引言
TensorFlow 是 Google 基于 DistBelief 进行研发的第二代人工智能学习系统,被广泛用于语音识别或图像识别等多项机器深度学习领域。其命名来源于本身的运行原理。Tensor(张量)意味着 N 维数组,Flow(流)意味着基于数据流图的计算,TensorFlow 代表着张量从图象的一端流动到另一端计算过程,是将复杂的数据结构传输至人工智能神经网中进行分析和处理的过程。
TensorFlow 完全开源,任何人都可以使用。可在小到一部智能手机、大到数千台数据中心服务器的各种设备上运行。
『机器学习进阶笔记』系列将深入解析 TensorFlow 系统的技术实践,从零开始,由浅入深,与大家一起走上机器学习的进阶之路。
GoogLeNet 是 ILSVRC 2014 的冠军,主要是直径经典的 LeNet-5 算法,主要是 Google 的 team 成员完成,paper 见Going Deeper with Convolutions. 相关工作主要包括LeNet-5、Gabor filters、Network-in-Network.Network-in-Network 改进了传统的 CNN 网络,采用少量的参数就轻松地击败了 AlexNet 网络,使用 Network-in-Network 的模型最后大小约为 29MNetwork-in-Network caffe model.GoogLeNet 借鉴了 Network-in-Network 的思想,下面会详细讲述下。
Network-in-Network
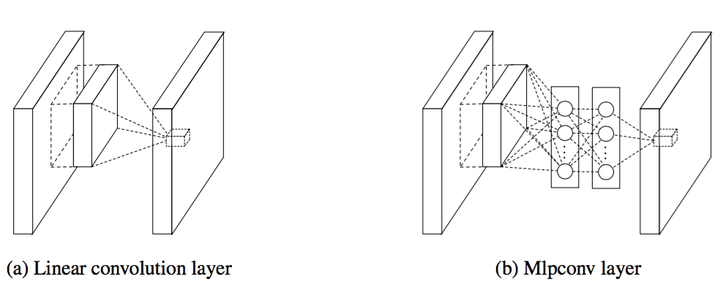
左边是我们 CNN 的线性卷积层,一般来说线性卷积层用来提取线性可分的特征,但所提取的特征高度非线性时,我们需要更加多的 filters 来提取各种潜在的特征,这样就存在一个问题,filters 太多,导致网络参数太多,网络过于复杂对于计算压力太大。
文章主要从两个方法来做了一些改良:1,卷积层的改进:MLPconv,在每个 local 部分进行比传统卷积层复杂的计算,如上图右,提高每一层卷积层对于复杂特征的识别能力,这里举个不恰当的例子,传统的 CNN 网络,每一层的卷积层相当于一个只会做单一任务,你必须要增加海量的 filters 来达到完成特定量类型的任务,而 MLPconv 的每层 conv 有更加大的能力,每一层能够做多种不同类型的任务,在选择 filters 时只需要很少量的部分;2,采用全局均值池化来解决传统 CNN 网络中最后全连接层参数过于复杂的特点,而且全连接会造成网络的泛化能力差,Alexnet 中有提高使用 dropout 来提高网络的泛化能力。

最后作者设计了一个 4 层的 Network-in-network + 全局均值池化层来做 imagenet 的分类问题.
class NiN(Network):def setup(self):(self.feed('data').conv(11, 11, 96, 4, 4, padding='VALID', name='conv1').conv(1, 1, 96, 1, 1, name='cccp1').conv(1, 1, 96, 1, 1, name='cccp2').max_pool(3, 3, 2, 2, name='pool1').conv(5, 5, 256, 1, 1, name='conv2').conv(1, 1, 256, 1, 1, name='cccp3').conv(1, 1, 256, 1, 1, name='cccp4').max_pool(3, 3, 2, 2, padding='VALID', name='pool2').conv(3, 3, 384, 1, 1, name='conv3').conv(1, 1, 384, 1, 1, name='cccp5').conv(1, 1, 384, 1, 1, name='cccp6').max_pool(3, 3, 2, 2, padding='VALID', name='pool3').conv(3, 3, 1024, 1, 1, name='conv4-1024').conv(1, 1, 1024, 1, 1, name='cccp7-1024').conv(1, 1, 1000, 1, 1, name='cccp8-1024').avg_pool(6, 6, 1, 1, padding='VALID', name='pool4').softmax(name='prob'))
网络基本结果如上,代码见GitHub - ethereon/caffe-tensorflow: Caffe models in TensorFlow.
这里因为我最近工作变动的问题,没有了机器来跑一篇,也无法画下基本的网络结构图,之后我会补上。这里指的提出的是中间 cccp1 和 ccp2(cross channel pooling)等价于 1*1kernel 大小的卷积层。caffe 中 NIN 的实现如下:
name: "nin_imagenet"layers {top: "data"top: "label"name: "data"type: DATAdata_param {source: "/home/linmin/IMAGENET-LMDB/imagenet-train-lmdb"backend: LMDBbatch_size: 64}transform_param {crop_size: 224mirror: truemean_file: "/home/linmin/IMAGENET-LMDB/imagenet-train-mean"}include: { phase: TRAIN }}layers {top: "data"top: "label"name: "data"type: DATAdata_param {source: "/home/linmin/IMAGENET-LMDB/imagenet-val-lmdb"backend: LMDBbatch_size: 89}transform_param {crop_size: 224mirror: falsemean_file: "/home/linmin/IMAGENET-LMDB/imagenet-train-mean"}include: { phase: TEST }}layers {bottom: "data"top: "conv1"name: "conv1"type: CONVOLUTIONblobs_lr: 1blobs_lr: 2weight_decay: 1weight_decay: 0convolution_param {num_output: 96kernel_size: 11stride: 4weight_filler {type: "gaussian"mean: 0std: 0.01}bias_filler {type: "constant"value: 0}}}layers {bottom: "conv1"top: "conv1"name: "relu0"type: RELU}layers {bottom: "conv1"top: "cccp1"name: "cccp1"type: CONVOLUTIONblobs_lr: 1blobs_lr: 2weight_decay: 1weight_decay: 0convolution_param {num_output: 96kernel_size: 1stride: 1weight_filler {type: "gaussian"mean: 0std: 0.05}bias_filler {type: "constant"value: 0}}}layers {bottom: "cccp1"top: "cccp1"name: "relu1"type: RELU}layers {bottom: "cccp1"top: "cccp2"name: "cccp2"type: CONVOLUTIONblobs_lr: 1blobs_lr: 2weight_decay: 1weight_decay: 0convolution_param {num_output: 96kernel_size: 1stride: 1weight_filler {type: "gaussian"mean: 0std: 0.05}bias_filler {type: "constant"value: 0}}}layers {bottom: "cccp2"top: "cccp2"name: "relu2"type: RELU}layers {bottom: "cccp2"top: "pool0"name: "pool0"type: POOLINGpooling_param {pool: MAXkernel_size: 3stride: 2}}layers {bottom: "pool0"top: "conv2"name: "conv2"type: CONVOLUTIONblobs_lr: 1blobs_lr: 2weight_decay: 1weight_decay: 0convolution_param {num_output: 256pad: 2kernel_size: 5stride: 1weight_filler {type: "gaussian"mean: 0std: 0.05}bias_filler {type: "constant"value: 0}}}layers {bottom: "conv2"top: "conv2"name: "relu3"type: RELU}layers {bottom: "conv2"top: "cccp3"name: "cccp3"type: CONVOLUTIONblobs_lr: 1blobs_lr: 2weight_decay: 1weight_decay: 0convolution_param {num_output: 256kernel_size: 1stride: 1weight_filler {type: "gaussian"mean: 0std: 0.05}bias_filler {type: "constant"value: 0}}}layers {bottom: "cccp3"top: "cccp3"name: "relu5"type: RELU}layers {bottom: "cccp3"top: "cccp4"name: "cccp4"type: CONVOLUTIONblobs_lr: 1blobs_lr: 2weight_decay: 1weight_decay: 0convolution_param {num_output: 256kernel_size: 1stride: 1weight_filler {type: "gaussian"mean: 0std: 0.05}bias_filler {type: "constant"value: 0}}}layers {bottom: "cccp4"top: "cccp4"name: "relu6"type: RELU}layers {bottom: "cccp4"top: "pool2"name: "pool2"type: POOLINGpooling_param {pool: MAXkernel_size: 3stride: 2}}layers {bottom: "pool2"top: "conv3"name: "conv3"type: CONVOLUTIONblobs_lr: 1blobs_lr: 2weight_decay: 1weight_decay: 0convolution_param {num_output: 384pad: 1kernel_size: 3stride: 1weight_filler {type: "gaussian"mean: 0std: 0.01}bias_filler {type: "constant"value: 0}}}layers {bottom: "conv3"top: "conv3"name: "relu7"type: RELU}layers {bottom: "conv3"top: "cccp5"name: "cccp5"type: CONVOLUTIONblobs_lr: 1blobs_lr: 2weight_decay: 1weight_decay: 0convolution_param {num_output: 384kernel_size: 1stride: 1weight_filler {type: "gaussian"mean: 0std: 0.05}bias_filler {type: "constant"value: 0}}}layers {bottom: "cccp5"top: "cccp5"name: "relu8"type: RELU}layers {bottom: "cccp5"top: "cccp6"name: "cccp6"type: CONVOLUTIONblobs_lr: 1blobs_lr: 2weight_decay: 1weight_decay: 0convolution_param {num_output: 384kernel_size: 1stride: 1weight_filler {type: "gaussian"mean: 0std: 0.05}bias_filler {type: "constant"value: 0}}}layers {bottom: "cccp6"top: "cccp6"name: "relu9"type: RELU}layers {bottom: "cccp6"top: "pool3"name: "pool3"type: POOLINGpooling_param {pool: MAXkernel_size: 3stride: 2}}layers {bottom: "pool3"top: "pool3"name: "drop"type: DROPOUTdropout_param {dropout_ratio: 0.5}}layers {bottom: "pool3"top: "conv4"name: "conv4-1024"type: CONVOLUTIONblobs_lr: 1blobs_lr: 2weight_decay: 1weight_decay: 0convolution_param {num_output: 1024pad: 1kernel_size: 3stride: 1weight_filler {type: "gaussian"mean: 0std: 0.05}bias_filler {type: "constant"value: 0}}}layers {bottom: "conv4"top: "conv4"name: "relu10"type: RELU}layers {bottom: "conv4"top: "cccp7"name: "cccp7-1024"type: CONVOLUTIONblobs_lr: 1blobs_lr: 2weight_decay: 1weight_decay: 0convolution_param {num_output: 1024kernel_size: 1stride: 1weight_filler {type: "gaussian"mean: 0std: 0.05}bias_filler {type: "constant"value: 0}}}layers {bottom: "cccp7"top: "cccp7"name: "relu11"type: RELU}layers {bottom: "cccp7"top: "cccp8"name: "cccp8-1024"type: CONVOLUTIONblobs_lr: 1blobs_lr: 2weight_decay: 1weight_decay: 0convolution_param {num_output: 1000kernel_size: 1stride: 1weight_filler {type: "gaussian"mean: 0std: 0.01}bias_filler {type: "constant"value: 0}}}layers {bottom: "cccp8"top: "cccp8"name: "relu12"type: RELU}layers {bottom: "cccp8"top: "pool4"name: "pool4"type: POOLINGpooling_param {pool: AVEkernel_size: 6stride: 1}}layers {name: "accuracy"type: ACCURACYbottom: "pool4"bottom: "label"top: "accuracy"include: { phase: TEST }}layers {bottom: "pool4"bottom: "label"name: "loss"type: SOFTMAX_LOSSinclude: { phase: TRAIN }}
NIN 的提出其实也可以认为我们加深了网络的深度,通过加深网络深度(增加单个 NIN 的特征表示能力)以及将原先全连接层变为 aver_pool 层,大大减少了原先需要的 filters 数,减少了 model 的参数。paper 中实验证明达到 Alexnet 相同的性能,最终 model 大小仅为 29M。
理解 NIN 之后,再来看 GoogLeNet 就不会有不明所理的感觉。
GoogLeNet
痛点
- 越大的 CNN 网络,有更大的 model 参数,也需要更多的计算力支持,并且由于模型过于复杂会过拟合;
- 在 CNN 中,网络的层数的增加会伴随着需求计算资源的增加;
- 稀疏的 network 是可以接受,但是稀疏的数据结构通常在计算时效率很低
Inception module
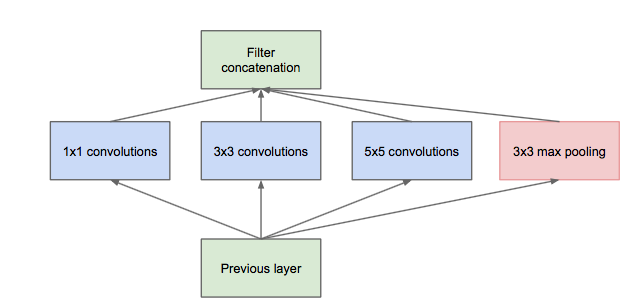
Inception module 的提出主要考虑多个不同 size 的卷积核能够 hold 图像当中不同 cluster 的信息,为方便计算,paper 中分别使用 11,33,55,同时加入 33 max pooling 模块。
然而这里存在一个很大的计算隐患,每一层 Inception module 的输出的 filters 将是分支所有 filters 数量的综合,经过多层之后,最终 model 的数量将会变得巨大,naive 的 inception 会对计算资源有更大的依赖。
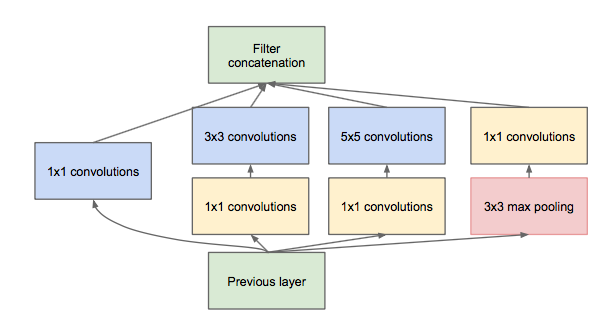
前面我们有提到 Network-in-Network 模型,1*1 的模型能够有效进行降维(使用更少的来表达尽可能多的信息),所以文章提出了”Inception module with dimension reduction”, 在不损失模型特征表示能力的前提下,尽量减少 filters 的数量,达到减少 model 复杂度的目的:
Overall of GoogLeNet
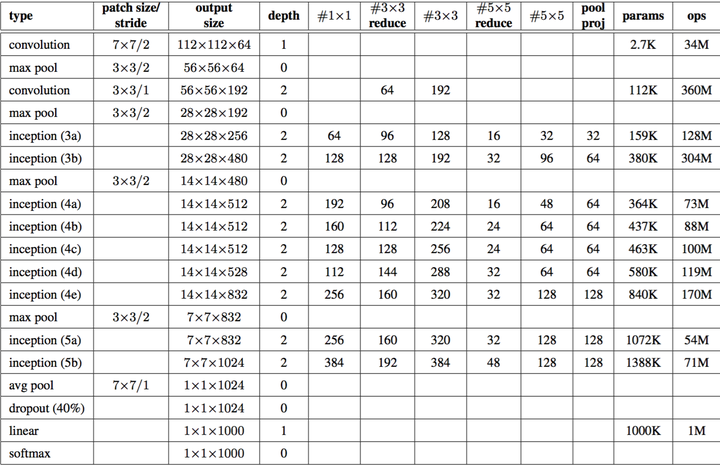
在 tensorflow 构造 GoogLeNet 基本的代码:
from kaffe.tensorflow import Network
class GoogleNet(Network):
def setup(self):(self.feed('data').conv(7, 7, 64, 2, 2, name='conv1_7x7_s2').max_pool(3, 3, 2, 2, name='pool1_3x3_s2').lrn(2, 2e-05, 0.75, name='pool1_norm1').conv(1, 1, 64, 1, 1, name='conv2_3x3_reduce').conv(3, 3, 192, 1, 1, name='conv2_3x3').lrn(2, 2e-05, 0.75, name='conv2_norm2').max_pool(3, 3, 2, 2, name='pool2_3x3_s2').conv(1, 1, 64, 1, 1, name='inception_3a_1x1'))(self.feed('pool2_3x3_s2').conv(1, 1, 96, 1, 1, name='inception_3a_3x3_reduce').conv(3, 3, 128, 1, 1, name='inception_3a_3x3'))(self.feed('pool2_3x3_s2').conv(1, 1, 16, 1, 1, name='inception_3a_5x5_reduce').conv(5, 5, 32, 1, 1, name='inception_3a_5x5'))(self.feed('pool2_3x3_s2').max_pool(3, 3, 1, 1, name='inception_3a_pool').conv(1, 1, 32, 1, 1, name='inception_3a_pool_proj'))(self.feed('inception_3a_1x1','inception_3a_3x3','inception_3a_5x5','inception_3a_pool_proj').concat(3, name='inception_3a_output').conv(1, 1, 128, 1, 1, name='inception_3b_1x1'))(self.feed('inception_3a_output').conv(1, 1, 128, 1, 1, name='inception_3b_3x3_reduce').conv(3, 3, 192, 1, 1, name='inception_3b_3x3'))(self.feed('inception_3a_output').conv(1, 1, 32, 1, 1, name='inception_3b_5x5_reduce').conv(5, 5, 96, 1, 1, name='inception_3b_5x5'))(self.feed('inception_3a_output').max_pool(3, 3, 1, 1, name='inception_3b_pool').conv(1, 1, 64, 1, 1, name='inception_3b_pool_proj'))(self.feed('inception_3b_1x1','inception_3b_3x3','inception_3b_5x5','inception_3b_pool_proj').concat(3, name='inception_3b_output').max_pool(3, 3, 2, 2, name='pool3_3x3_s2').conv(1, 1, 192, 1, 1, name='inception_4a_1x1'))(self.feed('pool3_3x3_s2').conv(1, 1, 96, 1, 1, name='inception_4a_3x3_reduce').conv(3, 3, 208, 1, 1, name='inception_4a_3x3'))(self.feed('pool3_3x3_s2').conv(1, 1, 16, 1, 1, name='inception_4a_5x5_reduce').conv(5, 5, 48, 1, 1, name='inception_4a_5x5'))(self.feed('pool3_3x3_s2').max_pool(3, 3, 1, 1, name='inception_4a_pool').conv(1, 1, 64, 1, 1, name='inception_4a_pool_proj'))(self.feed('inception_4a_1x1','inception_4a_3x3','inception_4a_5x5','inception_4a_pool_proj').concat(3, name='inception_4a_output').conv(1, 1, 160, 1, 1, name='inception_4b_1x1'))(self.feed('inception_4a_output').conv(1, 1, 112, 1, 1, name='inception_4b_3x3_reduce').conv(3, 3, 224, 1, 1, name='inception_4b_3x3'))(self.feed('inception_4a_output').conv(1, 1, 24, 1, 1, name='inception_4b_5x5_reduce').conv(5, 5, 64, 1, 1, name='inception_4b_5x5'))(self.feed('inception_4a_output').max_pool(3, 3, 1, 1, name='inception_4b_pool').conv(1, 1, 64, 1, 1, name='inception_4b_pool_proj'))(self.feed('inception_4b_1x1','inception_4b_3x3','inception_4b_5x5','inception_4b_pool_proj').concat(3, name='inception_4b_output').conv(1, 1, 128, 1, 1, name='inception_4c_1x1'))(self.feed('inception_4b_output').conv(1, 1, 128, 1, 1, name='inception_4c_3x3_reduce').conv(3, 3, 256, 1, 1, name='inception_4c_3x3'))(self.feed('inception_4b_output').conv(1, 1, 24, 1, 1, name='inception_4c_5x5_reduce').conv(5, 5, 64, 1, 1, name='inception_4c_5x5'))(self.feed('inception_4b_output').max_pool(3, 3, 1, 1, name='inception_4c_pool').conv(1, 1, 64, 1, 1, name='inception_4c_pool_proj'))(self.feed('inception_4c_1x1','inception_4c_3x3','inception_4c_5x5','inception_4c_pool_proj').concat(3, name='inception_4c_output').conv(1, 1, 112, 1, 1, name='inception_4d_1x1'))(self.feed('inception_4c_output').conv(1, 1, 144, 1, 1, name='inception_4d_3x3_reduce').conv(3, 3, 288, 1, 1, name='inception_4d_3x3'))(self.feed('inception_4c_output').conv(1, 1, 32, 1, 1, name='inception_4d_5x5_reduce').conv(5, 5, 64, 1, 1, name='inception_4d_5x5'))(self.feed('inception_4c_output').max_pool(3, 3, 1, 1, name='inception_4d_pool').conv(1, 1, 64, 1, 1, name='inception_4d_pool_proj'))(self.feed('inception_4d_1x1','inception_4d_3x3','inception_4d_5x5','inception_4d_pool_proj').concat(3, name='inception_4d_output').conv(1, 1, 256, 1, 1, name='inception_4e_1x1'))(self.feed('inception_4d_output').conv(1, 1, 160, 1, 1, name='inception_4e_3x3_reduce').conv(3, 3, 320, 1, 1, name='inception_4e_3x3'))(self.feed('inception_4d_output').conv(1, 1, 32, 1, 1, name='inception_4e_5x5_reduce').conv(5, 5, 128, 1, 1, name='inception_4e_5x5'))(self.feed('inception_4d_output').max_pool(3, 3, 1, 1, name='inception_4e_pool').conv(1, 1, 128, 1, 1, name='inception_4e_pool_proj'))(self.feed('inception_4e_1x1','inception_4e_3x3','inception_4e_5x5','inception_4e_pool_proj').concat(3, name='inception_4e_output').max_pool(3, 3, 2, 2, name='pool4_3x3_s2').conv(1, 1, 256, 1, 1, name='inception_5a_1x1'))(self.feed('pool4_3x3_s2').conv(1, 1, 160, 1, 1, name='inception_5a_3x3_reduce').conv(3, 3, 320, 1, 1, name='inception_5a_3x3'))(self.feed('pool4_3x3_s2').conv(1, 1, 32, 1, 1, name='inception_5a_5x5_reduce').conv(5, 5, 128, 1, 1, name='inception_5a_5x5'))(self.feed('pool4_3x3_s2').max_pool(3, 3, 1, 1, name='inception_5a_pool').conv(1, 1, 128, 1, 1, name='inception_5a_pool_proj'))(self.feed('inception_5a_1x1','inception_5a_3x3','inception_5a_5x5','inception_5a_pool_proj').concat(3, name='inception_5a_output').conv(1, 1, 384, 1, 1, name='inception_5b_1x1'))(self.feed('inception_5a_output').conv(1, 1, 192, 1, 1, name='inception_5b_3x3_reduce').conv(3, 3, 384, 1, 1, name='inception_5b_3x3'))(self.feed('inception_5a_output').conv(1, 1, 48, 1, 1, name='inception_5b_5x5_reduce').conv(5, 5, 128, 1, 1, name='inception_5b_5x5'))(self.feed('inception_5a_output').max_pool(3, 3, 1, 1, name='inception_5b_pool').conv(1, 1, 128, 1, 1, name='inception_5b_pool_proj'))(self.feed('inception_5b_1x1','inception_5b_3x3','inception_5b_5x5','inception_5b_pool_proj').concat(3, name='inception_5b_output').avg_pool(7, 7, 1, 1, padding='VALID', name='pool5_7x7_s1').fc(1000, relu=False, name='loss3_classifier').softmax(name='prob'))
代码在GitHub - ethereon/caffe-tensorflow: Caffe models in TensorFlow中,作者封装了一些基本的操作,了解网络结构之后,构造 GoogLeNet 很容易。之后等到新公司之后,我会试着在 tflearn 的基础上写下 GoogLeNet 的网络代码。
GoogLeNet on Tensorflow
GoogLeNet 为了实现方便,我用 tflearn 来重写了下,代码中和 caffe model 里面不一样的就是一些 padding 的位置,因为改的比较麻烦,必须保持 inception 部分的 concat 时要一致,我这里也不知道怎么修改 pad 的值(caffe prototxt),所以统一 padding 设定为 same,具体代码如下:
# -*- coding: utf-8 -*-""" GoogLeNet.Applying 'GoogLeNet' to Oxford's 17 Category Flower Dataset classification task.References:- Szegedy, Christian, et al.Going deeper with convolutions.- 17 Category Flower Dataset. Maria-Elena Nilsback and Andrew Zisserman.Links:- [GoogLeNet Paper](http://www.cv-foundation.org/openaccess/content_cvpr_2015/papers/Szegedy_Going_Deeper_With_2015_CVPR_paper.pdf)- [Flower Dataset (17)](http://www.robots.ox.ac.uk/~vgg/data/flowers/17/)"""from __future__ import division, print_function, absolute_importimport tflearnfrom tflearn.layers.core import input_data, dropout, fully_connectedfrom tflearn.layers.conv import conv_2d, max_pool_2d, avg_pool_2dfrom tflearn.layers.normalization import local_response_normalizationfrom tflearn.layers.merge_ops import mergefrom tflearn.layers.estimator import regressionimport tflearn.datasets.oxflower17 as oxflower17X, Y = oxflower17.load_data(one_hot=True, resize_pics=(227, 227))network = input_data(shape=[None, 227, 227, 3])conv1_7_7 = conv_2d(network, 64, 7, strides=2, activation='relu', name = 'conv1_7_7_s2')pool1_3_3 = max_pool_2d(conv1_7_7, 3,strides=2)pool1_3_3 = local_response_normalization(pool1_3_3)conv2_3_3_reduce = conv_2d(pool1_3_3, 64,1, activation='relu',name = 'conv2_3_3_reduce')conv2_3_3 = conv_2d(conv2_3_3_reduce, 192,3, activation='relu', name='conv2_3_3')conv2_3_3 = local_response_normalization(conv2_3_3)pool2_3_3 = max_pool_2d(conv2_3_3, kernel_size=3, strides=2, name='pool2_3_3_s2')inception_3a_1_1 = conv_2d(pool2_3_3, 64, 1, activation='relu', name='inception_3a_1_1')inception_3a_3_3_reduce = conv_2d(pool2_3_3, 96,1, activation='relu', name='inception_3a_3_3_reduce')inception_3a_3_3 = conv_2d(inception_3a_3_3_reduce, 128,filter_size=3, activation='relu', name = 'inception_3a_3_3')inception_3a_5_5_reduce = conv_2d(pool2_3_3,16, filter_size=1,activation='relu', name ='inception_3a_5_5_reduce' )inception_3a_5_5 = conv_2d(inception_3a_5_5_reduce, 32, filter_size=5, activation='relu', name= 'inception_3a_5_5')inception_3a_pool = max_pool_2d(pool2_3_3, kernel_size=3, strides=1, )inception_3a_pool_1_1 = conv_2d(inception_3a_pool, 32, filter_size=1, activation='relu', name='inception_3a_pool_1_1')# merge the inception_3a__inception_3a_output = merge([inception_3a_1_1, inception_3a_3_3, inception_3a_5_5, inception_3a_pool_1_1], mode='concat', axis=3)inception_3b_1_1 = conv_2d(inception_3a_output, 128,filter_size=1,activation='relu', name= 'inception_3b_1_1' )inception_3b_3_3_reduce = conv_2d(inception_3a_output, 128, filter_size=1, activation='relu', name='inception_3b_3_3_reduce')inception_3b_3_3 = conv_2d(inception_3b_3_3_reduce, 192, filter_size=3, activation='relu',name='inception_3b_3_3')inception_3b_5_5_reduce = conv_2d(inception_3a_output, 32, filter_size=1, activation='relu', name = 'inception_3b_5_5_reduce')inception_3b_5_5 = conv_2d(inception_3b_5_5_reduce, 96, filter_size=5, name = 'inception_3b_5_5')inception_3b_pool = max_pool_2d(inception_3a_output, kernel_size=3, strides=1, name='inception_3b_pool')inception_3b_pool_1_1 = conv_2d(inception_3b_pool, 64, filter_size=1,activation='relu', name='inception_3b_pool_1_1')#merge the inception_3b_*inception_3b_output = merge([inception_3b_1_1, inception_3b_3_3, inception_3b_5_5, inception_3b_pool_1_1], mode='concat',axis=3,name='inception_3b_output')pool3_3_3 = max_pool_2d(inception_3b_output, kernel_size=3, strides=2, name='pool3_3_3')inception_4a_1_1 = conv_2d(pool3_3_3, 192, filter_size=1, activation='relu', name='inception_4a_1_1')inception_4a_3_3_reduce = conv_2d(pool3_3_3, 96, filter_size=1, activation='relu', name='inception_4a_3_3_reduce')inception_4a_3_3 = conv_2d(inception_4a_3_3_reduce, 208, filter_size=3, activation='relu', name='inception_4a_3_3')inception_4a_5_5_reduce = conv_2d(pool3_3_3, 16, filter_size=1, activation='relu', name='inception_4a_5_5_reduce')inception_4a_5_5 = conv_2d(inception_4a_5_5_reduce, 48, filter_size=5, activation='relu', name='inception_4a_5_5')inception_4a_pool = max_pool_2d(pool3_3_3, kernel_size=3, strides=1, name='inception_4a_pool')inception_4a_pool_1_1 = conv_2d(inception_4a_pool, 64, filter_size=1, activation='relu', name='inception_4a_pool_1_1')inception_4a_output = merge([inception_4a_1_1, inception_4a_3_3, inception_4a_5_5, inception_4a_pool_1_1], mode='concat', axis=3, name='inception_4a_output')inception_4b_1_1 = conv_2d(inception_4a_output, 160, filter_size=1, activation='relu', name='inception_4a_1_1')inception_4b_3_3_reduce = conv_2d(inception_4a_output, 112, filter_size=1, activation='relu', name='inception_4b_3_3_reduce')inception_4b_3_3 = conv_2d(inception_4b_3_3_reduce, 224, filter_size=3, activation='relu', name='inception_4b_3_3')inception_4b_5_5_reduce = conv_2d(inception_4a_output, 24, filter_size=1, activation='relu', name='inception_4b_5_5_reduce')inception_4b_5_5 = conv_2d(inception_4b_5_5_reduce, 64, filter_size=5, activation='relu', name='inception_4b_5_5')inception_4b_pool = max_pool_2d(inception_4a_output, kernel_size=3, strides=1, name='inception_4b_pool')inception_4b_pool_1_1 = conv_2d(inception_4b_pool, 64, filter_size=1, activation='relu', name='inception_4b_pool_1_1')inception_4b_output = merge([inception_4b_1_1, inception_4b_3_3, inception_4b_5_5, inception_4b_pool_1_1], mode='concat', axis=3, name='inception_4b_output')inception_4c_1_1 = conv_2d(inception_4b_output, 128, filter_size=1, activation='relu',name='inception_4c_1_1')inception_4c_3_3_reduce = conv_2d(inception_4b_output, 128, filter_size=1, activation='relu', name='inception_4c_3_3_reduce')inception_4c_3_3 = conv_2d(inception_4c_3_3_reduce, 256, filter_size=3, activation='relu', name='inception_4c_3_3')inception_4c_5_5_reduce = conv_2d(inception_4b_output, 24, filter_size=1, activation='relu', name='inception_4c_5_5_reduce')inception_4c_5_5 = conv_2d(inception_4c_5_5_reduce, 64, filter_size=5, activation='relu', name='inception_4c_5_5')inception_4c_pool = max_pool_2d(inception_4b_output, kernel_size=3, strides=1)inception_4c_pool_1_1 = conv_2d(inception_4c_pool, 64, filter_size=1, activation='relu', name='inception_4c_pool_1_1')inception_4c_output = merge([inception_4c_1_1, inception_4c_3_3, inception_4c_5_5, inception_4c_pool_1_1], mode='concat', axis=3,name='inception_4c_output')inception_4d_1_1 = conv_2d(inception_4c_output, 112, filter_size=1, activation='relu', name='inception_4d_1_1')inception_4d_3_3_reduce = conv_2d(inception_4c_output, 144, filter_size=1, activation='relu', name='inception_4d_3_3_reduce')inception_4d_3_3 = conv_2d(inception_4d_3_3_reduce, 288, filter_size=3, activation='relu', name='inception_4d_3_3')inception_4d_5_5_reduce = conv_2d(inception_4c_output, 32, filter_size=1, activation='relu', name='inception_4d_5_5_reduce')inception_4d_5_5 = conv_2d(inception_4d_5_5_reduce, 64, filter_size=5, activation='relu', name='inception_4d_5_5')inception_4d_pool = max_pool_2d(inception_4c_output, kernel_size=3, strides=1, name='inception_4d_pool')inception_4d_pool_1_1 = conv_2d(inception_4d_pool, 64, filter_size=1, activation='relu', name='inception_4d_pool_1_1')inception_4d_output = merge([inception_4d_1_1, inception_4d_3_3, inception_4d_5_5, inception_4d_pool_1_1], mode='concat', axis=3, name='inception_4d_output')inception_4e_1_1 = conv_2d(inception_4d_output, 256, filter_size=1, activation='relu', name='inception_4e_1_1')inception_4e_3_3_reduce = conv_2d(inception_4d_output, 160, filter_size=1, activation='relu', name='inception_4e_3_3_reduce')inception_4e_3_3 = conv_2d(inception_4e_3_3_reduce, 320, filter_size=3, activation='relu', name='inception_4e_3_3')inception_4e_5_5_reduce = conv_2d(inception_4d_output, 32, filter_size=1, activation='relu', name='inception_4e_5_5_reduce')inception_4e_5_5 = conv_2d(inception_4e_5_5_reduce, 128, filter_size=5, activation='relu', name='inception_4e_5_5')inception_4e_pool = max_pool_2d(inception_4d_output, kernel_size=3, strides=1, name='inception_4e_pool')inception_4e_pool_1_1 = conv_2d(inception_4e_pool, 128, filter_size=1, activation='relu', name='inception_4e_pool_1_1')inception_4e_output = merge([inception_4e_1_1, inception_4e_3_3, inception_4e_5_5,inception_4e_pool_1_1],axis=3, mode='concat')pool4_3_3 = max_pool_2d(inception_4e_output, kernel_size=3, strides=2, name='pool_3_3')inception_5a_1_1 = conv_2d(pool4_3_3, 256, filter_size=1, activation='relu', name='inception_5a_1_1')inception_5a_3_3_reduce = conv_2d(pool4_3_3, 160, filter_size=1, activation='relu', name='inception_5a_3_3_reduce')inception_5a_3_3 = conv_2d(inception_5a_3_3_reduce, 320, filter_size=3, activation='relu', name='inception_5a_3_3')inception_5a_5_5_reduce = conv_2d(pool4_3_3, 32, filter_size=1, activation='relu', name='inception_5a_5_5_reduce')inception_5a_5_5 = conv_2d(inception_5a_5_5_reduce, 128, filter_size=5, activation='relu', name='inception_5a_5_5')inception_5a_pool = max_pool_2d(pool4_3_3, kernel_size=3, strides=1, name='inception_5a_pool')inception_5a_pool_1_1 = conv_2d(inception_5a_pool, 128, filter_size=1,activation='relu', name='inception_5a_pool_1_1')inception_5a_output = merge([inception_5a_1_1, inception_5a_3_3, inception_5a_5_5, inception_5a_pool_1_1], axis=3,mode='concat')inception_5b_1_1 = conv_2d(inception_5a_output, 384, filter_size=1,activation='relu', name='inception_5b_1_1')inception_5b_3_3_reduce = conv_2d(inception_5a_output, 192, filter_size=1, activation='relu', name='inception_5b_3_3_reduce')inception_5b_3_3 = conv_2d(inception_5b_3_3_reduce, 384, filter_size=3,activation='relu', name='inception_5b_3_3')inception_5b_5_5_reduce = conv_2d(inception_5a_output, 48, filter_size=1, activation='relu', name='inception_5b_5_5_reduce')inception_5b_5_5 = conv_2d(inception_5b_5_5_reduce,128, filter_size=5, activation='relu', name='inception_5b_5_5' )inception_5b_pool = max_pool_2d(inception_5a_output, kernel_size=3, strides=1, name='inception_5b_pool')inception_5b_pool_1_1 = conv_2d(inception_5b_pool, 128, filter_size=1, activation='relu', name='inception_5b_pool_1_1')inception_5b_output = merge([inception_5b_1_1, inception_5b_3_3, inception_5b_5_5, inception_5b_pool_1_1], axis=3, mode='concat')pool5_7_7 = avg_pool_2d(inception_5b_output, kernel_size=7, strides=1)pool5_7_7 = dropout(pool5_7_7, 0.4)loss = fully_connected(pool5_7_7, 17,activation='softmax')network = regression(loss, optimizer='momentum',loss='categorical_crossentropy',learning_rate=0.001)model = tflearn.DNN(network, checkpoint_path='model_googlenet',max_checkpoints=1, tensorboard_verbose=2)model.fit(X, Y, n_epoch=1000, validation_set=0.1, shuffle=True,show_metric=True, batch_size=64, snapshot_step=200,snapshot_epoch=False, run_id='googlenet_oxflowers17')
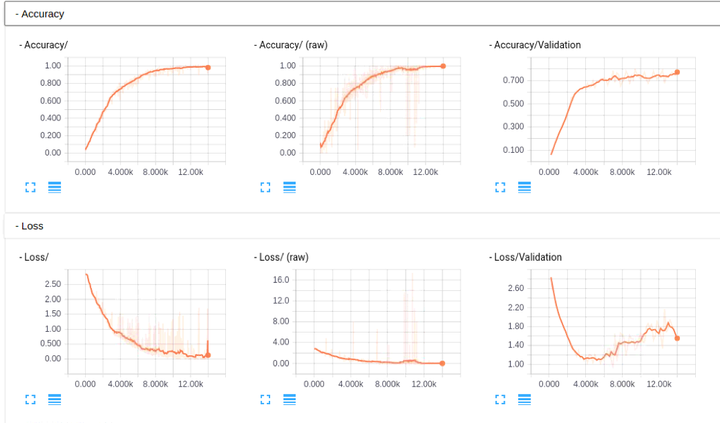
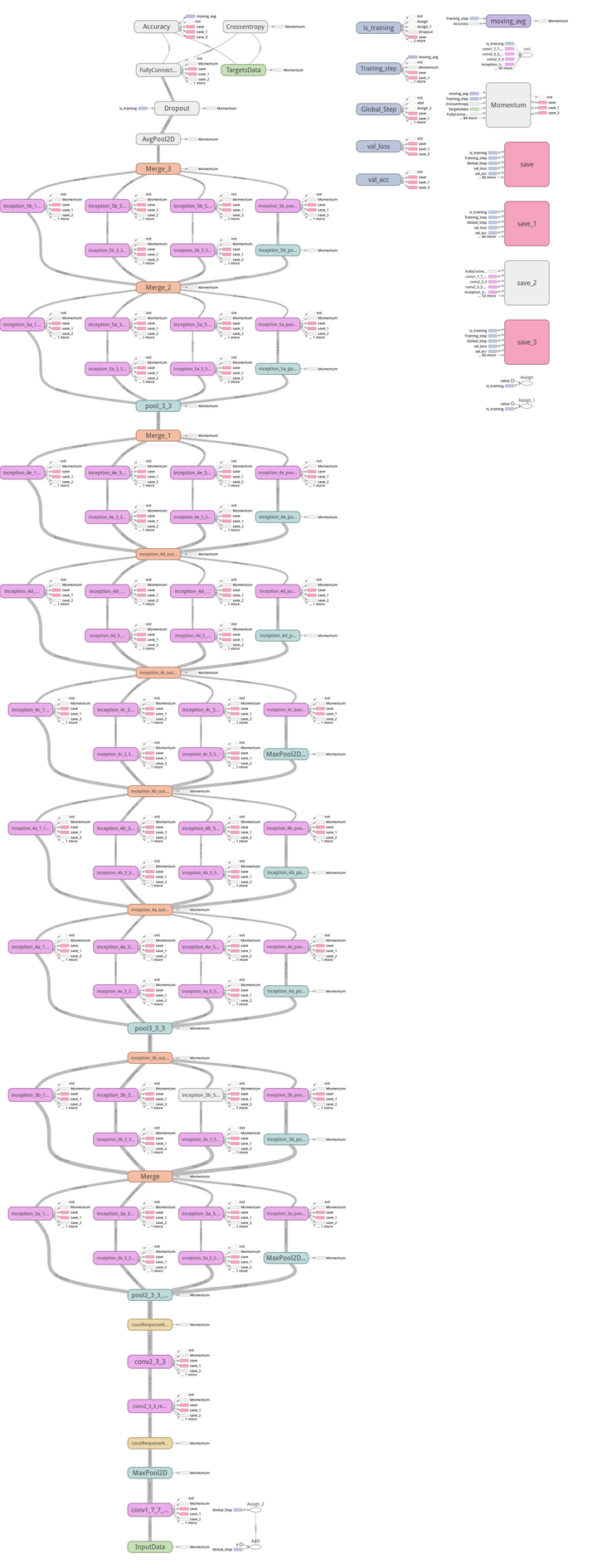
大家如果感兴趣,可以看看这部分的 caffe model prototxt, 帮忙检查下是否有问题,代码我已经提交到 tflearn 的官方库了,add GoogLeNet(Inception) in Example,各位有 tensorflow 的直接安装下 tflearn,看看是否能帮忙检查下是否有问题,我这里因为没有 GPU 的机器,跑的比较慢,TensorBoard 的图如下,不像之前 Alexnet 那么明显(主要还是没有跑那么多 epoch, 这里在写入的时候发现主机上没有磁盘空间了,尴尬,然后从新写了 restore 来跑的,TensorBoard 的图也貌似除了点问题, 好像每次载入都不太一样,但是从基本的 log 里面的东西来看,是逐步在收敛的,这里图也贴下看看吧)
网络结构,也无法从 TensorBoard 上直接 download 下来,我这里就一步步自己截的图 (勉强看看吧),好傻:
为了方便,这里也贴出一些我自己保存的运行的 log,能够很明显的看出收敛:


相关阅读推荐:
机器学习进阶笔记之二 | 深入理解 Neural Style
本文由『UCloud 内核与虚拟化研发团队』提供。
关于作者:
Burness( ), UCloud 平台研发中心深度学习研发工程师,tflearn Contributor,做过电商推荐、精准化营销相关算法工作,专注于分布式深度学习框架、计算机视觉算法研究,平时喜欢玩玩算法,研究研究开源的项目,偶尔也会去一些数据比赛打打酱油,生活中是个极客,对新技术、新技能痴迷。
你可以在 Github 上找到他:http://hacker.duanshishi.com/
「UCloud 机构号」将独家分享云计算领域的技术洞见、行业资讯以及一切你想知道的相关讯息。
欢迎提问 & 求关注 o(////▽////)q~

若有收获,就点个赞吧
0 人点赞
