《Content-Aware Inter-Scale Cost Aggregation for Stereo Matching》来自于 ArXiv 的论文,看排版或许会出现在 ECCV2020。当前立体匹配网络中,代价是通过插值或反卷积升高分辨率,这些操作会导致细节较差。针对于此,本文提出了一种 “Content-Aware”(对内容感知)的代价聚合策略。
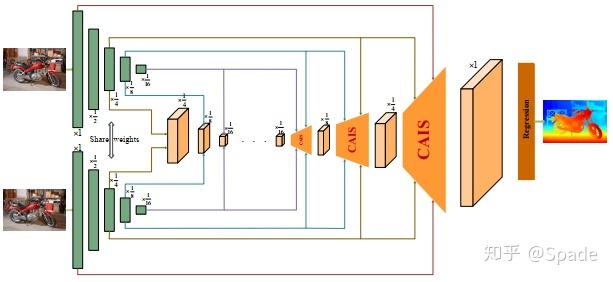
如图,本文的核心 CAIS 模块是用来实现代价体上采样的,同时还起到一定的聚合作用(同于其他网路中的 3D 卷积)。具体地,每个 CAIS 模块的输入是来自 2 个尺度的左右图特征(一共 4 条线)。接下来是 CAIS 的具体结构:
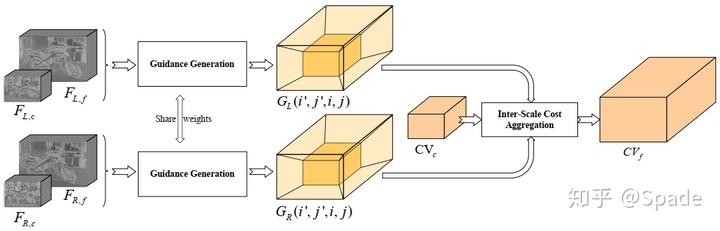
输入分别是左右图的粗(c)尺度和细(f)尺度特征,经过指导(这里指导的意思就是指导代价上采样)生成模块得到 G,可以看到,每个 G 是一个关于(i’, j’, i, j)的函数。(i’, j’)是大分辨率代价在 (H, W) 维度上的坐标,(i, j)是小分辨率代价在 (H, W) 维度上的坐标。大分辨率上代价某一点的值是通过聚合小分辨率代价值实现的,聚合的权重就是用 G 表示的。当然,代价体还有一个视差维度,所以代价上采样需要的聚合权重 G 应该是关于(i’, j’, d’, i, j, d)的函数。全 3D 空间的聚合上采样用下式表示(后面我们还会看到本文提出的另一个思路,将 3D 空间分解为视差 1D 空间和图像平面 2D 空间处理):
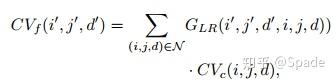
其中,
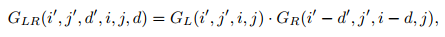
即:视差的上采样被嵌入到了 
的生成过程,这里蕴含的几何意义是,当图像上采样时,每个点的视差也要增大。而这里之所以能用一个 
和
的相乘就可以得到代价上采样的权重,是因为 Guidance 本身设计时,输出经过 softmax 得到一个 0-1 的值。聚合就是一个从小分辨率代价的某一邻域内加权平均,概率值就是 G;这里要区分一下当前立体匹配中的聚合过程,用于聚合的卷积核是不受限制的,而本文中是一个 0-1 的值。
接下来就是如何学习 G。这里可能我的理解也不太到位,感兴趣请仔细阅读原文。首先先给出符号化的表达,后面截图的公式会用到。
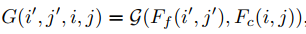
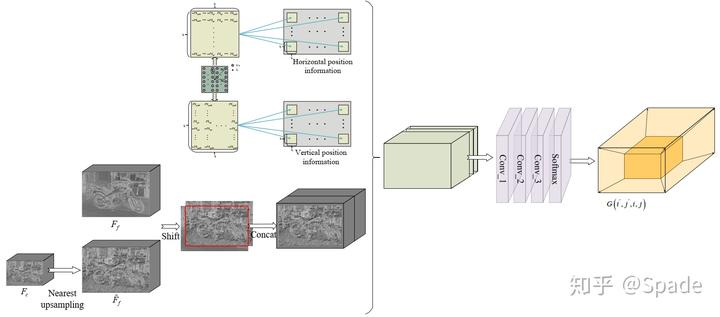
粗尺度的特征首先近邻插值到和细尺度同样大小。因为聚合是在一个小邻域进行,我们要学习的是邻域内每个点的权重。根据邻域内每个点的位置,对这两个特征进行不同方向的 padding,然后进行串联。而空间位置图就是重复的坐标矩阵,图中的每个元素都代表了一个方向向量(因此文中谈到显示地建模了空间位置关系)。将他们串联起来,经过卷积和 softmax 得到了最终的权重。
这一部分还可以这样理解:代价体的上采样是需要指导的,用于指导的信息就是来自 2 个尺度的特征的差异。
最后,关于将 3D 空间分解为 1D 空间和 2D 空间,是这样进行的。首先是 1D 的视差空间。在 cost volume 中,某一视差小邻域内 (i, j, d-n)~(i, j, d+n),对应的就是左图的(i, j) 和右图的(i-d+n, j)~(i-d-n, j)。由此,视差维度的聚合由以下 2 步组成:
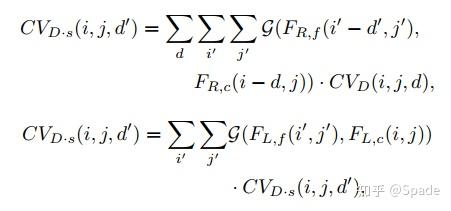
先右图某视差邻域上采样,再利用左图实现一个分辨率不变的映射。第二步输入的分辨率是 (i, j, d’),输出的分辨率也是 (i, j, d’)。随后,在进行 2D 图像空间的上采样,利用左图特征指导。
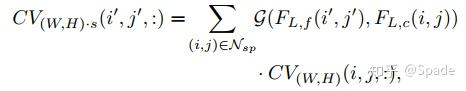
文中是谈到这样的分解能够提高计算效率。物理意义上讲分解的操作好像没什么特别之处。
实验结果:
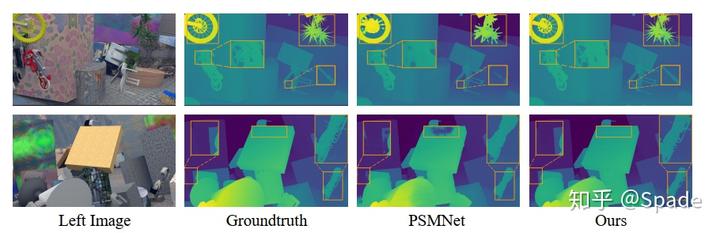

细节的恢复是相当好的,在 KITTI 排行榜上的指标也不错。
本文感觉问题的提出很好,就是上采样带来的细节损失问题。解决的思路能够理解,就是学习一些映射关系。结果还是很好的,尤其是根据文中给出的 SceneFlow 数据集上的指标和视觉结果。但是总感觉学习 G 那里的 location map 有些刻意,因为文中有谈到显示地编码不同尺度的空间关系,所以这里也可能是我的理解不太到位。
https://zhuanlan.zhihu.com/p/149848678

若有收获,就点个赞吧
0 人点赞
