论文原文:《Stereo R-CNN based 3D Object Detection for Autonomous Driving》
CVPR2019 新文,主要讲述应用双目视觉实现的 3D 目标检测。本文将 3D 目标检测问题归纳为一个在深度学习辅助下的几何学问题(而非一个端到端的预测任务),不需要深度信息或 3D 点云信息作为输入。在 KITTI 数据集上,与其他基于图像的方法相比,表现最好。甚至能与基于激光雷达的方法相媲美。
主要贡献:1. 提出 Stereo R-CNN,在关联双目图像的同时进行目标检测。2. 提出一种 3D 边界框估计器,根据关键点和双目 2D 边界框得到 3D 边界框。3. 提出 Dense Alignment,一种基于密集区域的双目匹配对齐方法,使得目标在三维空间中的定位更加精确。
虽然题目是 3D 目标检测,但本文主要针对的检测目标是车辆。论文中的所有示意图、解决方案、实验都是基于车辆的 3D 检测设计和实现的。
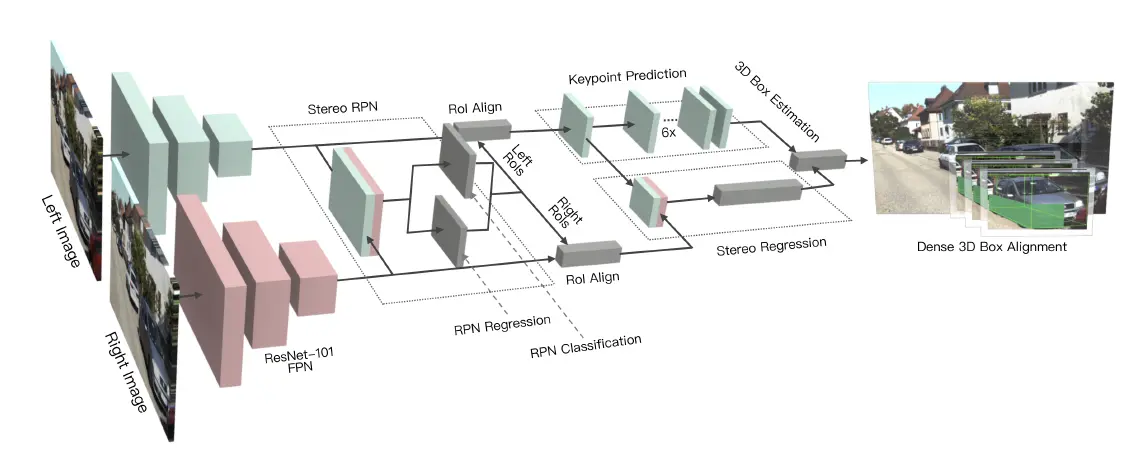
网络结构
首先由一对共享权重的 ResNet-101 FPN 提取特征。
然后分为三个主要模块:
1.Stereo RPN:基于双目图像改进的 RPN 网络,对双目图像分别预测 RoI 建议。改进点在于 Stereo RPN 考虑了双目图像之间的相关性。
2.Stereo Regression:基于 Stereo RPN 提出的 RoI,对目标进行分类,并对双目图像回归更精确的边界框、dimension(三维空间尺寸)、viewpoint(视角),以作为构建 3D 边界框的预备信息。
3.Keypoint Detection:定义了一系列帮助构建 3D 边界框的关键点。预测这些关键点的位置。
整理 Stereo Regression 和 Keypoint Detection 模块的输出,得到 3D 边界框。
(RPN:Faster R-CNN 首次提出的,基于滑动窗口的前景检测网络。为后续的分类和边框回归提供初始 RoI)
FPN 骨干网络特征提取后,双目图像的两张特征图在通道上被拼接在一起,并通过 3×3 卷积降低特征图的通道数,其后连接 RPN ,形式为两个全连接层,一个分支用于回归 RoI 位姿参数,另一个分支用于分类 RoI 中是否有目标。
Stereo RPN 提出了一个考虑双目图像中同一目标 RoI 相关性的预测方法:用一个涵盖左图中的 RoI GT 和右图中的 RoI GT 的 anchor 作为联合 GT。检测 RoI 中是否有目标,是对这个联合 GT 而言的。训练细节:和 Faster R-CNN 相同,在训练中,如果一个 anchor (人为设置的先验框)与联合 GT 的 IoU 达到 0.7,则记为正样本(有目标);如果一个 anchor 与任何联合 GT 的 IoU 都未达到 0.3,则记为负样本(无目标)。

黄框:联合 GT,绿框:左图 GT,红框:右图 GT
同一目标在双目图像中的水平坐标一般是不同的。不过,得益于联合 GT 的设计,一个被预测为有目标的 anchor,在双目图像中往往也能够涵盖目标。在针对单张图片的目标检测任务中,需要预测 4 个变换系数以对 RoI 的位姿做出修正,但在双目图像中,所需的变换系数并非 8 个而是 6 个,因为基于双目成像原理,在双目摄像头已校正的情况下,同一目标在双目图像中具有相同的纵向坐标以及相同的高度,所以总共有 6 个自由度。Stereo RPN 的边框回归分支预测 6 个变换系数
以从联合 GT 变换得到
中心点横坐标(左图)、宽度(左图)、中心点横坐标(右图)、宽度(右图)、中心点纵坐标(左右图)、高度(左右图)
。目前还在目标检测阶段,所以这些坐标都是在图像坐标系内的。
在预测时,分别对左图和右图中的 RoI 做非极大值抑制。如果一个目标的左右 RoI 皆被保留,则保留之。取被保留的 RoI 中,置信度最高的 2000 组作为 RPN 的输出。
(注:采用了与 FPN 类似的结构,在每个不同的尺度层级的特征图上评估和预测 anchor)
Stereo RPN 得到了左右成对的 RoI。对这些 RoI 做 RoI-Align 操作(RoI-Align:Mask R-CNN 中提出的,在亚像素上对 RoI 内容进行池化的操作,目的在于尽可能保留原始的空间信息。是 RoI Pooling 的改进),然后将左右特征图在通道上拼接,并通过两组全连接层以提取语义信息。
双目回归
用四个子支路分别预测目标类别、双目 2D 边界框、三维尺寸、视角。
目标类别预测:基本的分类问题。
双目 2D 边界框:边界框参数和 Stereo RPN 中相同,即
六个参数,不同之处在于左图基于左 RoI 变换,右图基于右 RoI 变换,不过这并不影响左右图使用相同的
,它们仍然符合双目成像原理。这和一系列基于 Fast R-CNN 的方法类似,都是在 RPN 提出的 RoI 建议上,通过语义信息进一步得到更准确的边界框。
dimension:目标在实际三维空间内的长、宽、高。dimension 的预测形式为,预测目标 dimension 到一个预设的先验值的偏移量。在后面还原 3D 边界框时会用到。
视角:表示目标的朝向。需要注意的是,此处定义的 “视角” 并不能唯一地还原出目标在三维空间中的朝向。如下图所示,根据摄像机的成像原理,这些不同朝向的目标在图像上具有相同的像。尽管这些像的位置不同可以作为估计其真实朝向的依据,但 RoI 中的内容已经被裁剪,只能反映局部信息,所以原理上无法令双目回归模块输出目标真实的朝向,目标的真实朝向需在后续模块中得出。此处定义的视角为
,
为目标中心到摄像头的连线与 z 轴方向的夹角,
为目标的真实朝向,即前方与 z 轴方向的夹角。角度在某些情况下是不连续的,所以实际预测目标为
而非
的角度值。
(此处有个小问题:有些目标根本没有明显的 “正面” 存在,比如路灯、花坛,这些东西的朝向怎么定义?虽然定义也没什么意义,毕竟这篇论文是针对无人驾驶的,而识别一个目标的正面也是为了预测它的轨迹,路灯和花坛本身也不会动,预测载具和行人的朝向才有实际意义)
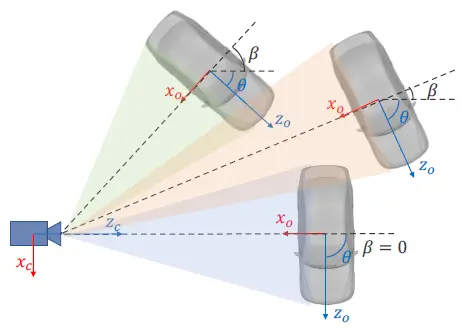
不同朝向(θ)的目标,有相同的视角(α=β+θ)
训练细节:和 Faster R-CNN 类似,在训练 RPN 后面这部分时,先由(训练好的) RPN 提出 RoI 建议区域,再进行语义网络的训练数据的采样。在采样 RoI 时,若左 RoI 与目标在左图上的 GT 的 IoU 达到
,且右 RoI 与目标在右图上的 GT 的 IoU 达到
,则认为这对 RoI 为前景。如果上述两者中任一方落在 )
)
区间内,则认为这对 RoI 为背景。不采用 IoU 都在
以下的 RoI ,是出于抛弃 Simple Example 的考虑,因为正样本比较少,为了均衡正负样本,这些对梯度贡献低的简单负样本是最先被抛弃的。
关键点检测
作者观察到,3D 边界框的 8 个角点中,差不多能投影到 2D 边界框中间的某个角点,能提供很多的 3D 位姿信息。预测这个点在 2D 边界框上的位置,能够为还原 3D 边界框提供很大帮助(即绘画中常提到的透视)。
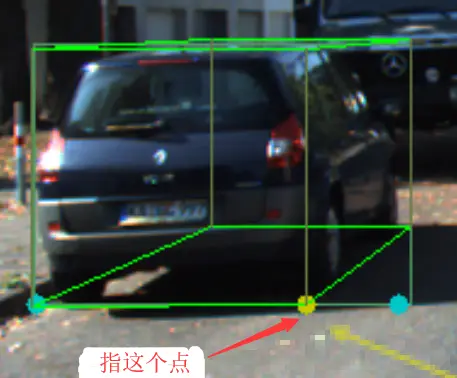
Perspective Keypoint
作者定义了 4 个三维语义关键点,为目标的 3D 边界框底部的 4 个角点。那么,对于一个目标而言,它的这 4 个关键点中最多有一个能像上面说的那样,在可见的情况下投影到 2D 边界框中间。这个关键点在二维图像上的投影记为透视点(Perspective Keypoint)。
另外还定义了一对边界关键点(Boundary Keypoint),以替代目标的像素分割级 Mask,只有在两个边界关键点之间的内容才被认为是属于目标的。
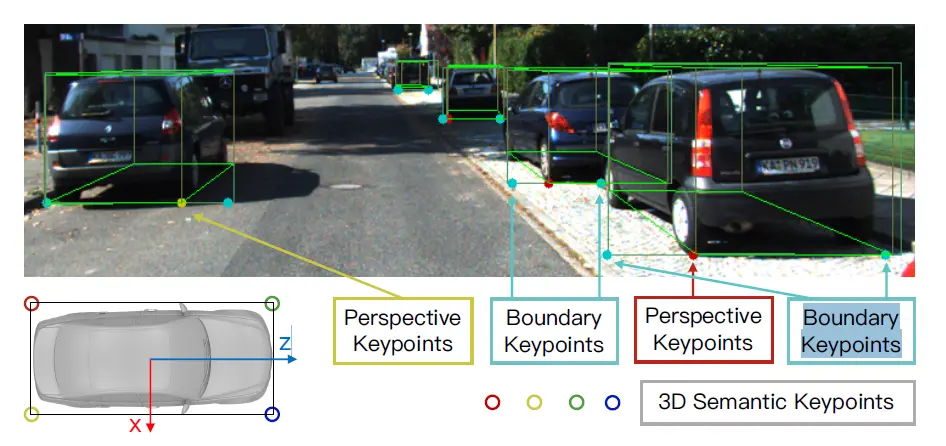
三维语义关键点
透视点如何贡献于 3D 边界框估计,边界关键点之间所决定的内容如何被应用,这些在后面会谈。但现在先讲它们的位置预测。4 个三维语义关键点用于还原 3D 边界框,2 个边界关键点用于更精细地分割目标,总共有 6 个关键点需要预测。
关键点的预测方法与 Mask R-CNN 中预测人体关键点的原理相同(Mask R-CNN 的 Mask 预测支路,实质为对每个特征像素进行二分类,所以同样可以应用于关键点预测)。为了保证关键点的唯一性,只使用左图 RoI 进行预测。将左图 RoI 经过 RoI Align 得到的特征图(14×14)通过六个连续的 256 通道的 3×3 卷积层,以 ReLu 作为激活函数,末尾使用 2×2 反卷积层将输出上采样至 28×28。
按说在 2D 图像上预测 6 个关键点 heatmap,需要 6×28×28 的输出形状。不过,4 个三维语义关键点中,只有透视点是重要的,而透视点总是位于 2D 边界框的底部;2 个边界点也只需要确定它们中间夹住的内容。基于如上考虑,关键点的纵坐标意义不大,所以将 6×28×28 的输出图在纵向上相加得到 6×28 的输出,仅预测关键点的横坐标。前 4 个通道对应 4 个三维语义关键点,因为实际上只有一个关键点(透视点)能够在图像上观测到,它理应是置信度最高的。为了防止模型对各个关键点的混淆,对整个 4×28 的输出通道应用一次 softmax 激活,以激励模型只输出一个关键点位置,即透视点。另外两个 1×28 的通道对应两个边界关键点,都能被观测到,所以分别用 softmax 激活。
训练细节:对于 4 个三维语义关键点,4×28 标签中只有一个点(透视点)被标记为目标点,如果出于某些遮挡或透视原因导致没有透视点能被观测到,则不进行标记。训练时,最小化对整个 4×28 输出的交叉熵损失函数。对于 2 个边界关键点, 分别最小化每个通道上的交叉熵。
其实我感觉,三维语义关键点中,既然标注只标注透视点,也只预测一个关键点,那为什么不将这个 4 通道的输出直接改成 1 通道呢?如果这么做没问题,那么原文里的做法就是有一点小冗余的?不过从另外的角度想,四个关键点对应车辆的不同位置,如果在通道上分开,也许能够有助于语义信息的提取。
前面做的工作,都是在图像坐标系下的。因为是 3D 目标检测任务,还需要还原出目标在实际三维空间内的位姿。这一步先还原出一个较粗糙的 3D 边界框。
已经有了回归得到的
,那么还需要估计的变量为
,分别为 3D 边界框的中心坐标和朝向与
轴的夹角。用到了七个上面已经得到的参数
——分别表示图像坐标系上左图边界框的左、右、顶、底边,右边界框的左、右边,透视点的横坐标——以估计 3D 边界框的这四个变量。
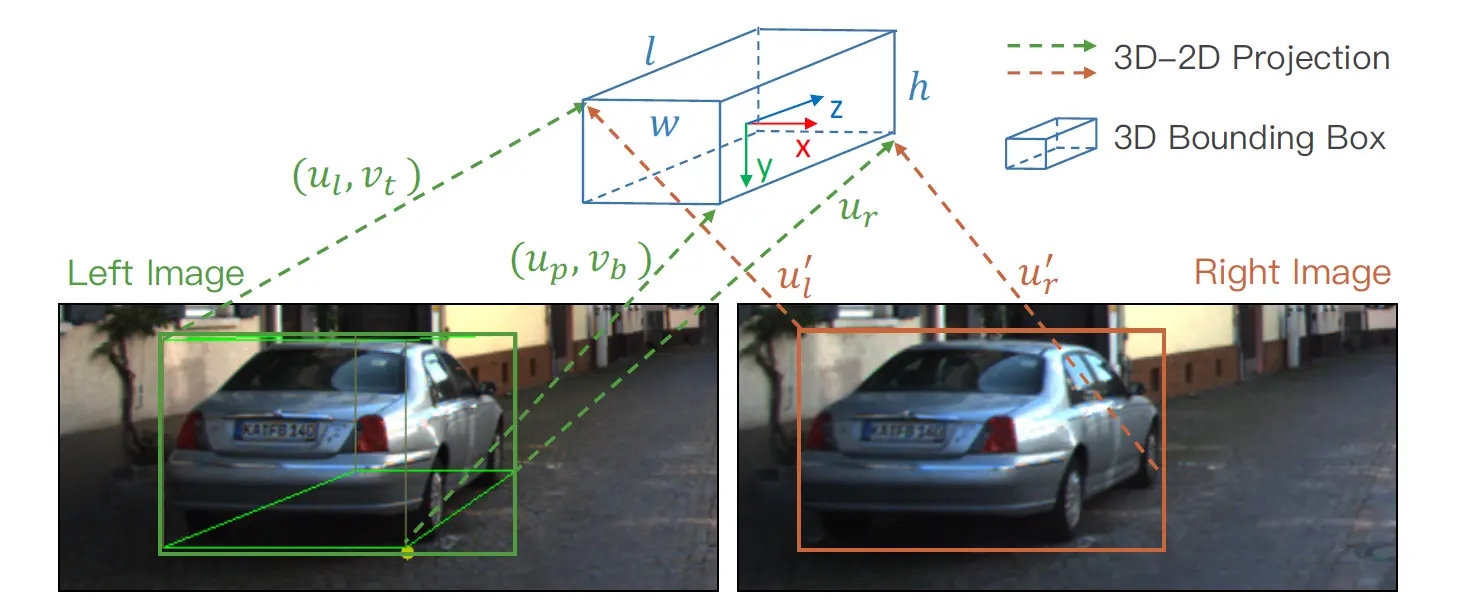
3D 边界框估计
给出 2D-3D 投影变换的公式:
 %20%2F%5Cleft(z-%5Cfrac%7Bw%7D%7B2%7D%20%5Csin%20%5Ctheta-%5Cfrac%7Bl%7D%7B2%7D%20%5Ccos%20%5Ctheta%5Cright)%20%5C%5C%20u%7Bl%7D%20%26%3D%5Cleft(x-%5Cfrac%7Bw%7D%7B2%7D%20%5Ccos%20%5Ctheta-%5Cfrac%7Bl%7D%7B2%7D%20%5Csin%20%5Ctheta%5Cright)%20%2F%5Cleft(z%2B%5Cfrac%7Bw%7D%7B2%7D%20%5Csin%20%5Ctheta-%5Cfrac%7Bl%7D%7B2%7D%20%5Ccos%20%5Ctheta%5Cright)%20%5C%5C%20u%7Bp%7D%20%26%3D%5Cleft(x%2B%5Cfrac%7Bw%7D%7B2%7D%20%5Ccos%20%5Ctheta-%5Cfrac%7Bl%7D%7B2%7D%20%5Csin%20%5Ctheta%5Cright)%20%2F%5Cleft(z-%5Cfrac%7Bw%7D%7B2%7D%20%5Csin%20%5Ctheta-%5Cfrac%7Bl%7D%7B2%7D%20%5Ccos%20%5Ctheta%5Cright)%20%5C%5C%0A…%5C%5C%20u_%7Br%7D%5E%7B%5Cprime%7D%20%26%3D%5Cleft(x-b%2B%5Cfrac%7Bw%7D%7B2%7D%20%5Ccos%20%5Ctheta%2B%5Cfrac%7Bl%7D%7B2%7D%20%5Csin%20%5Ctheta%5Cright)%20%2F%5Cleft(z-%5Cfrac%7Bw%7D%7B2%7D%20%5Csin%20%5Ctheta%2B%5Cfrac%7Bl%7D%7B2%7D%20%5Ccos%20%5Ctheta%5Cright)%20%5Cend%7Baligned%7D%5C%5C#align=left&display=inline&height=260&margin=%5Bobject%20Object%5D&originHeight=260&originWidth=900&status=done&style=none&width=900)
%20%2F%5Cleft(z-%5Cfrac%7Bw%7D%7B2%7D%20%5Csin%20%5Ctheta-%5Cfrac%7Bl%7D%7B2%7D%20%5Ccos%20%5Ctheta%5Cright)%20%5C%5C%20u%7Bl%7D%20%26%3D%5Cleft(x-%5Cfrac%7Bw%7D%7B2%7D%20%5Ccos%20%5Ctheta-%5Cfrac%7Bl%7D%7B2%7D%20%5Csin%20%5Ctheta%5Cright)%20%2F%5Cleft(z%2B%5Cfrac%7Bw%7D%7B2%7D%20%5Csin%20%5Ctheta-%5Cfrac%7Bl%7D%7B2%7D%20%5Ccos%20%5Ctheta%5Cright)%20%5C%5C%20u%7Bp%7D%20%26%3D%5Cleft(x%2B%5Cfrac%7Bw%7D%7B2%7D%20%5Ccos%20%5Ctheta-%5Cfrac%7Bl%7D%7B2%7D%20%5Csin%20%5Ctheta%5Cright)%20%2F%5Cleft(z-%5Cfrac%7Bw%7D%7B2%7D%20%5Csin%20%5Ctheta-%5Cfrac%7Bl%7D%7B2%7D%20%5Ccos%20%5Ctheta%5Cright)%20%5C%5C%0A…%5C%5C%20u_%7Br%7D%5E%7B%5Cprime%7D%20%26%3D%5Cleft(x-b%2B%5Cfrac%7Bw%7D%7B2%7D%20%5Ccos%20%5Ctheta%2B%5Cfrac%7Bl%7D%7B2%7D%20%5Csin%20%5Ctheta%5Cright)%20%2F%5Cleft(z-%5Cfrac%7Bw%7D%7B2%7D%20%5Csin%20%5Ctheta%2B%5Cfrac%7Bl%7D%7B2%7D%20%5Ccos%20%5Ctheta%5Cright)%20%5Cend%7Baligned%7D%5C%5C#align=left&display=inline&height=260&margin=%5Bobject%20Object%5D&originHeight=260&originWidth=900&status=done&style=none&width=900)
其中
为双目摄像机(经校正后的)基线长度。总共 7 个等式,总之都是简单的坐标变换运算,摄像机成像原理的基本内容,也懒得补全了… 嗯。因为等式多于待求变量,所以这是一个最小拟合问题,采用高斯 - 牛顿法即可求解,最小化的指标为得到的 3D 边界框再投影到图像坐标系上的重投影误差。如果某些情况导致透视点没有被观测到,则引入约束条件 #align=left&display=inline&height=42&margin=%5Bobject%20Object%5D&originHeight=42&originWidth=189&status=done&style=none&width=189)
#align=left&display=inline&height=42&margin=%5Bobject%20Object%5D&originHeight=42&originWidth=189&status=done&style=none&width=189)
进行补偿(
是视角,前面已经预测过了)。
前面的 3D 边界框估计,是通过 2D 边界框的一些参数推断的,而 2D 边界框本身是从一个 7×7 的 RoI 内的特征图推理出来的,在多层的卷积过程中,语义信息被提取与保留,而像素级精度的位置信息已经部分丢失了。为了得到在亚像素级别上准确的 3D 边界框匹配结果,需要再次从原图里提取辅助信息。Dense Alignment 的主要目的是得到更精确的 3D 边界框中心点的视差,因为应用了密集的像素级信息,所以这个方法被冠以 Dense 之名。
将一个目标视为长方体,在 3D 边界框估计的过程中解出该长方体的中心点坐标,则 RoI 中某一像素点与中心点的深度之差
能够很容易地得到。另外,为了排除非目标的像素,在 2D 图像上,保留两个边界关键点(边界关键点的位置前面已经预测过了)中夹住的内容,并且取靠近 RoI 底部的一半,作为 “有效 RoI”(原因:此方案针对车辆。车辆的底盘比车篷宽,RoI 的下半边往往能被底盘占满,非目标的像素更少。所以这里是直接把车的下半边看作一个长方体了)。对于一个在有效 RoI 内,归一化后坐标为 #align=left&display=inline&height=26&margin=%5Bobject%20Object%5D&originHeight=26&originWidth=62&status=done&style=none&width=62)
#align=left&display=inline&height=26&margin=%5Bobject%20Object%5D&originHeight=26&originWidth=62&status=done&style=none&width=62)
的像素
而言,定义其双目匹配误差为:
 -I%7Br%7D%5Cleft(u%7Bi%7D-%5Cfrac%7Bb%7D%7Bz%2B%5CDelta%20z%7Bi%7D%7D%2C%20v%7Bi%7D%5Cright)%5Cright%5C%7C%5C%5C#align=left&display=inline&height=65&margin=%5Bobject%20Object%5D&originHeight=65&originWidth=900&status=done&style=none&width=900)
-I%7Br%7D%5Cleft(u%7Bi%7D-%5Cfrac%7Bb%7D%7Bz%2B%5CDelta%20z%7Bi%7D%7D%2C%20v%7Bi%7D%5Cright)%5Cright%5C%7C%5C%5C#align=left&display=inline&height=65&margin=%5Bobject%20Object%5D&originHeight=65&originWidth=900&status=done&style=none&width=900)
其中,
为左图和右图上的三通道像素值,
为像素点
与 3D 边界框中心的深度之差,
为基线长度。
是唯一需要被优化的决策变量。在右图上,通过双线性插值计算亚像素点的像素值。总的匹配误差表示为:

解出令
最小化的
,以此校正整个 3D 边界框。
与一般的双目匹配方法(如 SGM)相比,在 Dense Alignment 中目标 RoI 是一个在图形上具有约束能力的整体,所以能够自然地避免空间不连续点造成的误匹配问题。并且此方法能够很容易地迁移到其它基于图像的 3D 目标检测问题。
https://www.jianshu.com/p/9bea02b43299

若有收获,就点个赞吧
0 人点赞
