论文题目《EdgeStereo: A Context Integrated Residual Pyramid Network for Stereo Matching》,投在 18ACCV。本文主要的创新点在于网络不仅能够预测视差图,还训练一个边缘子网络预测边缘图,将边缘信息整合到主网络中,指导视差学习。人们擅长利用边缘信息进行一致性匹配,也通过全局信息对双目校准不好的低纹理区域等进行认知。但是多尺度这个问题已经在很多工作中有所涉及,因此本文提出的边缘子网络让人眼前一亮。
由于边缘检测和立体匹配的数据集是独立的,没办法同时训练,因此本文提出一个多相(multi-phase)训练策略。就是先用边缘检测的数据集训练边缘子网络,然后这部分网络参数固定,再用立体匹配的数据集训练主网络。
网络结构:
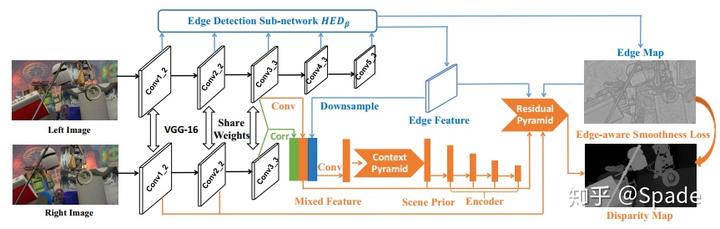
左图右图通过相同权重的网络提取特征,对两个特征计算相关(绿色部分),这里的相关和主流的 cost volume 构造方式不太相同(具体还没看提相关那篇论文…),然后左图特征(橙色线),再加上边缘特征(蓝色线)三者串联起来,用一个 1*1 的卷积融合得到混合特征(橙色 Mixed Feature)。融合特征送入景况金字塔(Context Pyramid),用来整合多尺度信息。文中尝试了卷积、池化、膨胀卷积三种方式的多尺度,发现池化效果最好,前一篇 SPP 也是多尺度池化。多尺度整合的结果称为场景先验(Scene Prior),场景先验经过一个编码器结构,解码器在后面的残差金字塔(Residual Pyramid)。
残差金字塔的结构如下:
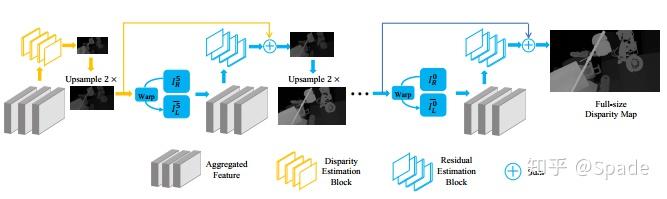
聚合特征(Aggregated Feature)由编码器输出的特征、边缘特征、几何约束构成。这部分称为残差金字塔,金字塔就体现在多尺度。根据最小尺度聚合特征估计最小尺度视差图,将这一视差图上采样,再加上下一尺度聚合特征学习到的残差,得到新的尺度的视差图。这就是残差的想法,下一尺度只负责学习上一尺度上采样后缺少的细节信息。几何约束利用了图像重建。利用视差图 + 右图可以重建左图(无论视差图是左图的视差图还是右图的视差图),对应的存在重建误差。几何约束这部分就是将左图、右图、视差图、重建左图、误差图串联起来。
边缘感知平滑损失(edge-aware smoothness loss):
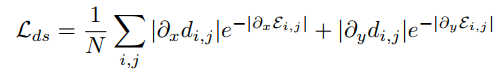
相比于其他一些用到平滑损失的工作,就是把 RGB 图像替换为边缘概率图。主要想法就是允许视差在边缘存在的地方不连续。但是这样的问题就是:是否边缘存在的地方视差一定不连续呢?如一张桌子上面放着很多物品,就存在许多边缘,可是相机正对桌子的话,深度值几乎是相同的。
之前提到训练时采取的多相策略。首先用边缘检测的数据集训练边缘子网络。然后这部分权重固定,用监督损失 + 平滑损失训练主网络,注意残差金字塔的部分有多尺度,所以这部分损失是多尺度求和。最后去掉平滑损失,只用监督损失训练整个网络。KITTI 上立体匹配的数据是很少的,KITTI2015 只有 200 对训练图像、200 对测试图像,而且训练集的视差真值也是不完整的。
效果:立体匹配的指标在 KITTI2015 排行上不算很优秀,但是根据作者给出的效果图,结合视差学习后,边缘图的学习有了提高。

边缘效果图(边缘确实明显了):
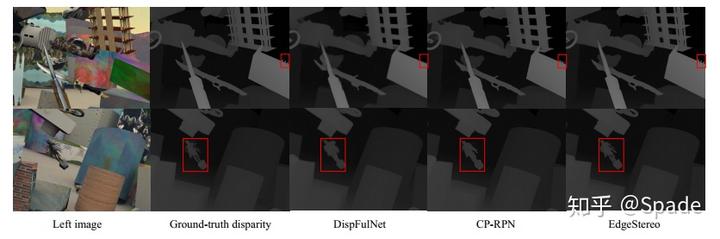
感觉主要是网络没调好导致最好指标不太高,不然感觉可以投更好一些的会议。看到这个边缘子网络真的眼前一亮(主要是之前都不知道还有边缘检测的数据集…)
https://zhuanlan.zhihu.com/p/53055789

若有收获,就点个赞吧
0 人点赞
