前言
近年来随着硬件计算能力的大爆发,在高性能计算的支持下深度学习有了革命性的进步,在互联网大数据的保证下深度学习有了源源不断的动力,优秀的网络结构被不断提出,深度学习技术已被推向 时代浪潮。在深度学习的分支领域,计算机视觉领域当中,人脸识别技术的发展依然是工业界、学术界重点关注的对象。在 ResNet 在 2015 年被提出后,越来越多优秀的网络基于 ResNet 进行优化更新也已取得卓越的成就,而在网络结构进一步升级优化有困难的情况下,研究者逐步将目光转向损失函数这一指挥棒上。
文章[ArcFace:Additive Angular Margin Loss for Deep Face Recognition]的作者提出的 Angular Margin Loss 在继 SoftmaxLoss、Center Loss、A-Softmax Loss、Cosine Margin Loss 之后有更加卓越的表现,同时作者也对这一 “卓越表现” 予以了论证。

论文地址:https://arxiv.org/abs/1801.07698
Code:https://github.com/deepinsight/insightface
人脸识别流程
人脸识别分为四个过程:人脸检测、人脸对齐、特征提取、特征匹配。其中,特征提取作为人脸识别最关键的步骤,提取到的特征更偏向于该人脸 “独有” 的特征,对于特征匹配起到举足轻重的作用,而我们的网络和模型承担着提取特征的重任,优秀的网络和训练策略使得模型更加健壮。
但在 Resnet 网络表现力十分优秀的情况下,要提高人脸识别模型的性能,除了优化网络结构,修改损失函数是另一种选择,优化损失函数可以使模型从现有数据中学习到更多有价值的信息。
而在我们以往接触的分类问题有很大一部分使用了 Softmax loss 来作为网络的损失层,实验表明 Softmax loss 考虑到样本是否能正确分类,而在扩大异类样本间的类间距离和缩小同类样本间的类内距离的问题上有很大的优化空间,因而作者在 Arcface 文章中讨论了 Softmax 到 Arcface 的变化过程,同时作者还指出了数据清洗的重要性,改善了 Resnet 网络结构使其 “更适合” 学习人脸的特征。
如下是 ArcFace 的输入到输出流程(上面的是论文原图,下面的是此文章的图):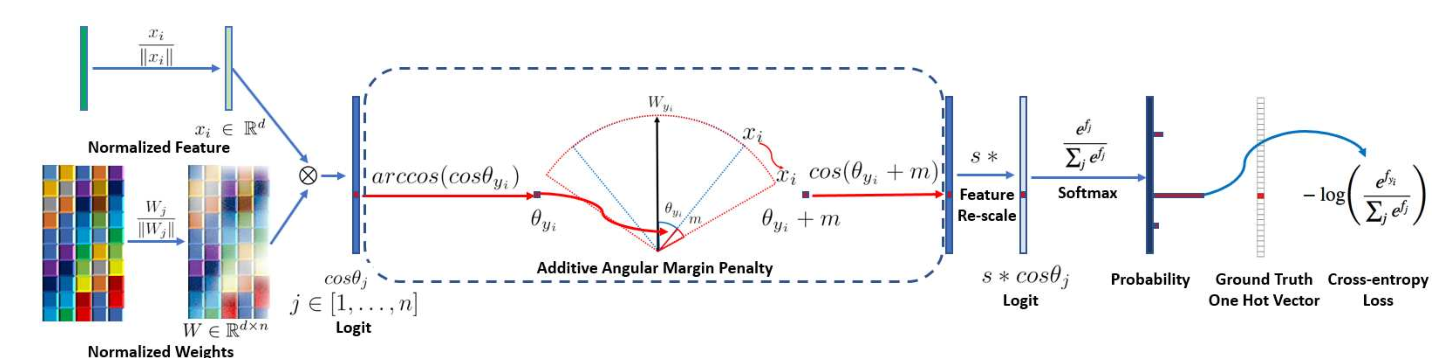
上图的处理流程是这样子的,这里假设我们的样本类别数为 n,我们的输入数据 x 的维度为 d,模型权重 w 的维度为 d⋅n,我们首先对我们的样本 x 和权重 w进行归一化,归一化之后样本经过网络最后得到 1⋅n 维的全连接输出,输出后计算得到 Target Logit 再乘以归一化参数 s再经过 Softmax 计算得到 Prob。
数据

在训练过程中,神经网络都是基于我们的训练数据学习特征的,既然是从训练数据学习特征,最终的方向自然是逼近最终数据的最真实的特征,也就是说,我们数据最原始是什么样子,我们的网络的极限就是什么样子,它不能超越数据本身,而研究者在做的事情,也就是使得网络最后能更加逼近 “极限”。所以数据在深度学习中扮演着极其重要的角色,所以文章中强调了干净的数据(数据清洗)的重要性。
这里列举一些文章中提到的开源数据集:
VGG2
VGG2Face 人脸数据集包含有训练集 8631 个人的脸(总量有 3141890 张人脸),测试集包含有 500 个人的脸(总量有 169396 张人脸),属于高质量数据集。
MS-Celeb-1M
MS1M 数据集包含有大约 10 万个人的脸(大约有 1 千万张人脸),但是数据集中包含有很多的 “噪声”,所以作者对 MS1M 做了数据清洗,最终作者清洗得到的干净的数据包含有 8.5 万个人的脸(包含有 380 万张人脸)。
MegaFace
MegaFace 数据集包含有 69 万个人的脸(包含大约有 100 万张人脸),所有数据由华盛顿大学从 Flickr 上组织收集。MegaFace 是第一个在百万规模级别的面部识别算法的测试基准,这个项目旨在研究当数据库规模提升数个量级时,现有的脸部识别系统能否维持可靠的准确率。MegaFace 是目前最为权威、最热门的评价人脸识别性能,特别是海量人脸识别检索性能的基准参照之一。
LFW
LFW(Labeled Faces in the Wild)数据集包含了从网络收集的 13000 张人脸图像,每张图像都以被拍摄的人名命名。其中,有 1680 个人有两个或两个以上不同的照片。LFW 主要侧重于对比两张人脸照片是否具有相同身份不同。
CPF
CFP(Celebrities in Frontal Profile )数据集是美国名人的人脸数据集,其中包含有 500 个人物对象,有他们的 10 张正面照以及 4 张形象照,因此在作为人物比对验证的时候,作者选用了最有挑战的正面照与形象照作为验证集(CFP,Frontal-Profile,CFP-FP )。
AgeDB
AgeDB(Age Database )数据集包含有 440 个人的脸(包含有 12240 张人脸),但其中包含有不同人的不同年龄阶段的照片,最小从 3 岁到最大 101 岁时期的照片,每个对象的平均年龄范围为 49 年。作者采用和 LFW 一样的对比验证方式。
最后,作者在网络训练过程中采用了 VGG2 以及 MS1M 作为训练集,选用了 LFW、CPF 以及 AgeDB 作为验证集,最终使用 MegaFace 作为评测标准。
损失层
关于 Loss 对于网络的影响,最直观的就是通过计算 Loss 反传梯度来实现对模型参数的更新,不同的 Loss 可以使模型更加侧重于学习到数据某一方面的特性,并在之后能够更好地提取到这一 “独有” 的特征,因此 Loss 对于网络优化有导向性的作用。
而在近年来人脸识别领域,优化 Loss 对于最终结果的提高有很大的帮助,从 Center Loss 的提出,到 SphereFace,CosineFace,InsightFace 等都有在损失函数这一环节提出新的解决方案,它们的出现对于人脸识别的发展做出了不可磨灭的贡献。
无论是 SphereFace、CosineFace 还是 ArcFace 的损失函数,都是基于传统的 softmax loss 进行修改得到的,所以想要理解 ArcFace,需要对之前的损失函数有一定理解。
Softmax Loss
这是我们传统的 Softmax 公式,其中,
代表我们的全连接层输出,我们在使损失
下降的过程中,则必须提高我们的
所占有的比重,从而使得该类的样本更多地落入到该类的决策边界之内。
而这种方式主要考虑样本是否能正确分类,缺乏类内和类间距离的约束。
在[A Discriminative Feature Learning Approach for Deep Face Recognition]这篇文章中,作者使用了一个比 LeNet 更深的网络结构,用 Mnist 做了一个小实验来证明 Softmax 学习到的特征与理想状态下的差距。
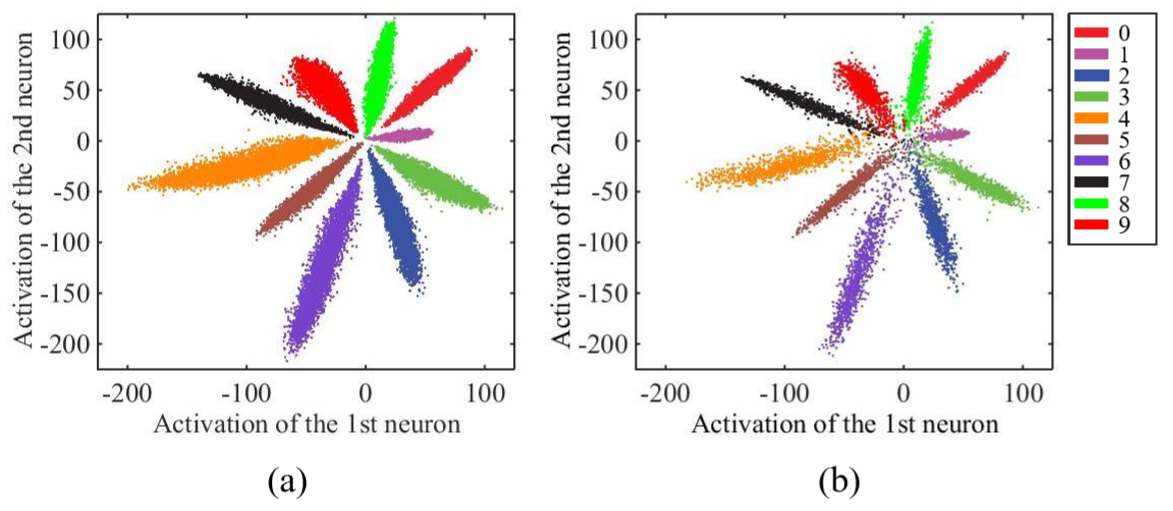
实验结果表明,传统的 Softmax 仍存在着很大的类内距离,也就是说,通过对损失函数增加类内距离的约束,能达到比更新现有网络结构更加事半功倍的效果。于是,[A Discriminative Feature Learning Approach for Deep Face Recognition]的作者提出了 Center Loss,并从不同角度对结果的提升做了论证。
Center Loss
Center Loss 的整体思想是希望一个 batch 中的每个样本的 feature 离 feature 的中心的距离的平方和要越小越好,也就是类内距离要越小越好。作者提出,最终的损失函数包含 softmax loss 和 center loss,用参数λ来控制二者的比重,如下面公式所示:
因而,加入了 Softmax Loss 对正确类别分类的考虑以及 Center Loss 对类内距离紧凑的考虑,总的损失函数在分类结果上有很好的表现力。以下是作者继上个实验后使用新的损失函数并调节不同的参数λλ得到的实验结果,可以看到,加入了 Center Loss 后增加了对类内距离的约束,使得同个类直接的样本的类内特征距离变得紧凑。
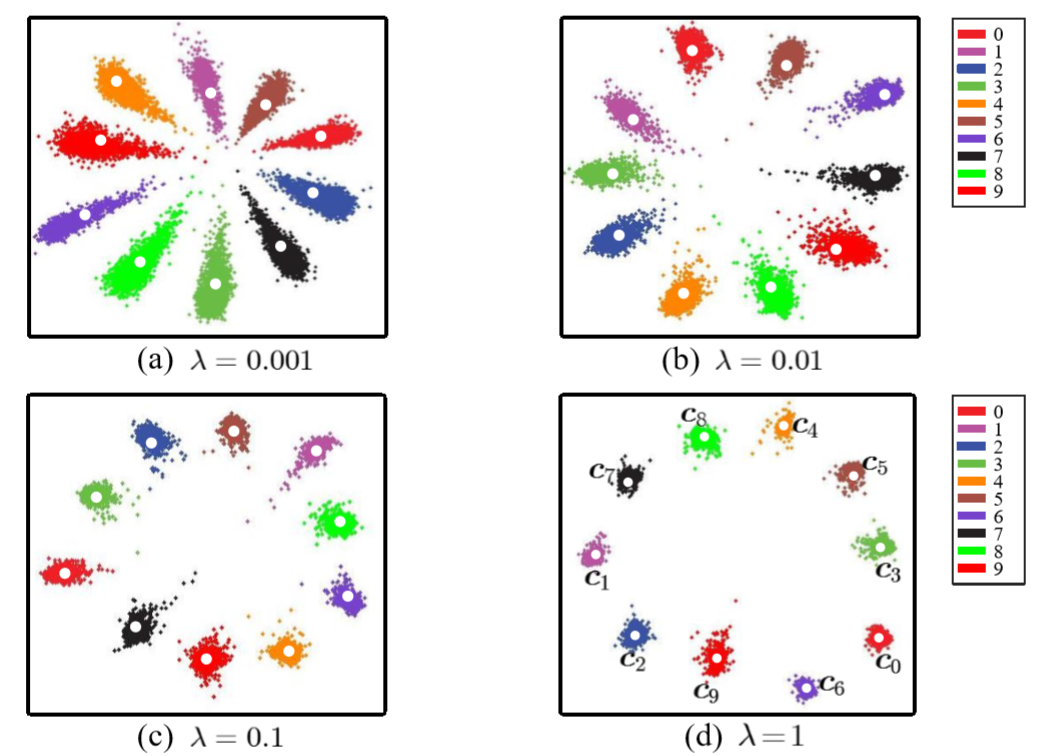
A-Softmax Loss(SphereFace)
Center Loss 的出现,使得人脸识别的研究转向损失函数的改进,对于之前的损失函数,研究发现 Softmax Loss 学习到的特征分辨性不够强,Center Loss 考虑到了使得类内紧凑,却不能使类间可分,而 Contrastive Loss、Triplet Loss 增加了时间上的消耗,[SphereFace: Deep Hypersphere Embedding for Face Recognition]这篇文章的作者提出了 A-Softmax Loss。
在 Softmax Loss 中,由
知,特征向量相乘包含由角度信息,即 Softmax 使得学习到的特征具有角度上的分布特性,为了让特征学习到更可分的角度特性,作者对 Softmax Loss 进行了一些改进。
其中,作者在
中约束了||W||=1并且令 bj=0 , 并将
从
区分出来,就是为了让特征学习到更可分的角度特性。通过这样的损失函数学习,可以使得学习到的特征具有更明显的角分布,因为决策边界只与角相关。
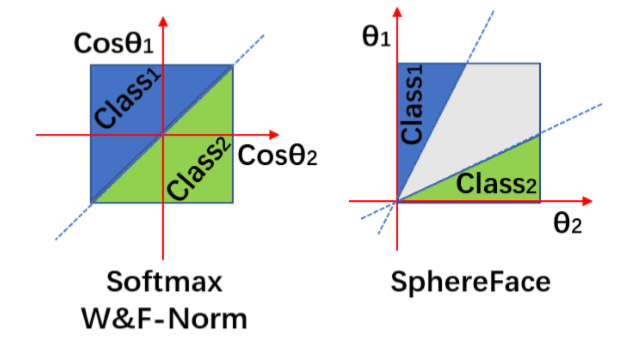
对于 Softmax 而言,希望能有cos(θ1)>cos(θ2),所以作者增加了在角度空间中对损失函数的约束cos(t⋅θ1)>cos(θ2),也就是要把同类数据压缩在一个紧致的空间,同时拉大类间差距。
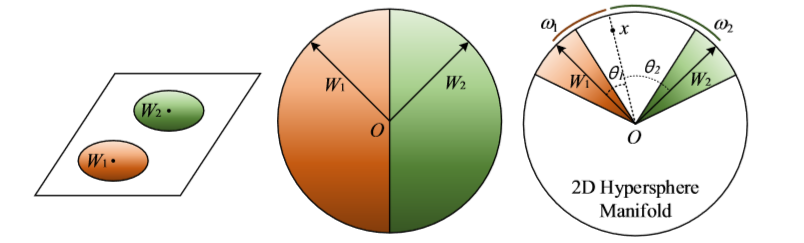
由于cosθ在[0,π]上单调递减,因此θ有上界,为了使得这个函数随角度单调递减,作者构造一个函数去代替cosθ。
在 SphereFace 的实际训练过程中,作者发现引入 Softmax 约束可以保证模型的收敛性。因此,对φ(θyi) 函数做了变更,并同时用参数λ来控制二者的比重。
t的大小是控制同一类点聚集的程度,从而控制了不同类之间的距离。如图可以看出不同的 t 的取值对映射分布的影响(不同的类位于一个单位超球表面的不同区域)
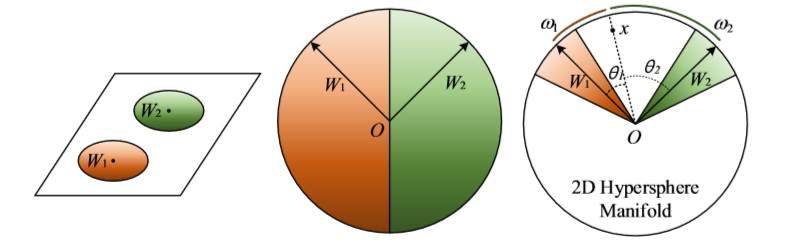
后续的 F-Norm SphereFace 对 SphereFace 做了更新,仅注重从数据中得到的角度信息,而不考虑特征向量的值,所以采用了s=64作为特征归一化参数替代了||x||,因此公式更新为:
而这种采用了 s=64 作为特征归一化参数替代了 ||x||的思想也被 Cosine Loss 和 Arcface Loss 沿用,即相对于距离信息更加关注角度信息。
Cosine Margin Loss
与 SphereFace 相比,CosineFace 最明显的变化就是将cos(t⋅θyi)中的 t 提出来变成cos(θyi)−t,与之前相比,这样有几个明显的优势。
- 相对于 SphereFace 而言要更加容易实现,移除了φ(θyi),减少了复杂的参数计算
- 去除了 Softmax 监督约束,训练过程变得简洁同时也能够实现收敛
- 模型性能有明显的改善
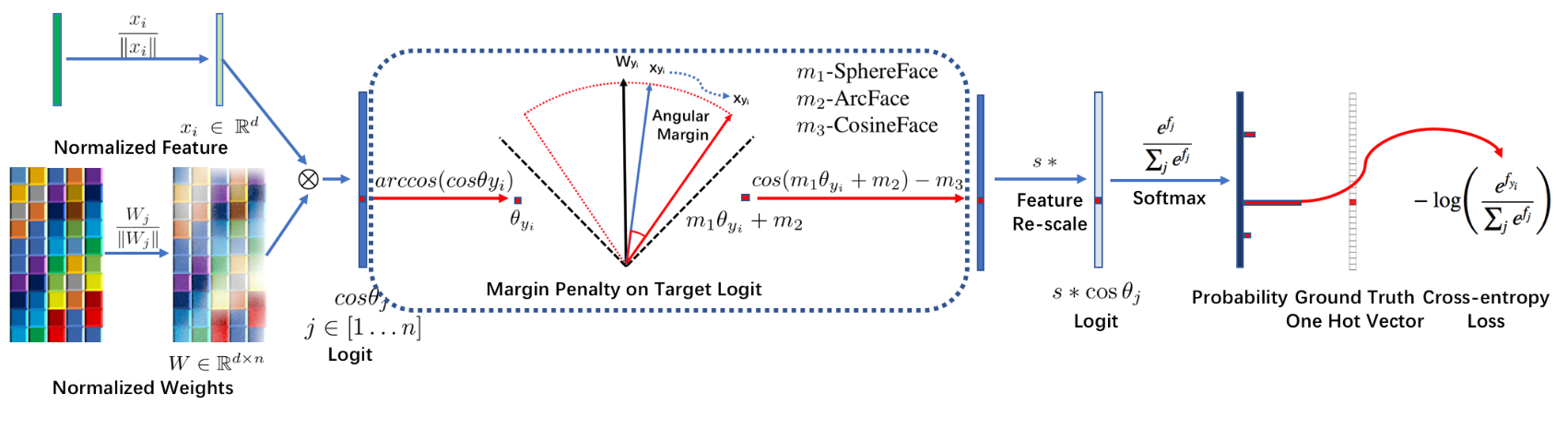
Angular Margin Loss
尽管在余弦范围到角度范围的映射具有一对一的关系,但他们之间仍有不同之处,事实上,实现角度空间内最大化分类界限相对于余弦空间而言具有更加清晰的几何解释性,角空间中的边缘差距也相当于超球面上的弧距。
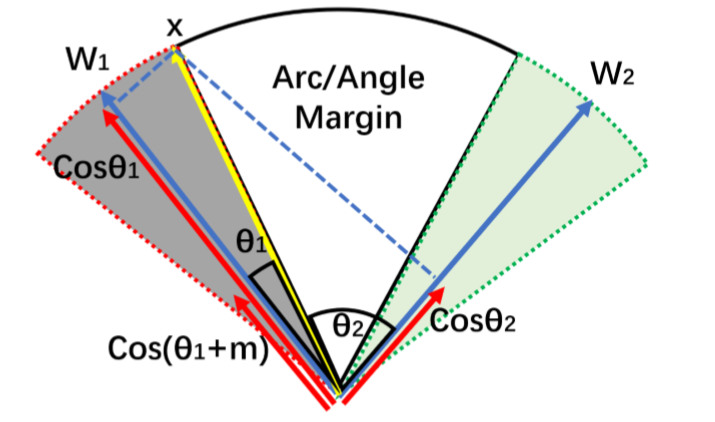
于是,作者提出了 Angular Margin Loss,将角度边缘t置于cos(θ)函数内部,使得cos(θ+t)在θ∈[0,π−t]范围内要小于cos(θ),这一约束使得整个分类任务的要求变得更加苛刻。
对于
,在满足
的情况下,其损失计算公式为
对于
可以得到
,对比 CosineFace 的
,ArcFace 中的
不仅形式简单,并且还动态依赖于
,使得网络能够学习到更多的角度特性。
Loss 对比分析
为了研究 SphereFace、 CosineFace 和 ArcFace 是如何提高人脸识别的效果,作者使用了 LResNet34E-IR 网络和 M1SM 人脸数据集分别使用不同的损失函数对网络进行训练,客观分析了其中的影响。
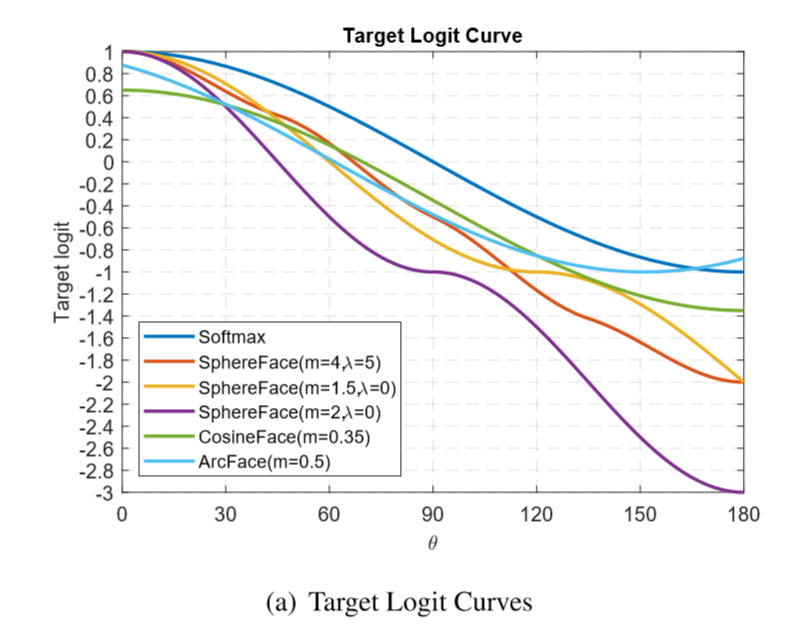
上图的 Target Logit Curve 描绘了随着角度值θ的变化,
对于
, 其中的Target Logit 也就是指
的值,s是归一化参数,在
条件下,
是输入向量与权重在超平面中的夹角,
同理,
对于
来说, Target Logit 对应着
的值,也就意味着,在θ∈[0∘,30∘]时,CosineFace 的曲线要低于 ArcFace,也就是在θ∈[0∘,30∘]范围内 CosineFace 对于网络的 “惩罚” 要大于 ArcFace,再看θ∈[30∘,90∘]范围内 ArcFace 的曲线要低于 CosineFace,也就是说在θ∈[30∘,90∘]内 ArcFace 对于网络的 “惩罚” 要大于 CosineFace(由下面的θ分布图可知θ在 90∘以上范围基本没有,可以忽略)。
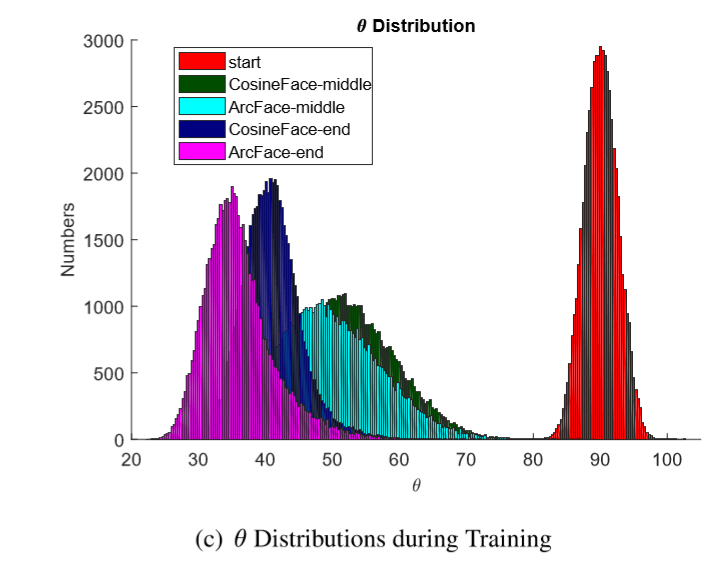
而作者提供了训练开始时,中间以及收敛后的θ的分布图,可以看到,在网络收敛的情况下,ArcFace 和 CosineFace 的θ分布基本在[30∘,60∘]范围内,同时,ArcFace 和 CosineFace 的θ中心值要更靠左一点,虽然在θ∈[0∘,30∘]范围内 CosineFace 对于网络的 “惩罚” 要大于 ArcFace,但是由最终结果可以看出,收敛时θθ达到[0∘,30∘][0∘,30∘]范围内的数量很少,相对于[30∘,60∘]范围内可以忽略,而在 ArcFace 对于网络的 “惩罚” 要大于 CosineFace 的θ∈[30∘,60∘]范围内分布着绝大多数的θ。
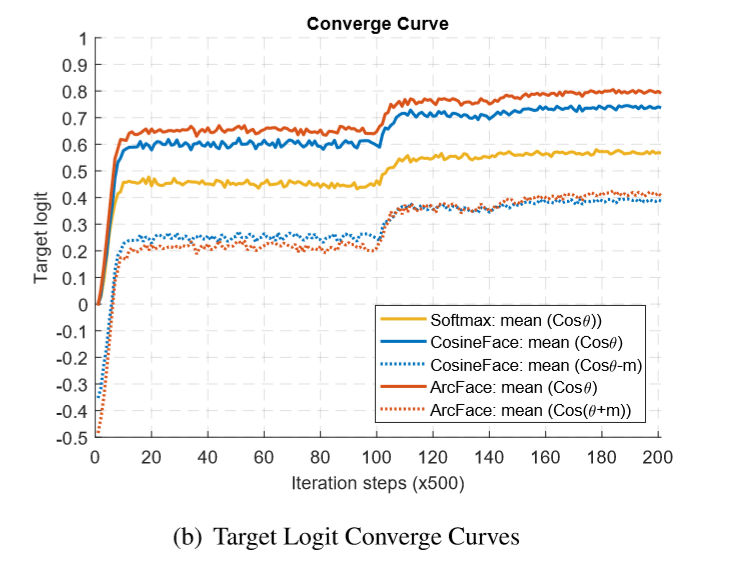
我们已经由θ的分布图可知在收敛的时候 ArcFace 的θ中心值与 CosineFace 相比要偏左一点,同时,由上图可知,收敛的时候红色实线要高于蓝色和黄色实线,也就意味着,收敛的时候 ArcFace 相对于其他 Loss 使得同一类更加 “紧凑”,相对于其他的 Loss 实现了将同一个类压缩到一个更紧致的空间,更密集,使得网络学习到的特征具有更明显的角分布特性。
网络
为了衡量怎样的网络更适合人脸识别,作者在基于 VGG2Face 作为训练集和使用 Softmax 作为损失函数的情况下对 Resnet 网络做了不同的设置,以期望能达到最好的效果。
作者用了 8 块特斯拉 P40 的显卡,设置训练时的总的 Batch Size 为 512,同时学习率从 0.1 开始在分别在 10 万、14 万、16 万次迭代下降一个量级,设置了总的迭代为 20 万次,momentum 动量为 0.9,权值衰减为 5e−4 。
PS:实验表明采用权值衰减值为 5e−4 效果最好。
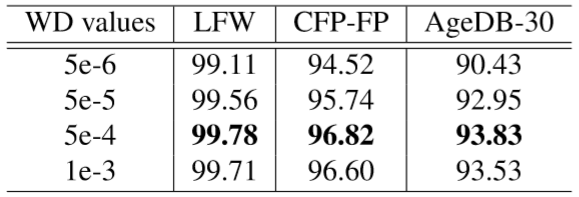
Input selects L
大多数的卷积神经网络为完成 Image-Net 的分类任务而设计的,所以网络会采用 224x224 的输入,然而作者所用的人脸大小为 112x112,如果直接将 112x112 的数据作为预训练模型的输入会使得原本最后提取到的特征维度是 7x7 变成 3x3,因此作者将预训练模型的第一个 7x7 的卷积层(stride=2)替换成 3x3 的卷积层(stride=1),这样第一个卷积层就不会将输入的维度缩减,因此最后还是能得到 7x7 的输入,如下图所示,实验中将修改后的网络在命名上加了字母 “L”,比如 SE-LResNet50D。
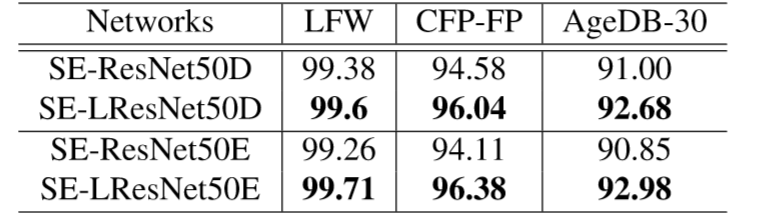
Output selects E
对于网络的最后几层,不同的输出可能会影响模型的性能,因此作者对 Option-A 到 Option-E 分别做了测试,在测试过程中,利用两个特征向量对距离进行计算。在识别与验证的过程中采用了最近邻与阈值比较法。
- Option-A: Use global pooling layer(GP).
- Option-B:Use one fullyconnected(FC) layer after GP.
- Option-C: Use FC-Batch Normalisation (BN) after GP.
- Option-D: Use FC-BN-Parametric Rectified Linear Unit (PReLu) after GP.
- Option-E: Use BN-Dropout-FC-BN after the last convolutional layer.
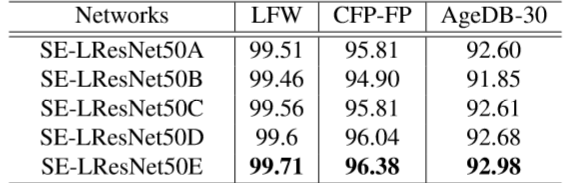
经过对比结果得知,使用 Option-E 模型能取得更好的表现。
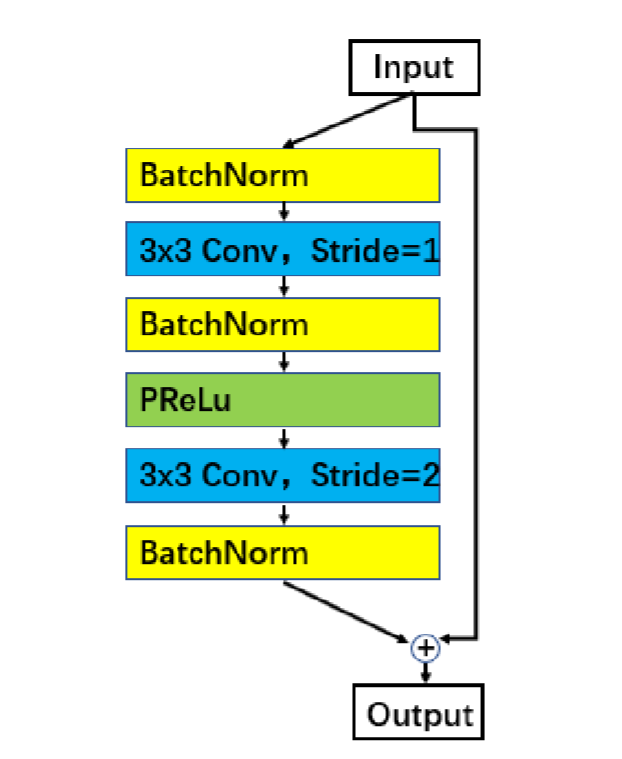
Block selects IR
作者改善了 Resnet 网络的残差块使其更适合人脸识别模型的训练,采用 BN-Conv-BN-PReLu-Conv-BN 结构作为残差块,并在残差块中将第一个卷积层的步长从 2 调整到 1,激活函数采用 PReLu 替代了原来的 ReLu。采用修改过的残差块的模型作者在后面添加了 “IR” 以作为标识。
同样实验表明,采用 Option-E 与改善后的残差块使得模型表现有明显的提升。

Network Setting Conclusions
综上所述,最终在 Resnet 网络上做出了 3 项改进,第一是将第一个 7x7 的卷积层(stride=2)替换成 3x3 的卷积层(stride=1),第二是采用了 Option-E 输出,第三是使用了改善后的残差块。
评估
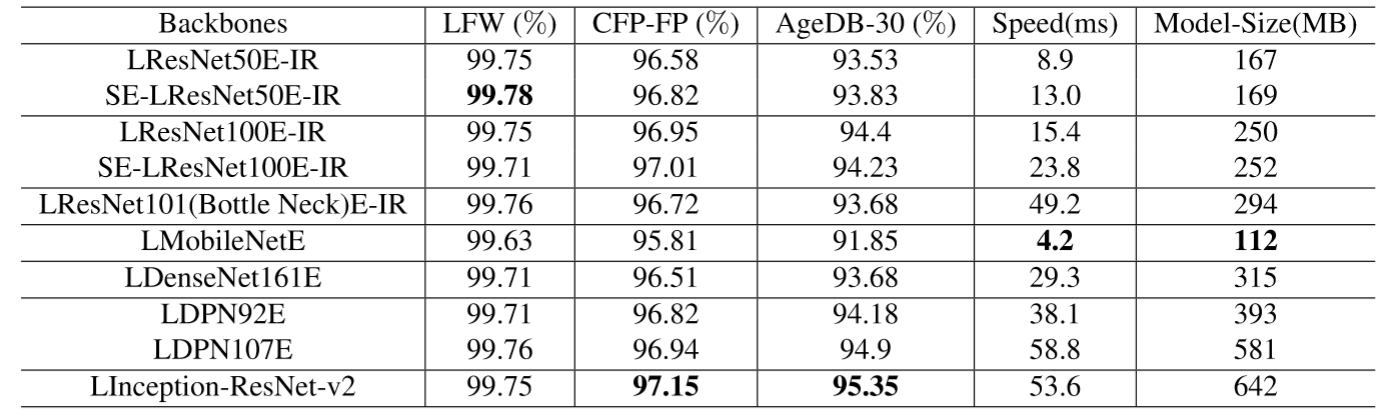
作者同时对比测试了其他主流的网络结构,有 MobileNet、Inception-Resnet-V2、DenseNet、Squeeze and excitation networks (SE) 以及 Dual path Network (DPN),评价的标准由精确度、速度以及模型大小组成。
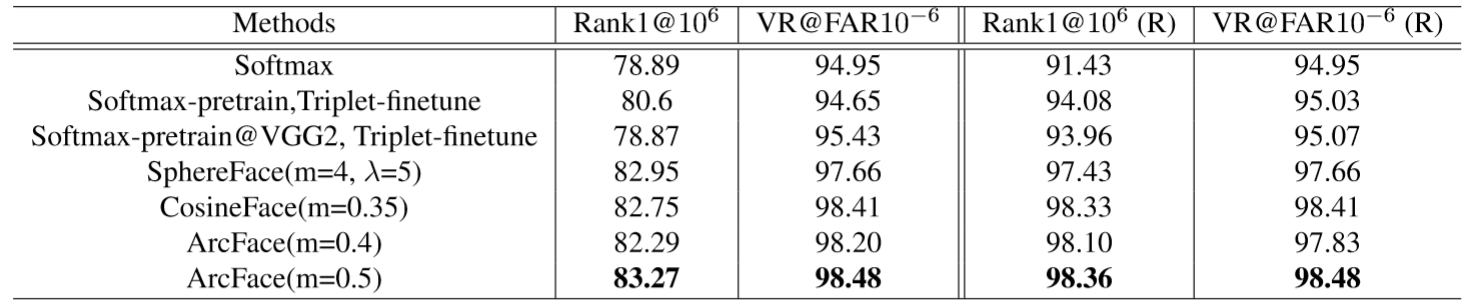
同时,MegaFace 作为百万规模级别的面部识别算法的测试基准,作者以 LResNet100E-IR 作为网络结构,以 MS1M 作为训练集,分别对比了不同损失函数在 MegaFace 上的表现,其中最后两列括号中有 “R” 是代表清洗过的 MegaFace,Rank1 指标代表第一次命中率,VR@FAR 代表在误识率 FAR 上的 TAR,也就是说第一次命中率 Rank1 越高越好,VR@FAR 越高越好。

若有收获,就点个赞吧
0 人点赞
