最近关注的朋友越来越多了,虽然有一些感觉像是系统的账号,不过还是小小地满足了虚荣心… 另一方面也督促着我把看过的论文再复习一遍。
论文题目《GA-Net: Guided Aggregation Net for End-to-end Stereo Matching》,来自 CVPR2019。题目中 guided 在这里是指用 RGB 指导一些任务,如我们的视差估计,深度补全任务也有谈到。Aggregation 就是代价聚合,之前还专门发了个问题想探讨一下如何理解代价聚合这一步,看了这篇论文稍微有了深一点的认识。
本文主要针对立体匹配中的代价聚合,像 PSMNet 那些方法中,代价聚合就是从得到 cost volume 到 softmax 回归计算视差这一部分,采用的方法就是堆叠的 3D 卷积,3D 卷积的参数量是很高的。而本文中提出了两种网络层,用更少的参数就可以达到相同的效果。一种是对半全局匹配的修改,称为半全局聚合层(semi-global aggregation layer),另一种是局部指导的聚合层(local guided aggregation layer),也是借鉴传统立体匹配方法的代价滤波策略(后面会稍微具体地解释)。前者聚合全图多个方向的代价,使得在遮挡区域、低纹理区域也有较好的估计;后者聚合局部代价来处理那些较细的结构和物体边缘。
先来看半全局聚合层(SGA)。在半全局匹配种,代价是通过一种互信息计算得到的,随后用动态规划的思路在多个方向进行代价聚合,然后通过最小化一个全局的总代价,寻找到最优的视差值。动态规划聚合代价的方式如下:
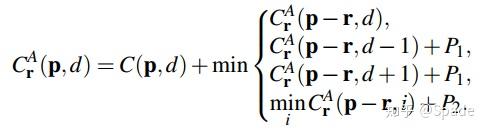
p 就是某一点的坐标,r 是方向,p-r 代表某一方向上之前的一个点的坐标,d 是视差,P 用来惩罚视差变化。这就是动态规划中的状态转移方程。而本文种的 SGA 层聚合代价的方式如下:
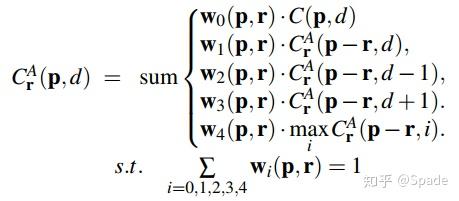
用加权求和的方式代替了求最小值,是为了能够融合到神经网络中计算梯度反向传播,同时这样的方法也不会丧失准确性,二者对比的感觉有点像池化与卷积的对比(一个取最小,一个加权求和)。权重和为 1 的约束是防止聚合的过程中代价累加得很大。在 SGM 算法中也提到了这个问题。最后一项针对允许视差变化较大的一项从 min 改为了 max,作者称是建模的概率,所以希望正确的概率最大,而不是代价最小。
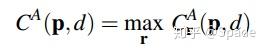
文中在 4 个方向聚合代价,然后选择最大的,作为聚合后的代价。
接下来是局部指导的聚合(LGA)层。还是先简单看一下传统的代价滤波方法:
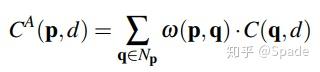
对于某一点,在其邻域内对各个代价加权求和。而这个权重是和 RGB 有关的,这也是所谓的 guided 图像滤波方法。再本文中,聚合的公式为:
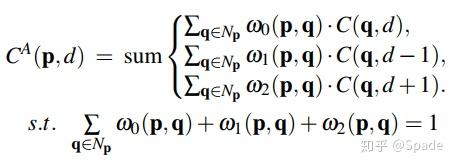
与 SGA 不同的地方在于这里的 w 不是一个单一的权重,而是一个卷积核,在 Np 这个邻域里卷积代价,再求和不同的视差值。同样地,权重归一化是为了防止代价无限制增高。
以上就是本文提到的两种聚合层,这里面都需要确定权重 w。而 guided 的思路就在于,这个权重是通过网络自己学出来的,在网络中,将嵌入一个小网络,这部分输入是 RGB,输出就是 SGA 和 LGA 所需要的参数,这个小网络会与大网络一起训练。
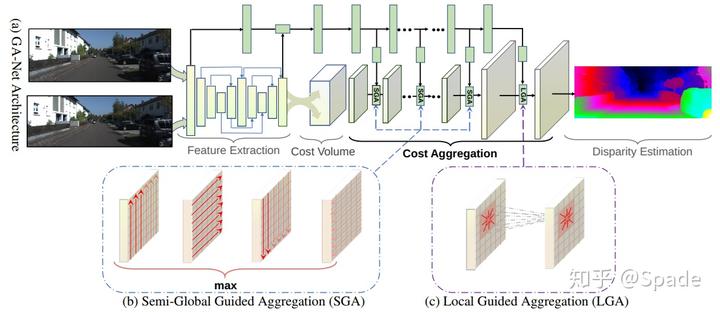
上面那条绿色的就是学习 SGA 和 LGA 所需要的权重参数。因为维度不一致,所以子网络输出的矩阵会 reshape 成聚合层所需要的权重的形式。
此外有一点值得注意的是,4D 的 cost volume 经过聚合层,并没有改变维度,仍然是 4D 的。因此,仍需要一些 3D 卷积,最终 softmax 得到概率乘以对应的视差求和得到最终的视差。只不过有了聚合层的帮助,可以减少很多 3D 卷积层。
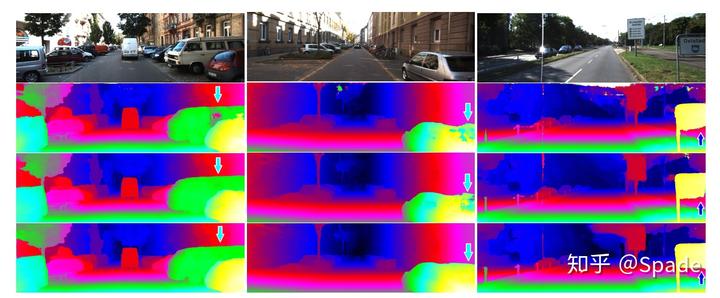
在实验部分,作者还是强调了一下自己这两个聚合层的优势。比如 LGA 让算法细的结构和物体边界上表现更好(最后一行是 GA-Net)。

若有收获,就点个赞吧
0 人点赞
