ECCV2020 oral 论文 Domain-invariant Stereo Matching Networks 。本文针对提升模型的泛化性,提出了一个域不变的框架,即在合成数据训练后可以直接迁移到其他场景使用。与域适应 / 无监督方法的区别:不需要目标域数据。
文中提出了域归一化(domain normalization)和结构化图滤波(Structure-preserving Graph-based Filtering)来解决这个问题。
域归一化 Domain Normalization
BN 层(统计每个通道的所有数据)的设计是为了稳定训练等,但是由于不同域统计数据的差异,通常影响了模型的泛化力。IN 层(对每个样本统计每个通道的所有数据)常用于风格迁移任务,因为每一张图都有可能有较大差异。DN:在 IN 的基础上,对每个点 C 通道的特征进行归一化。
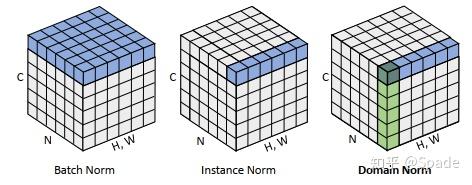
每使用一次 DN 层,输出特征图(CHW)的每个点的特征向量(C)通道的 L2 范数都是 1。这样,对于来自不同域的数据,相当于都固定了数值范围,相当于让模型在这种通用的数值分布下去学习如何完成匹配任务。
结构化图滤波 Structure-preserving Graph-based Filtering
这一部分是为了传递像素点间的信息,可以看作特征的聚合。相比于普通的卷积,他会根据特征的相似度加权,这样可以更好地保留结构信息,同时,信息的传递也是大范围的,可以捕获到远距离的关系。
首先将一个 8 连通图分解成两个有向图。图中每个结点都(最多)有 4 个输入,4 个输出。
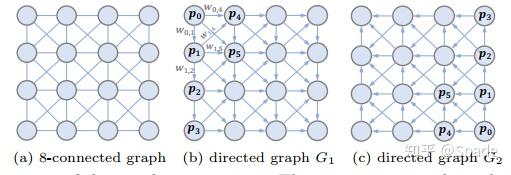
特征更新:以图 b 中的结点 5 为例,结点 0、1、2、4 都可以连过来,可以更新 5 的特征。此外,如果有间接连着的,也要更新。如 0 到 5 可以直接过来,也可以 0-1-5 这样过来,甚至 0-1-4-5 过来,对于所有可能的路径,都要计算到。
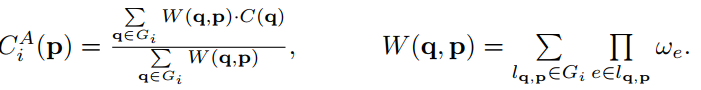
更新的公式如上,本质上是加权平均,权重是所有路径求和。如 p 代表结点 5,q 代表结点 0,那么 
包括 0-5、0-1-5、0-1-2-5、0-1-4-5、0-4-5,每条路径的权重是所有单独路径的累乘,如 0-1-2-5 的权重,是 w(0,1) w(1,2) w(2, 5)。
每条单独路径权重的计算方式:
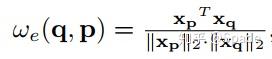
计算完余弦相似度会对每个节点的单独路径的和归一化。可以证明,对单独路径的和归一化等价于对所有路径的归一化,也即,每次更新特征时的权重之和都是 1,这样训练就可以保证数值稳定。
实际上,这样的更新可以通过迭代更新完成。假设结点 5 下面的结点是结点 6,那么可以看到结点 6 要聚合来自结点 0~5 的信息,但其实只有 1235 这四个结点与 6 直接相连。实际上,更新结点 6 等价于更新完结点 1235 后,仅利用这四个更新结点 6。通俗的解释是,更新结点 6 需要的结点 0 的信息传递,已经在更新结点 1235 这几步中完成了。
实验
指标很厉害,只在合成数据集上训练,就可以在 KITTI 达到 3px 误差 4% 以内的水平(虽然合成数据用了街景的)。
https://zhuanlan.zhihu.com/p/283066265

若有收获,就点个赞吧
0 人点赞
