论文题目:Multi-View 3D Object Detection Network for Autonomous Driving
开源代码:https://github.com/leeyevi/MV3D_TF
MV3D-Net 是 2017 年发表的一篇论文,它融合了视觉和雷达点云信息,同时,和以往基于 voxel 的方法不同,它只用了点云的俯视图和前视图,这样既能减少计算量,又不至于丧失过多的信息。随后生成 3D 候选区域,把特征和候选区域融合后输出最终的目标检测框。
一、相关工作及改进
该论文对相关工作做了比较清晰的总结,我们不妨把这部分原文贴在这里,算是对 3D 目标检测的算法有一个整体的了解。作者列出以上这些传统方法,也是为了显示自己提出的方法的优越性,针对这积累算法的缺点,作者也提出了相应的改进思路,这些思路就是的实现就是本文的核心内容。
1. 基于点云的 3D 目标检测
- 方法描述:将 3D 点云体素化,提取结构特征之后送入到 SVM 或者神经网络中进行分类,还有的使用了点云的前视图,包含 2D 点云图,使用了一个全链接的卷积网络作用在 2D 点云图上从而预测出 3D 的 boxes。
- 尚存缺点:计算量太大
- 改进思路:3D 点云编码为多视角的特征图,应用与基于区域的多模式表示。
2. 基于 Images 的 3D 目标检测
- 方法描述:通过 3D 体素模式(例如 3DVP)运用一系列的 ACF 检测器去做 2D 的检测和 3D 姿态的估计。
- 尚存缺点:Image-based 的方法通常都依赖于精确的深度估计或标记检测。
- 改进思路:融合雷达点云去提高 3D localization 的效果。
3. 多模态融合
- 方法描述:结合图像,深度,甚至光流应用于 2D 的行人检测。
- 尚存缺点:这方面工作太少,方法发展还不完善(作者这种描述,已经说明了他的态度,认为这是一个好思路)。
- 改进思路:本文是受到了 FractalNet 和 Deeply-Fused Net 的启发。在 FractalNet 中,基础模块使用不断增加的通道迭代地构建网络,相似地,通过联合浅层和深层子网络去构建深度融合的网络。文章的工作区别与他们的地方在于对于每一栏使用了相同的基础网络,为了正则化增加了辅助的路径和损失。
4. 3D 目标候选区
- 方法描述:基于立体的点云设计一些深度的特征来产生一些 3D 候选框(例如 3DOP),或者利用地平面和一些语义信息生成 3D 候选区(例如 Mono3D)。
- 尚存缺点:3DOP 和 Mono3D 都使用了手工的特征。
- 改进思路:文中提出了使用点云的俯视图表达,应用 2D 的卷积来生成 3D 的候选区。(使用俯视图的原因后面会有介绍)
二、实现方法
1. 整体介绍
理解了以上的改进思路,我们现在可以梳理本文的实现步骤了,为了更好的理解这些步骤,我们先把网络的结构图放上来。
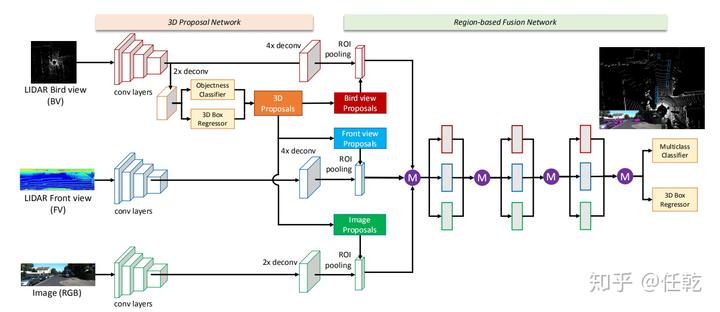
本文方法设计的具体步骤如下:
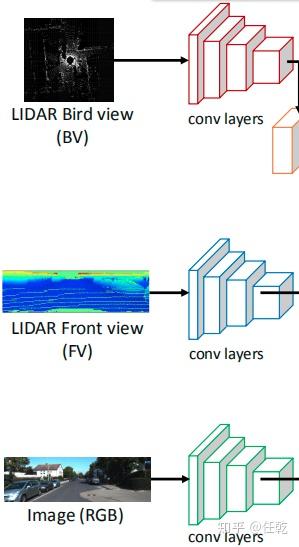
1)提取特征
a. 提取点云俯视图特征
b. 提取点云前视图特征
c. 提取图像特征
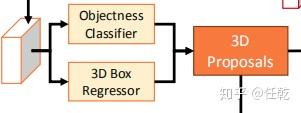
2)从点云俯视图特征中计算候选区域
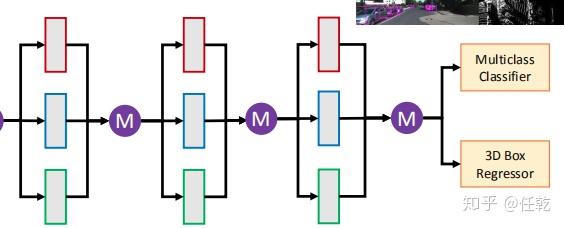
3)把候选区域分别与 1)中 a、b、c 得到的特征进行整合
a. 把俯视图候选区域投影到前视图和图像中
b. 经过 ROI pooling 整合成同一维度

4)把整合后的数据经过网络进行融合
这样捋一捋是不是就感觉清晰多了?
后面就是对上面每一步进行详细介绍了
2. 提取特征
1)提取俯视图特征
俯视图由高度、强度、密度组成,投影到分辨率为 0.1 的二维网格中。
a. 高度
对于每个网格来说,高度特征有点云单元格中的最高值得出;为了编码更多的高度特征,点云被分为 M 块,每一个块都计算相应的高度图,从而获得了 M 个高度图。
b. 强度
强度是每个单元格中有最大高度的点的映射值.
c. 密度
表示每个单元格中点的数目,为了归一化特征,被计算为:

其中 N 为单元格中的点的数目。强度和密度特征计算的是整个点云,而高度特征是计算 M 切片,所以,总的俯视图被编码为(M + 2)个通道的特征
2)提取前视图特征
前视图给俯视图提供了额外的信息。由于激光点云非常稀疏的时候,投影到 2D 图上也会非常稀疏。相反,我们将它投影到一个圆柱面生成一个稠密的前视图。 假设 3D 坐标为
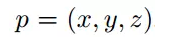
那么他的前视图坐标

可以通过如下式子计算
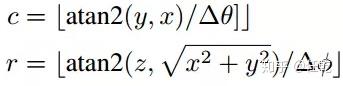
3)提取图像特征
是它,是它,就是它,我们熟悉的朋友,小哪吒,哦不对,是小 VGG-16。
那就不需要多说了吧
2. 候选区域网络
此处选用的是俯视图进行候选区域计算,那么我们就问了,为啥要用俯视图呢?原因有三:
1)物体投射到俯视图时,保持了物体的物理尺寸,从而具有较小的尺寸方差,这在前视图 / 图像平面的情况下不具备的。
2)在俯视图中,物体占据不同的空间,从而避免遮挡问题。
3)在道路场景中,由于目标通常位于地面平面上,并在垂直位置的方差较小,可以为获得准确的 3Dbounding box 提供良好基础。
至于候选区域怎么做,我们就不必详细介绍了,因为候选区域网络就是我们熟悉的 RPN 呀,关于 RPN 的介绍可以参考这篇文章
3. 把候选区域分别与提取的特征进行整合
a. 把俯视图候选区域投影到前视图和图像中
给一个俯视图,网络通过一些 3D prior boxes 生成 3D 的候选框。每一个 3D 候选框都被参数化为:
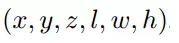
这些锚点都可以由
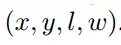
离散化后获得。通过这种思路,我们就可以得到前视图和图像中的锚点。
b. 经过 ROI pooling 整合成同一维度
它的目的是在融合之前要保证数据是同一维度。至于 ROI pooling 的详细介绍我们不在这写了,给出一个参考资料,大家感兴趣的可以自己去看。
4. 融合网络
有了整合后的数据,要想得到最终的检测框,那不就很简单了吗。
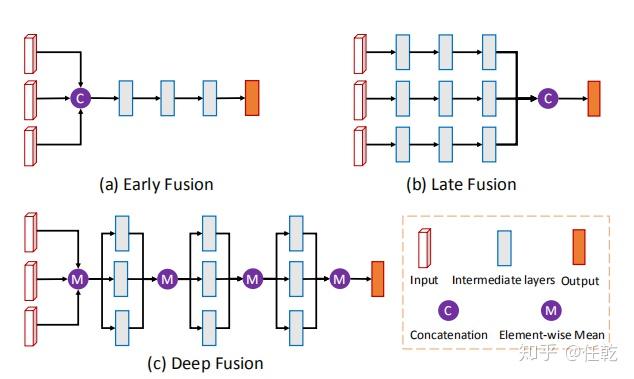
不过值得注意的是,作者在这里做了一个讨论,它尝试了三种融合方法,最终才选择了现在使用的这一种。
三、实验结果
给出一张表大家自己看吧,总之就是说自己的好呗

最后给出一张图,这张图也是说自己的比别的好,看大家能不能在图里发现到底好在哪


若有收获,就点个赞吧
0 人点赞
