之前实习用过太多次 mobilenet_ssd,但是一直只是用,没有去了解它的原理。今日参考了一位大神的博客,写得很详细,也很容易懂,这里做一个自己的整理,供自己理解,也欢迎大家讨论。
先整理 MobileNet
这里奉上大神的博客地址:https://blog.csdn.net/u013082989/article/details/77970196
论文地址:MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
caffe 版 mobilenet:Caffe Implementation of Google’s MobileNets (v1 and v2)
1:mobilenet 主要是为了适用于移动端而提出的一种轻量级深度网络模型。主要使用了深度可分离卷积 Depthwise Separable Convolution 将标准卷积核进行分解计算,减少了计算量
2:引入了两个超参数来减少参数量和计算量
- 宽度乘数(Width Multiplier):减少输入输出的 channels
- 分辨率乘数(Resolution Multiplier):减少输入输出的 feature map 的大小
3:深度可分离卷积是将一个标准的卷积核分成深度卷积核和 1x1 的点卷积核,假设输入为 M 个通道的 feature map,卷积核大小为 DK∗DK,输出通道为 N,那么标准卷积核即为 M∗DK∗DK∗N。例如,输入 feature map 为 m∗n∗16,想输出 32 通道,那么卷积核应为 16∗3∗3∗32,则可以分解为深度卷积:16∗3∗3 得到的是 16 通道的特征图谱。点卷积为 16∗1∗1∗32,如果用标准卷积,则计算量为:m∗n∗16∗3∗3∗32\=m∗n∗4608。用深度可分解卷积之后的计算量为 m∗n∗16∗3∗3+m∗n∗16∗1∗1∗32\=m∗n∗656
4:所以和标准卷积核相比计算量比率为:Dk∗Dk∗Df∗Df∗M+Df∗Df∗M∗NDk∗Dk∗M∗N∗Df∗Df\=1N+1Dk2
5:深度可分解卷积操作示意图如下:
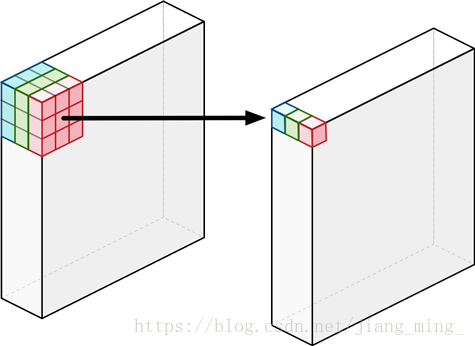
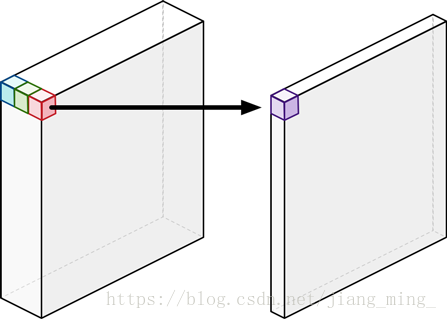
6:mobilenet 共 28 层(深度卷积和点卷积单独算一层),每层后边都跟有 batchnorm 层 和 relu 层
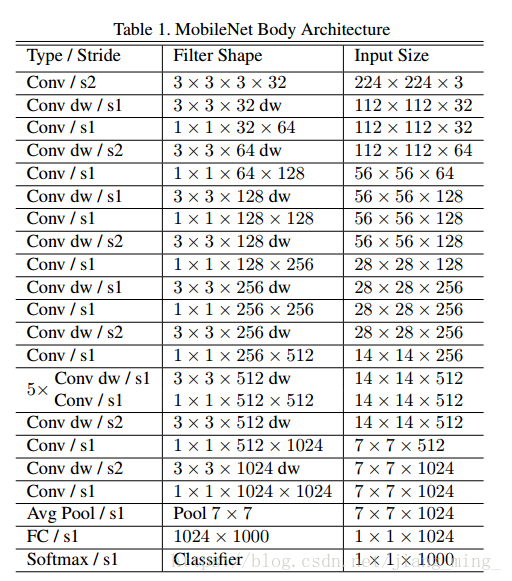

7:引入宽度乘数和分辨率乘数两个超参数,
宽度乘数α主要用于减少 channels, 即即输入层的 channels 个数 M,变成αM,输出层的 channels 个数 N 变成了αN
所以引入宽度乘数后的总的计算量是:Dk⋅Dk⋅αM⋅DF⋅DF+αM⋅αN⋅DF⋅DF
分辨率乘数ρ主要用于降低图片的分辨率,即作用在 feature map 上
所以引入分辨率乘数后的总的计算量为:Dk⋅Dk⋅αM⋅ρDF⋅ρDF+αM⋅αN⋅ρDF⋅ρDF
在看看 MobileNet_ssd
mobilenet_ssd caffe 模型可视化地址:MobileNet_ssd
可以看出,conv13 是骨干网络的最后一层,作者仿照 VGG-SSD 的结构,在 Mobilenet 的 conv13 后面添加了 8 个卷积层,然后总共抽取 6 层用作检测,貌似没有使用分辨率为 3838 的层,可能是位置太靠前了吧。
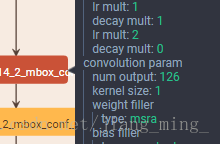
提取默认框的 6 层为 conv11, conv13, conv14_2, conv15_2, conv16_2, conv17_2, 该 6 层 feature map 每个 cell 产生的默认框个数分别为 3,6,6,6,6,6。也就是说在那 6 层的后边接的用于坐标回归的 33 的卷积核(层名为 conv11_mbox_loc……)的输出个数(num output)分别为 12,24,24,24,24,24,24。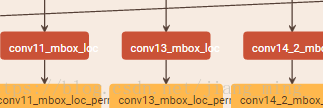
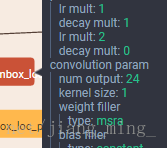
那 6 层后边接的用于类别得分的 33 卷积核(层名为 conv11_mbox_conf……)的输出个数为 321(类别为 21 类,3 个默认框) = 63,126, 126, 126, 126, 126。
https://blog.csdn.net/jiangming/article/details/82356642

若有收获,就点个赞吧
0 人点赞
