引言
TensorFlow 是 Google 基于 DistBelief 进行研发的第二代人工智能学习系统,被广泛用于语音识别或图像识别等多项机器深度学习领域。其命名来源于本身的运行原理。Tensor(张量)意味着 N 维数组,Flow(流)意味着基于数据流图的计算,TensorFlow 代表着张量从图象的一端流动到另一端计算过程,是将复杂的数据结构传输至人工智能神经网中进行分析和处理的过程。
TensorFlow 完全开源,任何人都可以使用。可在小到一部智能手机、大到数千台数据中心服务器的各种设备上运行。
『机器学习进阶笔记』系列将深入解析 TensorFlow 系统的技术实践,从零开始,由浅入深,与大家一起走上机器学习的进阶之路。
前面几篇文章讲述了在 Computer Vision 领域里面常用的模型,接下来一段时间,我会花精力来学习一些 TensorFlow 在 Computer Vision 领域的应用,主要是分析相关 pape 和源码,今天会来详细了解下fast neural style的相关工作,前面也有文章分析 neural style 的内容,那篇算是 neural style 的起源,但是无法应用到实际工作上,为啥呢?它每次都需要指定好 content image 和 style image,然后最小化 content loss 和 style loss 去生成图像,时间花销很大,而且无法保存某种风格的 model,所以每次生成图像都是训练一个 model 的过程。
而fast neural style中能够将训练好的某种 style 的 image 的模型保存下来,然后对 content image 进行 transform,当然文中还提到了 image transform 的另一个应用方向:Super-Resolution,利用深度学习的技术将低分辨率的图像转换为高分辨率图像,现在在很多大型的互联网公司,尤其是视频网站上也有应用。
Paper 原理
几个月前,就看了 Neural Style 相关的文章 深入理解 Neural Style,Neural Algorithm of Aritistic Style 中构造了一个多层的卷积网络,通过最小化定义的 content loss 和 style loss 最后生成一个结合了 content 和 style 的图像,很有意思,而Perceptual Losses for Real-Time Style Transfer and Super-Resolution,通过使用 perceptual loss 来替代 per-pixels loss 使用 pre-trained 的 vgg model 来简化原先的 loss 计算,增加一个 transform Network,直接生成 Content image 的 style 版本, 如何实现的呢,请看下图,容我道来:
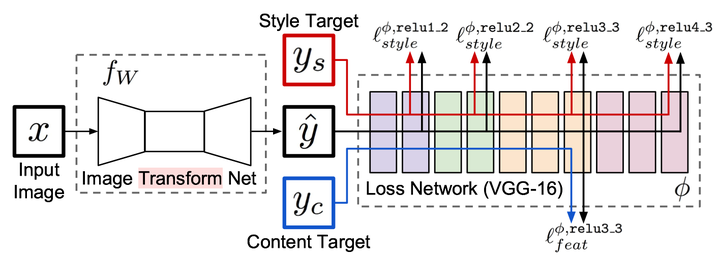
整个网络是由部分组成:image transformation network、 loss netwrok;Image Transformation network 是一个 deep residual conv netwrok,用来将输入图像(content image)直接 transform 为带有 style 的图像;而 loss network 参数是 fixed 的,这里的 loss network 和 A Neural Algorithm of Artistic Style 中的网络结构一致,只是参数不做更新(PS: 这里我之前可能理解有点小问题 —— neural style 的 weight 也是常数,不同的是像素级 loss 和 per loss 的区别,neural style 里面是更新像素,得到最后的合成后的照片),只用来做 content loss 和 style loss 的计算,这个就是所谓的 perceptual loss,作者是这样解释的,为 Image Classification 的 pretrained 的卷积模型已经很好的学习了 perceptual 和 semantic information(场景和语义信息),所以,后面的整个 loss network 仅仅是为了计算 content loss 和 style loss,而不像 A Neural Algorithm of Artistic Style 做更新这部分网络的参数,这里更新的是前面的 transform network 的参数,所以从整个网络结构上来看输入图像通过 transform network 得到转换的图像,然后计算对应的 loss,整个网络通过最小化这个 loss 去 update 前面的 transform network,是不是很简单?
loss 的计算也和之前的都很类似,content loss:
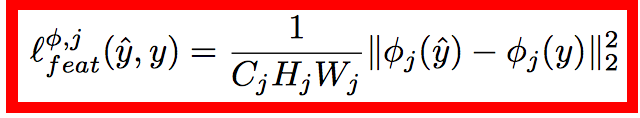
style loss:
style loss 中的 gram matrix:
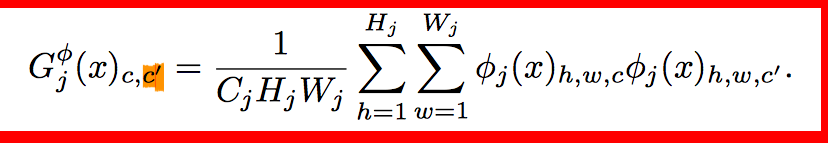
Gram Matrix 是一个很重要的东西,他可以保证 y^hat 和 y 之间有同样的 shape。 Gram 的说明具体见 paper 这部分,我这也解释不清楚,相信读者一看就明白:

相信看到这里就基本上明白了这篇 paper 在 fast neural style 是如何做的,总结一下:
- transform network 网络结构为 deep residual network,将输入 image 转换为带有特种风格的图像,网络参数可更新。
- loss network 网络结构同之前 paper 类似,这里主要是计算 content loss 和 style loss, 注意不像 neural style 里面会对图像做像素级更新更新。
- Gram matrix 的提出,让 transform 之后的图像与最后经过 loss network 之后的图像不同 shape 时计算 loss 也很方便。
Fast Neural Style on Tensorflow
代码参考OlavHN/fast-neural-style),但是我跑了下,代码是跑不通的,原因大概是 tensorflow 在更新之后,local_variables 之后的一些问题,具体原因可以看这个 issue:<tf.train.string_input_producer breaks when num_epochs is set · Issue #1045 · tensorflow/tensorflow>. 还有这个项目的代码都写在一起,有点杂乱,我将 train 和最后生成 style 后的图像的代码分开了,项目放到了我的个人的 github neural_style_tensorflow,项目基本要求:
- python 2.7.x
- Tensorflow r0.10
- VGG-19 model
- COCO dataset
Transform Network 网络结构
import tensorflow as tfdef conv2d(x, input_filters, output_filters, kernel, strides, padding=’SAME’):with tf.variable_scope('conv') as scope:shape = [kernel, kernel, input_filters, output_filters]weight = tf.Variable(tf.truncated_normal(shape, stddev=0.1), name='weight')convolved = tf.nn.conv2d(x, weight, strides=[1, strides, strides, 1], padding=padding, name='conv')normalized = batch_norm(convolved, output_filters)return normalizeddef conv2d_transpose(x, input_filters, output_filters, kernel, strides, padding=’SAME’):with tf.variable_scope('conv_transpose') as scope:shape = [kernel, kernel, output_filters, input_filters]weight = tf.Variable(tf.truncated_normal(shape, stddev=0.1), name='weight')batch_size = tf.shape(x)[0]height = tf.shape(x)[1] * strideswidth = tf.shape(x)[2] * stridesoutput_shape = tf.pack([batch_size, height, width, output_filters])convolved = tf.nn.conv2d_transpose(x, weight, output_shape, strides=[1, strides, strides, 1], padding=padding, name='conv_transpose')normalized = batch_norm(convolved, output_filters)return normalizeddef batch_norm(x, size):batch_mean, batch_var = tf.nn.moments(x, [0, 1, 2], keep_dims=True)beta = tf.Variable(tf.zeros([size]), name='beta')scale = tf.Variable(tf.ones([size]), name='scale')epsilon = 1e-3return tf.nn.batch_normalization(x, batch_mean, batch_var, beta, scale, epsilon, name='batch')def residual(x, filters, kernel, strides, padding=’SAME’):with tf.variable_scope('residual') as scope:conv1 = conv2d(x, filters, filters, kernel, strides, padding=padding)conv2 = conv2d(tf.nn.relu(conv1), filters, filters, kernel, strides, padding=padding)residual = x + conv2return residualdef net(image):with tf.variable_scope('conv1'):conv1 = tf.nn.relu(conv2d(image, 3, 32, 9, 1))with tf.variable_scope('conv2'):conv2 = tf.nn.relu(conv2d(conv1, 32, 64, 3, 2))with tf.variable_scope('conv3'):conv3 = tf.nn.relu(conv2d(conv2, 64, 128, 3, 2))with tf.variable_scope('res1'):res1 = residual(conv3, 128, 3, 1)with tf.variable_scope('res2'):res2 = residual(res1, 128, 3, 1)with tf.variable_scope('res3'):res3 = residual(res2, 128, 3, 1)with tf.variable_scope('res4'):res4 = residual(res3, 128, 3, 1)with tf.variable_scope('res5'):res5 = residual(res4, 128, 3, 1)with tf.variable_scope('deconv1'):deconv1 = tf.nn.relu(conv2d_transpose(res5, 128, 64, 3, 2))with tf.variable_scope('deconv2'):deconv2 = tf.nn.relu(conv2d_transpose(deconv1, 64, 32, 3, 2))with tf.variable_scope('deconv3'):deconv3 = tf.nn.tanh(conv2d_transpose(deconv2, 32, 3, 9, 1))y = deconv3 * 127.5return y
使用 deep residual network 来训练 COCO 数据集,能够在保证性能的前提下,训练更深的模型。 而 Loss Network 是有 pretrained 的 VGG 网络来计算,网络结构:
import tensorflow as tfimport numpy as npimport scipy.iofrom scipy import miscdef net(data_path, input_image):layers = ('conv1_1', 'relu1_1', 'conv1_2', 'relu1_2', 'pool1','conv2_1', 'relu2_1', 'conv2_2', 'relu2_2', 'pool2','conv3_1', 'relu3_1', 'conv3_2', 'relu3_2', 'conv3_3','relu3_3', 'conv3_4', 'relu3_4', 'pool3','conv4_1', 'relu4_1', 'conv4_2', 'relu4_2', 'conv4_3','relu4_3', 'conv4_4', 'relu4_4', 'pool4','conv5_1', 'relu5_1', 'conv5_2', 'relu5_2', 'conv5_3','relu5_3', 'conv5_4', 'relu5_4')data = scipy.io.loadmat(data_path)mean = data['normalization'][0][0][0]mean_pixel = np.mean(mean, axis=(0, 1))weights = data['layers'][0]net = {}current = input_imagefor i, name in enumerate(layers):kind = name[:4]if kind == 'conv':kernels, bias = weights[i][0][0][0][0]# matconvnet: weights are [width, height, in_channels, out_channels]# tensorflow: weights are [height, width, in_channels, out_channels]kernels = np.transpose(kernels, (1, 0, 2, 3))bias = bias.reshape(-1)current = _conv_layer(current, kernels, bias, name=name)elif kind == 'relu':current = tf.nn.relu(current, name=name)elif kind == 'pool':current = _pool_layer(current, name=name)net[name] = currentassert len(net) == len(layers)return net, mean_pixeldef _conv_layer(input, weights, bias, name=None):conv = tf.nn.conv2d(input, tf.constant(weights), strides=(1, 1, 1, 1),padding='SAME', name=name)return tf.nn.bias_add(conv, bias)def _pool_layer(input, name=None):return tf.nn.max_pool(input, ksize=(1, 2, 2, 1), strides=(1, 2, 2, 1),padding='SAME', name=name)def preprocess(image, mean_pixel):return image - mean_pixeldef unprocess(image, mean_pixel):return image + mean_pixel
Content Loss:
def compute_content_loss(content_layers,net):content_loss = 0# tf.app.flags.DEFINE_string("CONTENT_LAYERS", "relu4_2", "Which VGG layer to extract content loss from")for layer in content_layers:generated_images, content_images = tf.split(0, 2, net[layer])size = tf.size(generated_images)content_loss += tf.nn.l2_loss(generated_images - content_images) / tf.to_float(size)content_loss = content_loss / len(content_layers)return content_loss
Style Loss:
def compute_style_loss(style_features_t, style_layers,net):style_loss = 0for style_gram, layer in zip(style_features_t, style_layers):generated_images, _ = tf.split(0, 2, net[layer])size = tf.size(generated_images)for style_image in style_gram:style_loss += tf.nn.l2_loss(tf.reduce_sum(gram(generated_images) - style_image, 0)) / tf.to_float(size)style_loss = style_loss / len(style_layers)return style_loss
gram:
def gram(layer):shape = tf.shape(layer)num_images = shape[0]num_filters = shape[3]size = tf.size(layer)filters = tf.reshape(layer, tf.pack([num_images, -1, num_filters]))grams = tf.batch_matmul(filters, filters, adj_x=True) / tf.to_float(size / FLAGS.BATCH_SIZE)return grams
在 trainfast_neural_style.py main() 中,net, \= http://vgg.net(FLAGS.VGG_PATH, tf.concat(0, [generated, images])) 这部分有点疑问,按我的想法来说应该分别把 generated、images 作为 input 给到http://vgg.net,然后在后面去计算与 content image 和 style 的 loss,但是这里是直接首先把 generated 和原来的 content images 先 concat by axis=0(具体可以查下 tf.concat)然后在输出进行 tf.split 得到对应网络的输出,这个很有意思,想想 CNN 在做卷积的时候某个位置的值只与周围相关,共享 weight 之后,该层彼此之间不相关(可能在 generated 和 image 之间就边缘地方有些许 pixels 的影响,基本可以忽略,我的解释可能就是这样,有其他更合理的解释的小伙伴,请在本文下方留言),这个技巧感觉挺有用的,以后写相关代码的时候可以采纳。
后记
代码图像生成效果不是很好,我怀疑是 content 和 style 之间的 weight 大小的关系,还有就是可能是 epoch 数大小的问题,之后我会好好改下权重,看看能不能有点比较好的结果。
—试过好多不同的版本,fast neural style 确实效果要差一点。
——————
相关阅读推荐:
机器学习进阶笔记之五 | 深入理解 VGG\Residual Network
机器学习进阶笔记之二 | 深入理解 Neural Style
本文由『UCloud 内核与虚拟化研发团队』提供。
关于作者:
Burness( ), UCloud 平台研发中心深度学习研发工程师,tflearn Contributor & tensorflow Contributor,做过电商推荐、精准化营销相关算法工作,专注于分布式深度学习框架、计算机视觉算法研究,平时喜欢玩玩算法,研究研究开源的项目,偶尔也会去一些数据比赛打打酱油,生活中是个极客,对新技术、新技能痴迷。
你可以在 Github 上找到他:http://hacker.duanshishi.com/
「UCloud 机构号」将独家分享云计算领域的技术洞见、行业资讯以及一切你想知道的相关讯息。
欢迎提问 & 求关注 o(////▽////)q~

若有收获,就点个赞吧
0 人点赞
