关键词:
1、介绍
在过去的十几年中,随着汽车的普及以及互联网的发展,自动驾驶汽车吸引了包括学术界和工业界的极大关注。对自动驾驶的研究正在迅速发展。 而车距估计是自动驾驶的关键技术之一。
当前对车辆距离的估计方法主要包括激光雷达测距,微波雷达测距,超声波测距和视觉测距等。LiDAR能够准确地检测3D信息,但是感知范围相对较短(〜100 m),具有几个激光束的数据的相对稀疏分辨率以及设备的高昂价格。微波雷达[19]也可以准确提供目标车辆的距离信息,但是,高成本和数据收集仍然是限制其使用的关键问题。超声波传感器的检测范围较短,通常只有30米。相比之下,摄像机更便宜且分辨率更高,因此它成为车辆距离估计的重要手段。
基于机器视觉测量距离方法主要分为单眼视觉和双眼视觉。单眼视觉系统结构简单,成本低,适用范围广。但是仍然存在精度低,长距离测量结果误差大,应用场景范围狭窄等问题。与单眼视觉系统相比,立体视觉系统通过左右光度对齐提供了更精确的深度信息。 与LiDAR相比,立体相机价格低廉,同时对于具有非凡差异的物体也可达到相当的深度精度。 立体摄像机的感知范围取决于焦距和基线。 因此,立体视觉具有通过组合具有不同焦距和基线的不同立体模块来提供更大范围感知的潜在能力。为此,我们提出了一种基于立体视觉的3D对象检测车距估计方法。
在这项工作中,我们改进了[6]中的车辆检测方法,并利用了深度卷积神经网络和KITTI数据集[11]的优势来训练3D检测网络。我们通过充分利用立体图像中的语义和几何信息来研究3D车辆对象。我们的方法使用改进的Stereo R-CNN3D检测网络获得车辆的实际信息和投影信息。由此 通过区域距离几何模型, 将上面提取的车辆信息用作模型的输入,最后,通过测距模型获得车辆的距离值。
我们将主要贡献总结如下:
- 为了综合平衡距离估计系统的效率和精度,我们利用深度学习网络框架,提出了一种基于双目视觉的车距估计模型。
- 利用深度学习网络,提出了一种基于双目视觉的车辆尺寸估计网络。
- 改进了基于Stereo R-CNN的3D目标检测方法,可更好的同时检测和关联立体图像中的车辆对象。
利用立体图像的优势,通过关键点、立体框约束和光度对齐方法,可确保我们的3D车辆定位精度。- 通过KITTI数据集的评估显示,我们的性能优于所有基于单目视觉的的车距估计方法。
2、相关工作
通过视觉测距获得在前方车辆的距离的过程主要包括以下两个步骤:首先,目标检测,在图像中找到要检测的车辆。 其次,使用真实世界和图片中的目标车辆位置进行车辆测距。 可见目标检测的准确性直接影响车距的估计。
根据维度,当前的目标检测网络分为2D检测和3D检测。当下流行的2D目标检测网络中,诸如faster-rcnn、yolo4、ssd通过2D边界框指示目标在图像中的位置和以及类别。而mask-rcnn可以获得更详细的投影轮廓,并且减少了冗余。这些2D检测方法的检测结果非常优秀[40],但它们只能显示图像中对象的位置,大小和分类,不能反映物体的3D姿态。在自动驾驶的应用场景中,获取图像中车辆的3D形状和信息至关重要。因此,车辆3D检测是当前的研究热点。
当前已经有不少优秀的3D车辆检测网络提出来了。[6]提出了LaserNet,一种从LiDAR数据进行3D对象检测以实现自动驾驶的高效计算方法,精确度非常高。[8]提出了一种立体视觉的3D对象检测方法,该方法不依赖LiDAR数据作为输入或训练中的监督,而仅采用带相应注释的RGB图像3D边界框作为训练数据,模型是一个不需要多个阶段或后处理算法的端到端学习框架。 [7]利用一个独立的模块将输入数据从2D图像平面转换到3D点云空间,以获得更好的输入表示,然后使用PointNet骨干网执行3D检测以获得对象的3D位置,尺寸和方向。[3]提出了多视图3D网络(MV3D),一种融合了LIDAR点云和RGB图像作为输入并预测定向3D边界框的感觉融合框架。[4]提出了基于单个RGB图像的高效3D对象检测框架,利用现成的2D对象检测器提取2D图像中的基础3D信息]。[5]提出了一种基于立体R-CNN的3D对象检测方法,利用立体相机通过左右光度对齐提供深度信息。针对目标检测的正确率和设备的性价比的一个权衡,本文选择了[5]。
当前,使用视觉进行车距测量,已经提出了很多算法和模型,但绝大多数都是基于单目视觉。【29】【2】通过检测出车身宽度,通过相似三角形原理来计算车距。【3】【6】则是通过检测出车牌宽度来达到这一目的。【5】根据车牌实际高度和像素高度比例计算车距。【17】【23】根据检测到的车辆的位置和道路消失点来估算与其前部车辆之间的距离。【11】采用实例分割,根据照相机成像原理,基于不同类型的汽车的尺寸信息与其遮罩值之间的关系来计算图像中汽车的距离。【12】通过角度回归模型(ARN)获取目标车辆的姿态角信息,尺寸估算网络确定目标车辆的实际尺寸。然后,根据图像解析几何原理设计二维基本矢量几何模型,以准确地恢复目标车辆的后方区域。最后,基于摄像机投影原理进行区域距离建模以估计距离。【14】使用车辆3D检测方法获得目标车辆后部的实际区域和图像中的相应投影区域。然后,使用测距几何模型估计车辆之间的绝对距离。然而针对双目车距测量而提出的算法模型依然十分有限。
3、系统模型
3.1. System Overview
2D检测测距方法中存在问题的主要原因是未考虑车辆的3D尺寸以及方向角。 在实际的交通场景中,目标车辆是立体的。 如果目标是规则的,则可以用一个真实的3D矩形框来表示。 因此,车辆的投影部件在不同的驾驶状态下,应该表现出与实际场景一对一的投影关系。 然而,如图1(a)所示,由2D检测框提供的车辆投影信息没有表现出与实际车辆信息的对应投影关系。 如果认为投影关系相同,则使用该投影关系进行距离估计会增加测距结果的绝对误差.
此外,在严重遮挡和远距离情况下,传统的2D目标检测方法还存在车辆召回率低的问题。 因此,我们无法获得被遮挡和远距离车辆的投影信息。 这种情况导致整个测距系统的测距范围和适用性都受到很大限制。 这个问题在实际交通场景中至关重要。 本文所提出的3D检测方法可以解决上述的2D检测方法的问题。 它不仅可以确保检测结果的准确性并提高召回率,而且可以非常准确获得车辆的3D尺寸以及方向角。
综上所述,我们设计的双目3D车距估计系统框架如图所示:首先,将双目相机获取的左右图像输入到训练好的车辆特征提取网络中,利用得到的左右特征图,通过迁移学习训练获得的深度卷积神经网络获取目标车辆的真实3D尺寸,同时通过改进的stereo rcnn网络获取目标车辆的精确3D框信息,最后,根据[19福大]面积-距离几何模型,使用车辆实际尺寸以及3D投影框来计算车辆后部的实际面积和投影面积,以此估计车辆之间的距离。提出的距离估计系统是一个完整的端到端测距框架,该框架结合了对象分类,对象3D框和对象绝对距离值。它不仅可以加快测距速度,而且可以提高测距性能和检测结果。~~ 3D候选区域采用[6]中3D边界框估计的设计概念和深度网络框架~~。我们使用预先准备的训练集来训练网络。通过训练有素的网络,可以获得车辆的精确3D信息。然后,图像中的车辆的3D框被可视化以识别车辆的3D候选区域。
3.2. 双目图像特征提取与立体 RPN
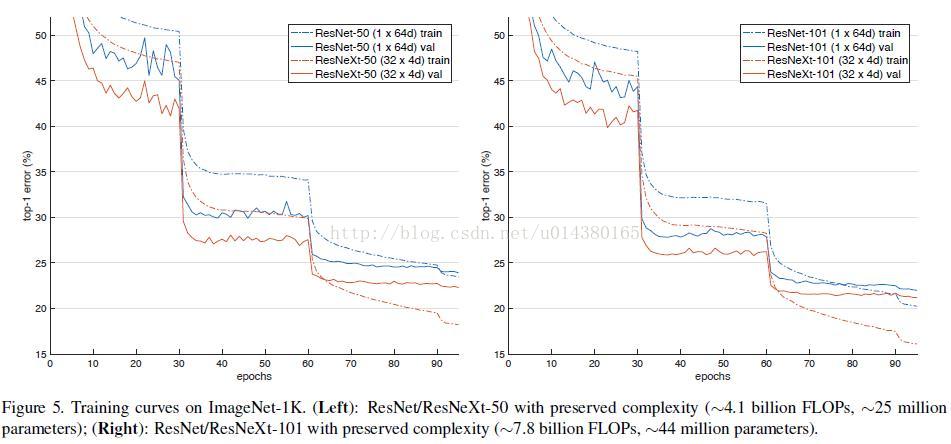
我们使用 ResNeXt-50【】 和 FPN 【】作为骨干网络,提取左右图像的一致特征。ResNeXt用一种平行堆叠相同拓扑结构的 blocks 代替原来 ResNet 的三层卷积的 block[下图一],在不明显增加参数量级的情况下提升了模型的准确率[下图2],同时由于拓扑结构相同,超参数也减少了,便于模型移植。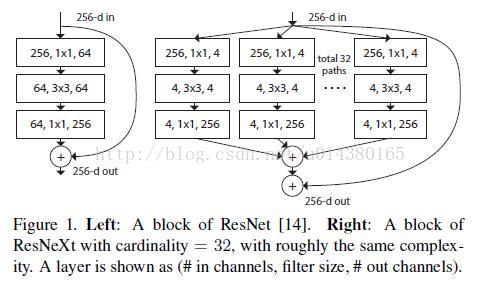
区域建议网络 (RPN) 是一种基于滑动窗口的前景检测器。特征提取后,使用一个 3×3 卷积层进行下采样,然后使用两个同级全连通层对每个输入位置的目标性进行分类,并对每个输入位置的回归盒偏移量进行归一化处理,该归一化处理用预定义的多尺度盒锚定。与 FPN 相似,我们通过在多尺度特征图上评估锚点来修正金字塔特征的原始 RPN。不同之处在于,我们在每个尺度上连接左、右特征映射,然后将连接的特征输入立体 RPN 网络。
关键的设计使我们能够同时检测和关联目标是不同的 ground truth(GT)盒分配目标分类器和立体盒回归器。如图 2 所示,我们将左右 GT 盒的并集 (称为并集 GT 盒) 作为目标分类的目标。如果锚点与其中一个联合 GT 盒的交超并集 (IoU) 比值大于 0.7,则赋予其正标签; 如果锚点与任意一个并集盒的 IoU 比值小于 0.3,则赋予其负标签。得益于这种设计,正锚往往同时包含左右两个目标区域。我们计算目标并集 GT 盒中包含的左右 GT 盒的正锚的偏移量,然后分别将偏移量分配到左右回归。立体回归器一共有 5 个回归量: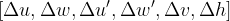
,我们用 u, v 来表示 2D 的水平和垂直坐标框中心在图像空间中, w h 框的宽度和高度, 和相应的上标对应正确的图像。注意,我们对左右框使用相同的 v,h 偏移量∆v,∆h,因为我们使用的是经过校正的立体图像。因此,我们有六个立体 RPN 回归器的输出通道,而不是原始 RPN 实现中的四个。由于左右区域建议是由相同的锚点生成的,并且共享目标得分,所以它们可以自然地关联在一起。为了减少冗余,我们分别对左右 RoI 使用非最大抑制 (NMS),然后从保存在左右 NMS 中的条目中选择前 2000 名候选框进行训练。测试时,我们只选择前 300 个候选框。
3.3. Estimation of the Vehicle’s Physical Dimension and the Projected 3D Box
根据3.2的stereo rpn网络获取的2D回归框, we have corresponding left-right proposal pairs. We apply RoI Align [8] on the left and right feature maps respectively at appropriate pyramid level. The left and right RoI features are concatenated and fed into two sequential sibling networks to get the Vehicle’s Physical Dimension and the Projected 3D Box respectively.
我们使用stereo rcnn【】网络获取车辆的精确3D框信息,该网络在立体区域建议网络 (RPN) 之后添加额外的分支来预测稀疏的关键点、视点和目标维数,并结合二维左右框来计算粗略的三维目标边界框。然后,使用左右RoI通过基于区域的光度对齐来恢复准确的3D边界框。该方法不需要深度输入和三维位置监督,但是,优于所有现有的完全监督的基于图像的方法。
为了获取目标车辆的真实3D尺寸,我们根据[6]【见下图】中的尺寸估算架构的设计思想,由于stereo rcnn已经获取的目标车辆的类别和方向角,故只需要其中预测3D尺寸信息的分支。基于所获取的concatenated left and right RoI features map ,我们修改了全连接层(FC)之后的回归参数,然后使用KITTI3D检测数据集来训练所需的3D尺寸估计模块。
3.4.Distance Estimation Module
我们的方法基于双目视觉和目标检测,还依赖于相机的固有参数fx和fy(以像素为单位的焦距)来实现距离估计。 我们将焦距(以像素为单位)与实际对象的大小结合起来,可以使用其在图像空间中的大小来估计对象的距离。 图6显示了基于相机成像原理的距离估计模型。
The principle of camera projection is a method to transform three-dimensional coordinates into two-dimensional coordinates. In order to obtain the form of pixels in the image, we need to transform the four coordinate systems. First, the points (Xw, Yw, Zw) in the world coordinate system is converted to the points (Xc, Yc, Zc) in the camera coordinate system, which then become points (x, y) on the 2D plane through perspective projection. Lastly, points(x, y) are stored in the form of pixels (u, v).
4、实验
Datasets: 本研究中提出的测距方法主要涉及车辆的3D检测网络,输出车辆的3D信息参数,并可用于可视化车辆在图像中投影的3D框。在提出的距离估计系统中,所涉及的网络模型在训练期间需要车辆的3D信息(即,长度,宽度和高度)。因此,所使用的数据集必须包含车辆的真实3D信息的标签。KITTI数据集是车辆计算机视觉评估数据集[11],该数据集主要用于车辆图像分析,是目前在自动驾驶领域使用最为广泛的数据集。该数据集标签包含相机视场中的每个运动对象的真实3D尺寸以及距离信息。因此,我们主要使用KITTI中的对象检测数据来训练网络,然后在KITTI检测基准上对其进行测试和验证。
5、结果
6、总结

若有收获,就点个赞吧
0 人点赞
