图像分类是CV核心之一,比如目标定位、语义分割、全景分割等的核心还是图像分类。图像分类只要求知道图像中有某样东西即可,而无需知道它的具体位置
最近邻算法(惰性算法):如果一个样本在特征空间中的最相邻的样本属于某一个类别,则该样本也属于这个类别
KNN(K最近邻):(纳入更多是参考邻居)核心思想是如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。该方法在确定分类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。 kNN方法在类别决策时,只与极少量的相邻样本有关。由于kNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,kNN方法较其他方法更为适合。KNN百度百科
在对比两张图片的相似度,这里使用两种方式:曼哈顿距离(折线距离)和欧式距离(直线距离)相似度计算之(一)——欧式距离与曼哈顿距离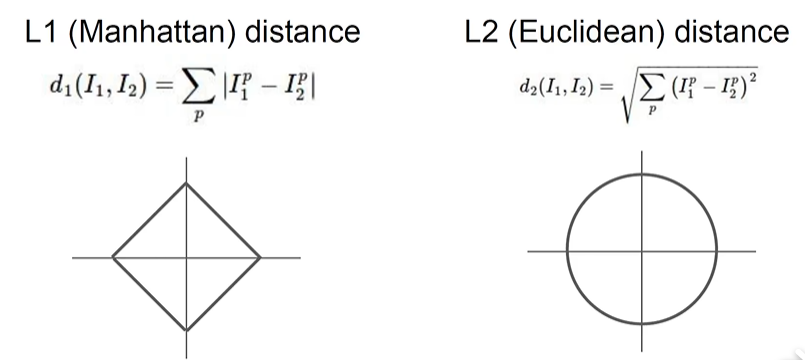
可见L1对旋转敏感,L2
线性分类器:
Wx+b
正则化:
There is one bug with the loss function we presented above. Suppose that we have a dataset and a set of parameters W that correctly classify every example (i.e. all scores are so that all the margins are met, and Li=0Li=0 for all i). The issue is that this set of W is not necessarily unique: there might be many similar W that correctly classify the examples. One easy way to see this is that if some parameters W correctly classify all examples (so loss is zero for each example), then any multiple of these parameters λWλW where λ>1λ>1 will also give zero loss because this transformation uniformly stretches all score magnitudes and hence also their absolute differences. For example, if the difference in scores between a correct class and a nearest incorrect class was 15, then multiplying all elements of W** by 2 would make the new difference 30.

若有收获,就点个赞吧
0 人点赞
