0. 本文内容
最近在重温检测相关的模型, 所以把最近对经典的检测模型的一些感悟整理一下. 主要包括 1-stage 的模型 SSD 与 2-stage 模型 Faster-rcnn, 并比较两者的优缺点, 根据两者的缺点, 介绍一些更新的模型. 由于内容较多, 因此会一篇一篇来介绍.
本文首先先介绍一下 1-stage 的模型, 主要包括以下内容:
- 什么是检测任务 (不定数量物体的分类与回归), 以及检测任务的基本解决思路是什么 (将一张图拆分成子图)
- 详细介绍了 SSD, 包括模型结构, 输入输出, Loss, 数据增广等
- 从训练的角度, 确定每次 SSD 到底在学习什么, 讨论为什么 SSD 这类 1-stage 模型在训练过程中有严重类不平衡问题
1. 什么是检测任务
1.1 检测任务是做什么
- 检测任务, 是找到一张图中所有目标物体的位置 (用 bounding box 来表示) 以及对应类别.
- 注意: 不同图中目标物体的数量是不确定的. 也就是说, 最终输出的结果个数是不固定的.
- 可以把检测任务分解为分类 + 定位两个任务, 分类负责确定目标物体的类别, 定位负责确定目标物体的位置. 但由于不同图中目标物体的个数是不缺定的, 因此不能简单地使用一个固定输出大小的 multi-label 模型, 需要有新的思路来实现目标物体数量不确定的情况
下图是 cs231 课件给出的分类, 定位, 检测, 分割的例子. 检测实际上就是目标物体数不确定的分类 + 定位问题:
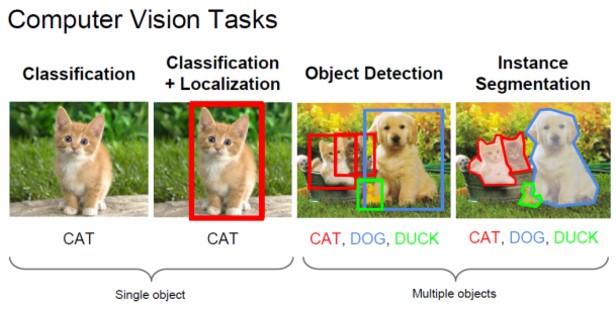
图 1. 检测任务
1.2 检测任务基本思路
上述说到, 由于检测的输入图片的目标物体数量是不确定的, 需要想个办法解决问题. 考虑的因为一张图中, 不同物体的位置是不同的, 那么我们把一张图切分成多张子图, 每张子图只负责预测 1 个物体, 那么这个问题就解决了.

图 2. 检测任务基本思路
当然, 像上述一样的切分方式对其他图可能就没效果了. 为了保证把一张图切成多张子图的时候, 每个目标物体都能被切成独立的一张图, 我们可以使用不同尺寸的滑动窗口, 有重叠地移动, 保证了每个目标物体都能被作为一张子图来训练. 这就是最早的 overfeat 模型所使用的方法, 如下图所示:

图 3. Overfeat 模型
检测的基本思路就是把一张图分解成多张图, 每张图都分别做一次分类和定位.
不同模型的区别就在于如何对图进行切分. 后续我们介绍的 SSD 和 faster rcnn 就是两种图形切分的大方向.
2. 1-stage 方法, SSD
2.1 SSD 系统介绍
2.1.1. 模型结构
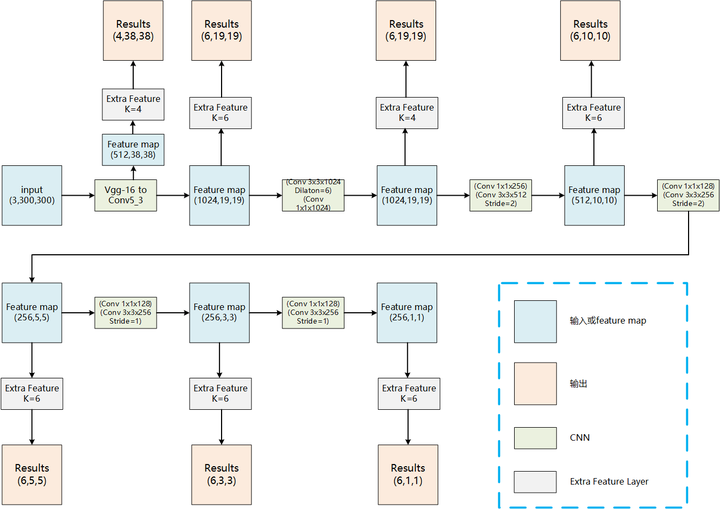
图 4. SSD 模型结构(点击可放大)
SSD 的模型结构如上图所示, 在不断进行卷积的时候, 途中得到的 feature map 不断被 Extra feature 层用来输出一部分预测, 形成了多个输出路径. 每个 Extra Feature 的详细计算如下图, 其中 K 表示 anchor 的数量, anchor 是什么将会在下面进行介绍.
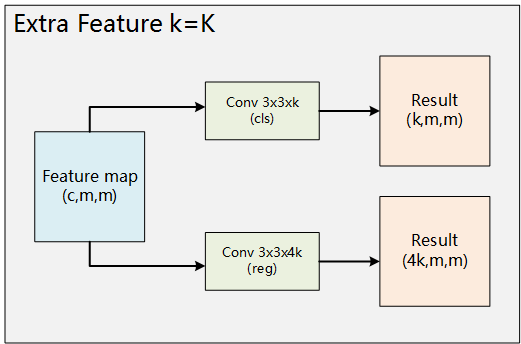
图 5. Extra Feature 层
而且不同的输出路径的输出结果数量不同, 如第一个输出路径的结果数为 4x38x38, 最后一个输出路径的结果数为 6x1x1.
为了简化说明, 把模型简化为单输出的网络, 即只有一输出路径. 实际上, 每个路径都是一个全卷积网络:

图 6. 简化的 SSD 模型 (只有一个输出层)
2.1.2. 输入
SSD 的输入是一个大小为 (300, 300) 或(512, 512)的图片, 后面我们将以大小为 (300, 300) 的输入为例子来介绍 SSD
2.1.3. 输出与 anchor
现在我们讨论我们输出预测的东西到底是什么, 以及如何在训练的时候确定对应的 label.
首先, 先简单说下 anchor 是什么, 以及 anchor 与输出的关系.
先记住: anchor 是输入图像中一些固定大小位置和长宽比的矩形区域. 每个 anchor 都跟一个输出对应. 而当 anchor 中存在物体时, 输出的结果就是该物体.
从模型结构中, 我们可以看到, SSD 实际是一个全卷积网络. 如下图左上角所示, 其最后的完整输出是一个长方体, 这个长方体长宽都为 m, 通道数 = k(n_label+4), 其中 n_label 是预测的种类数, 4 是坐标数, k 是 anchor 种类数 (anchor 种类的大小与长宽比有关). 如下图右上角所示, 我们可以把一个完整的输出, 拆分成 kmm 个单独输出, 每个输出都包括类别 (n_label) 与 4 个 bbox 坐标, 即 (n_label+4). *每一个这样的单独输出都与一个 anchor 对应, 即与输入的一个固定的矩形区域对应. 如图所示, 每一个输出, 都对应输入图像的一个 anchor.
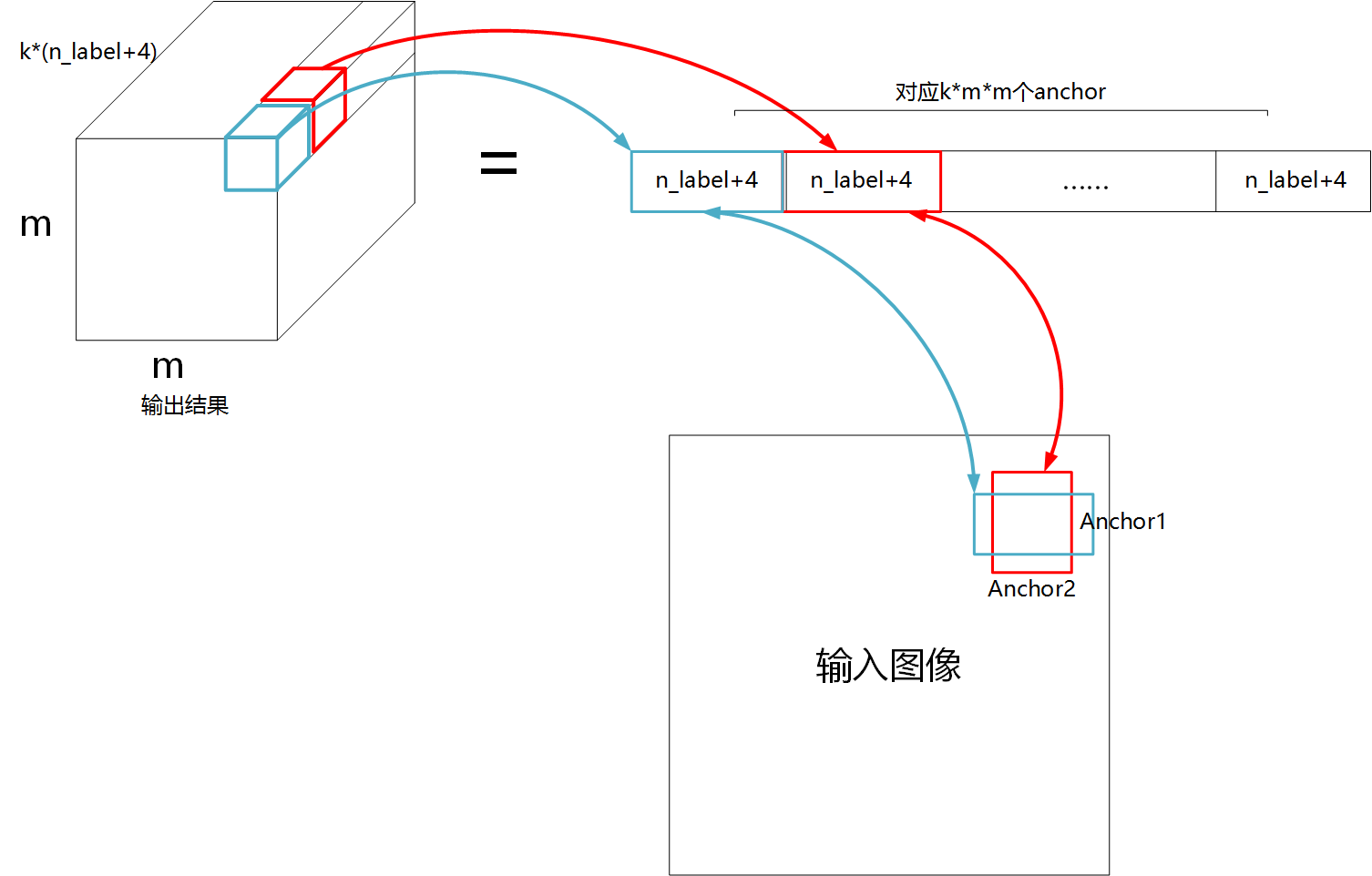
图 7. 输入图像中的 anchor 与输出的对应关系
既然 anchor 是一个矩形区域, 矩形区域就有其位置与大小长宽比, 那么 anchor 的位置大小与长宽比是如何与输出对应的呢?
先从anchor 的位置开始, 如图, 假如输出的 size 是 2x2, 我们把输入图片切成 2x2, 被切成的每张子图的中心点, 就是 anchor 的中心点, 这个 anchor 就是对应输出相同位置.

图 8. anchor 位置与输出位置对应关系
而anchor 的大小是根据输出位于网络哪一层确定的, 位于网络越深的层, 对应 anchor 面积越大, 如下图中间是浅层特征的输出, 右边是深层特征的输出. 浅层结果输出的空间分辨率较大, 每个输出对应 anchor(图中用虚线表示) 的面积较小, 而深层输出对应的 anchor 面积较大. 具体面积可以参考论文中的计算公式.
anchor 长宽比包括 1, 2, 3, 1/2, 1/3. 由于同一个位置上 (anchor 中心点) 有不同长宽比, 所以同一个位置上的 anchor 不止一个, 如下图, 存在以相同坐标为中心, 不同长宽比的 anchor. 这就是上述 k 的由来, 当 k=6 表示有[1, 2, 3, 1/2, 1/3], 其中共 5 种长宽比, 而 1 又包括了 2 种输出大小. 所以一个有 6 个 anchor.
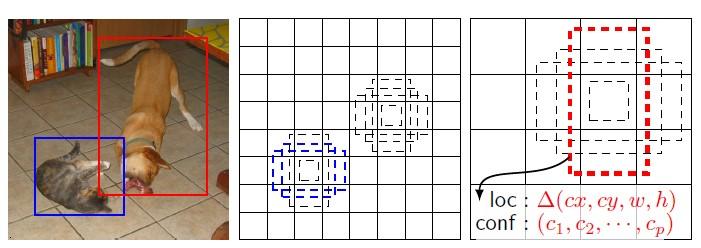
图 9. anchor 大小和长宽比与输出的关系; anchor 与 label 的对应关系
现在我们明确了, 一个输出都对应一个 anchor, 即一个输出都和输入的某个固定位置的矩形区域有关, 那么 anchor 如何影响我们的的输出与 label 呢?
anchor 是输入图片上一个固定的矩形区域, 在训练时, 这个矩形区域范围附近如果存在物体 (满足 anchor 与物体的 iou 大于 0.5), 那么这个 anchor 对应的输出的 label 就是该物体. 否则就是背景. 如上图有两个 anchor 跟猫 iou 满足, 那么这两个 anchor 对应的输出为猫. 同理, 狗也是.
总结起来就是:
- anchor 是输入图像上固定的矩形区域
- 一个 anchor 对应一个输出
- anchor 位置与输出节点的位置相对应, anchor 大小与输出节点位于网络哪一层有关, anchor 有固定的长宽比
- 如果 anchor 与物体 iou 大于 0.5, 那么输出将会输出该物体类别
2.1.4. Loss
由于检测既包括了分类与回归, 所以 loss 也由分类与回归组成:
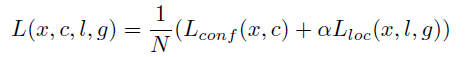
回归 loss, smoothL1:
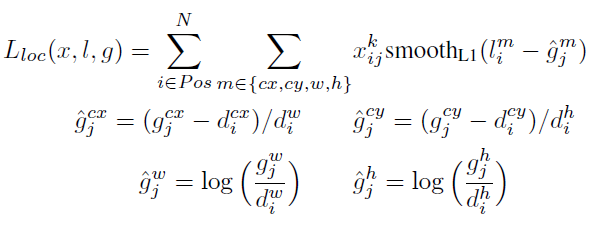
分类 loss, 交叉熵损失函数:

对 bbox 的预测有以下注意点:
- 使用 smoothL1, 而不使用 L2loss, 是因为若采用 L2loss, 在训练时, 某些预测结果与实际相差太大, L2loss 的梯度将过大, 影响训练. 而 smoothL1 在偏差较大时, 不会有类似问题.
- 论文回归的目标对象是, 物体的 bbox 中心点坐标与 anchor 中心点坐标的偏移, 以及物体 bbox 的长宽与 anchor 的长宽的比值. 并不是对 bbox 四个点坐标做回归.
2.1.5. Data Augmentation
训练数据集进行如下数据增广:
- 完整的图
- crop(由于 SSD 是在不同特征层会预测不同大小的物体, 为了保证每个特征层都得到充分训练 (特别是最后几层), 进行了图像的 Crop, 这样相当于放大了一个物体)
- 对图像采样一个 patch, 该 patch 的条件是与物体的 IoU 为 0.1 0.3 0.5 0.7 0.9
- random crop,且保证物体中心点在 crop 区域
- crop 后, ground truth 将会被同样裁剪到 crop 图与 ground truth 重叠地区域
- 翻转
- zoom out(将一张图缩小, 并进行 padding 后作为输入, 有利于预测小物体)
2.1.6. 抽样方式, hard example mining
正样本: 1. 一张图中, 与物体重合最高的 anchor, 其输出对应 label 设为对应物体. 2. 物体 bbox 与 anchor iou 满足大于 0.5
负样本: 对负样本的 loss 排序,选择 loss 最大的样本,并使得正负样本比例为 1:3
2.1.7. train 流程
输入 -> 输出 ->hem-> 反向传播, 更新权值
2.1.8. test 流程
输入 -> 输出 ->nms-> 输出
2.2 SSD 在训练什么
要弄懂一个模型, 不能只知道模型的结构是什么样的, 还要理解模型在训练时, 到底是在训练什么, 这包括训练的输入, 输出. 但之前我们不是已经说过输入输出是什么了吗? 后面, 我们将拆解模型的输入输出, 理解 SSD 到底在训练什么.
2.2.1 输出与感受野
可以通过计算得知, 网络不同层级的输出对应输入的感受野并不是整张图, 可能比整张图小, 也可能比整张图大. 对于感受野比图小的例子, 可以见下图, 一般层级较浅的输出, 比如 (38, 38), (19, 19) 的输出感受野都要小于整张图. 因此他们并不是用整张图来训练.

图 10. Feature map 感受野较小
而感受野大于输入的情况一般发生在层级比较深的输出, 在感受野大于输入时, 可以理解为感受野大于的部分都是 padding, 如下图:

图 11. Feature map 感受野较大
2.2.2 全卷积分解为多个单输出的卷积
SSD 的输出是一系列的全卷积网络, 实际上由于卷积时权值共享的, 可以把全卷积当做对一张图的不同部分做单输出的卷积, 然后把卷积结果按顺序排列, 如下图:
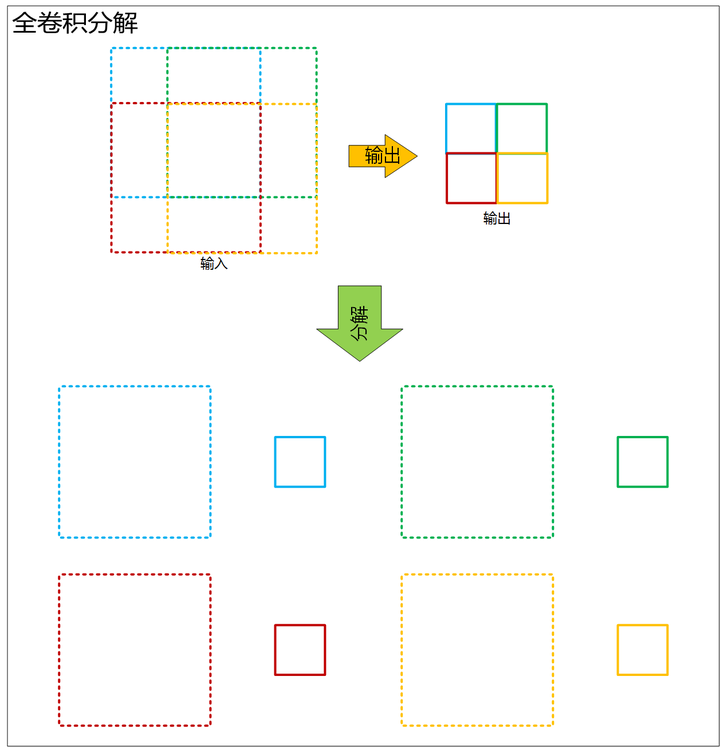
图 12. 将全卷积分解为多个单输出的卷积
上图中, 原始图像经过全卷积得到蓝绿红黄四个输出, 其输出对应输入的感受野也由对应的颜色体现, 我们可以把感受野拆成对应的四幅图, 由于全卷积网络是权值共享的, 因此可以认为是每次四张子图都通过一个相同的 cnn, 得到输出, 然后将输出按顺序拼接.
所以, SSD 的训练可以近似为把一张图拆分成无数个不同大小的子图, 然后做单一输出的分类与定位. 事实上这与滑动窗口十分相似.
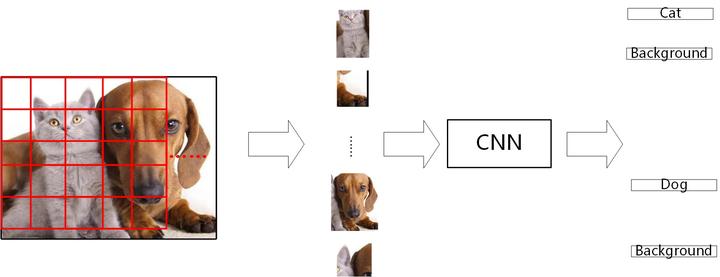
图 13. SSD 近似把一张图分成多张子图进行训练与预测
2.2.3 训练的目标
再回到 anchor, 每个输出都有一个对应的感受野, 也有一个 anchor, 虽然我们每次输入感受野内的图像, 但并不以感受野存在物体而就认为它的输出是这个物体. 只有当感受野内的 anchor 满足与物体 iou 大于 0.5, 才预测存在物体. 因此, 总结起来, 我们学习的实际是一张图 (感受野) 与固定范围 (anchor) 的 iou 大于 0.5 的物体是什么, 以及这个物体相对于 anchor 位置的偏移量什么. 因此, anchor 实际上就是一个 RoI, 相比于 fast-rcnn 的 roi, SSD 的 roi 是固定的, 且每个 roi 都有输出.
总结起来, 不严格地讲, SSD 训练一张图片, 如下图左边图所示, 相当于把一张完整图切分成大大小小 8732 张子图 (300*300 的模型一共有 8732 个 anchor), 每张子图都有一个固定的 RoI 区域 (如下图中间部分所示), 然后以 8732 张子图作为一个 batch 进行训练. 在训练时, 如果 RoI 区域与物体满足 IoU 条件, 我们将其对应的 label 设为该物体, 并且预测其与对应 anchor 的偏移, 否则预测为背景. 这样当预测时, 也是把一张图切成这么多子图, 然后分别进行预测.
SSD 预测的目标就是以一张图中所有 anchor 为窗口, 看其窗口是否存在物体, 如果有物体, 预测其类别以及位置. 无物体则预测为背景.
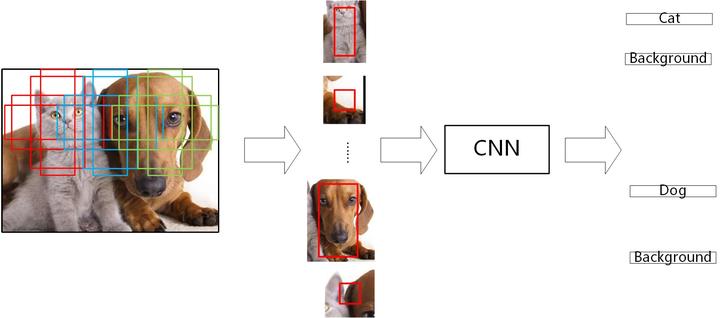
图 14. SSD 的训练目标是预测与 anchor 重合的图像到底是什么物体
2.2.4 类不平衡问题
这样就引出了一个问题, 一张图, 相当于我们一次训练 8732 张图片, 但这 8732 张图片大部分是背景图, 这样就产生了严重的类不平衡问题, 如下图. SSD 解决的方法就是通过启发式采样, 每次并不训练 8732 张图片, 而是训练所有的正样本, 然后再取 loss 最大的负样本 k 个, 使得正负样本比例为 1:3. 虽然这一定程度上缓解了类不平衡问题, 但实际上, 由于训练的的负样本总数是不变的, 每次训练, 每个负样本依旧都有机会与正样本进行训练, 导致负样本在训练时, 对 loss 的贡献要覆盖了正样本对 loss 的贡献, 影响了梯度更新的正确方向, 导致模型无法学习到有用的特征.

图 15. 物体与背景类不平衡
3. 总结
- SSD 这类 1-stage 的检测模型实际上是把一张完整的图分成固定大小与长宽比的成千上万个划窗, 分别预测类别与 bounding box
- 理解一个模型, 不仅仅要理解网络结构, 还需要理解训练过程的数据流, 才能知道模型到底学习了什么. 例如, SSD 的训练过程, 实际上可以看成多张图片进行分类与回归, 因此会出现类不平衡问题
未完待续
后续将会在第二篇文章中, 详细介绍 2-stage 的检测方法, 并将 2-stage 方法与 1-stage 方法进行比较, 分析两者的优缺点.

若有收获,就点个赞吧
0 人点赞
