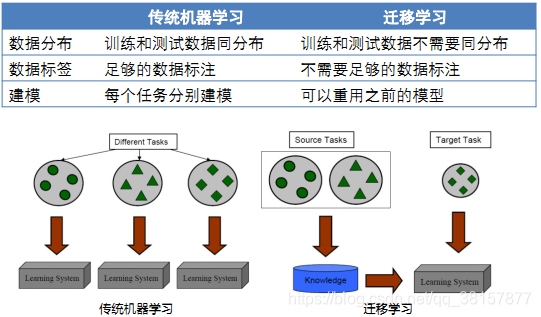
在机器学习、深度学习和数据挖掘的大多数任务中,我们都会假设 training 和 inference 时,采用的数据服从相同的分布(distribution)、来源于相同的特征空间(feature space)。但在现实应用中,这个假设很难成立,往往遇到一些问题:
- 1、带标记的训练样本数量有限。比如,处理 A 领域(target domain)的分类问题时,缺少足够的训练样本。同时,与 A 领域相关的 B(source domain)领域,拥有大量的训练样本,但 B 领域与 A 领域处于不同的特征空间或样本服从不同的分布。
- 2、数据分布会发生变化。数据分布与时间、地点或其他动态因素相关,随着动态因素的变化,数据分布会发生变化,以前收集的数据已经过时,需要重新收集数据,重建模型。
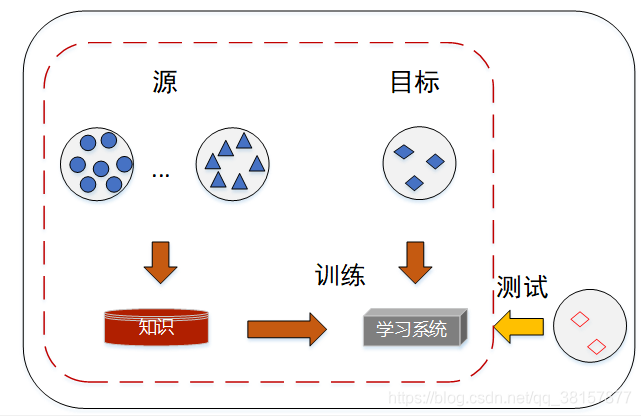
这时,知识迁移(knowledge transfer)是一个不错的选择,即把 B 领域中的知识迁移到 A 领域中来,提高 A 领域分类效果,不需要花大量时间去标注 A 领域数据。迁移学习,做为一种新的学习范式,被提出用于解决这个问题。
迁移学习的研究来源于一个观测:人类可以将以前的学到的知识应用于解决新的问题,更快的解决问题或取得更好的效果。迁移学习被赋予这样一个任务:从以前的任务当中去学习知识(knowledge)或经验,并应用于新的任务当中。换句话说,迁移学习目的是从一个或多个源任务(source tasks)中抽取知识、经验,然后应用于一个目标领域(target domain)当中去。
自 1995 年以来,迁移学习吸引了众多的研究者的目光,迁移学习有很多其他名字:学习去学习(Learning to learn)、终身学习(life-long learning)、推导迁移(inductive transfer)、知识强化(knowledge consolidation)、上下文敏感性学习(context-sensitive learning)、基于知识的推导偏差(knowledge-based inductive bias)、累计 / 增量学习(increment / cumulative learning)等
其目标是将某个领域或任务上学习到的知识应用到不同的但相关的领域或问题中。例如学习 C++ 的技能可以用来学习 java
利用相关领域的知识完成目标领域的任务
数据的标签很难获取;从头建立模型是复杂和耗时的
迁移学习放宽了传统机器学习训练数据和测试数据服从独立同分布这一假设,从而使得参与学习的领域或任务可以服从不同的边缘概率分布或条件概率分布。
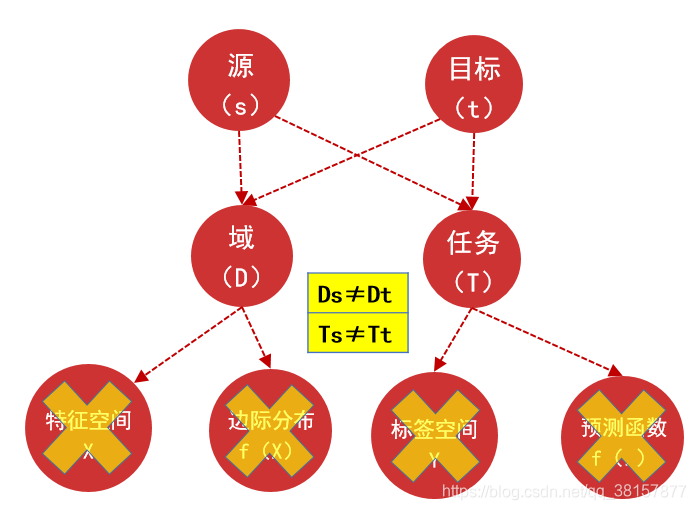
域(domain)
用 D={χ,P(X)} 表示,它包含两部分:特征空间χ和边缘概率分布 P(X)其中 X={x1,…xn}∈χ
在文本分类任务中,把每一个单词看作二值的特征即出现或者不出现,所有检索词向量的空间就是χ,xi 对应某一文本第 i 个词向量的值,X 就是特定的学习样本。如果说两个数据域不同,表示两个数据域的特征空间或者边缘概率分布不同。
任务(task)
用 T={У,ƒ(X)} 表示,它包含两部分:标签空间У和目标预测函数ƒ(X),ƒ(X)也可以看作条件概率 P(y|x)
在文本分类任务中У是所有标签的集合。
数学定义:
给出源领域的数据 Ds 和任务 Ts,目标领域的数据 Dt 和任务 Tt,迁移学习旨在使用源领域 Ds 和 Ts 中的知识去改进对于目标领域的预测函数ƒt(),其中 Ds≠Dt 或者 Ts≠Tt
由于 **D={χ,P(X)}, 在上述的定义中 Ds≠Dt 意味着 χs≠χt 或者 Ps(X)≠Pt(X)**。
在文本分类任务中,这两种情况分别意味着在源文本集和目标文本集之间,词特征不同(两个文本使用两种不同语言的情况)以及边缘分布不同。
类似的,由于 **T={У,ƒ(X)},Ts≠Tt意味着 Уs≠Уt或者 Ps(y|x)≠Pt(y|x)。**
在文本分类任务中,这两种情况分别意味着源领域上的任务要求将文本分为 **2 类,目标领域的任务要求将文本分为 10** 类,以及在定义的类别上,源数据和目标数据数量不平衡。
根据源领域和目标领域的相似度,可以将情况总结如下:
| |
Ds&Dt
|
Ts&Tt
|
|
传统机器学习
|
相同
|
相同
|
|
迁移学习
|
归纳式迁移学习
|
相同 / 相关
|
相关
|
|
无监督迁移学习
|
相关
|
相关
|
|
直推式迁移学习
|
相关
|
相同
|
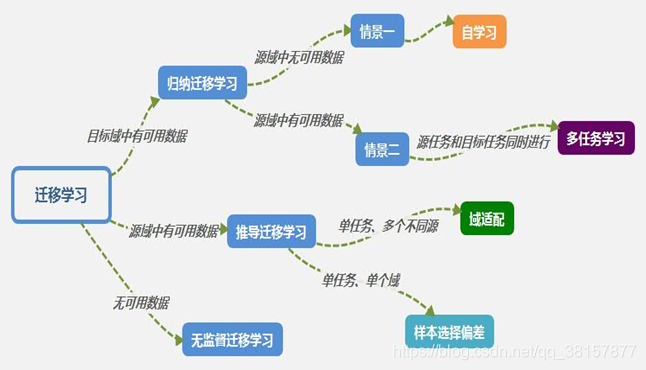
根据每一种类型的迁移学习,又可根据标签数据的多少分情况讨论:
- 归纳式迁移学习
- 源数据域包含有大量标签数据,这时归纳式迁移学习和多任务学习类似。
- 源数据域没有可用的标签数据,这时归纳式迁移学习相当于自我学习。
- 直推式迁移学习
a. 特征空间不同χs≠χt
b. 特征空间相同χs=χt 但是边缘分布不同 Ps(X)≠Pt(X),此时可用域适应,样本选择偏差和 Covariate Shift。
- 无监督迁移学习
总结如下表:
| |
相关领域
|
源数据域标签
|
目标数据域标签
|
任务
|
|
归纳式迁移学习
|
多任务学习
|
有
|
有
|
分类回归
|
|
自我学习
|
无
|
有
|
分类回归
|
|
直推式迁移学习
|
域适应,样本选择偏差和 Covariate Shift
|
有
|
无
|
分类回归
|
|
无监督迁移学习
| |
无
|
无
|
聚类降维
|
依据迁移知识的形式可将迁移学习分为:基于实例的迁移学习;基于特征的迁移学习;基于模型的迁移学习;基于关系的迁移学习。
|
迁移学习方法
|
方法描述
|
|
基于实例的迁移学习
|
基于实例的迁移学习方法适用于源域和目标域相似度较高的情况。主要思想是:通过改变样本的存在形式来减少源域和目标域的差异。
|
|
基于特征的迁移学习
|
基于特征的迁移学习算法可应用在域间相似度不太高的甚至不相似的情况。主要思想是:通过特征变换将源于和目标域在某个特征空间下表现出相似的性质。
|
|
基于参数的迁移学习
|
基于参数的迁移学习方法从模型的角度出发,共享源域模型与目标域模型之间的某些参数达到迁移学习的效果。
|
|
基于关系的迁移学习
|
基于关系的迁移学习是通过将两个域之间的相关性知识建立一个映射来达到迁移学习的效果。
|
根据源与目标的样本空间和标记空间的一致性可将迁移学习分为同构迁移学习与异构迁移学习。
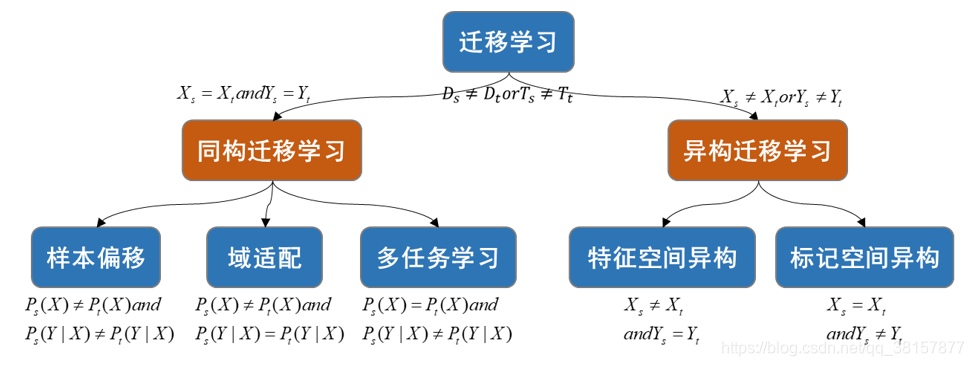
当源和目标的样本空间和标记空间一致时称为同构迁移学习;当样本空间和标记空间中只要有一个不一致时称为异构迁移学习。
- 国内外发展现状
归纳式迁移学习
基于实例的迁移:主要思想就是在目标领域的训练中,虽然源数据域不能直接使用,但是可以从中挑选部分,用于目标领域的学习。
1.TrAdaBoost 算法是 AdaBoost 的提升版本,用于解决归纳式迁移学习问题。它假设源数据域和目标数据域使用相同的特征和标签集合,但是分布不相同。有一些源数据对于目标领域的学习是有帮助的,但是还有一些是无帮助甚至是有害的。所以它迭代地指定源数据域每一个数据的权重,旨在训练当中减小 “坏” 数据的影响,加强 “好” 数据的作用。
- 使用启发式的方法,根据条件概率 P(Yt|Xt)和 P(Ys|Xs)的差异,去除源数据域中 “不好” 的样本。
基于特征表示的迁移:主要思想是寻找一个 “好” 的特征表示,最小化域间差异和分类回归的误差。可以分为有监督和无监督两种情况。
有监督特征构造的基本思想是学习一个低维的特征表示,使得特征可以在相关的多个任务中共享,同时也要使分类回归的误差最小。此时目标函数如下:
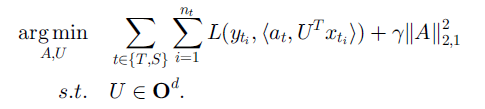
其中 S 和 T 表示源域和目标域,U 是将高维的数据映射为低维表示的矩阵。
无监督特征构造的基本思想包含两步,第一步在源领域上学习一个基向量 b 和基于这组基对于输入 x 的新的表示 a
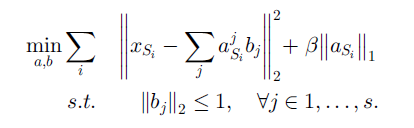
在得到基向量 b 之后,第二步在目标领域上根据基向量 b 来学习其特征表示
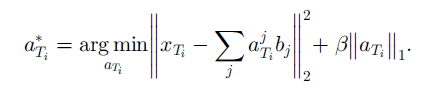
最后通过使用目标领域的新特征来训练分类回归模型。
基于参数的迁移:参数迁移方法假定在相关任务上的模型应该共享一些参数、先验分布或者超参数。
多任务学习中多使用这种方法,通过将多任务学习对于源域和目标域的权值做改变(增大目标域权值,减小源域权值),即可将多任务学习转变成迁移学习。
基于相关性的迁移:和前三种方式不同,相关知识迁移方法在相关域中处理迁移学习的问题,它不假设每一个域的数据都是独立同分布的,而是将数据之间的联系从源域迁移到目标域。
直推式迁移学习
基于实例的迁移: 直推式迁移学习因为任务相同,所以可以直接使用源域上的损失函数。在源域上最小化目标函数如下
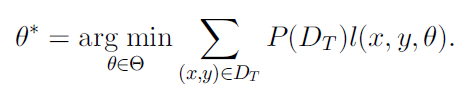
但是由于目标域数据是没有标签的,所以取而代之使用源域的数据,如果 Ds 和 Dt 分布相同,可以直接使用
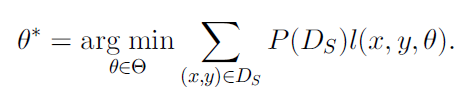
否则,就不能简单的使用 Ds,而是需要通过转化,对于每一个样本增加一个权值
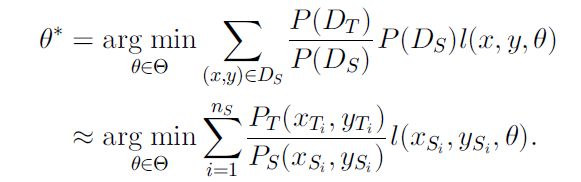
此时需要计算
因为直推式迁移学习任务相同的假设,Ps(y|x)=Pt(y|x),可得出
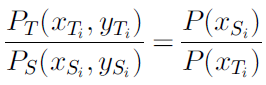
接下来只要计算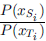
就可以解决直推式迁移学习问题。
基于特征表示的迁移: 大多数特征表示迁移方法都基于非监督学习。SCL 算法,使用目标域的无标签数据提取一些相关特征从而减小两个域之间的差异。SCL 算法第一步在两个域的无标签数据上定义一个 pivot 特征集合(包含 m 个 pivot 特征),然后把一个 pivot 特征看作一个标签
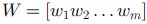
最终通过学习得到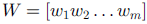
,第三步将 W 矩阵做奇异值分解从而形成增广特征。
无监督迁移学习
基于特征表示的迁移: 无监督迁移学习的研究工作较少,在无监督迁移问题上通常通过自我聚类以及 TDA(Transferred Discriminative Analysis) 算法来聚类和降维。
自我聚类的目标是基于源域无标签数据的帮助,来对目标域无标签数据聚类,通过学习跨域的共同的特征空间,帮助目标域的聚类,目标函数如下:
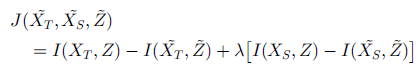
其中 Z 是共享的特征空间,I 计算两个量之间的互信息,最终要使得聚类过后损失的互信息最小。
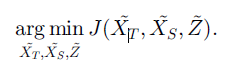
- 多源迁移学习
多源迁移学习是指迁移学习过程中,源域的个数不止一个,通过适量的增加源域的个数可以有效避免负迁移现象的发生。目前多源迁移学习的成熟算法可分为两类:基学习器加权法,特征表示法。图 1.14 为多源迁移学习示意图。
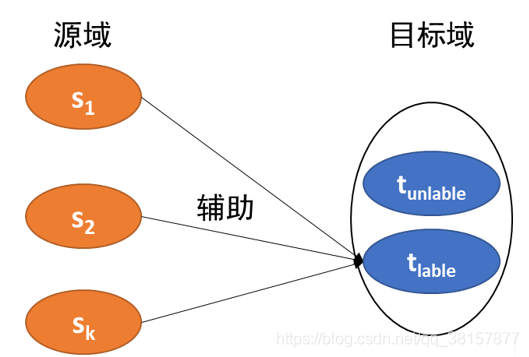
- 基于实例的多源迁移学习
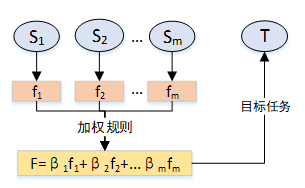
- 基于特征的多源迁移学习
- 研究学者
- 未来的发展趋势
第一, 针对领域相似性、共同性的度量,目前还没有深入的研究成果,未来还需要确定更加准确的度量方法。第二,在算法研究方面,迁移学习的应用范围很广。迁移学习多用于分类算法方面,其他方面的应用算法有待进一步研究。比如情感分类、强化学习、排序学习、度量学习、人工智能规划等。第三,关于可迁移学习条件,获取实现正迁移的本质属性还没有完全摸透,如何避免负迁移,实现迁移的有效性也是方向之一。
- 技术难点
负迁移是一个重要的技术难点。负迁移表示目标域训练中源域数据的使用不仅没有提升模型能力,反而降低了识别率的现象。尽管实际当中如何避免负迁移现象是很重要的问题,但是在这个问题上的研究依然很少,经验表明如果两个任务太不相似,那么鲁莽的强制迁移会损害性能。目前已有一些对任务和任务之间聚类的探索,旨在对如何自动避免负迁移提供指导。
另外在非简单分类或者回归的问题上,如何更好地优化迁移算法,以达到适合任务的最佳效果,也是一个难点。在不同的应用背景下,迁移学习是否适合以及需要做怎样的改进都是值得去考虑的。
https://blog.csdn.net/qq_38157877/article/details/88651075

若有收获,就点个赞吧
0 人点赞
