。两部分损失函数相加,得到总的损失函数,计算损失函数,梯度下降,更新参数。
ftmax计算,得出预测值,此预测值与hard target进行比较。两部分损失函数相加,得到总的损失函数,计算损失函数,梯度下降,更新参数。
另一种算法示意图如下: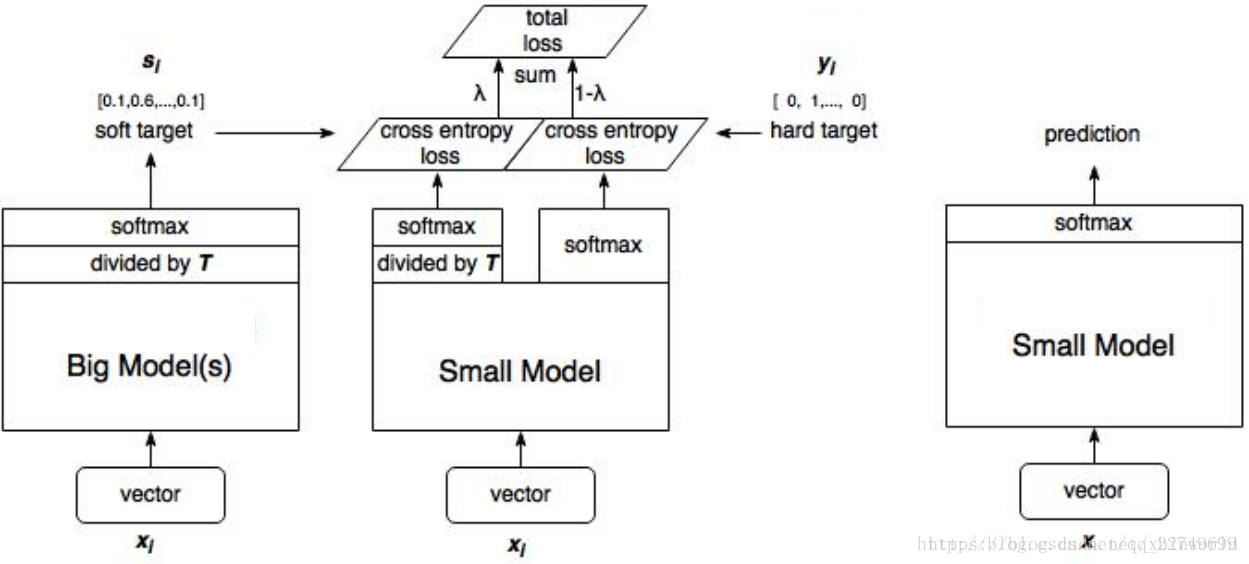
1、训练大模型:先用hard target,也就是正常的label训练大模型。
2、计算soft target:利用训练好的大模型来计算soft target。也就是大模型“软化后”再经过softmax的output。
3、训练小模型,在小模型的基础上再加一个额外的soft target的loss function,通过lambda来调节两个loss functions的比重。
4、预测时,将训练好的小模型按常规方式(右图)使用。

若有收获,就点个赞吧
0 人点赞
