引言:
被 CVPR2021 接受的论文《SMD-Nets: Stereo Mixture Density Networks》,本文主要解决两个问题:如何估计锐利的边缘和如何获得更高分辨率的视差图。
为解决前者,本文将一个点的视差建模为一个双峰分布,也即题目中的混合分布(如下图)。直观地,对于边缘处的点,代价聚合后的视差概率分布容易在前景视差值和背景视差值产生两个概率较大的峰,本文通过显式地建模这两个峰,在测试阶段选择概率更高的那个,从而得到锐利地边缘。针对第二个问题,本文设计了一种方法使得可以估计视差图中任意位置的视差值,从而打破了只能在规则的像素网格上获得视差的瓶颈。对于输出视差图的每个点,利用插值找到对应的原图特征,再用该特征预测视差,这样显然要比直接插值视差来的准。
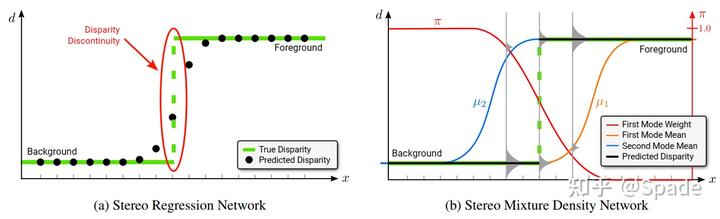
图中横坐标是代表像素网格的一条水平线,纵坐标是视差值。理想情况下,视差应该有个锋利的跳变。但当前回归网络通常会将边界预测得平滑(如左图),而采取了混合分布的预测策略时,可以通过选择概率最大的视差值避免平滑。(右图中命名为μ的两条曲线分别建模了预测为背景、预测为前景的情况, 
是选择背景视差的概率)
方法:
对于任意的立体匹配网络,都是以左右图为输入。在 SMD-Nets 的设计模式中,要求输出是 D 维的特征图(这里的特征已经隐含了每个点视差的信息)。对于输出视差图上的任意一点,利用双线性插值找到对应的 D 维特征(这种方式允许视差图与特征的分辨率不一致)。这个 D 维特征将经过一个多层感知机预测 5 个参数: 
。5 个参数建模了一个双峰的拉普拉斯分布:
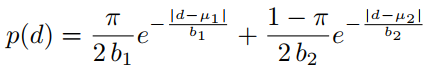
训练阶段,采用真值分布和该分布的最大似然损失。测试阶段,则直接选择概率最大的视差值。
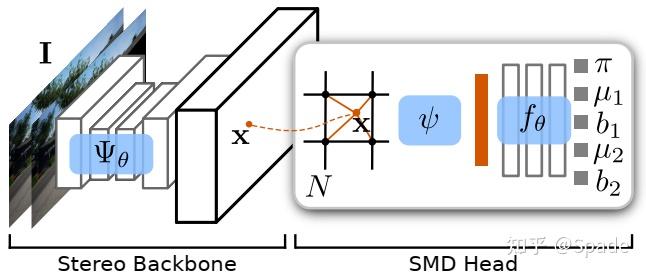
如图为 SMD-Nets 的操作流程,Stereo Backbone 可以是任意的匹配网络。
训练策略:从图像中采样 N 个点,预测该点的双峰拉普拉斯分布,再利用真值分布进行监督。这里采样时作者还专门在视差不连续处多彩了一些点。
另外,由于是可以通过插值找到对应的特征,该方法可以对输出图的任意位置预测视差。所以,本文模型可以用较小分辨率的 RGB 图和较大分辨率的视差真值进行训练。文中称作 Stereo Super-Resolution。利用更高分辨率的视差训练,可以进一步提升模型表现(请参考原论文实验部分)。
实验:
主要就是关于建模双峰分布和这种允许任意位置的视差预测的优势,另外就是本文提供了一个新的数据集(毕竟当前主流的数据集都是 RGB 和视差真值分辨率相同的,无法印证 Stereo Super-Resolution 的优势)。
https://zhuanlan.zhihu.com/p/370925305

若有收获,就点个赞吧
0 人点赞
