引言:
来自 CVPR 2021 的论文《A Decomposition Model for Stereo Matching》,是为了解决当前立体匹配模型在输入图像对分辨率比较高时要消耗大量的显存和运算时间这一问题。本文方法的核心即 “分解(Decomplosition)”:在一张图里,一个较大平面内的点的视差可以在低分辨率进行估计;另外的一些细节点再在高分辨率上估计。这样,在低分辨率上进行致密的匹配,在高分辨率上进行稀疏的匹配,从而使模型可以处理大分辨率的图像。
区别于之前的一些 coarse-to-fine 的方法(如 StereoNet、AnyNet、CSN),本文方法属于 coarse+fine。在本文中,coarse 区域和 fine 区域互不相交,同时二者互补,并集是整张图,这也对应了 “分解” 这一核心思想。
方法:
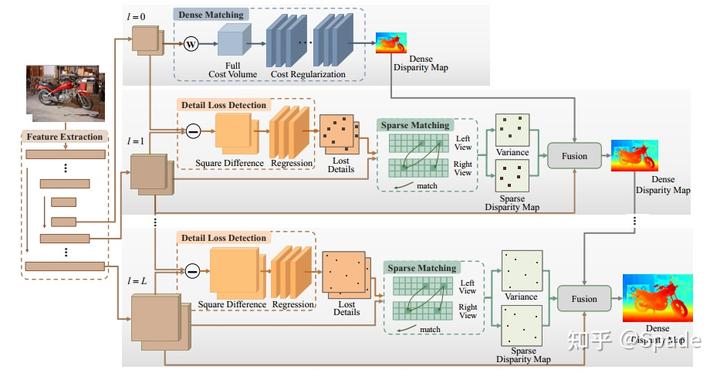
首先就是在最低分辨率上进行的致密匹配,还是 cost volume+3D 卷积那一套。
接下来就是逐步提升分辨率在高分辨率上进行的稀疏匹配。第一步就是如何确定要对哪些稀疏点进行匹配。本文采用了学习的方式,利用一个由 3 层卷积 + sigmoid 组成的小模块,以上采样的特征和本来提取的高分辨率的特征做差为输入,输出一个掩膜,掩膜的值越接近 1 越代表这个点在低分辨率上可能丢失,需要在高分辨率上恢复。对于这个模块的输入的直观解释是如果插值的特征和正常网络提取的高分辨率特征相差较大,这个点则有较大可能属于细节,要在高分辨率上进行匹配。这一模块的学习是利用一个无监督的损失进行约束:其中 FA 代表图像中的 fine 区域,即要进行稀疏匹配的区域。损失包含两部分,一方面希望不要有太多的点属于 FA 区域,即强调稀疏性;另一方面就是稀疏点要是那些特征存在差异的点,即哪些点属于稀疏点。
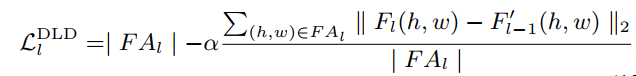
当我们已经检测到左右图的稀疏点时,只需要沿着水平线进行稀疏匹配即可。对于左图的任意一个点,计算和右图所有可能的匹配点的特征相似度作为(负的)匹配代价,然后对匹配代价做归一化转化为匹配概率,最终加权平均得到该点视差。
现在有了来自低分辨率的插值的致密视差图(这里插值还用了一种 content-aware 的动态方法,是学习得到的插值权重,而不是简单的双线性),有了高分辨率得到的稀疏视差图,下一步就是如何进行融合。本文采用了一种 soft 融合的方式,即融合的掩膜不是二进制的,是允许有小数的,当然这个掩膜也是通过学习得到的,这种学习的方式应该还是在准确度上有些优势。这部分的模块也是 3 层卷积 + sigmoid,输入是致密视差和稀疏视差、同分辨率特征、用于预测稀疏匹配点的掩膜、以及一个稀疏匹配的置信度。
最后,视差融合之后会再接一个调优模块,以 warp 的左图特征、左图特征、初始视差为输入,经过 7 个卷积层,得到视差残差。
实验:
首先是一些关于检测到的细节区域的示意图:

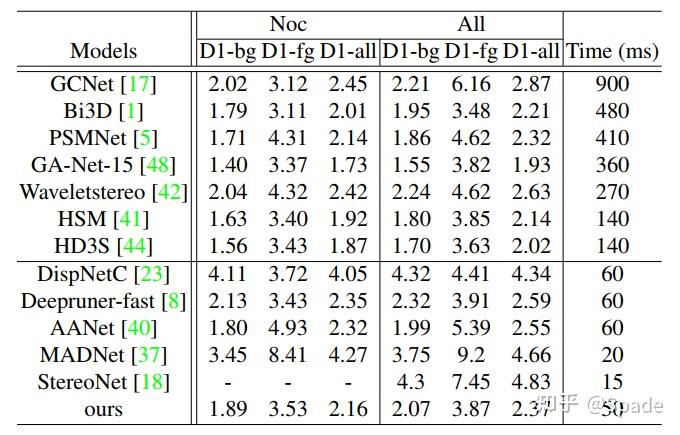
指标上对比(分别在 SceneFlow 和 KITTI 2015 上评测得到),模型兼顾准确性与速度:


若有收获,就点个赞吧
0 人点赞
