Abstract.
随着汽车驾驶的发展,对距离测量的要求也越来越高。传统的距离估算方法需要根据摄像机的内部和外部参数进行复杂的校准。基于神经网络结构的最新方法主要测量整个图像的相对深度。我们采用实例分割和相机焦距的单眼视觉技术来检测前置摄像头与车载摄像头的绝对距离。首先,我们从物体检测网络中提取汽车的位置。其次,将汽车的位置发送到汽车分类网络和实例分割网络,以获取汽车的类型及其掩码值。在这里,我们使用由CompCars数据集训练的模型对汽车类型进行分类,并使用Cityscapes数据集训练新的实例细分模型以获得每辆汽车的遮罩。第三,根据照相机成像原理,基于不同类型的汽车的尺寸信息与其遮罩值之间的关系来计算图像中汽车的绝对距离。通过KITTI数据集对提出的方法进行了检验,实验表明该方法的结果可以接近地面真实性。此外,该方法利用实例分割网络来降低深度估计过程的复杂度,即使在部分遮挡汽车的情况下,仍然可以产生令人满意的结果。
1 Introduction
汽车的普及推动了智能汽车的发展。 随着机器视觉的发展,机器很可能以与人类相同的方式从图像中检索信息。 越来越快的R-CNN1,2和全卷积网络(FCN)3框架在对象检测和语义分割方面取得的成就提高了检测的准确性和速度。 它们为自动驾驶带来了良好的视野。 基于这项技术,当前的研究旨在从车载摄像机的视频中检测前车的深度。
在汽车驾驶需求的推动下,从将单眼/双眼视觉中的几何关系应用于深度学习框架或基于三维(3-D)图像重建来测量深度,开发了距离测量方法。4 在现有主流方法中,距离测量大致可分为五种类型。
较早的方法依赖于深度学习和网络体系结构。5-10这些方法尝试使用多尺度卷积网络体系结构粗略地估计深度,并使用网络中的各种改进措施来估计深度图。
每个对象都具有深度信息的特征,并且与其他特征具有某种关系。 深度信息和语义分割都是图像到图像的转换。 深度信息有多个联系与语义分割信息。 语义分割的许多方法都可以直接使用深度预测。11,12深度信息可以看作是从远到近的分层问题,因此可以视为距离的渐进分类。
使用深度学习网络架构进行深度估计并不是一种新颖的方法。 使用条件随机场(CRF)方法获得的效果已显示出极好的结果。 CRF在语义分割方面已显示出相当大的成功。 它使用条件概率建模来锐化由卷积神经网络(CNN)回归生成的模糊图像。 受CRF的启发,出现了将CNN与CRF结合的方法。 它使用条件概率建模来生成CNN深度图的回归。
在无限制设置的情况下,无法使用深度传感器获得深度信息。 人类不擅长估计度量深度或3-D度量结构; 此外,从单个图像恢复度量深度的结果因人而异。 但是,人类擅长判断相对距离。 这些方法着重于图像中各点之间的关系,并通过训练每个图像中标记的两个点之间的相对深度来预测深度图。
我们上面解释的大多数深度估计方法都被视为监督学习问题。 尽管这些方法在深度估计方面取得了很大的成功,但它们仅限于场景较大的场景它们相应的像素深度可用。 一种称为无监督学习的方法被用于深度估计。23–26该方法训练左右图像之间的视差损失,使CNN能够通过深度与视差之间的关系学习图像深度估计,而无需使用深度数据的GT 。
深度估计的方法试图直接预测图像中每个像素的深度,结果由深度图显示。 但是,这些方法存在两个问题:(1)它们可以获得相对深度而不是绝对距离;(2)深度信息包括多余的部分,例如天空,远处的建筑物和林木,它们具有 在交通场景中对距离测量的影响很小。
由于效率高,传统的目标检测被深度学习方法所取代。 在本文中,我们受到基于深度学习的深度估计方法的启发,并尝试通过深度学习方法在实际交通场景中为驾驶员反映车辆的绝对距离。 车载摄像机进行距离估计的主要困难在于目标检测的准确性以及使用适合于交通场景的距离测量算法的可行性。
为了解决这些问题,我们将距离估计与实例分割相结合,并利用每个汽车的尺寸信息与其分段蒙版值之间的关系来计算汽车的绝对距离,同时降低了距离估计过程的复杂性。
2 Method
我们的方法概述如图1所示。首先,将整个图像用作输入,目标检测部分使用区域提议网络(RPN)融合提议和CNN分类,并实现完整的 端CNN目标检测模型,不仅可以加快目标检测速度,而且可以提高目标检测性能。 由对象检测网络获得的车辆位置的相应信息被发送到车辆分类网络和分割网络。 其次,车辆分类网络根据他们先前通过物体检测网络检测到的位置确定车辆类型和尺寸信息。 同时,分割网络会基于对象检测网络先前检测到的位置,使用完整的CNN进行像素级分割,从而获得每辆车的遮罩。 最后,根据摄像机成像的原理,我们利用摄像机焦距以及分类和分割网络中的反馈信息来计算每辆车的绝对深度。
2.1 Designed Module of Instance Segmentation
在此,提出一种结合深度估计的图像分割方法。 提出的方法对目标检测到的车辆进行分割,并获取其像素级掩码以供以后的深度计算。 图像分割的主要方法可以分为两类。
2.1.1 From R-CNN to mask R-CNN
2.1.2 Methods based on FCN
传统的基于CNN的分割方法通常使用像素周围的图像块作为CNN输入进行训练和预测,以获得像素分类,但是检测效率不高。 FCN3的外观已实现了从图像级别分类到像素级别分类的进一步扩展。 随着FCN在图像分割中的发展趋势,逐渐形成了一种基于FCN的改进分割网络。 在获得像素分类并考虑图像中的空间信息之后,方法29,30通过使用完全连接的CRF获得了精细的分割结果。 提出了实例敏感得分图的概念,以与FCN31和首个端到端全卷积实例分割相结合.
在这项研究中,我们使用最新的实例分割网络掩码R-CNN作为分割网络,并重新训练了汽车的分割模型,以确保在此过程中没有检测到多余的物品。
掩码R-CNN基于更快的R-CNN。 更快的R-CNN对每个目标对象都有两个输出:分类分支和边界框分支(图2)。 遮罩R-CNN继承了更快的R-CNN的体系结构,但是它包括第三个输出,即遮罩分支,用于提取对象的详细空间布局。 遮罩R-CNN可以解决即时分割问题,也可以检测和描绘图像中每个不同的关注对象。 即时分割是两个子问题的组合。 首先是对象检测,这是在图像中查找和分类可变数量的对象的问题。 即时分割的第二部分是语义分割,这是对像素级别的图像的理解,也就是说,他们希望将对象类别分配给图像中的每个像素此信息对于特定于位置的任务(例如创建对象蒙版)至关重要。
在预测的图像中,边界框是通过对象检测创建的,而遮罩是语义分割的输出。 掩码R-CNN使用类似于更快的R-CNN的体系结构进行对象检测。 更快的R-CNN结合了使用RPN的注意力机制,并分两个阶段执行对象检测。 第一阶段确定边界框,并因此通过RPN确定感兴趣的区域。 第二阶段使用RoI池来确定每个RoI的类标签。 对于掩模R-CNN,它在第二阶段使用RoIAlign而不是RoI池,这比RoI池执行得更好,因为它允许保留每个感兴趣区域的空间像素到像素对齐。 遮罩R-CNN使用像素到像素对齐输出对象遮罩。 掩码R-CNN使用完全卷积网络来预测每个RoI的掩码,因为卷积层保留了空间方向。
与更快的R-CNN相比,掩码R-CNN具有三个优点。 首先,掩膜R-CNN使用ResNeXt-101将特征金字塔网络(FPN)33作为特征提取网络,从而增强了网络基础。 其次,它将RoIPool替换为RoIAlign,以解决由直接池化采样引起的不对齐问题。 第三,掩码R-CNN可以独立预测每个类别的二进制掩码。 每个二进制掩码的分类取决于网络RoI分类分支给出的分类预测,因此不会引起类之间的竞争。 对于损失函数,掩码R-CNN在每个采样的RoI上将多任务损失定义为L¼LclsþLboxþLmask(图3)。 分类损失Lcls和边界框损失Lbox在参考资料中定义。 1,掩膜损耗Lmask在参考文献1中定义。
如参考文献中所述。 如图28所示,遮罩R-CNN在实例分割中取得了出色的性能。 传统方法使用二维(2-D)边界框进行对象检测,但无法检测对象的细节。 我们的方法使用掩码R-CNN进行实例分割,因为语义分割基于具有细粒度分割的像素级,而不仅是二维边界框的粗略位置。 解决了FCIS中重叠对象分割不准确的问题。 它是2017年COCO的赢家。在实际交通情况下,存在大量重叠。 因此,我们选择遮罩RCNN作为我们的实例分割网络,以确保正确的距离检测。
2.2 Designed Module of Vehicle Type Detection
2.3 Designed Module of Absolute Distance
我们的方法基于单眼视觉和图像分割,还依赖于相机的固有参数fx和fy(以像素为单位的焦距)来实现距离估计。 我们将焦距(以像素为单位)与真实物体的大小结合起来,可以使用其在图像空间中的大小来估计物体的距离。 我们采用一种具有新方法的网络体系结构来解决过程中存在的绝对深度估计和冗余项的问题。 图6显示了基于相机成像原理的深度估计模型。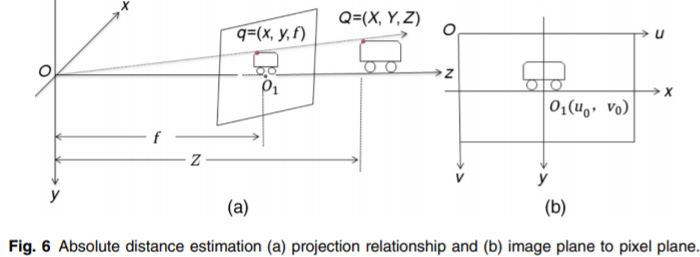
根据相机成像原理,我们的方法使用相机焦距fx的像素面积与真实面积之间的关系; 可以测量距离。

若有收获,就点个赞吧
0 人点赞
