HTTP 中的 hex
在很多关于 HTTP 的内容解析的场景,数据的展示都是采用 16进制 的表示形式,跟猜测的情况类似,首先二进制转十六进制十分容易(所以一个二进制的数要转为十进制,可以先转为十六进制,再转十进制),且由于是 ascii 基本单位的 2倍数,能够更好地表示出数据,利于阅读及存储。
二进制与十六进制互转: 由于 1111 才4位,所以我们必须直接记住它每一位的权值,并且是从高位往低位记,:8、4、2、1。即,最高位的权值为2 = 8,然后依次是 2 = 4,=2, 2 = 1。
1234 转为 二进制如下: 比如,十进制数 1234转换成二制数,如果要一直除以2,直接得到2进制数,需要计算较多次数。所以我们可以先除以16,得到16进制数:


| 被除数 | 计算过程 | 商 | 余数 |
|---|---|---|---|
| 1234 | 1234/16 | 77 | 2 |
| 77 | 77/16 | 4 | 13 (D) |
| 4 | 4/16 | 0 | 4 |
所以经过两次除16,不可再除,用余数表示 十六进制 则为:0x4D2 然后我们可直接写出0x4D2的二进制形式:0100 1101 0010。 其中对映关系为: 0100 — 4 1101 — D 0010 — 2
十六进制:hex(hexadecimal)
16进制:用16作为基数的计数系统。用数字0-9和字母a-f(或其大写A-F)表示0到15。
为什么用16进制
- 计算机硬件是0101二进制的,16进制刚好是2的倍数,更容易表达一个命令或者数据
- 最早规定ASCII字符集采用的就是8bit(后期扩展了,但是基础单位还是8bit), 8bit用2个16进制直接就能表达出来,不管阅读还是存储都比其他进制要方便
- 计算机中CPU运算也是遵照ASCII字符集,以16、32、64的这样的方式在发展,因此数据交换的时候16进制也显得更好
- 为了统一规范,CPU、内存、硬盘我们看到都是采用的16进制计算
换行符:0d0a(\r\n)
基本字符使用 ascii 码表示,\r\n 也有自己的十进制码位,所以 \r\n 就是 013 010,转化成 hex 就是 0d0a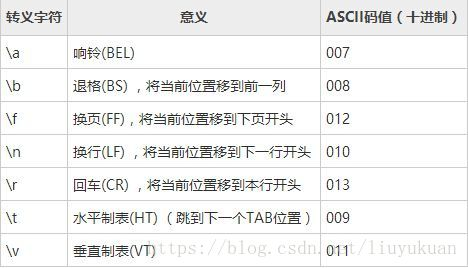
0xff -> 1111 1111 -> 255
这是个经常看到的数字,255,十六进制为 0xff(0x表示这是个十六进制数),按照上面的转化过程可以得到 十六进制 计算为十进制的过程:15 16 + 15 = 255,而它的二进制则是 1111 1111 也就是 (8 + 2 + 4 + 1)222*2 +(8 + 4 + 2 + 1)。
0xff 表示的二进制 1111 1111 占一个字节(8 bit, 1 byte)。
URI
URI 的转义规则也是采用十六进制,通过直接将 ASCII 或 特殊字符(中、日文这种,转为十六进制,需要编码规则) 转换成 十六进制字节值,也就是类似 %FF%FF%FF 这样的结构,%为分隔符,FF为1个字节的十六进制,如”银河”,”%E9%93%B6%E6%B2%B3”
用百度测试下:

所以如果存在特殊字符,在读取这段十六进制时,还需要先进行类似 UTF-8 这样的编码转义。所以像百度,需要提供ie=UTF-8。
所以可以得出结论由于十六进制,在数据表示的场景下比较优秀,长度不太长,结构又规整。所以经常出现在 数据即将进入传输层,需要展示给使用者查看的场景。所以很多时候我们都看到十六进制数而不是二进制或十进制的原因就在此。不是十进制:因为传输的内容不仅仅是数字。
不是二进制:展示起来太长。
十六进制:不长,两位1Byte,展示效果优秀。

若有收获,就点个赞吧
0 人点赞
