作者主页 (文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN 博客
本文网址:https://blog.csdn.net/HiWangWenBing/article/details/121312417
目录
第 3 章 什么是 Transfer Trainning(迁移学习)
第 1 章 前言:常见的工程诉求与特点
(1)数据集欠缺
个人的数据集小,无法提供向 ImageNet 这样的大数据集,但又想利用在 ImageNet 上训练的模型好的模型,为我所用,即基于在一些知名的数据集上训练好的模型,在进一步的训练,以满足自己的应用场景的需求,而无需重头开始训练。
(2)分类数多变
个人特定的应用,分类的种类与 Image(1000 种分类)等知名数据集的分类的种类不同,我们想在已经训练好模型的基础上,做适当的重新训练,以支持我们自己的分类数目,如 100 分类。
(3)防止过度训练,即过拟合
在训练的过程中,能够把在测试集上准确率最好的模型给存储下来,而不是存储后来一次的训练模型,因为大多数情况下,随着训练次数的增加,有可能在某个时间点后,再训练的化,就会出现过拟合的情形。
(4)选择最优的中间结果
训练的过程是耗时的,我们期望能够把训练过程中,反馈优秀的模型给保留下来,而不是等到模型训练好在保存模型,这样防止在训练过程中出现异常,如掉电等因素,导致前面的训练功亏一篑。
(5)在前序训练模型的总体结果基础之上继续训练
有时候,我们期望训练的时候,不是从头开始,也不是完全采用官网上的预训练好的模型,而是基于我们上次训练好的模型的基础之上,进一步的训练。
(6)对训练模型的参数选择性的重新训练
有时候,需要基于已有的模型,锁定部分的网络,如图像特征发现的卷积网络,而只需要训练与特定的数据集强相关的全连接网络。这样,一方面节省了训练资源与实践,另一方面,充分利用他人或之前的训练成果。
上述问题,是大部分人工智能工程应用中涉及到的问题,他们不需要重新设计网络,不需要重新训练,他们尽可能的利用已有的训练好的网络,做最小的问题,来满足自身的工程应用。
所有上述问题,无论是因为数据集的缺乏,还是处于加速训练的考虑,我们都期望基于前序的训练的结果之上,进一步的训练,而无需没都重头开始训练。这就迁移学习和 Fine Tunning 要处理的问题。
第 2 章 神经网络的网络架构
2.1 神经网络的网络架构
要回答上述问题,我们就需要别人训练好的神经网络进行解构。
确认哪些组件或环节是异变的,重构或重新训练。
哪些组件是稳定的,可以被复用,甚至可以完全不用修改。
哪些组件需要微调。
如下是典型的人工神经网络的主要逻辑处理单元或组件。
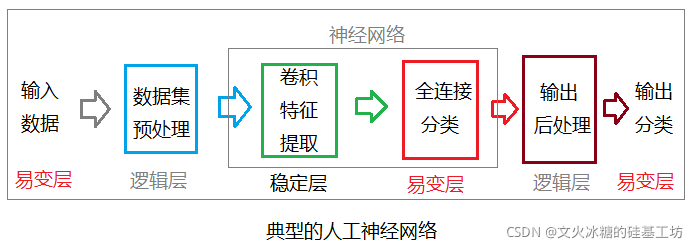
网络的前端的卷积层,用于通用的特征提取。
网络的后端的全连接层或卷积层,用于根据提取的特征进行分类。
2.2 神经网络的三类主攻方向
(1)稳定的卷积层(这部分通常学者、大组织的主攻领域)
用于特征提取,对于图像的特征提取,与特定图像关系不大,可以完全复用,是属于稳定层
当然,稳定是相对于的,用图像训练的特征提取的卷积层,用于语音识别就不合适了。
全局层的网络规模是最大的,需要训练的资源也是最大的,因此,如果能够复用卷积层,实际上可以节省大量的时间和资源。
(2)异变的输入数据、输出种类、全连接层(这部分是小微组织的主攻领域)
特定的工程应用,差别最大的是这三部分,其中只有全连接层属于神经网络。
这也是本文的落脚点和重点要讨论的地方!!!
(3)用于逻辑处理的数据集预处理与后处理(这部分是中等组织的主攻领域)
这部分,大多数情况是稳定的。
但这部分也是整个系统系统,优化最大的地方,是性能优化的重点领域。
有一定规模的公司,如果想要从众多公司中脱颖而出,超越大部分的对手,但有没有能力、没有精力设计出一个全新的网络,对数据的预处理和后处理,就是他们有别于其他对手重要的手段。
第 2 章 什么是 Fine-Tuning(微调)
2.1 什么是 Fine-Tuning
Fine Tuning,中文为微调。
它在保留现有网络架构和参数值得基础之上,重新训练,进行微小的调整,它不涉及对网络参数进行裁剪和重构,因此,Fine-Tuning 是一种整体性、全局的的、微小的改良。
Fine:杰出的;优秀的; 细粒的; 细微的;细小的;
Tune:为… 调音; 调准; 对… 调谐; 使适应;调节;

锁定某个频道之后的微调,去掉杂音,使得声音更加的清晰,这就是 Fine Tuning。
如果需要重新选择频道,就不是 FineTuning 了。
2.2 决定是否需要 Fine Tunning
决定如何使用迁移学习的因素有很多,这是最重要的只有两个:
(1)新数据集的大小
数据集的大小,决定是否需要微调、训练具有特征提取能力的卷积层。
(2)新数据和原数据集的相似程度
新数据和原数据集的相似度,决定了是否能够共享卷积层和全连接层。
- 新数据集与原数据集只有属于同一种类型,才能直接锁定、利用已经训练好的特征提取的卷积层。图像与语音不完全不同的数据集,就不能复用卷积层。
- 新数据集与原数据集只有属于同分类,才能微调全连接层。各种狗的分类、各种花的分类,可以利用全局层,但不能利用全连接层,就需要重新训练全连接层。
2.2 使用 Fine-Tuning 常见场合
下面讨论 4 种常见的场合
(1)与原数据集相似度大 + 新数据集比较小
新数据集比较小,如果整体 fine-tune 可能会过拟合;网络规模大,训练数据集小,是导致过拟合一个重要的原因。
自身的数据集太小,不足以训练需要大量数据的、具有特征提取能力的卷积层。
适合只 FineTuning 全连接层。
(2)与原数据集相似度大 + 新数据集比较大
因为新数据集足够大,适合 fine-tune 整个网络。
(3)与原数据集相似度小 + 新数据集比较大
由于数据集相似度差,原先网络的特征提取功能,不一定适合新数据集,需要训练网络。
且因为新数据集足够大,可以重新训练整个网络。
(4)与原数据集相似度小 + 新数据集比较小
原数据集不相似,需要 Fine-Tuning 或重新训练整个网络。
但因为新数据集小,又不足以有能力训练整个网络。
这就比较尴尬了,最好重新选择预训练网络。
2.3 实现 Fine-Tuning 的方法
- 基于当前的网络架构和网络参数值,使用新的数据集对整个网络重新训练。
- 基于当前的网络架构和网络参数值,锁定卷积层,只对全连接层进行重新训练。
第 3 章 什么是 Transfer Trainning(迁移学习)
3.1 什么是迁移学习
Transfer Learning Definition:
Ability of a system to recognize and apply knowledge and skills learned in previous domains/tasks to novel domains/tasks.
凡是能够利用过去学习的经验为今所用,即将某个领域或任务上学习到的知识或模式应用到不同但相关、相似的领域或问题中,都称为迁移学习。
从上述定义可以看出,迁移学习相对于 Fine-Tuning,是一个更加广泛的概念。
在心理学中,它指的是是一种学习对另一种学习的影响,指在一种情境中获得的技能、知识或态度对另一种情境中技能、知识的获得或态度的形成的影响。
迁移:一种学习对另一种学习的影响, 教育, 在线教育, 好看视频 (baidu.com)
迁移不仅存在于某种经验内部,而且也存在于不同的经验之间。比如,数学学习中审题技能的掌握可能会促进物理、化学等其他学科审题技能的应用;语言学习中丰富的词汇知识的掌握将促进阅读技能的提高,而阅读技能的提高又可以促进更多的词汇知识的获得。知识与技能之间相互迁移。
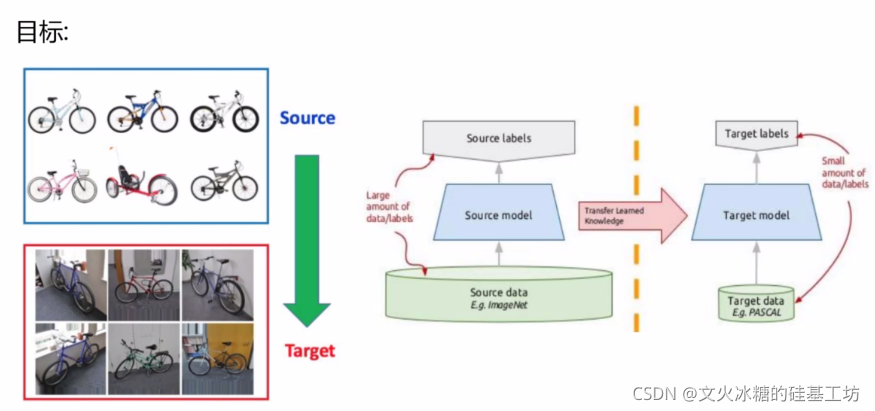
3.2 人工神经网络的 **可迁移的过去经验 **
- 已经标注过的数据集(即使已经过期)
- 已有的神经网络的架构(可以后续优化的基础)
- 神经网络已经学习、训练获得的以后的参数(可以作为后续学习的初始条件)
3.3 迁移学习的好处
(1)对提高解决问题的能力具有直接的促进作用
在学校情境中,大部分问题解决是通过迁移来实现的,要将校内所学的知识技能用于解决校外的现实问题,同样也依赖于迁移。要培养解决问题的能力,就必须从迁移能力的培养入手。
(2)是原有经验得以概括化、系统化的有效途径,是能力与品德形成的关键环节
只有通过广泛的迁移,原有经验才能得以改造,才能够概括化、系统化,原有经验的结构才能更为完善、充实,从而建立起能稳定地调节个体活动的心理结构,即能力与品德的心理结构。迁移是习得的知识、技能与行为规范向能力与品德转化的关键环节。
(3)迁移规律对于学习者、教育工作者以及有关培训人员具有重要的指导作用
应用有效的迁移原则,学习者可以在有限的时间内学得更快、更好,并在适当的情境中主动、准确地应用原有经验,防止原有经验的惰性化。教育工作者以及有关的培训人员应用迁移规律进行教学和培训系统的设计,在课程设置、教材选择、教学方法的确定、教学活动的安排、教学成效的考核等方面利用迁移规律,可以加快教学和培训的进程。
3.4 没有迁移学习的弊端或困境
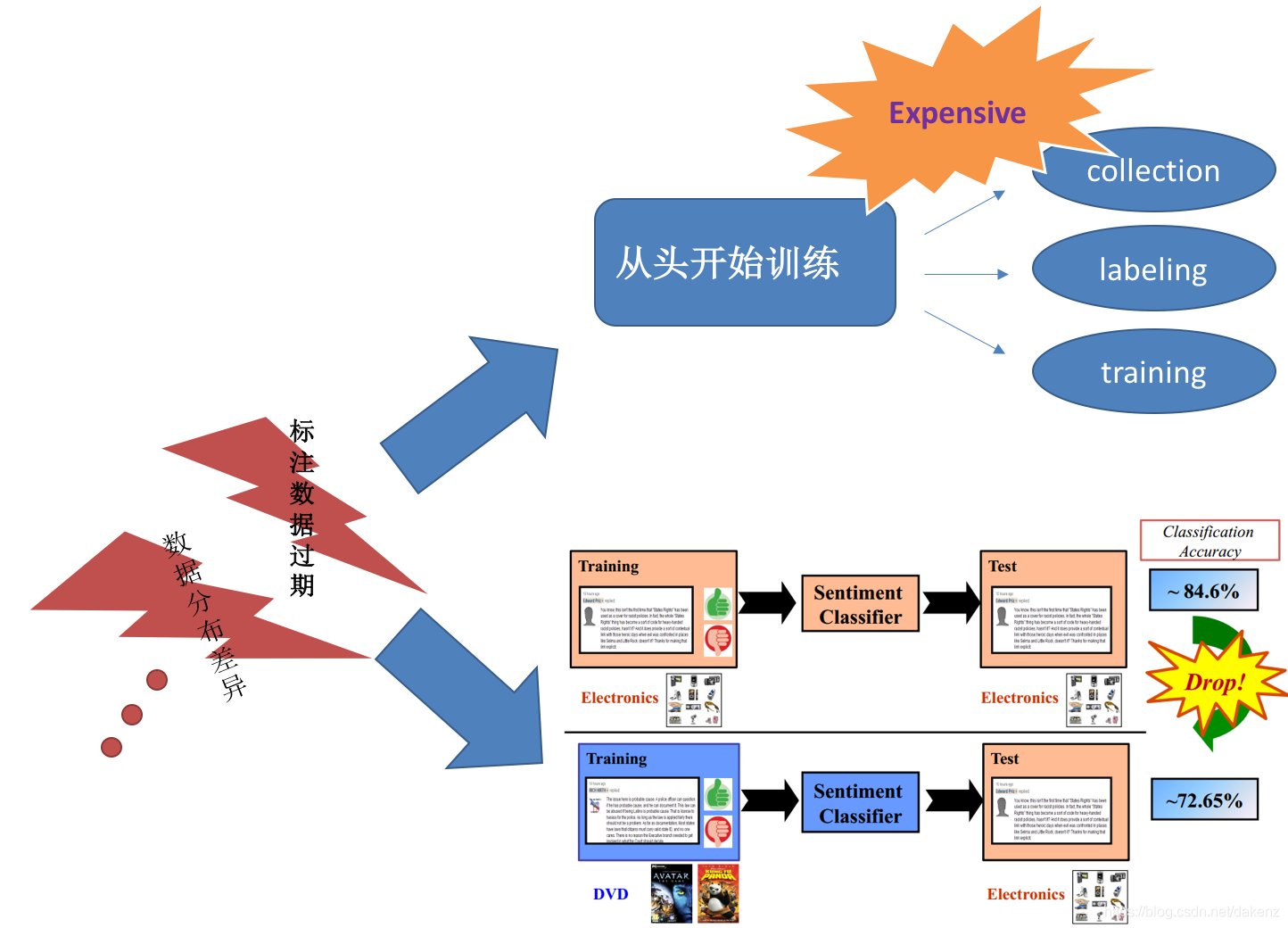
- 采用全新的、大量数据的数据集,并为数据集打标签。
- 设计新的网络模型,网络的效果、性能不确定性大。
- 即使利用现有的网络模型,但从零、从头训练网络的参数,耗时、耗资源、好力。
- 即使利用现有的网络模型,但自己训练的效果还不见得好于他人预训练好的模型参数。
3.5 针对于人工神经网络,过去的经验带来的好处有:
(1)弥补新数据集的不足
- 在新数据集缺乏的情况下,直接利用原先的数据集 + 现有的数据集,组合成新的数据集,弥补新数据集的不足。
(2)减少网络设计的时间
- 不需要重新设计整个网络架构,可以直接利用现有的网络架构
- 在现有网络架构上进行修改,节省了重构网络架构是的时间
(3)节省网络训练的时间
- 通过导入已训练好的模型参数,可以节省模型在新数据集上的收敛时间
- 通过锁定模型的部分参数,节省模型在新数据集所需要消耗的资源
(4)拓展网络的新能力
- 通过在已有模型上,重新训练,拓展模型性能能力
- 通过修订、替代现有模型,重新训练,拓展模型性能能力
3.5 迁移学习在人工神经网络中的实现方法
(1)导入已有的数据集
(2)导入已有的神经网络的架构
(3)导入神经网络已经训练好的模型参数
(4)锁定部分网络参数(如卷积层参数),在新的数据集上重新训练全连接网络
(5)锁定卷积层、替换全连接层,在新的数据集上重新训练全连接网络
第 4 章 常见可以被迁移的预定义网络
AlexNet
VGG
ResNet
SqueezeNet
DenseNet
Inception v3
GoogLeNet
ShuffleNet v2
MobileNetV2
MobileNetV3
ResNeXt
Wide ResNet
MNASNet
EfficientNet
RegNe
第 5 章 建立统一的软件工程架构
详见后续章节,与深度学习强相关…….
作者主页 (文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN 博客
本文网址:https://blog.csdn.net/HiWangWenBing/article/details/121312417
https://blog.csdn.net/HiWangWenBing/article/details/121312417?spm=1001.2101.3001.6650.10&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromBaidu%7ERate-10.pc_relevant_default&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromBaidu%7ERate-10.pc_relevant_default&utm_relevant_index=15

若有收获,就点个赞吧
0 人点赞
