PASCAL VOC 挑战赛 (The PASCAL Visual Object Classes )是一个世界级的计算机视觉挑战赛, PASCAL全称:Pattern Analysis, Statical Modeling and Computational Learning,是一个由欧盟资助的网络组织。
很多优秀的计算机视觉模型比如分类,定位,检测,分割,动作识别等模型都是基于 PASCAL VOC 挑战赛及其数据集上推出的,尤其是一些目标检测模型(比如大名鼎鼎的 R CNN 系列,以及后面的 YOLO,SSD 等)。
PASCAL VOC 从 2005 年开始举办挑战赛,每年的内容都有所不同,从最开始的分类,到后面逐渐增加检测,分割,人体布局,动作识别(Object Classification 、Object Detection、Object Segmentation、Human Layout、Action Classification)等内容,数据集的容量以及种类也在不断的增加和改善。该项挑战赛催生出了一大批优秀的计算机视觉模型(尤其是以深度学习技术为主的)。



我们知道在 ImageNet 挑战赛上涌现了一大批优秀的分类模型,而 PASCAL 挑战赛上则是涌现了一大批优秀的目标检测和分割模型,这项挑战赛已于 2012 年停止举办了,但是研究者仍然可以在其服务器上提交预测结果以评估模型的性能。
虽然近期的目标检测或分割模型更倾向于使用 MS COCO 数据集,但是这丝毫不影响 PASCAL VOC 数据集的重要性,毕竟 PASCAL 对于目标检测或分割类型来说属于先驱者的地位。对于现在的研究者来说比较重要的两个年份的数据集是 PASCAL VOC 2007 与 PASCAL VOC 2012,这两个数据集频频在现在的一些检测或分割类的论文当中出现。
- PASCAL 主页 与 排行榜 (榜上已几乎看不到传统的视觉模型了,全是基于深度学习的)
- PASCAL VOC 2007 挑战赛主页 与 PASCAL VOC 2012 挑战赛主页 与 PASCAL VOC Evaluation Server.
- 以及在两个重要时间点对 PASCAL VOC 挑战赛 成绩进行总结的两篇论文
- The PASCAL Visual Object Classes Challenge: A Retrospective
Everingham, M., Eslami, S. M. A., Van Gool, L., Williams, C. K. I., Winn, J. and Zisserman, A.
International Journal of Computer Vision, 111(1), 98-136, 2015
Bibtex source | Abstract | PDF
主要总结 PASCAL VOC 2012 的数据集情况,以及 2011 年 - 2013 年之间出现的模型及其性能对比 - The PASCAL Visual Object Classes (VOC) Challenge
Everingham, M., Van Gool, L., Williams, C. K. I., Winn, J. and Zisserman, A.
International Journal of Computer Vision, 88(2), 303-338, 2010
Bibtex source | Abstract | PDF
主要总结 PASCAL VOC 2007 的数据集情况,以及 2008 年之前出现的模型及其性能对比 - 不过在以上论文中出现的深度学习模型只有一个 R-CNN 吧,大部分都是传统方式的模型,毕竟深度学习模型主要在 14 年以后才大量涌现。
- The PASCAL Visual Object Classes Challenge: A Retrospective
本文也是以 PASCAL VOC 2007 和 2012 为例简要介绍 VOC 数据集的结构。
1.1 层级结构
PASCAL VOC 数据集的 20 个类别及其层级结构:

- 从 2007 年开始,PASCAL VOC 每年的数据集都是这个层级结构
- 总共四个大类:vehicle,household,animal,person
- 总共 20 个小类,预测的时候是只输出图中黑色粗体的类别
- 数据集主要关注分类和检测,也就是分类和检测用到的数据集相对规模较大。 关于其他任务比如分割,动作识别等,其数据集一般是分类和检测数据集的子集。
1.2 发展历程与使用方法
简要提一下在几个关键时间点数据集的一些关键变化,详细的请查看PASCAL VOC 主页 。
- 2005 年:还只有 4 个类别: bicycles, cars, motorbikes, people. Train/validation/test 共有图片 1578 张,包含 2209 个已标注的目标 objects.
- 2007 年 :在这一年 PASCAL VOC 初步建立成一个完善的数据集。类别扩充到 20 类,Train/validation/test 共有 9963 张图片,包含 24640 个已标注的目标 objects.
07 年之前的数据集中 test 部分都是公布的,但是之后的都没有公布。 - 2009 年:从这一年开始,通过在前一年的数据集基础上增加新数据的方式来扩充数据集。比如 09 年的数据集是包含了 08 年的数据集的,也就是说 08 年的数据集是 09 年的一个子集,以后每年都是这样的扩充方式,直到 2012 年;09 年之前虽然每年的数据集都在变大(08 年比 07 年略少),但是每年的数据集都是不一样的,也就是说每年的数据集都是互斥的,没有重叠的图片。
- 2012 年:从 09 年到 11 年,数据量仍然通过上述方式不断增长,11 年到 12 年,用于分类、检测和 person layout 任务的数据量没有改变。主要是针对分割和动作识别,完善相应的数据子集以及标注信息。
对于分类和检测来说,也就是下图所示的发展历程,相同颜色的代表相同的数据集:

分割任务的数据集变化略有不同:
- VOC 2012 用于分类和检测的数据包含 2008-2011 年间的所有数据,并与 VOC2007 互斥。
- VOC 2012 用于分割的数据中 train+val 包含 2007-2011 年间的所有数据,test 包含 2008-2011 年间的数据,没有包含 07 年的是因为 07 年的 test 数据已经公开了。
2012 年是最后一次挑战赛,最终用于分类和检测的数据集规模为:train/val :11540 张图片,包含 27450 个已被标注的 ROI annotated objects ;用于分割的数据集规模为:trainval:2913 张图片,6929 个分割,用于其他任务的不再细说,参考这里 。
即便挑战赛结束了,但是研究者们仍然可以上传预测结果进行评估。上传入口: PASCAL VOC Evaluation Server.
目前广大研究者们普遍使用的是 VOC2007 和 VOC2012 数据集,因为二者是互斥的,不相容的。
论文中针对 VOC2007 和 VOC2012 的具体用法有以下几种:
- 只用 VOC2007 的 trainval 训练,使用 VOC2007 的 test 测试
- 只用 VOC2012 的 trainval 训练,使用 VOC2012 的 test 测试,这种用法很少使用,因为大家都会结合 VOC2007 使用
- 使用 VOC2007 的 train+val 和 VOC2012 的 train+val 训练,然后使用 VOC2007 的 test 测试,这个用法是论文中经常看到的 07+12 ,研究者可以自己测试在 VOC2007 上的结果,因为 VOC2007 的 test 是公开的。
- 使用 VOC2007 的 train+val+test 和 VOC2012 的 train+val 训练,然后使用 VOC2012 的 test 测试,这个用法是论文中经常看到的 07++12 ,这种方法需提交到 VOC 官方服务器上评估结果,因为 VOC2012 test 没有公布。
- 先在 MS COCO 的 trainval 上预训练,再使用 VOC2007 的 train+val、 VOC2012 的 train+val 微调训练,然后使用 VOC2007 的 test 测试,这个用法是论文中经常看到的 07+12+COCO 。
- 先在 MS COCO 的 trainval 上预训练,再使用 VOC2007 的 train+val+test 、 VOC2012 的 train+val 微调训练,然后使用 VOC2012 的 test 测试 ,这个用法是论文中经常看到的 07++12+COCO,这种方法需提交到 VOC 官方服务器上评估结果,因为 VOC2012 test 没有公布。
在各自数据集上分别进行建模和评测的用法比较少,基本上在早期论文里出现就是起个对照作用;现在的大部分论文都会为了增加数据量而将二者合起来使用。
由于现在的研究基本上都是在 VOC2007 和 VOC2012 上面进行,因此只介绍这两个年份的。
2.1 VOC 2007
一些示例图片展示:Classification/detection example images
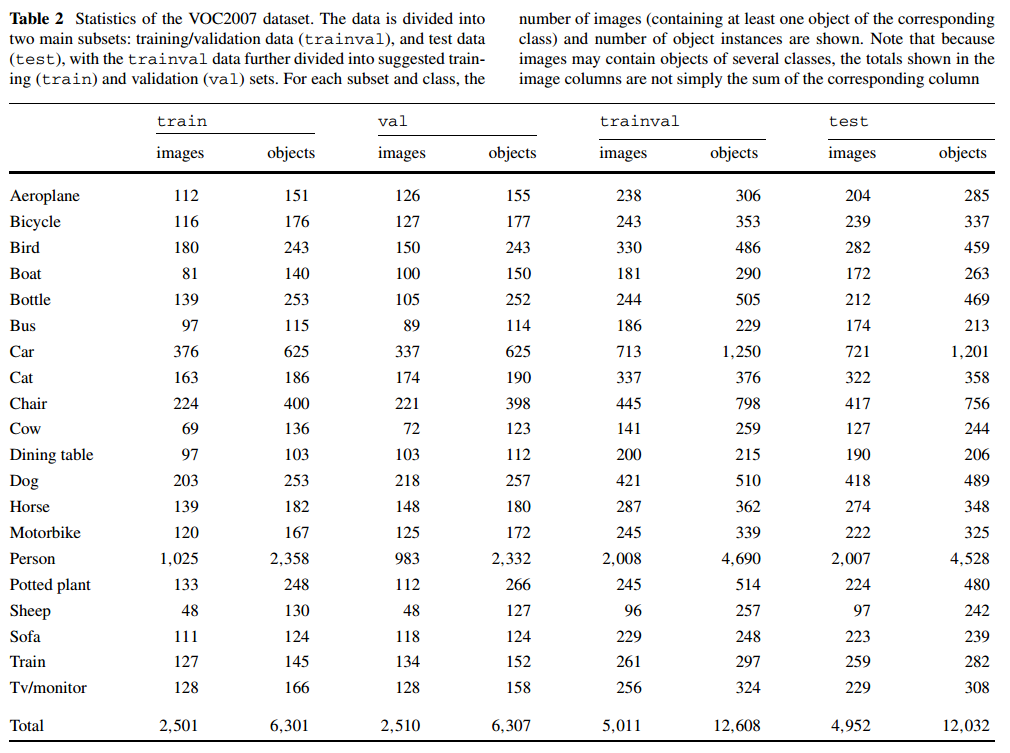
数据集总体统计:
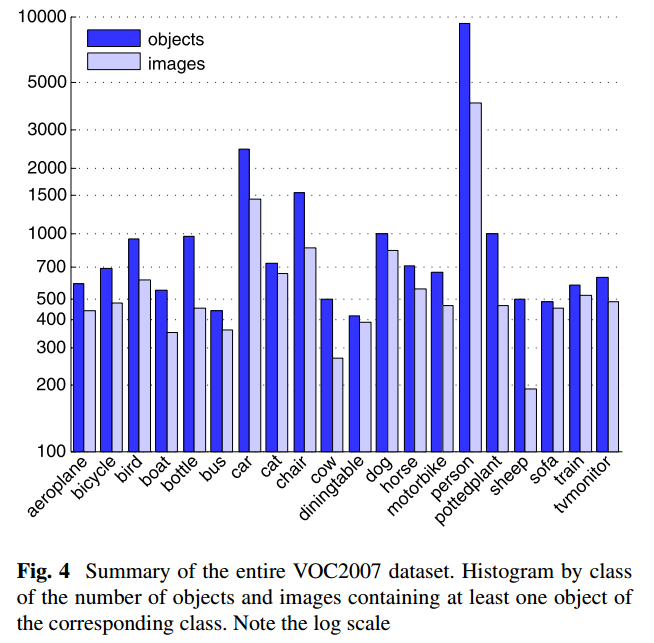
- 以上是数据集总体的统计情况,这个里面是包含了测试集的,可见 person 类是最多的。
训练集,验证集,测试集划分情况

- PASCAL VOC 2007 数据集分为两部分:训练和验证集 trainval,测试集 test ,两部分各占数据总量的约 50%。其中 trainval 又分为训练集和测试集,二者分别各占 trainval 的 50%。
- 每张图片中有可能包含不只一个目标 object。
这里我就只贴出用于分类和检测的划分情况,关于分割或者其他任务的划分方式 点击这里查看 。
2.2 VOC 2012
一些示例图片展示:Classification/detection example images
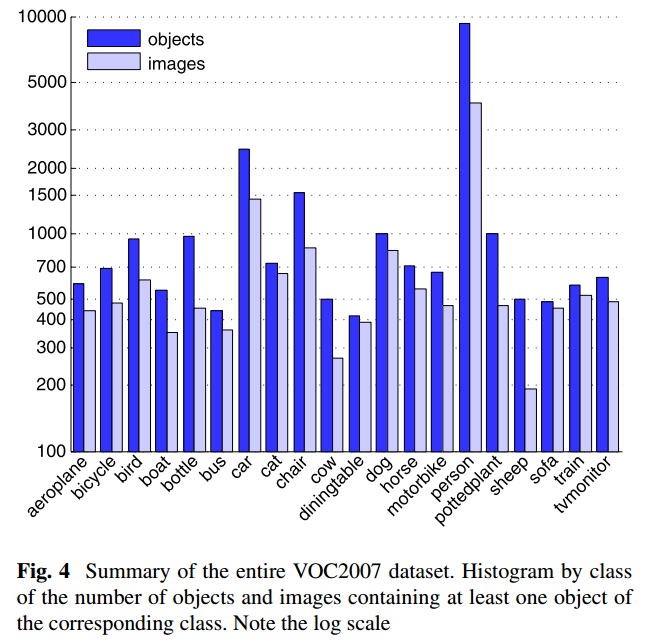
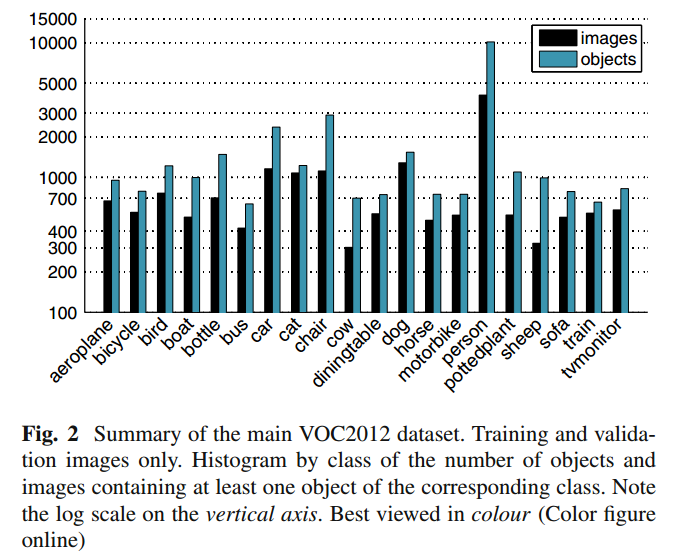
数据集总体统计

- 这个统计是没有包含 test 部分的,仍然是 person 类最多
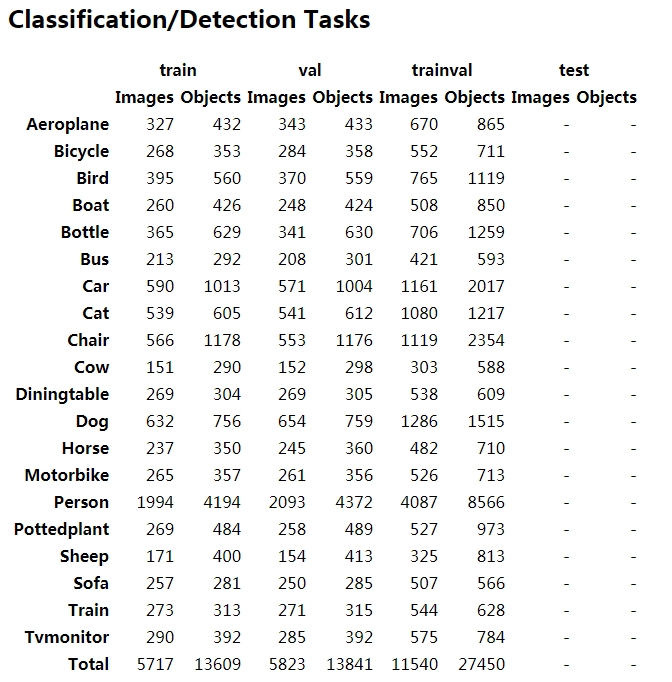
trainval 部分的数据统计:
test 部分没有公布,同样的 除了分类和检测之外的数据统计,参考这里
2.3 VOC 2007 与 2012 的对比
VOC 2007 与 2012 数据集及二者的并集 数据量对比

- 黑色字体所示数字是官方给定的,由于 VOC2012 数据集中 test 部分没有公布,因此红色字体所示数字为估计数据,按照 PASCAL 通常的划分方法,即 trainval 与 test 各占总数据量的一半。
数据集的标注还是很谨慎的,有专门的标注团队,并遵从统一的标注标准,参考 guidelines 。
标注信息是用 xml 文件组织的如下:
- filename :文件名
- source,owner:图片来源,及拥有者
- size:图片大小
- segmented:是否分割
- object:表明这是一个目标,里面的内容是目标的相关信息

4.1 Classification Task
每一类都有一个 txt 文件,里面每一行都是测试集中的一张图片,前面一列是图片名称,后面一列是预测的分数。
comp1_cls_test_car.txt:
4.2 Detection Task
comp3_det_test_car.txt:
每一类都有一个 txt 文件,里面每一行都是测试集中的一张图片,每行的格式按照如下方式组织
confidence 用来计算 mAP.
PASCAL 的评估标准是 mAP(mean average precision)
关于 mAP 不再详细解释,参考以下资料:
- 性能指标(模型评估)之 mAP
- average precision
- 周志华老师 《机器学习》 模型评估标准一节
这里简单的提一下:
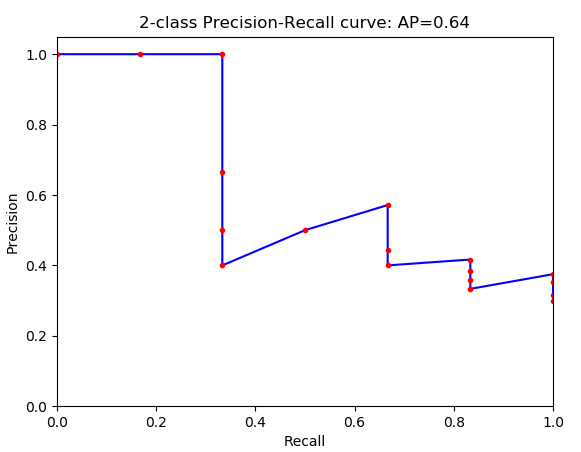
下面是一个二分类的 P-R 曲线(precision-recall curve),对于 PASCAL 来说,每一类都有一个这样的 P-R 曲线,P-R 曲线下面与 x 轴围成的面积称为 average precision,每个类别都有一个 AP, 20 个类别的 AP 取平均值就是 mAP。
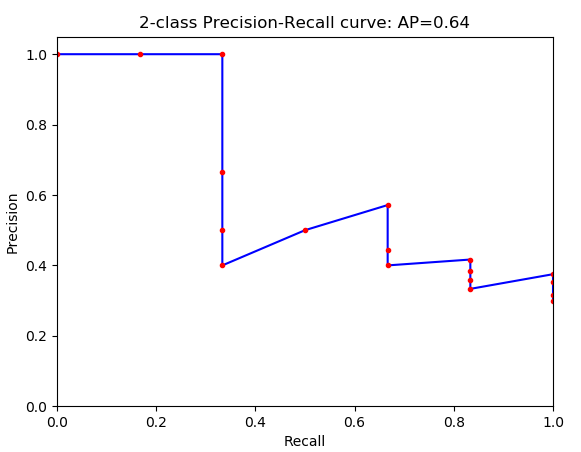
PASCAL 官方给了评估脚本 mAP 的脚本和示例代码 development kit code and documentation ,是用 MATLAB 写的。
数据集的下载:
或者支直接点击下面链接下载:
- Download the training/validation data (450MB tar file)
- Download the annotated test data (430MB tar file)
上面的解压命令会将 VOC2007 的 trainval 和 test 解压到一块,数据会混在一起,如果不想,可以自己指定解压路径。以 VOC 2007 为例,解压后的文件:
Annotations 文件夹:
以 xml 文件的形式,存放标签文件,文件内容如前述,文件名与图片名是一样的,6 位整数
ImageSets 文件夹:
存放数据集的分割文件
包含三个子文件夹 Layout,Main,Segmentation,其中 Main 文件夹存放的是用于分类和检测的数据集分割文件,Layout 文件夹用于 person layout 任务,Segmentation 用于分割任务
主要介绍一下 Main 文件夹中的组织结构,先来看以下这几个文件:
里面的文件内容是下面这样的:以 train.txt 文件为例
就是对数据库的分割,这一部分图片用于 train,其他的用作 val,test 等。
Main 中剩下的文件很显然就是每一类别在 train 或 val 或 test 中的 ground truth,这个 ground truth 是为了方便 classification 任务而提供的;如果是 detection 的话,使用的是上面的 xml 标签文件。
里面文件是这样的(以 aeroplane_train.txt 为例):
前面一列是训练集中的图片名称,这一列跟 train.txt 文件中的内容是一样的,后面一列是标签,即训练集中这张图片是不是 aeroplane,是的话为 1,否则为 - 1.
其他所有的 (class)_(imgset).txt 文件都是类似的。
- (class)_train 存放的是训练使用的数据,每一个 class 都有 2501 个 train 数据。
- (class)_val 存放的是验证使用的数据,每一个 class 都有 2510 个 val 数据。
- (class)_trainval 将上面两个进行了合并,每一个 class 有 5011 个数据。
- (class)_test 存放的是测试使用的数据,每一个 class 有 4952 个 test 数据。
所有文件都 指定了正负样本,每个 class 的实际数量为正样本的数量,train 和 val 两者没有交集。
VOC2012 的数据集组织结构是类似的,不一样的地方在于 VOC2012 中没有 test 类的图片和以及相关标签和分割文件,因为这部分数据 VOC2012 没有公布。

若有收获,就点个赞吧
0 人点赞

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}