引言
TensorFlow 是 Google 基于 DistBelief 进行研发的第二代人工智能学习系统,被广泛用于语音识别或图像识别等多项机器深度学习领域。其命名来源于本身的运行原理。Tensor(张量)意味着 N 维数组,Flow(流)意味着基于数据流图的计算,TensorFlow 代表着张量从图象的一端流动到另一端计算过程,是将复杂的数据结构传输至人工智能神经网中进行分析和处理的过程。
TensorFlow 完全开源,任何人都可以使用。可在小到一部智能手机、大到数千台数据中心服务器的各种设备上运行。
『机器学习进阶笔记』系列将深入解析 TensorFlow 系统的技术实践,从零开始,由浅入深,与大家一起走上机器学习的进阶之路。
Goal
本文目标是利用 TensorFlow 做一个简单的图像分类器,在比较大的数据集上,尽可能高效地做图像相关处理,从 Train,Validation 到 Inference,是一个比较基本的 Example, 从一个基本的任务学习如果在 TensorFlow 下做高效地图像读取,基本的图像处理,整个项目很简单,但其中有一些 trick,在实际项目当中有很大的好处, 比如绝对不要一次读入所有的 的数据到内存(尽管在 Mnist 这类级别的例子上经常出现)…
最开始看到是这篇 blog 里面的TensorFlow 练习 22: 手写汉字识别, 但是这篇文章只用了 140 训练与测试,试了下代码 很快,但是当扩展到所有的时,发现 32g 的内存都不够用,这才注意到原文中都是用 numpy,会先把所有的数据放入到内存,但这个不必须的,无论在 MXNet 还是 TensorFlow 中都是不必 须的,MXNet 使用的是 DataIter,会在程序运行的过程中异步读取数据,TensorFlow 也是这样的,TensorFlow 封装了高级的 api,用来做数据的读取,比如 TFRecord,还有就是从 filenames 中读取, 来异步读取文件,然后做 shuffle batch,再 feed 到模型的 Graph 中来做模型参数的更新。具体在 tf 如何做数据的读取可以看看reading data in tensorflow

这里我会拿到所有的数据集来做训练与测试,算作是对斗大的熊猫上面那篇文章的一个扩展。
Batch Generate
数据集来自于中科院自动化研究所,感谢分享精神!!!具体下载:
wget http://www.nlpr.ia.ac.cn/databases/download/feature_data/HWDB1.1trn_gnt.zipwget http://www.nlpr.ia.ac.cn/databases/download/feature_data/HWDB1.1tst_gnt.zip
解压后发现是一些 gnt 文件,然后用了斗大的熊猫里面的代码,将所有文件都转化为对应 label 目录下的所有 png 的图片。(注意在 HWDB1.1trn_gnt.zip 解压后是 alz 文件,需要再次解压 我在 mac 没有找到合适的工具,windows 上有 alz 的解压工具)。
import osimport numpy as npimport structfrom PIL import Imagedata_dir = '../data'train_data_dir = os.path.join(data_dir, 'HWDB1.1trn_gnt')test_data_dir = os.path.join(data_dir, 'HWDB1.1tst_gnt')def read_from_gnt_dir(gnt_dir=train_data_dir):def one_file(f):header_size = 10while True:header = np.fromfile(f, dtype='uint8', count=header_size)if not header.size: breaksample_size = header[0] + (header[1]<<8) + (header[2]<<16) + (header[3]<<24)tagcode = header[5] + (header[4]<<8)width = header[6] + (header[7]<<8)height = header[8] + (header[9]<<8)if header_size + width*height != sample_size:breakimage = np.fromfile(f, dtype='uint8', count=width*height).reshape((height, width))yield image, tagcodefor file_name in os.listdir(gnt_dir):if file_name.endswith('.gnt'):file_path = os.path.join(gnt_dir, file_name)with open(file_path, 'rb') as f:for image, tagcode in one_file(f):yield image, tagcodechar_set = set()for _, tagcode in read_from_gnt_dir(gnt_dir=train_data_dir):tagcode_unicode = struct.pack('>H', tagcode).decode('gb2312')char_set.add(tagcode_unicode)char_list = list(char_set)char_dict = dict(zip(sorted(char_list), range(len(char_list))))print len(char_dict)import picklef = open('char_dict', 'wb')pickle.dump(char_dict, f)f.close()train_counter = 0test_counter = 0for image, tagcode in read_from_gnt_dir(gnt_dir=train_data_dir):tagcode_unicode = struct.pack('>H', tagcode).decode('gb2312')im = Image.fromarray(image)dir_name = '../data/train/' + '%0.5d'%char_dict[tagcode_unicode]if not os.path.exists(dir_name):os.mkdir(dir_name)im.convert('RGB').save(dir_name+'/' + str(train_counter) + '.png')train_counter += 1for image, tagcode in read_from_gnt_dir(gnt_dir=test_data_dir):tagcode_unicode = struct.pack('>H', tagcode).decode('gb2312')im = Image.fromarray(image)dir_name = '../data/test/' + '%0.5d'%char_dict[tagcode_unicode]if not os.path.exists(dir_name):os.mkdir(dir_name)im.convert('RGB').save(dir_name+'/' + str(test_counter) + '.png')test_counter += 1
处理好的数据,放到了云盘,大家可以直接在我的云盘来下载处理好的数据集HWDB1. 这里说明下,char_dict 是汉字和对应的数字 label 的记录。
得到数据集后,就要考虑如何读取了,一次用 numpy 读入内存在很多小数据集上是可以行的,但是在稍微大点的数据集上内存就成了瓶颈,但是不要害怕,TensorFlow 有自己的方法:
def batch_data(file_labels,sess, batch_size=128):image_list = [file_label[0] for file_label in file_labels]label_list = [int(file_label[1]) for file_label in file_labels]print 'tag2 {0}'.format(len(image_list))images_tensor = tf.convert_to_tensor(image_list, dtype=tf.string)labels_tensor = tf.convert_to_tensor(label_list, dtype=tf.int64)input_queue = tf.train.slice_input_producer([images_tensor, labels_tensor])labels = input_queue[1]images_content = tf.read_file(input_queue[0])# images = tf.image.decode_png(images_content, channels=1)images = tf.image.convert_image_dtype(tf.image.decode_png(images_content, channels=1), tf.float32)# images = images / 256images = pre_process(images)# print images.get_shape()# one hotlabels = tf.one_hot(labels, 3755)image_batch, label_batch = tf.train.shuffle_batch([images, labels], batch_size=batch_size, capacity=50000,min_after_dequeue=10000)# print 'image_batch', image_batch.get_shape()coord = tf.train.Coordinator()threads = tf.train.start_queue_runners(sess=sess, coord=coord)return image_batch, label_batch, coord, threads
简单介绍下,首先你需要得到所有的图像的 path 和对应的 label 的列表,利用 tf.convert_to_tensor 转换为对应的 tensor, 利用 tf.train.slice_input_producer 将 image_list ,label_list 做一个 slice 处理,然后做图像的读取、预处理,以及 label 的 one_hot 表示,然后就是传到 tf.train.shuffle_batch 产生一个个 shuffle batch,这些就可以 feed 到你的 模型。 slice_input_producer 和 shuffle_batch 这类操作内部都是基于 queue,是一种异步的处理方式, 会在设备中开辟一段空间用作 cache,不同的进程会分别一直往 cache 中塞数据 和取数据,保证内存或显存的占用以及每一个 mini-batch 不需要等待,直接可以从 cache 中获取。
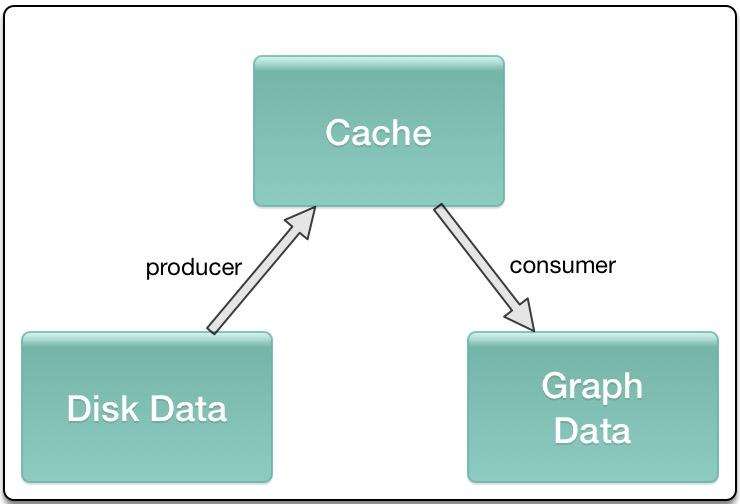
Data Augmentation
由于图像场景不复杂,只是做了一些基本的处理,包括图像翻转,改变下亮度等等,这些在 TensorFlow 里面有现成的 api,所以尽量使用 TensorFlow 来做相关的处理:
def pre_process(images):if FLAGS.random_flip_up_down:images = tf.image.random_flip_up_down(images)if FLAGS.random_flip_left_right:images = tf.image.random_flip_left_right(images)if FLAGS.random_brightness:images = tf.image.random_brightness(images, max_delta=0.3)if FLAGS.random_contrast:images = tf.image.random_contrast(images, 0.8, 1.2)new_size = tf.constant([FLAGS.image_size,FLAGS.image_size], dtype=tf.int32)images = tf.image.resize_images(images, new_size)return images
Build Graph
这里很简单的构造了一个两个卷积 + 一个全连接层的网络,没有做什么更深的设计,感觉意义不大,设计了一个 dict,用来返回后面要用的所有 op,还有就是为了方便再训练中查看 loss 和 accuracy, 没有什么特别的,很容易理解, labels 为 None 时 方便做 inference。
def network(images, labels=None):endpoints = {}conv_1 = slim.conv2d(images, 32, [3,3],1, padding='SAME')max_pool_1 = slim.max_pool2d(conv_1, [2,2],[2,2], padding='SAME')conv_2 = slim.conv2d(max_pool_1, 64, [3,3],padding='SAME')max_pool_2 = slim.max_pool2d(conv_2, [2,2],[2,2], padding='SAME')flatten = slim.flatten(max_pool_2)out = slim.fully_connected(flatten,3755, activation_fn=None)global_step = tf.Variable(initial_value=0)if labels is not None:loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(out, labels))train_op = tf.train.AdamOptimizer(learning_rate=0.0001).minimize(loss, global_step=global_step)accuracy = tf.reduce_mean(tf.cast(tf.equal(tf.argmax(out, 1), tf.argmax(labels, 1)), tf.float32))tf.summary.scalar('loss', loss)tf.summary.scalar('accuracy', accuracy)merged_summary_op = tf.summary.merge_all()output_score = tf.nn.softmax(out)predict_val_top3, predict_index_top3 = tf.nn.top_k(output_score, k=3)endpoints['global_step'] = global_stepif labels is not None:endpoints['labels'] = labelsendpoints['train_op'] = train_opendpoints['loss'] = lossendpoints['accuracy'] = accuracyendpoints['merged_summary_op'] = merged_summary_opendpoints['output_score'] = output_scoreendpoints['predict_val_top3'] = predict_val_top3endpoints['predict_index_top3'] = predict_index_top3return endpoints
Train
train 函数包括从已有 checkpoint 中 restore,得到 step,快速恢复训练过程,训练主要是每一次得到 mini-batch,更新参数,每隔 eval_steps 后做一次 train batch 的 eval,每隔 save_steps 后保存一次 checkpoint。
def train():sess = tf.Session()file_labels = get_imagesfile(FLAGS.train_data_dir)images, labels, coord, threads = batch_data(file_labels, sess)endpoints = network(images, labels)saver = tf.train.Saver()sess.run(tf.global_variables_initializer())train_writer = tf.train.SummaryWriter('./log' + '/train',sess.graph)test_writer = tf.train.SummaryWriter('./log' + '/val')start_step = 0if FLAGS.restore:ckpt = tf.train.latest_checkpoint(FLAGS.checkpoint_dir)if ckpt:saver.restore(sess, ckpt)print "restore from the checkpoint {0}".format(ckpt)start_step += int(ckpt.split('-')[-1])logger.info(':::Training Start:::')try:while not coord.should_stop():# logger.info('step {0} start'.format(i))start_time = time.time()_, loss_val, train_summary, step = sess.run([endpoints['train_op'], endpoints['loss'], endpoints['merged_summary_op'], endpoints['global_step']])train_writer.add_summary(train_summary, step)end_time = time.time()logger.info("the step {0} takes {1} loss {2}".format(step, end_time-start_time, loss_val))if step > FLAGS.max_steps:break# logger.info("the step {0} takes {1} loss {2}".format(i, end_time-start_time, loss_val))if step % FLAGS.eval_steps == 1:accuracy_val,test_summary, step = sess.run([endpoints['accuracy'], endpoints['merged_summary_op'], endpoints['global_step']])test_writer.add_summary(test_summary, step)logger.info('===============Eval a batch in Train data=======================')logger.info( 'the step {0} accuracy {1}'.format(step, accuracy_val))logger.info('===============Eval a batch in Train data=======================')if step % FLAGS.save_steps == 1:logger.info('Save the ckpt of {0}'.format(step))saver.save(sess, os.path.join(FLAGS.checkpoint_dir, 'my-model'), global_step=endpoints['global_step'])except tf.errors.OutOfRangeError:# print "============train finished========="logger.info('==================Train Finished================')saver.save(sess, os.path.join(FLAGS.checkpoint_dir, 'my-model'), global_step=endpoints['global_step'])finally:coord.request_stop()coord.join(threads)sess.close()
Graph

Loss and Accuracy
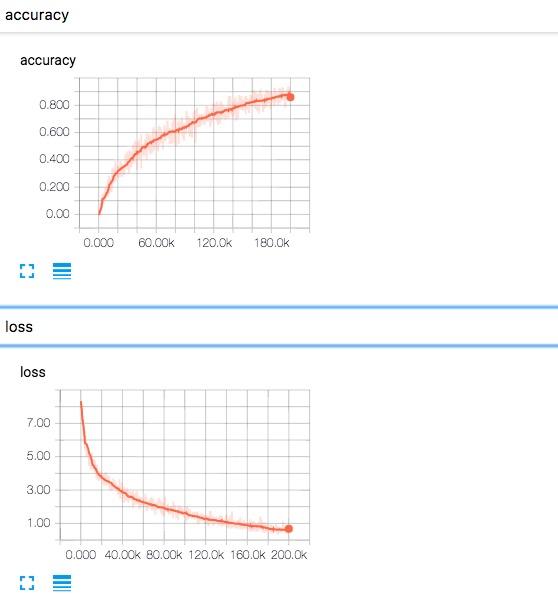
Validation
训练完成之后,想对最终的模型在测试数据集上做一个评估,这里我也曾经尝试利用 batch_data,将 slice_input_producer 中 epoch 设置为 1,来做相关的工作,但是发现这里无法和 train 共用,会出现 epoch 无初始化值的问题(train 中传 epoch 为 None),所以这里自己写了 shuffle batch 的逻辑,将测试集的 images 和 labels 通过 feed_dict 传进到网络,得到模型的输出, 然后做相关指标的计算:
def validation():# it should be fixed by using placeholder with epoch num in train stagesess = tf.Session()file_labels = get_imagesfile(FLAGS.test_data_dir)test_size = len(file_labels)print test_sizeval_batch_size = FLAGS.val_batch_sizetest_steps = test_size / val_batch_sizeprint test_steps# images, labels, coord, threads= batch_data(file_labels, sess)images = tf.placeholder(dtype=tf.float32, shape=[None, 64, 64, 1])labels = tf.placeholder(dtype=tf.int32, shape=[None,3755])# read batch images from file_labels# images_batch = np.zeros([128,64,64,1])# labels_batch = np.zeros([128,3755])# labels_batch[0][20] = 1#endpoints = network(images, labels)saver = tf.train.Saver()ckpt = tf.train.latest_checkpoint(FLAGS.checkpoint_dir)if ckpt:saver.restore(sess, ckpt)# logger.info("restore from the checkpoint {0}".format(ckpt))# logger.info('Start validation')final_predict_val = []final_predict_index = []groundtruth = []for i in range(test_steps):start = i* val_batch_sizeend = (i+1)*val_batch_sizeimages_batch = []labels_batch = []labels_max_batch = []logger.info('=======start validation on {0}/{1} batch========='.format(i, test_steps))for j in range(start,end):image_path = file_labels[j][0]temp_image = Image.open(image_path).convert('L')temp_image = temp_image.resize((FLAGS.image_size, FLAGS.image_size),Image.ANTIALIAS)temp_label = np.zeros([3755])label = int(file_labels[j][1])# print labeltemp_label[label] = 1# print "====",np.asarray(temp_image).shapelabels_batch.append(temp_label)# print "====",np.asarray(temp_image).shapeimages_batch.append(np.asarray(temp_image)/255.0)labels_max_batch.append(label)# print images_batchimages_batch = np.array(images_batch).reshape([-1, 64, 64, 1])labels_batch = np.array(labels_batch)batch_predict_val, batch_predict_index = sess.run([endpoints['predict_val_top3'],endpoints['predict_index_top3']], feed_dict={images:images_batch, labels:labels_batch})logger.info('=======validation on {0}/{1} batch end========='.format(i, test_steps))final_predict_val += batch_predict_val.tolist()final_predict_index += batch_predict_index.tolist()groundtruth += labels_max_batchsess.close()return final_predict_val, final_predict_index, groundtruth
在训练 20w 个 step 之后,大概能达到在测试集上能够达到:

相信如果在网络设计上多花点时间能够在一定程度上提升 accuracy 和 top 3 accuracy. 有兴趣的小伙伴们可以玩玩这个数据集。
Inference
def inference(image):temp_image = Image.open(image).convert('L')temp_image = temp_image.resize((FLAGS.image_size, FLAGS.image_size),Image.ANTIALIAS)sess = tf.Session()logger.info('========start inference============')images = tf.placeholder(dtype=tf.float32, shape=[None, 64, 64, 1])endpoints = network(images)saver = tf.train.Saver()ckpt = tf.train.latest_checkpoint(FLAGS.checkpoint_dir)if ckpt:saver.restore(sess, ckpt)predict_val, predict_index = sess.run([endpoints['predict_val_top3'],endpoints['predict_index_top3']], feed_dict={images:temp_image})sess.close()return final_predict_val, final_predict_index
运气挺好,随便找了张图片就能准确识别出来
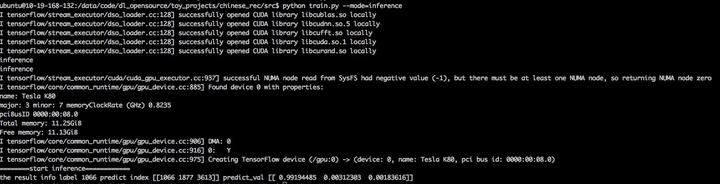
Summary
综上,就是利用 tensorflow 做中文手写识别的全部,从如何使用 tensorflow 内部的 queue 来有效读入数据,到如何设计 network, 到如何做 train,validation,inference,珍格格流程比较清晰, 美中不足的是,原本打算是在训练过程中,来对测试集做评估,但是在使用 queue 读 test_data_dir 下的 filenames,和 train 本身的好像有点问题,不过应该是可以解决的,我这里就 pass 了。另外可能 还有一些可以改善的地方,比如感觉可以把 batch data one hot 的部分写入到 network,这样,减缓在 validation 时内存会因为 onehot 的 sparse 开销比较大。
感觉这个中文手写汉字数据集价值很大,后面感觉会有好多可以玩的,比如
- 可以参考项亮大神的这篇文章端到端的 OCR:验证码识别做定长的字符识别和不定长的字符识别,定长的基本原理是说,可以把最终输出扩展为 k 个输出, 每个值表示对应的字符 label,这样 cnn 模型在 feature extract 之后就可以自己去识别对应字符而无需人工切割;而 LSTM+CTC 来解决不定长的验证码,类似于将音频解码为汉字
- 最近 GAN 特别火,感觉可以考虑用这个数据来做某个字的生成,和 text2img 那个项目text-to-image
这部分的代码都在我的 github 上tensorflow-101,有遇到相关功能, 想参考代码的可以去上面找找,没准就能解决你们遇到的一些小问题.
——————
相关阅读推荐:
机器学习进阶笔记之六 | 深入理解 Fast Neural Style
机器学习进阶笔记之五 | 深入理解 VGG\Residual Network
机器学习进阶笔记之二 | 深入理解 Neural Style
本文由『UCloud 内核与虚拟化研发团队』提供。
关于作者:
Burness( ), UCloud 平台研发中心深度学习研发工程师,tflearn Contributor & tensorflow Contributor,做过电商推荐、精准化营销相关算法工作,专注于分布式深度学习框架、计算机视觉算法研究,平时喜欢玩玩算法,研究研究开源的项目,偶尔也会去一些数据比赛打打酱油,生活中是个极客,对新技术、新技能痴迷。
你可以在 Github 上找到他:http://hacker.duanshishi.com/
「UCloud 机构号」将独家分享云计算领域的技术洞见、行业资讯以及一切你想知道的相关讯息。
欢迎提问 & 求关注 o(////▽////)q~

若有收获,就点个赞吧
0 人点赞
