论文题目《Anytime Stereo Image Depth Estimation on Mobile Devices》,19 年的论文,被 ICRA 接收,稍微看了一下,是机器人领域那边还不错的会议。代码已开源。这篇文章主要关注的是算法的实时性和准确性,根据不同的要求,可以有不同的结果。当然,速度越快的,误差就越大,这就是 any 的含义。
这篇论文主要想分享作者关于残差的处理。在立体匹配这边,很多有关调优的工作会从重建出发,比如我现在有一张粗略的视差结果,用这个视差图可以进行对左图进行重建得到右图,重建的右图与本来的右图对比会得到一个残差。本文也是这样的想法,不过是从 cost volume 出发,感觉很巧妙。
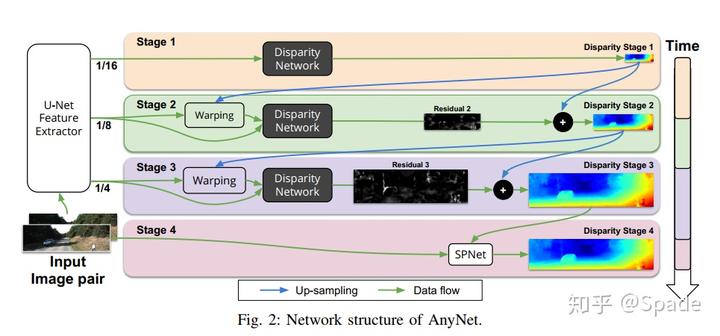
在特征提取部分,会有多尺度的特征(用于不同分辨率的输出,分辨率越低速度越快,对应 any)。在最低的分辨率 1/16(图中 stage 1),cost volume 中视差的范围是 0~D/16(D 为可能的最大视差值),然后用 3D 卷积,回归得到视差图。
如允许更久的时间或更准确结果的需要,进入 stage 2。分辨率 1/16 的视差图上采样至 1/8,配合特征提取器中 1/8 分辨率的左右特征使用。利用视差对右图特征重建得到左图特征,重建的左图特征与左图特征形成一个调优 cost volume。在正常左右特征 cost volume 中,视差这个维度是表示视差,现在右特征变成了重建的左特征,理论上来讲,如果重建完全正确,那么视差这个维度应该都是 0 是最佳的视差值。因此,对于重建特征与原特征组成的 cost volume,视差的范围变成了 - 2~2。这样的 cost volume 经过 3D 卷积输出的是一个残差图,范围就是 - 2~2,也就是我们认为对 stage 1 粗略视差调整的范围。如果视差值正确,那么这个位置在 stage 2 输出的残差值就是 0,如果不正确,就学习调整。
其他就没什么特殊要讲的了,关于左右特征的 cost volume 和重建特征 + 特征的 cost volume 输出视差和残差的原理如果还有什么疑问推荐看一下作者的论文或者代码哈。
https://zhuanlan.zhihu.com/p/85827513

若有收获,就点个赞吧
0 人点赞
