
vict_wang 2019-03-02 15:06:10 
16826 
收藏 69
最后发布:2019-03-02 15:06:10 首次发布:2019-03-02 15:06:10
来源:https://www.cnblogs.com/skyfsm/p/8453498.html
https://blog.csdn.net/bingocsdn/article/details/79393354
BN 是由 Google 于 2015 年提出,这是一个深度神经网络训练的技巧,它不仅可以加快了模型的收敛速度,而且更重要的是在一定程度缓解了深层网络中 “梯度弥散(特征分布较散)” 的问题,从而使得训练深层网络模型更加容易和稳定。所以目前 BN 已经成为几乎所有卷积神经网络的标配技巧了。
从字面意思看来 Batch Normalization(简称 BN)就是对每一批数据进行归一化,确实如此,对于训练中某一个 batch 的数据 {x1,x2,…,xn},注意这个数据是可以输入也可以是网络中间的某一层输出。在 BN 出现之前,我们的归一化操作一般都在数据输入层,对输入的数据进行求均值以及求方差做归一化,但是 BN 的出现打破了这一个规定,我们可以在网络中任意一层进行归一化处理,因为我们现在所用的优化方法大多都是 min-batch SGD,所以我们的归一化操作就成为 Batch Normalization。
1. 特征分布对神经网络训练的作用
在神经网络的训练过程中,我们一般会将输入样本特征进行归一化处理,使数据变为均值为 0,标准差为 1 的分布或者范围在 0~1 的分布。因为当我们没有将数据进行归一化的话,由于样本特征分布较散,可能会导致神经网络学习速度缓慢甚至难以学习。
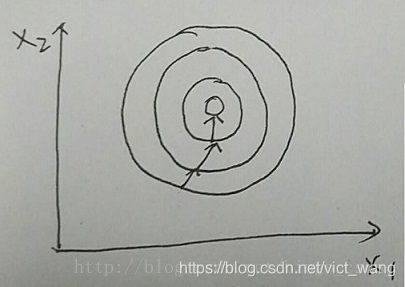
用 2 维特征的样本做例子。如下两个图
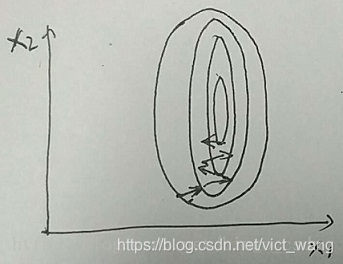
左图中样本特征的分布为椭圆,当用梯度下降法进行优化学习时,其优化过程将会比较曲折,需要经过好久才能到达最优点;
右图中样本特征的分布为比较正的圆,当用梯度下降法进行优化学习时,其有过的梯度方向将往比较正确的方向走,训练比较快就到达最优点。
因此一个比较好的特征分布将会使神经网络训练速度加快,甚至训练效果更好。
2.BN 的作用
但是我们以前在神经网络训练中,只是对输入层数据进行归一化处理,却没有在中间层进行归一化处理。要知道,虽然我们对输入数据进行了归一化处理,但是输入数据经过σ(WX+b) σ(WX+b) 这样的矩阵乘法以及非线性运算之后,其数据分布很可能被改变,而随着深度网络的多层运算之后,数据分布的变化将越来越大。如果我们能在网络的中间也进行归一化处理,是否对网络的训练起到改进作用呢?答案是肯定的。
这种在神经网络中间层也进行归一化处理,使训练效果更好的方法,就是批归一化 Batch Normalization(BN)。BN 在神经网络训练中会有以下一些作用:
- 加快训练速度
- 可以省去 dropout,L1, L2 等正则化处理方法
- 提高模型训练精度
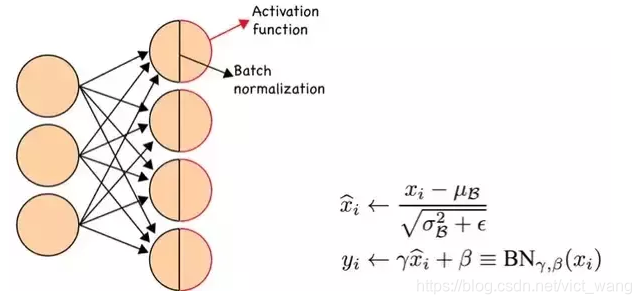
BN 可以作为神经网络的一层,放在激活函数(如 Relu)之前。BN 的算法流程如下图:

- 求每一个小批量训练数据的均值
- 求每一个小批量训练数据的方差
- 使用求得的均值和方差对该批次的训练数据做归一化,获得 0-1 分布。其中ε ε是为了避免除数为 0 时所使用的微小正数。
- 尺度变换和偏移:将 xi x_i 乘以γ γ调整数值大小,再加上β β增加偏移后得到 yi y_i,这里的γ γ是尺度因子,β β是平移因子。这一步是 BN 的精髓,由于归一化后的 xi x_i 基本会被限制在正态分布下,使得网络的表达能力下降。为解决该问题,我们引入两个新的参数:γ,β γ,β。 γ γ和β β是在训练时网络自己学习得到的。
一个标准的归一化步骤就是减均值除方差,那这种归一化操作有什么作用呢?我们观察下图
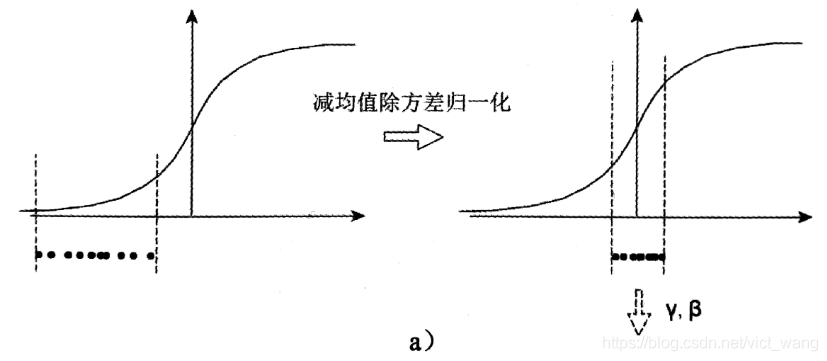
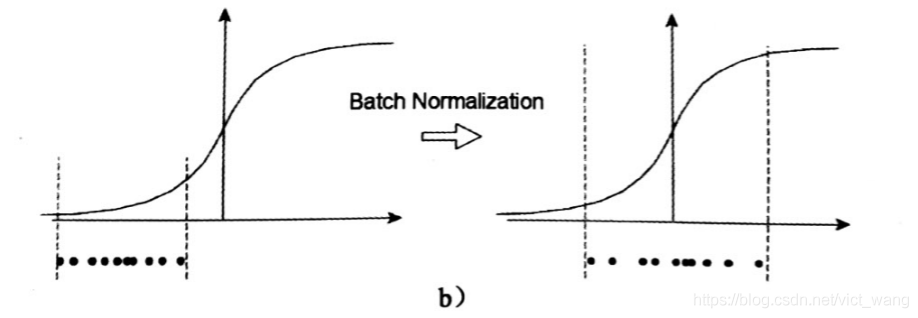
a 中左图是没有经过任何处理的输入数据,曲线是 sigmoid 函数,如果数据在梯度很小的区域,那么学习率就会很慢甚至陷入长时间的停滞。减均值除方差后,数据就被移到中心区域如右图所示,对于大多数激活函数而言,这个区域的梯度都是最大的或者是有梯度的(比如 ReLU),这可以看做是一种对抗梯度消失的有效手段。对于一层如此,如果对于每一层数据都那么做的话,数据的分布总是在随着变化敏感的区域,相当于不用考虑数据分布变化了,这样训练起来更有效率。
那么为什么要有第 4 步,不是仅使用减均值除方差操作就能获得目的效果吗?我们思考一个问题,减均值除方差得到的分布是正态分布,我们能否认为正态分布就是最好或最能体现我们训练样本的特征分布呢?不能,比如数据本身就很不对称(不符合正态分布),或者激活函数未必是对方差为 1 的数据最好的效果,比如 Sigmoid 激活函数,在 - 1~1 之间的梯度变化不大,那么非线性变换的作用就不能很好的体现,换言之就是,减均值除方差操作后可能会削弱网络的性能!针对该情况,在前面三步之后加入第 4 步完成真正的 batch normalization。
BN 的本质就是利用优化变一下方差大小和均值位置,使得新的分布更切合数据的真实分布,保证模型的非线性表达能力。BN 的极端的情况就是这两个参数等于 mini-batch 的均值和方差,那么经过 batch normalization 之后的数据和输入完全一样,当然一般的情况是不同的。
在训练时,我们会对同一批的数据的均值和方差进行求解,进而进行归一化操作。
但是对于预测时我们的均值和方差怎么求呢?
比如我们预测单个样本时,那还怎么求均值和方法呀!其实是这种样子的,对于预测阶段时所使用的均值和方差,其实也是来源于训练集。比如我们在模型训练时我们就记录下每个 batch 下的均值和方差,待训练完毕后,我们求整个训练样本的均值和方差期望值,作为我们进行预测时进行 BN 的的均值和方差:
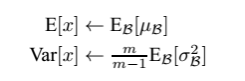
最后测试阶段,BN 的使用公式就是:
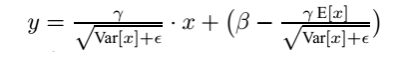
关于 BN 的使用位置,在 CNN 中一般应作用与非线性激活函数之前,s 型函数 s(x) 的自变量 x 是经过 BN 处理后的结果。因此前向传导的计算公式就应该是:

其实因为偏置参数 b 经过 BN 层后其实是没有用的,最后也会被均值归一化,当然 BN 层后面还有个β参数作为偏置项,所以 b 这个参数就可以不用了。因此最后把 BN 层 + 激活函数层就变成了:

注意前面写的都是对于一般情况,对于卷积神经网络有些许不同。
因为卷积神经网络的特征是对应到一整张特征响应图上的,所以做 BN 时也应以响应图为单位而不是按照各个维度。
比如在某一层,batch 大小为 m,响应图大小为 w×h,则做 BN 的数据量为 m×w×h。
BN 在深层神经网络的作用非常明显:若神经网络训练时遇到收敛速度较慢,或者 “梯度爆炸” 等无法训练的情况发生时都可以尝试用 BN 来解决。同时,常规使用情况下同样可以加入 BN 来加速模型训练,甚至提升模型精度。
https://blog.csdn.net/vict_wang/article/details/88075861

若有收获,就点个赞吧
0 人点赞
