引言
前段时间,『机器学习进阶笔记』系列一直关注 TensorFlow 系统的技术实践(想看 TensorFlow 技术实践的同学可直接拉到文章底部看相关阅读推荐),帮助大家从零开始,由浅入深,走上机器学习的进阶之路。虽然之前都在夸 TensorFlow 的好,但其劣势也很明显——对计算力要求太高,虽然使用方便,但是显存占用太高,计算也不够快,做公司项目还好,自己玩一些好玩的东西时太费时间了。
简而言之,穷!
今天新开一篇,给大家介绍另一个优秀而强大的深度学习框架——MXnet,现在 MXnet 资源相对少一点,基于 MXnet 的有意思的开源项目也相对少一点,不过没关系,都不是问题,他的优点是足够灵活,速度足够快,扩展新的功能比较容易,还有就是造 MXnet 都是一群说得上名字的大牛,能和大牛们玩一样的东西,想想都很兴奋有没有!
那我们开始吧:)
前言
如何找到自己实用的丹炉,是一个深度修真之人至关重要的,丹炉的好坏直接关系到炼丹的成功与否,道途千载,寻一合适丹炉也不妨这千古悠悠的修真(正)之路。
为什么学 mxnet? 熟悉本人博客的都知道,前段时间一直在关注 TensorFlow 也安利了很多次 TFlearn,为什么这次突然会写 MXnet 的东西呢?原因是没钱呀,TensorFlow 计算力要求太高,虽然使用方便,但是显存占用太高,计算也不够快,做公司项目还好,自己玩一些好玩的东西时太费时间,不过现在 MXnet 资源相对少一点,基于 MXnet 的有意思的开源项目也相对少一点,不过没关系,都不是问题,另外一点就是造 MXnet 都是一群说得上名字的大牛,能和大牛们玩一样的东西,想想都很兴奋。
MXnet 的文档一直被一些爱好者喷,确实文档比较少,不过考虑到开发者都是业余时间造轮子(不,造丹炉!),很那像其他的框架有那么熟悉的文档,不过还好,在 cv 这块还是比较容易下手的。 这里有我从最近开始接触 MXnet(其实很早就听说一直没有用过),学习的一些代码还有笔记mxnet 101, 没有特别细致研究,只是了解怎么用在 CV 上,完整的做一个项目。
新的丹方—inception-resnet-v2
每一付新的丹方,无不是深度前辈们多年经验的结晶,丹方,很多时候在同样炼丹材料表现天差地别,也成为传奇前辈们的一个个标志。
一看到这个名字就知道和 resnet 和 inception(googlenet 即是 inception-v1)逃脱不了干系,就是一个比较复杂的网络结构,具体多复杂?!玩过 tflearn 的去看看我写的代码,run 下 然后从 tensorboard 的 graph 打开看看,(之前一个被 merge 的版本后来发现没有 batch normalization)改了的提了 PR 但是在写博客的时候还没有被 mergeadd inception-resnet-v2 in branch inception-resnet-v2 #450。总之就是” 丹方” 特别复杂,具体去结合Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning,了解过 resnet 和 googlenet 的网络结构的小伙伴应该很容易弄明白,以下 tflearn 的代码参考tf.slim 下 inception-resnet-v2。 基本的代码结构:
# -*- coding: utf-8 -*-""" inception_resnet_v2.Applying 'inception_resnet_v2' to Oxford's 17 Category Flower Dataset classification task.References:Inception-v4, Inception-ResNet and the Impact of Residual Connectionson LearningChristian Szegedy, Sergey Ioffe, Vincent Vanhoucke, Alex Alemi.Links:[http://arxiv.org/abs/1602.07261](http://arxiv.org/abs/1602.07261)"""from __future__ import division, print_function, absolute_importimport tflearnfrom tflearn.layers.core import input_data, dropout, flatten, fully_connectedfrom tflearn.layers.conv import conv_2d, max_pool_2d, avg_pool_2dfrom tflearn.utils import repeatfrom tflearn.layers.merge_ops import mergefrom tflearn.data_utils import shuffle, to_categoricalimport tflearn.activations as activationsimport tflearn.datasets.oxflower17 as oxflower17def block35(net, scale=1.0, activation='relu'):tower_conv = conv_2d(net, 32, 1, normalizer_fn='batch_normalization', activation='relu', name='Conv2d_1x1')tower_conv1_0 = conv_2d(net, 32, 1, normalizer_fn='batch_normalization', activation='relu',name='Conv2d_0a_1x1')tower_conv1_1 = conv_2d(tower_conv1_0, 32, 3, normalizer_fn='batch_normalization', activation='relu',name='Conv2d_0b_3x3')tower_conv2_0 = conv_2d(net, 32, 1, normalizer_fn='batch_normalization', activation='relu', name='Conv2d_0a_1x1')tower_conv2_1 = conv_2d(tower_conv2_0, 48,3, normalizer_fn='batch_normalization', activation='relu', name='Conv2d_0b_3x3')tower_conv2_2 = conv_2d(tower_conv2_1, 64,3, normalizer_fn='batch_normalization', activation='relu', name='Conv2d_0c_3x3')tower_mixed = merge([tower_conv, tower_conv1_1, tower_conv2_2], mode='concat', axis=3)tower_out = conv_2d(tower_mixed, net.get_shape()[3], 1, normalizer_fn='batch_normalization', activation=None, name='Conv2d_1x1')net += scale * tower_outif activation:if isinstance(activation, str):net = activations.get(activation)(net)elif hasattr(activation, '__call__'):net = activation(net)else:raise ValueError("Invalid Activation.")return netdef block17(net, scale=1.0, activation='relu'):tower_conv = conv_2d(net, 192, 1, normalizer_fn='batch_normalization', activation='relu', name='Conv2d_1x1')tower_conv_1_0 = conv_2d(net, 128, 1, normalizer_fn='batch_normalization', activation='relu', name='Conv2d_0a_1x1')tower_conv_1_1 = conv_2d(tower_conv_1_0, 160,[1,7], normalizer_fn='batch_normalization', activation='relu',name='Conv2d_0b_1x7')tower_conv_1_2 = conv_2d(tower_conv_1_1, 192, [7,1], normalizer_fn='batch_normalization', activation='relu',name='Conv2d_0c_7x1')tower_mixed = merge([tower_conv,tower_conv_1_2], mode='concat', axis=3)tower_out = conv_2d(tower_mixed, net.get_shape()[3], 1, normalizer_fn='batch_normalization', activation=None, name='Conv2d_1x1')net += scale * tower_outif activation:if isinstance(activation, str):net = activations.get(activation)(net)elif hasattr(activation, '__call__'):net = activation(net)else:raise ValueError("Invalid Activation.")return netdef block8(net, scale=1.0, activation='relu'):""""""tower_conv = conv_2d(net, 192, 1, normalizer_fn='batch_normalization', activation='relu',name='Conv2d_1x1')tower_conv1_0 = conv_2d(net, 192, 1, normalizer_fn='batch_normalization', activation='relu', name='Conv2d_0a_1x1')tower_conv1_1 = conv_2d(tower_conv1_0, 224, [1,3], normalizer_fn='batch_normalization', name='Conv2d_0b_1x3')tower_conv1_2 = conv_2d(tower_conv1_1, 256, [3,1], normalizer_fn='batch_normalization', name='Conv2d_0c_3x1')tower_mixed = merge([tower_conv,tower_conv1_2], mode='concat', axis=3)tower_out = conv_2d(tower_mixed, net.get_shape()[3], 1, normalizer_fn='batch_normalization', activation=None, name='Conv2d_1x1')net += scale * tower_outif activation:if isinstance(activation, str):net = activations.get(activation)(net)elif hasattr(activation, '__call__'):net = activation(net)else:raise ValueError("Invalid Activation.")return net# Data loading and preprocessingimport tflearn.datasets.oxflower17 as oxflower17X, Y = oxflower17.load_data(one_hot=True, resize_pics=(299, 299))num_classes = 17dropout_keep_prob = 0.8network = input_data(shape=[None, 299, 299, 3])conv1a_3_3 = conv_2d(network, 32, 3, strides=2, normalizer_fn='batch_normalization', padding='VALID',activation='relu',name='Conv2d_1a_3x3')conv2a_3_3 = conv_2d(conv1a_3_3, 32, 3, normalizer_fn='batch_normalization', padding='VALID',activation='relu', name='Conv2d_2a_3x3')conv2b_3_3 = conv_2d(conv2a_3_3, 64, 3, normalizer_fn='batch_normalization', activation='relu', name='Conv2d_2b_3x3')maxpool3a_3_3 = max_pool_2d(conv2b_3_3, 3, strides=2, padding='VALID', name='MaxPool_3a_3x3')conv3b_1_1 = conv_2d(maxpool3a_3_3, 80, 1, normalizer_fn='batch_normalization', padding='VALID',activation='relu', name='Conv2d_3b_1x1')conv4a_3_3 = conv_2d(conv3b_1_1, 192, 3, normalizer_fn='batch_normalization', padding='VALID',activation='relu', name='Conv2d_4a_3x3')maxpool5a_3_3 = max_pool_2d(conv4a_3_3, 3, strides=2, padding='VALID', name='MaxPool_5a_3x3')tower_conv = conv_2d(maxpool5a_3_3, 96, 1, normalizer_fn='batch_normalization', activation='relu', name='Conv2d_5b_b0_1x1')tower_conv1_0 = conv_2d(maxpool5a_3_3, 48, 1, normalizer_fn='batch_normalization', activation='relu', name='Conv2d_5b_b1_0a_1x1')tower_conv1_1 = conv_2d(tower_conv1_0, 64, 5, normalizer_fn='batch_normalization', activation='relu', name='Conv2d_5b_b1_0b_5x5')tower_conv2_0 = conv_2d(maxpool5a_3_3, 64, 1, normalizer_fn='batch_normalization', activation='relu', name='Conv2d_5b_b2_0a_1x1')tower_conv2_1 = conv_2d(tower_conv2_0, 96, 3, normalizer_fn='batch_normalization', activation='relu', name='Conv2d_5b_b2_0b_3x3')tower_conv2_2 = conv_2d(tower_conv2_1, 96, 3, normalizer_fn='batch_normalization', activation='relu',name='Conv2d_5b_b2_0c_3x3')tower_pool3_0 = avg_pool_2d(maxpool5a_3_3, 3, strides=1, padding='same', name='AvgPool_5b_b3_0a_3x3')tower_conv3_1 = conv_2d(tower_pool3_0, 64, 1, normalizer_fn='batch_normalization', activation='relu',name='Conv2d_5b_b3_0b_1x1')tower_5b_out = merge([tower_conv, tower_conv1_1, tower_conv2_2, tower_conv3_1], mode='concat', axis=3)net = repeat(tower_5b_out, 10, block35, scale=0.17)tower_conv2_2 = conv_2d(tower_conv2_1, 96, 3, normalizer_fn='batch_normalization', activation='relu',name='Conv2d_5b_b2_0c_3x3')tower_pool3_0 = avg_pool_2d(maxpool5a_3_3, 3, strides=1, padding='same', name='AvgPool_5b_b3_0a_3x3')tower_conv3_1 = conv_2d(tower_pool3_0, 64, 1, normalizer_fn='batch_normalization', activation='relu',name='Conv2d_5b_b3_0b_1x1')tower_5b_out = merge([tower_conv, tower_conv1_1, tower_conv2_2, tower_conv3_1], mode='concat', axis=3)net = repeat(tower_5b_out, 10, block35, scale=0.17)tower_conv = conv_2d(net, 384, 3, normalizer_fn='batch_normalization', strides=2,activation='relu', padding='VALID', name='Conv2d_6a_b0_0a_3x3')tower_conv1_0 = conv_2d(net, 256, 1, normalizer_fn='batch_normalization', activation='relu', name='Conv2d_6a_b1_0a_1x1')tower_conv1_1 = conv_2d(tower_conv1_0, 256, 3, normalizer_fn='batch_normalization', activation='relu', name='Conv2d_6a_b1_0b_3x3')tower_conv1_2 = conv_2d(tower_conv1_1, 384, 3, normalizer_fn='batch_normalization', strides=2, padding='VALID', activation='relu',name='Conv2d_6a_b1_0c_3x3')tower_pool = max_pool_2d(net, 3, strides=2, padding='VALID',name='MaxPool_1a_3x3')net = merge([tower_conv, tower_conv1_2, tower_pool], mode='concat', axis=3)net = repeat(net, 20, block17, scale=0.1)tower_conv = conv_2d(net, 256, 1, normalizer_fn='batch_normalization', activation='relu', name='Conv2d_0a_1x1')tower_conv0_1 = conv_2d(tower_conv, 384, 3, normalizer_fn='batch_normalization', strides=2, padding='VALID', activation='relu',name='Conv2d_0a_1x1')tower_conv1 = conv_2d(net, 256, 1, normalizer_fn='batch_normalization', padding='VALID', activation='relu',name='Conv2d_0a_1x1')tower_conv1_1 = conv_2d(tower_conv1,288,3, normalizer_fn='batch_normalization', strides=2, padding='VALID',activation='relu', name='COnv2d_1a_3x3')tower_conv2 = conv_2d(net, 256,1, normalizer_fn='batch_normalization', activation='relu',name='Conv2d_0a_1x1')tower_conv2_1 = conv_2d(tower_conv2, 288,3, normalizer_fn='batch_normalization', name='Conv2d_0b_3x3',activation='relu')tower_conv2_2 = conv_2d(tower_conv2_1, 320, 3, normalizer_fn='batch_normalization', strides=2, padding='VALID',activation='relu', name='Conv2d_1a_3x3')tower_pool = max_pool_2d(net, 3, strides=2, padding='VALID', name='MaxPool_1a_3x3')net = merge([tower_conv0_1, tower_conv1_1,tower_conv2_2, tower_pool], mode='concat', axis=3)net = repeat(net, 9, block8, scale=0.2)net = block8(net, activation=None)net = conv_2d(net, 1536, 1, normalizer_fn='batch_normalization', activation='relu', name='Conv2d_7b_1x1')net = avg_pool_2d(net, net.get_shape().as_list()[1:3],strides=2, padding='VALID', name='AvgPool_1a_8x8')net = flatten(net)net = dropout(net, dropout_keep_prob)loss = fully_connected(net, num_classes,activation='softmax')network = tflearn.regression(loss, optimizer='RMSprop',loss='categorical_crossentropy',learning_rate=0.0001)model = tflearn.DNN(network, checkpoint_path='inception_resnet_v2',max_checkpoints=1, tensorboard_verbose=2, tensorboard_dir="./tflearn_logs/")model.fit(X, Y, n_epoch=1000, validation_set=0.1, shuffle=True,show_metric=True, batch_size=32, snapshot_step=2000,snapshot_epoch=False, run_id='inception_resnet_v2_17flowers')tower_conv = conv_2d(net, 384, 3, normalizer_fn='batch_normalization', strides=2,activation='relu', padding='VALID', name='Conv2d_6a_b0_0a_3x3')tower_conv1_0 = conv_2d(net, 256, 1, normalizer_fn='batch_normalization', activation='relu', name='Conv2d_6a_b1_0a_1x1')tower_conv1_1 = conv_2d(tower_conv1_0, 256, 3, normalizer_fn='batch_normalization', activation='relu', name='Conv2d_6a_b1_0b_3x3')tower_conv1_2 = conv_2d(tower_conv1_1, 384, 3, normalizer_fn='batch_normalization', strides=2, padding='VALID', activation='relu',name='Conv2d_6a_b1_0c_3x3')tower_pool = max_pool_2d(net, 3, strides=2, padding='VALID',name='MaxPool_1a_3x3')net = merge([tower_conv, tower_conv1_2, tower_pool], mode='concat', axis=3)net = repeat(net, 20, block17, scale=0.1)tower_conv = conv_2d(net, 256, 1, normalizer_fn='batch_normalization', activation='relu', name='Conv2d_0a_1x1')tower_conv0_1 = conv_2d(tower_conv, 384, 3, normalizer_fn='batch_normalization', strides=2, padding='VALID', activation='relu',name='Conv2d_0a_1x1')tower_conv1 = conv_2d(net, 256, 1, normalizer_fn='batch_normalization', padding='VALID', activation='relu',name='Conv2d_0a_1x1')tower_conv1_1 = conv_2d(tower_conv1,288,3, normalizer_fn='batch_normalization', strides=2, padding='VALID',activation='relu', name='COnv2d_1a_3x3')tower_conv2 = conv_2d(net, 256,1, normalizer_fn='batch_normalization', activation='relu',name='Conv2d_0a_1x1')tower_conv2_1 = conv_2d(tower_conv2, 288,3, normalizer_fn='batch_normalization', name='Conv2d_0b_3x3',activation='relu')tower_conv2_2 = conv_2d(tower_conv2_1, 320, 3, normalizer_fn='batch_normalization', strides=2, padding='VALID',activation='relu', name='Conv2d_1a_3x3')tower_pool = max_pool_2d(net, 3, strides=2, padding='VALID', name='MaxPool_1a_3x3')net = merge([tower_conv0_1, tower_conv1_1,tower_conv2_2, tower_pool], mode='concat', axis=3)net = repeat(net, 9, block8, scale=0.2)net = block8(net, activation=None)net = conv_2d(net, 1536, 1, normalizer_fn='batch_normalization', activation='relu', name='Conv2d_7b_1x1')net = avg_pool_2d(net, net.get_shape().as_list()[1:3],strides=2, padding='VALID', name='AvgPool_1a_8x8')net = flatten(net)net = dropout(net, dropout_keep_prob)loss = fully_connected(net, num_classes,activation='softmax')network = tflearn.regression(loss, optimizer='RMSprop',loss='categorical_crossentropy',learning_rate=0.0001)model = tflearn.DNN(network, checkpoint_path='inception_resnet_v2',max_checkpoints=1, tensorboard_verbose=2, tensorboard_dir="./tflearn_logs/")model.fit(X, Y, n_epoch=1000, validation_set=0.1, shuffle=True,show_metric=True, batch_size=32, snapshot_step=2000,snapshot_epoch=False, run_id='inception_resnet_v2_17flowers')
想要 run 下的可以去使用下 tflearn,注意更改 conv_2d 里面的内容,我这里在本身 conv_2d 上加了个 normalizer_fn,来使用 batch_normalization。
MXnet 炼丹
不同的丹炉,即使是相同的丹方,炼丹的方式都不仅相同。
在打算用 MXnet 实现 inception-resnet-v2 之前,除了 mxnet-101 里面的代码,基本没有写过 mxnet,但是没关系,不怕,有很多其他大神写的丹方,这里具体参考了symbol_inception-bn.py。首先,为了减少代码条数,参考创建一个 ConvFactory,但是和 inception-bn 不同的是,inception-resnet-v2 要考虑是否要激活函数的版本。所以 inception-resnet-v2 的 ConvFactory 如下:
def ConvFactory(data, num_filter, kernel, stride=(1,1), pad=(0, 0), act_type="relu", mirror_attr={},with_act=True):conv = mx.symbol.Convolution(data=data, num_filter=num_filter, kernel=kernel, stride=stride, pad=pad)bn = mx.symbol.BatchNorm(data=conv)if with_act:act = mx.symbol.Activation(data = bn, act_type=act_type, attr=mirror_attr)return actelse:return bn
然后就简单了,按照网络一路往下写:
def get_symbol(num_classes=1000,input_data_shape=(64,3,299,299)):data = mx.symbol.Variable(name='data')conv1a_3_3 = ConvFactory(data=data, num_filter=32, kernel=(3,3), stride=(2, 2))conv2a_3_3 = ConvFactory(conv1a_3_3, 32, (3,3))conv2b_3_3 = ConvFactory(conv2a_3_3, 64, (3,3), pad=(1,1))maxpool3a_3_3 = mx.symbol.Pooling(data=conv2b_3_3, kernel=(3, 3), stride=(2, 2), pool_type='max')conv3b_1_1 = ConvFactory(maxpool3a_3_3, 80 ,(1,1))conv4a_3_3 = ConvFactory(conv3b_1_1, 192, (3,3))maxpool5a_3_3 = mx.symbol.Pooling(data=conv4a_3_3, kernel=(3,3), stride=(2,2), pool_type='max')tower_conv = ConvFactory(maxpool5a_3_3, 96, (1,1))tower_conv1_0 = ConvFactory(maxpool5a_3_3, 48, (1,1))tower_conv1_1 = ConvFactory(tower_conv1_0, 64, (5,5), pad=(2,2))tower_conv2_0 = ConvFactory(maxpool5a_3_3, 64, (1,1))tower_conv2_1 = ConvFactory(tower_conv2_0, 96, (3,3), pad=(1,1))tower_conv2_2 = ConvFactory(tower_conv2_1, 96, (3,3), pad=(1,1))tower_pool3_0 = mx.symbol.Pooling(data=maxpool5a_3_3, kernel=(3,3), stride=(1,1),pad=(1,1), pool_type='avg')tower_conv3_1 = ConvFactory(tower_pool3_0, 64, (1,1))tower_5b_out = mx.symbol.Concat(*[tower_conv, tower_conv1_1, tower_conv2_2, tower_conv3_1])
然后就不对了,要重复条用一个 block35 的结构,repeat 函数很容易实现,给定调用次数,调用函数,参数, 多次调用就好了:
def repeat(inputs, repetitions, layer, *args, **kwargs):outputs = inputsfor i in range(repetitions):outputs = layer(outputs, *args, **kwargs)return outputs
这里很简单,但是 block35 就有问题啦,这个子结构的目的要输出与输入同样大小的 channel 数,之前因为在 tensorflow 下写的,很容易拿到一个 Variable 的 shape,但是在 MXnet 上就很麻烦,这里不知道怎么做,提了个 issue How can i get the shape with the net?,然后就去查 api,发现有个 infer_shape,mxnet 客服部小伙伴也让我用这个去做, 试了试,挺管用能够拿到 shape,但是必须给入一个 4d 的 tensor 的 shape,比如 (64,3,299,299),他会在 graph 运行时 infer 到对应 symbol 的 shape,然后就这么写了:
def block35(net, input_data_shape, scale=1.0, with_act=True, act_type='relu', mirror_attr={}):assert len(input_data_shape) == 4, 'input_data_shape should be len of 4, your \input_data_shape is len of %d'%len(input_data_shape)_, out_shape,_ = net.infer_shape(data=input_data_shape)tower_conv = ConvFactory(net, 32, (1,1))tower_conv1_0 = ConvFactory(net, 32, (1,1))tower_conv1_1 = ConvFactory(tower_conv1_0, 32, (3, 3), pad=(1,1))tower_conv2_0 = ConvFactory(net, 32, (1,1))tower_conv2_1 = ConvFactory(tower_conv2_0, 48, (3, 3), pad=(1,1))tower_conv2_2 = ConvFactory(tower_conv2_1, 64, (3, 3), pad=(1,1))tower_mixed = mx.symbol.Concat(*[tower_conv, tower_conv1_1, tower_conv2_2])tower_out = ConvFactory(tower_mixed, out_shape[0][1], (1,1), with_act=False)net += scale * tower_outif with_act:act = mx.symbol.Activation(data = net, act_type=act_type, attr=mirror_attr)return actelse:return net
大家是不是感到很别扭,我也觉得很别扭,但是我一直是个『不拘小节』的工程师,对这块不斤斤计较,所以,写完这块之后也觉得就成了接下来就是 block17, block8, 这里都很简单的很类似,就不提了。
然后就接下来一段,很快就完成了:
net = repeat(tower_5b_out, 10, block35, scale=0.17, input_num_channels=320)tower_conv = ConvFactory(net, 384, (3,3),stride=(2,2))tower_conv1_0 = ConvFactory(net, 256, (1,1))tower_conv1_1 = ConvFactory(tower_conv1_0, 256, (3,3), pad=(1,1))tower_conv1_2 = ConvFactory(tower_conv1_1, 384, (3,3),stride=(2,2))tower_pool = mx.symbol.Pooling(net, kernel=(3,3), stride=(2,2), pool_type='max')net = mx.symbol.Concat(*[tower_conv, tower_conv1_2, tower_pool])net = repeat(net, 20, block17, scale=0.1, input_num_channels=1088)tower_conv = ConvFactory(net, 256, (1,1))tower_conv0_1 = ConvFactory(tower_conv, 384, (3,3), stride=(2,2))tower_conv1 = ConvFactory(net, 256, (1,1))tower_conv1_1 = ConvFactory(tower_conv1, 288, (3,3), stride=(2,2))tower_conv2 = ConvFactory(net, 256, (1,1))tower_conv2_1 = ConvFactory(tower_conv2, 288, (3,3), pad=(1,1))tower_conv2_2 = ConvFactory(tower_conv2_1, 320, (3,3), stride=(2,2))tower_pool = mx.symbol.Pooling(net, kernel=(3,3), stride=(2,2), pool_type='max')net = mx.symbol.Concat(*[tower_conv0_1, tower_conv1_1, tower_conv2_2, tower_pool])net = repeat(net, 9, block8, scale=0.2, input_num_channels=2080)net = block8(net, with_act=False, input_num_channel=2080)net = ConvFactory(net, 1536, (1,1))net = mx.symbol.Pooling(net, kernel=(1,1), global_pool=True, stride=(2,2), pool_type='avg')net = mx.symbol.Flatten(net)net = mx.symbol.Dropout(data=net,p= 0.8)net = mx.symbol.FullyConnected(data=net,num_hidden=num_classes)softmax = mx.symbol.SoftmaxOutput(data=net, name='softmax')
感觉很开心,写完了,这么简单,大家先忽略先忽悠所有的 pad 值,因为找不到没有 pad 的版本,所以大家先忽略下。然后就是写样例测试呀,又是 17flowers 这个数据集,参考 mxnet-101 中如何把 dataset 转换为 binary, 首先写个 py 来 get 到所有的图像 list,index 还有他的 label_index,这个很快就解决了。
具体参考我这里的mxnet-101 然后就是拿数据开始 run 啦,Ready? Go!
咦, 车开不起来,不对,都是些什么鬼? infer_shape 有问题? 没事,查 api tensorflow 中 padding 是”valid” 和”same”,mxnet 中没有, 没有…,要自己计算,什么鬼?没有 valid,same,我不会呀!!!
写了这么久,就不写了?不行,找下怎么搞定,看了 tensorflow 的文档,翻了资料,same 就是保证 input 与 output 保持一致,valid 就无所谓,不需要设置 pad,所以当 tensorflow 中有 same 的时候,就需要在 mxnet 中设置对应的 pad 值,kernel 为 3 的时候 pad=1, kernel=5,pad=2。这里改来改去,打印出每一层网络后的 shape,前后花了我大概 6 个小时,终于让我一步一步 debug 出来了,但是不对,在 repeat 10 次 block35 后,怎么和 tf.slim 的 inception-resnet-v2 的注释的 shape 不同?
我了个擦,当时已经好像快凌晨 4 点了,本以为 run 起来了,怎么就解释不通呢?不会 tensorflow 的注释有问题吧?我了个擦,老美真是数学有点问题,提了个 issue,很快就有人 fix 然后 commit 了 may be an error in slim.nets.inception_resnet_v2 #634,不过貌似到现在还没有被 merge。
一切 ok,开始 run 了,用 17flowers,很快可以收敛,没有更多的资源来测试更大的数据集,就直接提交了,虽然代码很烂,但怎么着也是一步一步写出来的,可是,始终确实是有点问题,后来经过 github 的好心人指点肯定也是一个大牛,告诉我 Pooling 有个 global_pool 来做全局的池化,我了个擦,这么好的东西,tensorflow 上可没有,所以 tensorflow 上用的是通过 get_shape 拿到对应的 tensor 的 width 和 height 来做 pooling,我也二笔的在 mxne 它里面这样用,所以需要 input_shape_shape 来 infer 到所在 layer 的 shape,来做全局池化,有了这个,我还 infer_shape 个什么鬼,blockxx 里面也不需要了,channel 数可以直接手工计算,传一个 channel 数就好了,get_symbol 也可以保持和原来一样不需要传什么 input_data_shape 啦!!!
感谢zhreshold的提示,一切都 ok,更改了,但是后面 mxnet 的大神在重构一些代码,还没有 merge,不过没有关系,等他们 ok 了 我再把 inception-resnet-v2 整理下,再提 pr(教练,我想当 mxnet contributor)。
def block35(net, input_num_channels, scale=1.0, with_act=True, act_type='relu', mirror_attr={}):tower_conv = ConvFactory(net, 32, (1,1))tower_conv1_0 = ConvFactory(net, 32, (1,1))tower_conv1_1 = ConvFactory(tower_conv1_0, 32, (3, 3), pad=(1,1))tower_conv2_0 = ConvFactory(net, 32, (1,1))tower_conv2_1 = ConvFactory(tower_conv2_0, 48, (3, 3), pad=(1,1))tower_conv2_2 = ConvFactory(tower_conv2_1, 64, (3, 3), pad=(1,1))tower_mixed = mx.symbol.Concat(*[tower_conv, tower_conv1_1, tower_conv2_2])tower_out = ConvFactory(tower_mixed, input_num_channels, (1,1), with_act=False)net += scale * tower_outif with_act:act = mx.symbol.Activation(data = net, act_type=act_type, attr=mirror_attr)return actelse:return net
一直到这里,inception-resnet-v2 就写出来了,但是只是测试了小数据集,后来在 zhihu 上偶遇李沐大神,果断上去套近乎,最后拿到一个一台机器,就在测大一点的数据集,其实也不大,102flowers,之后会请沐神帮忙扩展一个大点的盘来放下 ImageNet,测试一下性能,不过现在 102flowers 也还行,效果还不错。
丹成
金丹品阶高低,以丹纹记,不同炼丹材料丹纹不同,评判标准也不同,acc 是最常用判断金丹品阶高低的手段。
将 102flower 按 9:1 分成训练集和验证集,设置 300 个 epoch(数据集比较小,貌似设置多点 epoch 才能有比较好的性能,看有小伙伴用 inception-bn 在 imagenet 上只需要 50 个 epoch),网络 inception-resnet-v2 确实大,如此小的数据集上 300 epoch 大概也需要 1 天,不过对比 tensorflow 那是快多了。
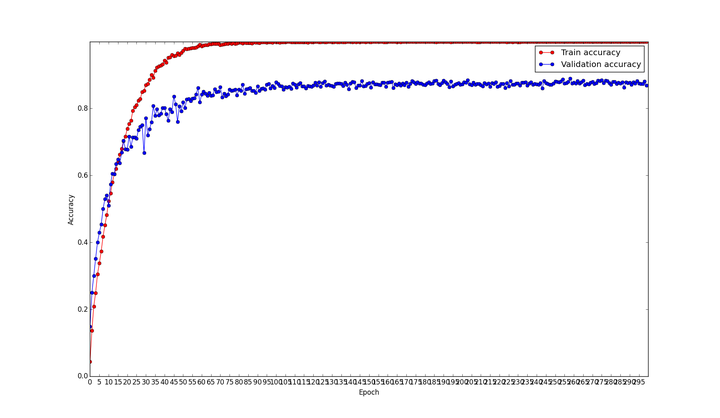
编不下去了(predict)
这里,会简单地写一个 inference 的例子,算作学习如果使用训练好的 model,注意还是最好使用 python 的 opencv,因为 mxnet 官方是用的 opencv,使用 cv2 这个库,我在网上找的使用 skimage 的库,做出来的始终有问题,应该是 brg2rgb 的问题,使用 cv2 的 cv2.cvtColor(img, cv2.COLOR_BGR2RGB 之后会成功:
import mxnet as mximport loggingimport numpy as npimport cv2import scipy.io as siologger = logging.getLogger()logger.setLevel(logging.DEBUG)num_round = 260prefix = "102flowers"model = mx.model.FeedForward.load(prefix, num_round, ctx=mx.cpu(), numpy_batch_size=1)# synset = [l.strip() for l in open('Inception/synset.txt').readlines()]def PreprocessImage(path, show_img=False):# load imageimg = cv2.imread(path)img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)mean_img = mx.nd.load('mean.bin').values()[0].asnumpy()print img.shapeprint mean_img.shapeimg = cv2.resize(img,(299,299))img = np.swapaxes(img, 0, 2)img = np.swapaxes(img, 1, 2)img = img -mean_imgimg = img[np.newaxis, :]print img.shapereturn imgright = 0sum = 0with open('test.lst', 'r') as fread:for line in fread.readlines()[:20]:sum +=1batch = '../day2/102flowers/' + line.split("\t")[2].strip("\n")print batchbatch = PreprocessImage(batch, False)prob = model.predict(batch)[0]pred = np.argsort(prob)[::-1]# # Get top1 label# top1 = synset[pred[0]]top_1 = pred[0]if top_1 == int(line.split("\t")[1]):print 'top1 right'right += 1print 'top 1 accuracy: %f '%(right/(1.0*sum))
使用第 260 个 epoch 的模型 weight,这里因为手贱删除了 9:1 时的 test.lst,只能用 7:3 是的 test.lst 暂时做计算,最后 accuracy 应该会比较偏高,不过这不是重点。
总结(继续编不下去了)
在这样一次畅快淋漓的 mxnet 之旅后,总结一下遇到的几个坑,与大家分享:
- 无法直接拿到 tensor 的 shape 信息,通过 infer_shape,在设计代码时走了很多;
- im2rec 时,准备的 train.lst, test.lst 未 shuffle,在 102flowers 上我都没有发觉,在后面做鉴黄的 training 的时候发现开始 training accuracy,分析可能是 train.lst 未 shuffle 的问题(以为在 ImageRecordIter 中有 shuffle 参数,就不需要),改了后没有 training accuracy 从开始就为 1 的情况;
- pad 值的问题,翻阅了很多资料才解决,文档也没有特别多相关的,对于我这种从 tensorflow 转 mxnet 的小伙伴来说是个比较大的坑;
- predict 的问题,找了 mxnet github 的源上的 example,并不能成功,在找官网上的 example 发现使用的是 cv2,并不是一些例子当中的 skimage,考虑到 mxnet 在安装时需要 opencv,可能 cv2 和 skimage 在一些标准上有差异,就改用 cv2 的 predict 版本,还有读入图片之后要 cv2.cvtColor(img, cv2.COLOR_BGR2RGB).
- 还是 predict 的问题,在 mxnet 中,构造 ImageRecordIter 时没有指定 mean.bin,但是并不是说计算的时候不会减到均值图片在训练,开始误解为不需要减到均值图片,后来发现一直不正确,考虑到 train 的时候会自己生成 mean.bin,猜测可能是这里的问题,通过 mean_img = mx.nd.load(‘mean.bin’).values()[0].asnumpy() 读入后,在原始图片减去均值图,结果 ok;但整个流程相对于 tf.slim 的 predict 还是比较复杂的。
优点
- 速度快,速度快,速度快,具体指没有做测量,但是相对于 tensorflow 至少两到三倍;
- 占用内存低, 同样 batch 和模型,12g 的显存,tf 会爆,但是 mxnet 只需要占用 7g 多点;
- im2rec 很方便,相对于 tensorflow 下 tfrecord 需要写部分代码,更容易入手,但是切记自己生成 train.lst, test.lst 的时候要 shuffle;
- Pooling 下的 global_pool 是个好东西,tensorflow 没有;
——————
That is all!之后会在 ImageNet Dataset 做一下测试,感觉会更有意思。
坐等更新,期待!
相关阅读推荐:
机器学习进阶笔记之六 | 深入理解 Fast Neural Style
机器学习进阶笔记之五 | 深入理解 VGG\Residual Network
机器学习进阶笔记之二 | 深入理解 Neural Style
本文由『UCloud 内核与虚拟化研发团队』提供。
关于作者:
Burness( ), UCloud 平台研发中心深度学习研发工程师,tflearn Contributor & tensorflow Contributor,做过电商推荐、精准化营销相关算法工作,专注于分布式深度学习框架、计算机视觉算法研究,平时喜欢玩玩算法,研究研究开源的项目,偶尔也会去一些数据比赛打打酱油,生活中是个极客,对新技术、新技能痴迷。
你可以在 Github 上找到他:http://hacker.duanshishi.com/
「UCloud 机构号」将独家分享云计算领域的技术洞见、行业资讯以及一切你想知道的相关讯息。
欢迎提问 & 求关注 o(////▽////)q~

若有收获,就点个赞吧
0 人点赞
