大多数最先进的3D对象检测器都严重依赖LiDAR传感器,并且由于在3D场景中对预测的不适当表示,导致基于图像的方法与基于LiDAR的方法之间在性能方面仍存在很大差距。我们的方法称为深度立体几何网络(DSGN),它通过在可区分的体积表示形式(3D几何体)上检测3D对象来显着减小此差距,该方法可有效地为3D规则空间编码3D几何结构。通过这种表示,我们可以同时学习深度信息和语义提示。我们首次提供了一种简单有效的基于立体声的单阶段3D检测管道,该管道可以以端到端的学习方式联合估算深度并检测3D对象。我们的方法优于以前的基于立体声的3D检测器(在AP方面要高出约10个),甚至可以在KITTI 3D对象检测排行榜上用几种基于LiDAR的方法达到可比的性能。代码将在https://github.com/chenyilun95/DSGN上公开提供。
1. Introduction
3D场景理解是3D感知中的一项艰巨任务,它是自动驾驶和机器人技术的基本组成部分。 由于LiDAR传感器能够准确地检索3D信息,因此我们见证了3D对象检测的快速发展。 提出了各种3D对象检测器[9,23,58,26,27,33,39,52,54]以利用LiDAR点云表示。 LiDAR的局限性在于具有几个激光束的数据的相对稀疏分辨率以及设备的高昂价格。
相比之下,摄像机更便宜且分辨率更高。 计算立体图像上景深的方法是通过立体对应估计来考虑视差。 尽管最近有几种基于单眼[36、7、6、30、48]或立体声[25、45、37、56]设置的3D检测器推动了基于图像的3D对象检测的极限,但准确性仍然远远落后 与基于LiDAR的方法相比。
Challenges 基于图像的方法面临的最大挑战之一是为预测3D对象提供适当而有效的表示方法。 最近的工作[25、36、48、37、40、2]将该任务分为两个子任务,即深度预测和目标检测。 相机投影是将3D世界映射为2D图像的过程。 不同对象姿势中的一个3D功能会导致局部外观变化,从而使2D网络难以提取稳定的3D信息。
解决方案的另一行[45、56、47、30]生成中间点云,然后是基于LiDAR的3D对象检测器。 由于转换是不可微的,并且合并了几个独立的网络,因此这种3D表示效果较差。 此外,点云还面临物体伪影[18、47、56]的挑战,这限制了后续3D物体检测器的检测精度。
Our Solution 在本文中,我们提出了一种基于立体声的端到端3D对象检测管道(图1)–深度立体几何网络(DSGN),它依赖于从2D特征到有效3D结构的空间转换,称为3D几何体 (3DGV)。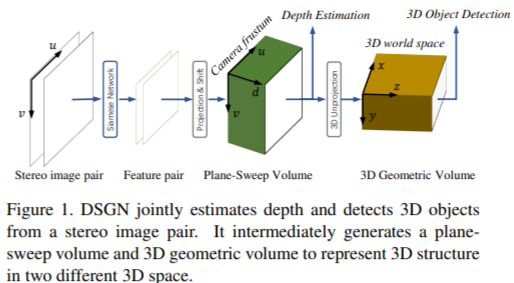
3DGV背后的见解在于构建可对3D几何进行编码的3D体积的方法。 3D几何体是在3D世界空间中定义的,是从在视锥中构造的平面扫描体(PSV)[10,11]转换而成的。 在PSV中可以很好地学习像素对应约束,而在3DGV中可以学习现实世界对象的3D特征。 音量结构完全可以区分,因此可以联合优化以学习立体匹配和目标检测。
这种体积表示具有两个关键优势。 首先,很容易施加像素对应约束并将完整的深度信息编码为3D实际体积。 其次,它为3D表示提供了几何信息,从而可以学习现实世界对象的3D几何特征。 据我们所知,还没有研究明确研究将3D几何编码到基于图像的检测网络中的方法。 我们的贡献总结如下:
- 为了弥合2D图像和3D空间之间的差距,我们在平面扫描体积中建立立体对应关系,然后将其转换为3D几何体积,以便能够对3D几何形状和语义提示进行编码,以便在3D规则空间中进行预测。
- 我们设计了一个端到端流水线,用于提取用于立体匹配的像素级特征和用于对象识别的高级特征。 拟议的网络共同估算场景深度并检测3D世界中的3D对象,从而实现许多实际应用。
- 不用花哨,我们的简单且完全可区分的网络在官方的KITTI排行榜上胜过所有其他基于立体的3D对象检测器(AP高10点)[13]。
2. Related Work
我们简要回顾一下立体声匹配和多视图立体声的最新工作。 然后,我们调查基于LiDAR,单眼图像和立体图像的3D对象检测。
Stereo Matching 在双目图像的立体匹配领域,[21、4、57、14、43、46]的方法通过暹罗网络处理左右图像,并构造3D成本量以计算匹配成本。 在最近的工作中应用了基于相关性的成本量[31、55、51、14、28、42]。 GC-Net [21]形成了基于串联的成本量,并将3D卷积应用于回归差异估计。 最近的PSMNet [4]通过引入金字塔池模块和堆叠沙漏模块[32]进一步提高了准确性。 在KITTI 2015立体声基准测试中,最先进的方法已经实现了不到2%的3像素误差。
Multi-View Stereo [5、53、19、20、17、16]的方法在多视图立体设置[1,3]中重建3D对象。 MVSNet [53]在镜头平截头体上构造平面扫描体积,以生成每个视图的深度图。 相反,Point-MVSNet [5]将平面扫描体积中间转换为点云表示形式以节省计算量。 Kar等。 [20]提出了在多视图图像上的可微分投影和非投影操作。
Image-based 3D Detection 检测的另一条线是基于图像。 不管基于单眼或立体的设置,方法都可以根据中间表示的存在分为两种类型。
3D detector with depth predictor: 该解决方案依赖于2D图像检测器以及从单眼或立体图像中提取深度信息。 Stereo R-CNNStereo [25]将3D检测公式化为多个分支/阶段,以明确解决多个约束。 我们注意到,关键点约束可能难以推广到其他类别,例如行人,并且直接操作原始RGB图像的立体声匹配的密集对齐方式可能易于遮挡。
3D representation based 3D Detector:_ _3DOPStereo [7,8]通过立体声生成点云,并在能量函数中编码先验知识和深度。 几种方法[45、56、47、30]中间将深度图转换为PseudoLiDAR(点云),然后再转换为另一个独立网络。 与以前的方法相比,该管道产生了很大的改进。 OFT-NetMono [38]将图像特征映射到正射鸟瞰图表示中,并在鸟瞰图上检测3D对象。
3. Our Approach
在本节中,我们首先探索3D空间的正确表示方式,并激发我们的网络设计。 基于讨论,我们提出了在双目图像对设置下的完整3D检测管道。
3.1. Motivation
由于透视的原因,对象随着距离的增加而显得更小,这使得可以根据对象大小和上下文的相对比例来粗略估计深度。 但是,相同类别的3D对象可能仍具有各种大小和方向。这增加了做出正确预测的难度。
此外,透视的视觉效果导致附近的3D对象在图像中的缩放比例不均匀。 普通的长方体汽车看起来像不规则的平截头体。 这两个问题对2D神经网络建模2D成像和真实3D对象之间的关系提出了重大挑战[25]。 因此,通过依赖于反转投影过程,而不是依靠2D表示,中间3D表示为理解3D对象提供了一种更有希望的方式。 以下两个表示形式通常可以在3D世界中使用。
Point-based Representation 当前最先进的管线[45、56、30]通过深度预测方法[12、4、21]生成点云的中间3D结构,并应用基于LiDAR的3D对象检测器。 可能的主要缺点是,它涉及多个独立的网络,并且在中间转换过程中可能会丢失信息,从而使3D结构(例如成本量)简化为点云。这种表示经常在物体边缘附近遇到条纹伪影[18、47、56]。 此外,对于多对象场景,很难区分网络[5,54]。
Voxel-based Representation 作为3D表示的另一种方法,体积表示的研究较少。 OFT-Netmono [38]直接将图像特征映射到3D体素网格,然后在鸟瞰视图中将其折叠到特征。 但是,此转换保留该视图的2D表示,并且未明确编码数据的3D几何形状。
Our Advantage 建立有效3D表示的关键取决于对3D空间的准确3D几何信息进行编码的能力。 立体相机为计算深度提供了显式的像素对应约束。 为了设计一个统一的网络来利用这一约束,我们探索了能够提取立体对应的像素级特征和语义线索的高级特征的深层架构。
另一方面,假设沿着穿过每个像素的投影射线施加像素对应约束,在该像素中深度被确定为确定的。 为此,我们从双目图像对创建一个中间的平面扫掠体,以学习相机视锥中的立体对应约束,然后将其转换为3D空间中的3D体。 在具有从平面扫描体中提起的3D几何信息的3D体中,我们能够很好地学习现实对象的3D特征。
3.2. Deep Stereo Geometry Network
在本小节中,我们描述了总体流程-深度立体几何网络(DSGN),如图2所示。以双目图像对(IL,IR)的输入,我们通过连体网络提取特征并构建平面扫描 音量(PSV)。 在该体积上学习像素对应。 通过微分变形,我们将PSV转换为3D几何体(3DGV),以在3D世界空间中建立3D几何体。 然后,有关3D体的以下3D神经网络将学习3D对象检测的必要结构。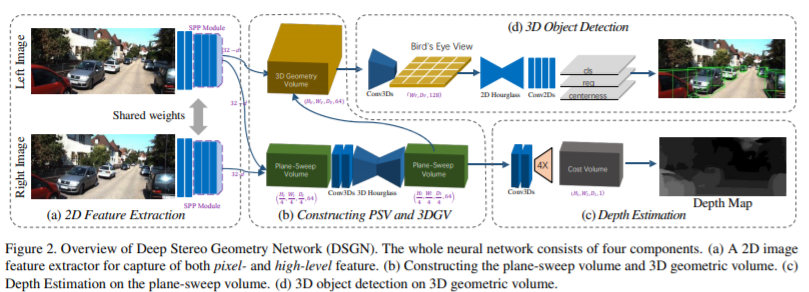
3.2.1 Image Feature Extraction
用于立体声匹配[21、4、14]和对象识别[15、41]的网络针对其各自的任务具有不同的体系结构设计。 为了确保立体声匹配的合理准确性,我们采用PSMNet的主要设计[4]。
由于检测网络需要基于高级语义特征和大量上下文信息的区分特征,因此我们修改网络以获取更多高级信息。 此外,以下用于成本汇总的3D CNN需要更多的计算,这为我们提供了修改2D特征提取器的空间,而不会在整个网络中引入额外的繁重计算开销。
Network Architecture Details
3.2.2 Constructing 3D Geometric Volume
4. Experiments
Datasets 我们的方法在流行的KITTI 3D对象检测数据集[13]上进行了评估,该数据集包含7个,481个立体图像对和点云的组合,用于训练,而7、518个则用于测试。 地面真实深度图是由[45,56]之后的点云生成的。 训练数据具有“汽车”,“行人”和“骑自行车”的注释。 KITTI排行榜限制了向服务器提交以评估测试集的访问权限。 因此,按照[9、25、45]中的协议,训练数据被分为训练集(3,712张图像)和验证集(3,769张图像)。 所有消融研究均在劈裂处进行。 为了提交我们的方法,仅在7K训练数据上从头开始训练我们的模型
Evaluation Metric

若有收获,就点个赞吧
0 人点赞
