Li 等。 - 2018 - Stereo Vision-Based Semantic 3D Object and Ego-Mot.pdf
摘要
我们提出了一种基于立体视觉的方法,用于在动态自动驾驶场景中跟踪相机的自我运动和3D语义对象。 代替使用端到端方法直接回归3D边界框,我们建议使用易于标记的2D检测和离散视点分类以及轻量级语义推断方法来获得粗糙的3D对象度量。 基于在动态环境下具有鲁棒性的可感知对象的相机姿态跟踪,结合我们新颖的动态对象束调整(BA)方法以融合时间稀疏特征对应和语义3D测量模型,我们可以获得3D对象姿态, 实例精度和时间一致性的速度和锚定动态点云估计。 我们提出的方法的性能在多种情况下得到了证明。 自我运动估计和对象定位都与最新解决方案进行了比较。
关键词
语义SLAM(simultaneous localization and mapping)即时定位与地图构建,3D对象本地化,视觉里程表
1 IntroductionS
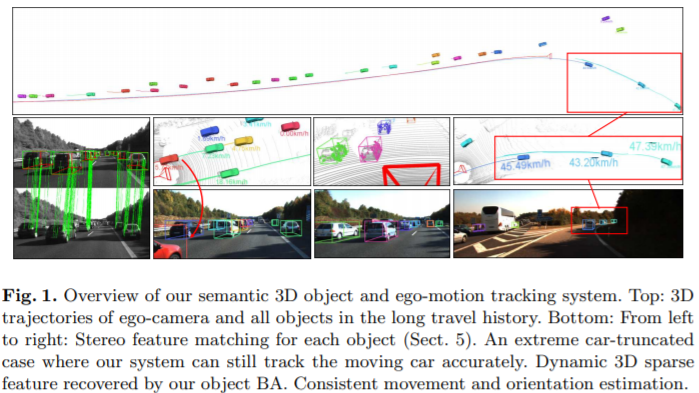
定位动态对象并估计3D空间中的相机自我运动是自动驾驶的关键任务。当前,这些目标分别通过端到端3D对象检测方法[1,2]和传统的视觉SLAM方法[3-5]进行探索。但是,很难将这些方法直接用于自动驾驶场景。对于3D对象检测,存在两个主要问题:1.端到端3D回归方法需要大量的训练数据,并且需要大量工作量才能精确标记3D空间中的所有对象框;以及2.实例3D检测产生帧-独立结果,对于自动驾驶中的连续感知而言,一致性不够高。为了克服这个问题,我们提出了一种仅依赖于2D对象检测和离散视点分类的轻量语义3D盒推理方法(第4节)。与直接3D回归相比,易于检测2D检测和分类任务,并且仅用2D图像即可轻松标记训练数据。但是,建议的3D盒推断也与帧无关,并且以实例2D检测精度为条件。在另一方面,由于精确的特征几何约束,众所周知的SLAM方法可以精确地跟踪相机运动。受此启发,我们可以类似地将稀疏特征对应关系用于对象相对运动约束,以增强时间一致性。但是,如果没有语义先验,则无法通过纯特征测量获得对象实例姿势。为此,由于语义和特征信息的互补性,我们将实例语义推断模型和时间特征相关性集成到紧密耦合的优化框架中,该框架可以连续跟踪3D对象并恢复具有实例的动态稀疏点云精度和时间一致性,可在图1中进行概述。从对象区域感知属性中受益,我们的系统能够可靠地估计摄像机的姿势,而不受动态对象的影响。由于时间几何条件的限制,即使在极端截断的情况下(如图1所示),我们也可以连续跟踪对象,在这种情况下,对象的姿势很难进行推理。此外,我们对检测到的汽车采用了运动学运动模型,以确保一致的方向和运动估计;对于没有特征观察的远距离汽车,它也起着重要的平滑作用。仅依靠成熟的2D检测和分类网络[6],我们的系统能够在各种情况下执行强大的自我运动估计和3D对象跟踪。主要贡献概述如下:
- 一种仅使用2D对象检测和建议的视点分类的轻量级3D框推理方法,该方法提供了对象重投影轮廓和遮挡遮罩以进行对象特征提取。 它还用作后续优化的语义度量模型
- 一种新颖的动态对象束调整方法,该方法将语义和特征量度紧密结合在一起,以实例精度和时间一致性连续跟踪对象状态。
- 在各种情况下进行演示,以表明所提议系统的实用性。
2 Related Work
我们在语义SLAM和基于学习的3D对象图像检测中回顾了相关作品
语义SLAM随着2D对象检测技术的发展,出现了几种具有语义理解工作的联合SLAM,我们将其分为三类。第一个是语义辅助的本地化:[7,8]通过将仅一维的对象度量大小合并到估计框架中,致力于校正单眼视觉Odometry(VO)的整体规模。这两件作品分别进行了室内有小物体的实验和室外实验。 [9]提出了一种概率形式的目标数据关联方法,并在重新观察先前的目标时显示了其漂移校正能力。但是,它通过将2D边界框视为点来忽略对象的方向。在[10]中,作者通过计算矩阵永久性来解决仅基于先验语义图中的对象观察的定位任务。第二个是SLAM辅助的对象检测[11,12]和重构[13,14]:[11]开发了一种2D对象识别系统,该系统对借助摄像机定位的视点改变具有鲁棒性,而[12]执行置信度-使用视觉惯性测量来增长3D对象检测。 [13,14]分别通过融合单眼和RGBD SLAM的点云来重建3D对象的密集表面。最后,第三类是相机和物体姿态的联合估计:[15]使用预先构建的二进制单词袋,[15]定位数据集中的物体并依次校正地图比例尺。在[16,17]中,作者提出了一种基于运动的语义结构(SfM)方法,以考虑场景分量的交互作用来共同估计摄像机,物体。但是,这些方法都没有显示出解决动态对象的能力,也没有充分利用2D边界框数据(中心,宽度和高度)和3维对象大小。也有一些现有的工作[18-21]建立密集的地图并用语义标签对其进行分割。这些工作不在本文讨论范围之内,因此我们将不对其进行详细讨论。
3D对象检测通过深度学习方法从图像推断对象姿态提供了一种定位3D对象的替代方法。 [22,23]使用3D对象姿势之前的形状,其中分别使用了密集形状和线框模型。在[24]中,采用体素模式来检测具有特定可见性模式的对象的3D姿势。与2D检测中的对象建议方法类似[6],[1]通过利用从立体图像中计算出的深度信息来生成3D建议,而[2]利用地平面假设和附加的分割特征来生成3D候选对象。然后,将R-CNN用于候选人评分和对象识别。用于提案生成或模型拟合的此类高维特征在训练和部署方面在计算上都很复杂。 [25]不是直接生成3D框,而是在单独的阶段对对象的方向和尺寸进行回归。然后使用2D-3D盒子几何约束来计算3D对象姿势,而仅取决于实例2D盒子限制了其在对象截断情况下的性能。
在这项工作中,我们研究了现有工作的利弊,并提出了一种用于自动驾驶的集成感知解决方案,该解决方案充分利用了实例语义先验和精确的特征时空对应关系,从而实现了对自我的鲁棒和连续状态估计。 摄像机以及各种环境中的静态或动态对象。
3 Overview
我们的语义跟踪系统具有三个主要模块,如图2所示。第一个模块执行2D对象检测和视点分类(第4节),其中,根据2D盒子边缘和3D盒子之间的约束大致推断出对象的姿势 顶点。 第二个模块是特征提取和匹配(第5节)。 它将所有推断的3D框投影到2D图像,以获取对象的轮廓和遮挡蒙版。 然后应用引导的特征匹配来获得立体和时间图像的鲁棒特征关联。 在第三个模块(第6节)中,我们将所有语义信息,特征度量集成到紧密耦合的优化方法中。 运动学模型还应用于汽车,以获得一致的运动估计。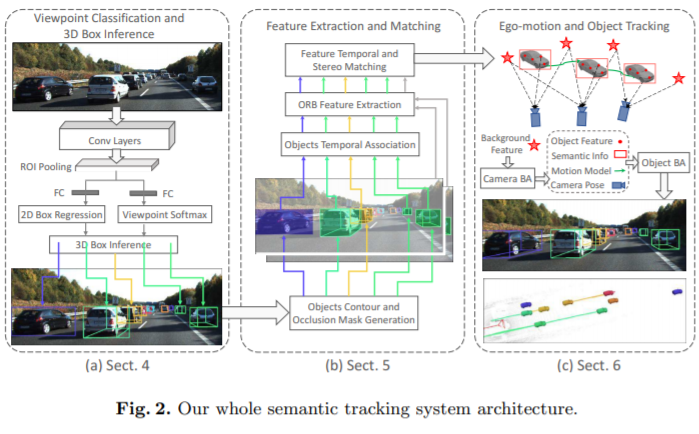
4 Viewpoint Classification and 3D Box Inference
我们的语义度量包括2D对象框和分类的视点。 基于此,可以立即以近似形式大致推断出对象的姿势。
4.1 Viewpoint Classification

若有收获,就点个赞吧
0 人点赞
