文章首次发表于本人 CSDN 博客。原文链接为:【AI 数学】用梯度下降算法优化线性回归方程(含代码)_木盏 - CSDN 博客
众所周知,线性回归(Linear Regression)是最常见的机器学习算法之一,简单但超级实用。线性回归旨在用线性方程来拟合数据分布,在数据量小计算速度要求高的地方是神经网络的最佳替代品。
LR 的一般表现形式为: 
通常,LR 优化方式可以通过构建均方误差损失函数,得到一个凸函数,计算导数为 0 的位置来确定 
和 
,就如周志华老师西瓜书里描述的那样。在工程上,我们可以把 LR 当做一个简易的神经网络来对待,用梯度下降算法就可以优化。本文提供一个梯度下降算法优化 LR 的实验例子,有助于加深大家对 LR 以及梯度下降的理解。
实验意图
假设有一个绝对正确的函数 
,对于任意输入 
,都可以得到一个准确的 
值。那咱们只需要知道真实的
和
即可。假定真值 
,而真值 
。首先咱们可以通过真值生成出大量的样本对 
,然后通过这些样本可以训练一个初始化的函数。用梯度下降算法修正参数即可。
重点:咱们只需把随机初始化的
和
优化到接近 
和 
的数值即可。
先做一个简单的数学推导:(其中 
,为损失函数)
求
的梯度: 


求
的更新公式: 
求
的梯度: 
求
的更新公式: 
根据上述公式,咱们可以写出 python 代码和 C++ 代码:(代码均为本人原创,借用请告知)
######################################################### @author: MuZhan# @contact: levio.pku@gmail.com# experiment: using GD to optimize Linear Regression# To fit `y=w*x+b`, where x and w are multi-dim vectors.########################################################import numpy as np# initial settingnp.random.seed(10)epochs = 30lr = .1 # learning ratew_ = np.array([3, 1, 4, 1, 5, 9, 2, 6]) # the ground truth wb_ = 3.7 # the ground truth bSAMPLE_NUM = 100x_dim = len(w_)# preparing random (x, y) pairsprint('preparing data...')x_list = []y_list = []for i in range(SAMPLE_NUM):x = np.random.rand(x_dim)y = w_.dot(x) + b_x_list.append(x)y_list.append(y)# init wnp.random.seed(10)w = np.random.rand(x_dim)# init bb = 1# trainingprint('training...')for e in range(epochs):print('epoch: ', e, end='\t')sum_loss = 0for i in range(len(x_list)):x = x_list[i]y_ = y_list[i]y = w.dot(x) + bloss = (y - y_) ** 2sum_loss += loss# use Gradient Descent to update parametersw = w - 2 * lr * (y - y_) * xb = b - 2 * lr * (y - y_)print('loss: ', sum_loss)print('Ground Truth w: ', w_, end='\t')print('learned w: ', w)print('Ground Truth b: ', b_, end='\t')print('learned b: ', b)
欣赏一下 C++ 代码实现:
#include<iostream>#include<vector>#include<cstdlib>#define SAMPLES_NUM 10000#define EPOCHS 20#define LEARNING_RATE 0.001using namespace std;float dot(float* x, float* w, int length){float res = 0;for(int i=0; i<length; ++i){res += x[i] * w[i];}return res;}float get_random(){return (rand() % 1000) / 100.0;}void update_weights(float* x, float* w, int length, float sqrt_loss){for(int i=0; i<length; ++i){w[i] -= 2 * LEARNING_RATE * sqrt_loss * x[i];}}int main(){float x[8] = {1, 1, 2, 2, 3, 3, 4, 4};float w_[8] = {3, 1, 4, 1, 5, 9, 2, 6}; // Ground Truth wfloat b_ = 3.7; // Ground Truth bint length = int(sizeof(w_)/sizeof(w_[0]));float y;// collect samplesvector<vector<float>> samples;vector<float> tmp;for(int i=0; i<=length; ++i) tmp.push_back(0);for(int i=0; i<SAMPLES_NUM; ++i){for(int j=0; j<length; ++j){tmp[j] = get_random();x[j] = tmp[j];}y = dot(x, w_, length) + b_;tmp[length] = y;samples.push_back(tmp);}// init w, bfloat w[8] = {1, 2, 3};float b = 1.0f;// trainingfloat x_tmp[length];float y_tmp, loss;for(int e=0; e<EPOCHS; ++e){for(int i=0; i<samples.size(); ++i){vector<float> sample = samples[i];copy(sample.begin(), sample.end(), x_tmp);y_tmp = sample[length];y = dot(x_tmp, w, length) + b;loss = (y - y_tmp) * (y - y_tmp);// update parametersupdate_weights(x_tmp, w, length, (y - y_tmp));b -= 2 * LEARNING_RATE * (y - y_tmp);}cout<<loss<<endl;}for(int i=0; i<length; ++i){cout<<w[i]<<" ";}cout<<endl;cout<<b<<endl;return 0;}
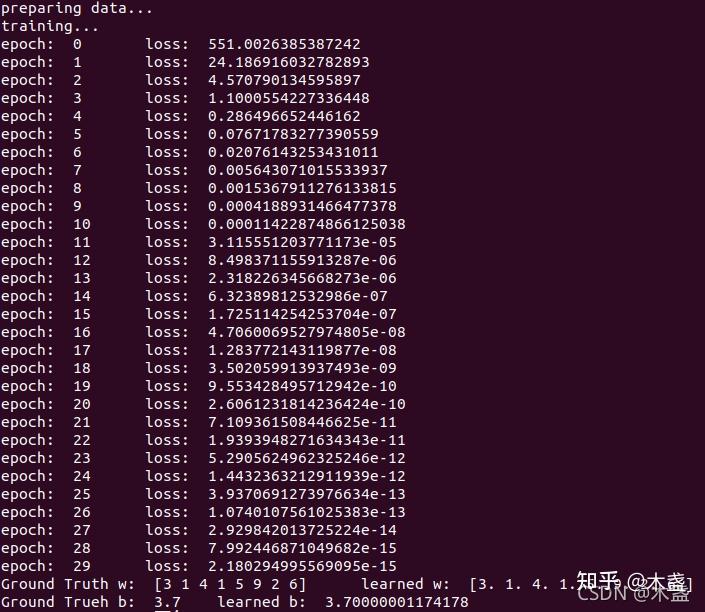
Python 代码输出结果:

若有收获,就点个赞吧
0 人点赞
