ROI(Region of Interest) Pooling 是 Pooling 的一种。在传统 CNN 中,Pooling 层的作用主要有三个:
1、特征不变性,使模型更加关注是否存在某些特征而不是特征具体的位置,对于一些旋转和平移具有不变性
2、特征降维,使模型可以抽取更广泛围的特征,减小了下一层输入大小,进而减小计算量和参数个数
3、在一定程度防止过拟合,更方便优化
ROI Pooling 是针对 RoIs 的 Pooling,其特点是输入特征图尺寸不固定,但是输出特征图尺寸固定。
在 Fast RCNN 中, RoI 是指 Selective Search 完成后得到的 “候选框” 在特征图上的映射
在 Faster RCNN 中,候选框是经过 RPN 产生的,然后再把各个 “候选框” 映射到特征图上,得到 RoIs
ROI Pooling 的思想来自于SPPNet中的 Spatial Pyramid Pooling,在Fast RCNN中使用时,将 SPPNet 中多尺度的池化简化了为单尺度。
在介绍 ROI Pooling 之前,先简单介绍一下 SPP 的过程,两者的目的都是将不同大小的窗口输入得到同样大小的窗口输出。
在卷积的操作中,对输入的尺寸是没有限制的,但是大多数网络结构的卷积操作后会连着全连接层,因此网络的输入也就有了限制,不然最后一层卷积的输出尺寸无法对应全连接层的输入。当输入图片不满足限制的尺寸时,需要进行裁剪 (crop) 和拉伸(warp),如下图:
这样做总是不好的:图像的纵横比 (ratio aspect) 和输入图像的尺寸是被改变的。这样就会扭曲原始的图像。而 Kaiming He 在这里提出了一个 SPP(Spatial Pyramid Pooling) 层能很好的解决这样的问题, 根据之前分析,SPP 只需连接在最后一层卷积层,以便满足全连接层的输入尺寸,与之前结构对比如下:
SPP 的显著特点是:
- 不管输入尺寸大小,SPP 可以产生固定尺寸的输出
- 使用多个不同大小的 pooling 窗口
- SPP 可以使用同一图像不同尺寸 (scale) 作为输入, 得到同样长度的池化特征。
因此,SPP 带来的好处有:
可以处理不同纵横比和不同尺寸的输入图片,所以提高了图像的尺度不变 (scale-invariance)、降低了过拟合
实验表明训练图像尺寸的多样性比单一尺寸的训练图像更容易使得网络收敛 (convergence)
SPP 对于特定的 CNN 网络设计和结构是独立的。(也就是说,只要把 SPP 放在最后一层卷积层后面,对网络的结构是没有影响的, 它只是替换了原来的 pooling 层)
空间金字塔池化(spatial pyramid pooling)的原理并不复杂,其网络结构如下图: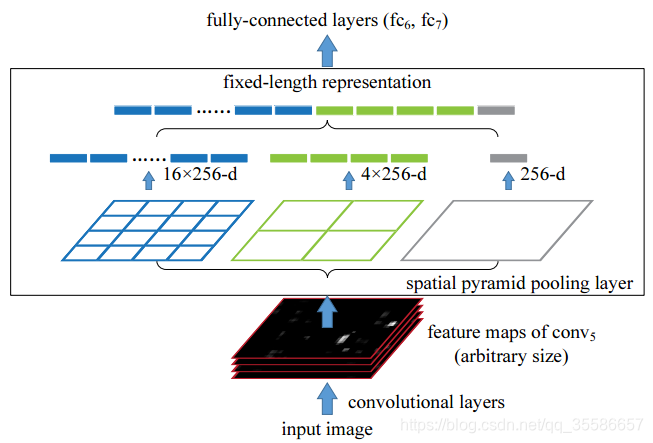
假设输入 feature map 的尺寸为 H x W x C,使用一个 H x W 尺寸的 pooling 层进行处理,那么每一个通道 C 变成了一个值,整个输入得到了一个 C 维的输出;再分别用 H/2 x W/2 和 H/4 x W/4 尺寸的 pooling 层处理,得到了 4xC 和 16xC 维的输出,把三个结果 concat 在一起变成了一个 21xC 维的输出,其大小和输入的 H 与 W 无关。
简而言之,是将任意尺寸的 feature map 用三个尺度的金字塔层分别池化,再将池化后的结果拼接得到固定长度的特征向量(图中的 256 为 filter 的个数),送入全连接层进行后续操作。
在 RCNN 的结构中,候选框通过 Selective Search 的方法获得,每一个框经过缩放分别送入网络中提取特征,因此非常消耗时间,Fast RCNN 借鉴了 SPP 的思想,通过 ROI Pooling 的结构解决了这个问题。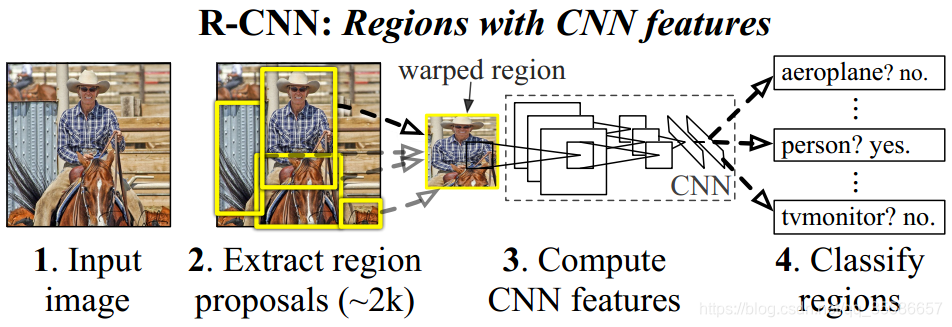
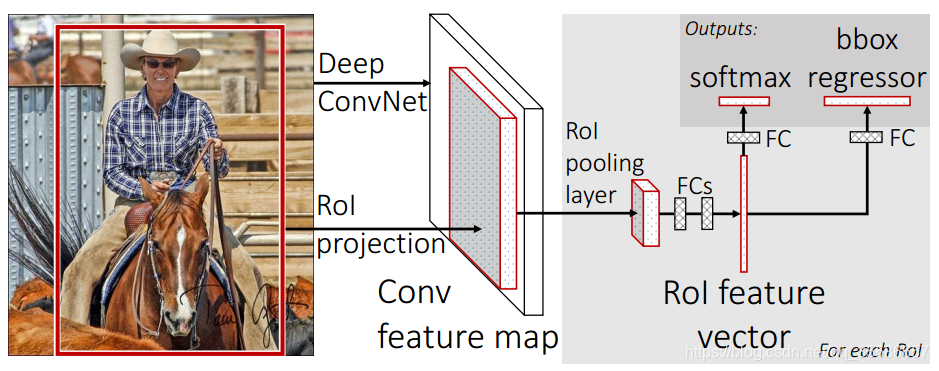
通过上图 RCNN 与 Fast RCNN 的结构对比,可以看到在 Fast RCNN 中只需要把原始图片送入网络提取一次特征即可,通过感受野的对应关系,把不同大小的候选框直接映射到最后一层卷积输出的 feature map 上,而 ROI Pooling 的作用就是把 feature map 上对应的不同大小的框,转换为相同大小作为下一层全连接的输入。
ROI Pooling 的输入:
网络最后一个卷积层的输出 feature map,shape 为 (N, W/16, H/16, channels),除以 16 是因为使用 VGG16 的话,会经历四次 2 x 2 的 max poolinig,尺寸相比于图片原始 W 和 H 缩小了 16 倍
ROI(Region of Interest) 的坐标,一个 N x 5 的矩阵,其中 N 表示 ROI 的数目。第一列表示图像 index,其余四列表示每个矩形框的左上角和右下角坐标(在原图而不是 feature map 上的坐标值);
ROI Pooling 的具体操作:
得到最后一个卷积层的输出 feature map
根据 feature map 与原图的比例,将 ROI 映射到 feature map 对应位置上(图片的尺寸已经下降了 16 倍,那么输入的 ROI 也会相应的就行缩小 16 倍,在代码中 spatio_scale=1/16);
将映射后的区域划分为相同大小的 sections(sections 数量与输出的维度相同);
对每个 sections 进行 max pooling 操作;
ROI Pooling 的输出:
不同 ROI 对应的相同尺寸的特征向量,shape 为 (num_ROIs, expected_H, expected_W, channels) ,论文中提到如果使用 VGG-16 的话,expected_H=expected_W=7
ROI Pooling 实例:
我们有一个 8x8 大小的 feature map,一个 ROI,以及输出大小为 2x2.
- 输入固定大小的 feature map
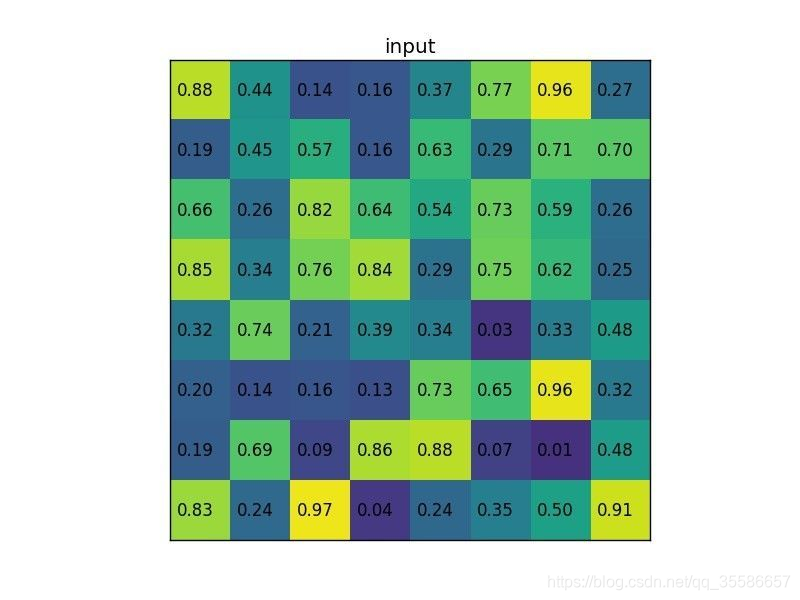
- region proposal 投影之后位置(左上角,右下角坐标):(0,3),(7,8)。
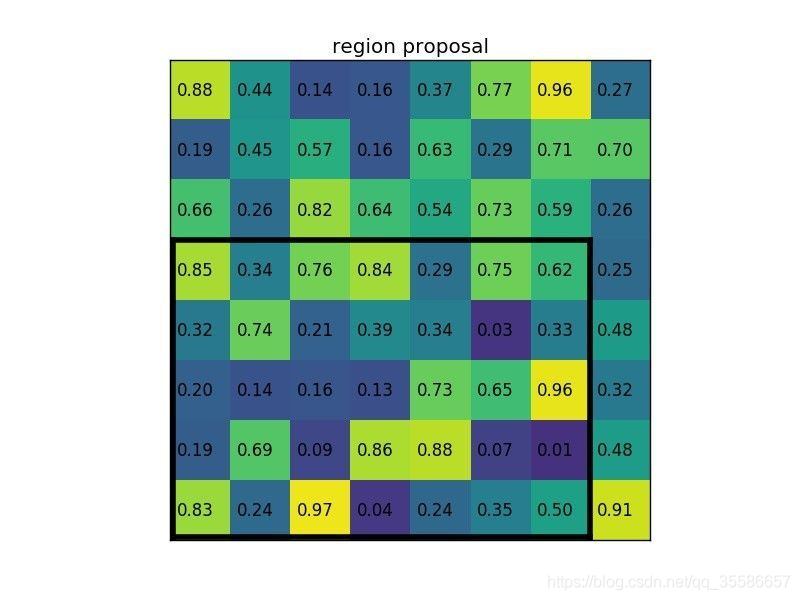
- 将其划分为(2x2)个 sections(指定输出的大小为 2x2),可以得到:
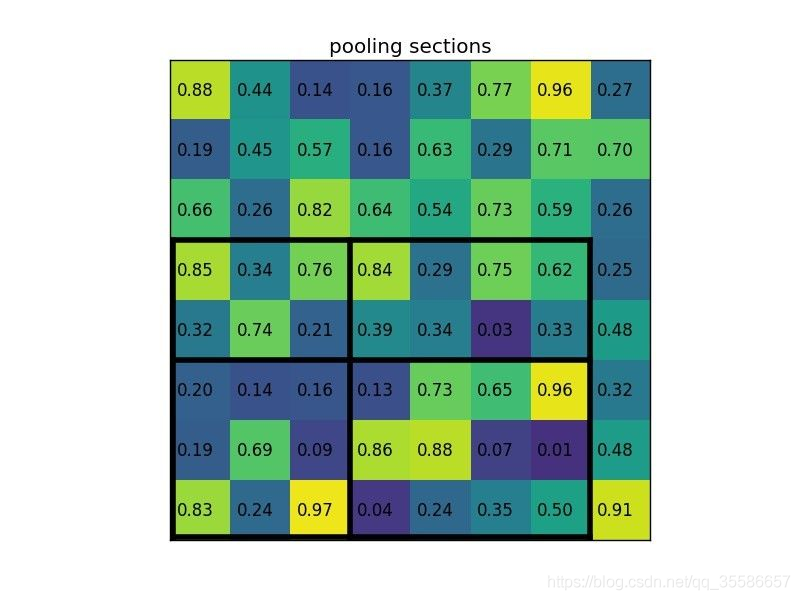
- 对每个 section 做 max pooling,可以得到:
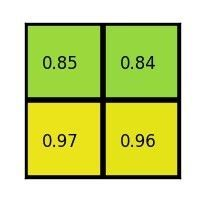
完整过程如下: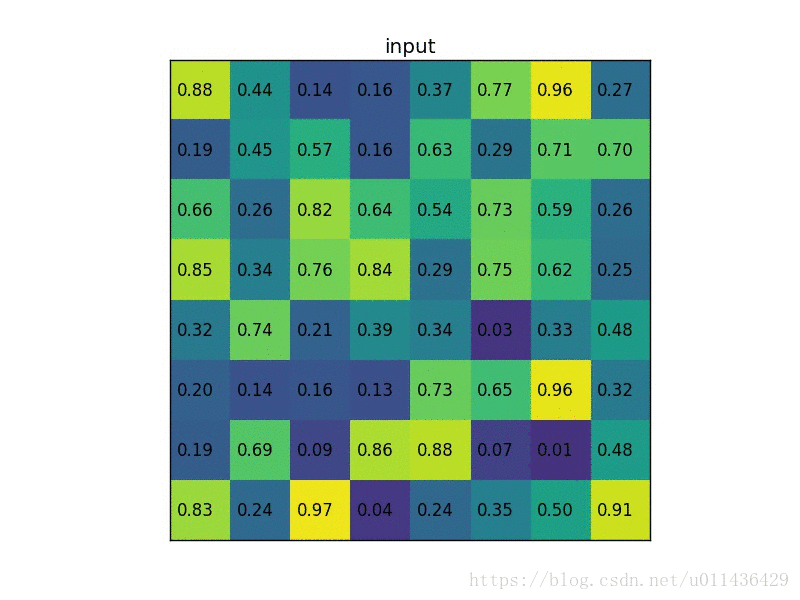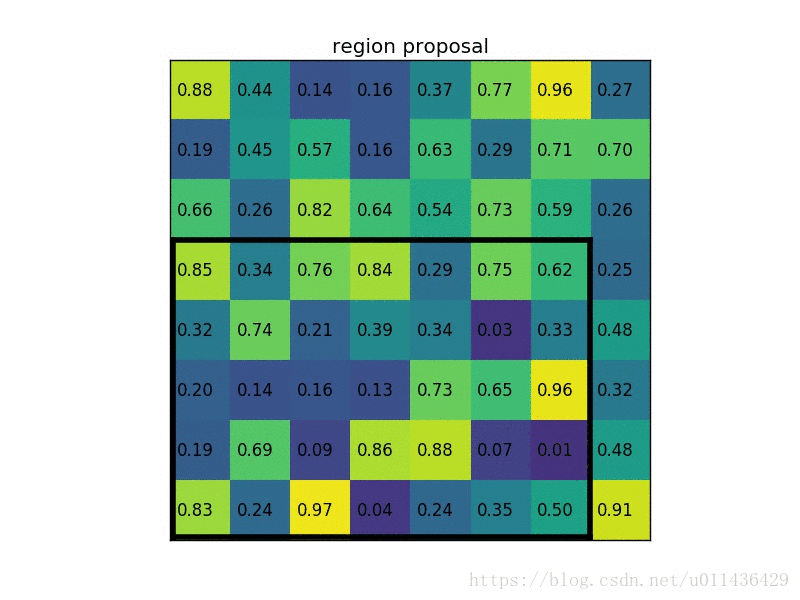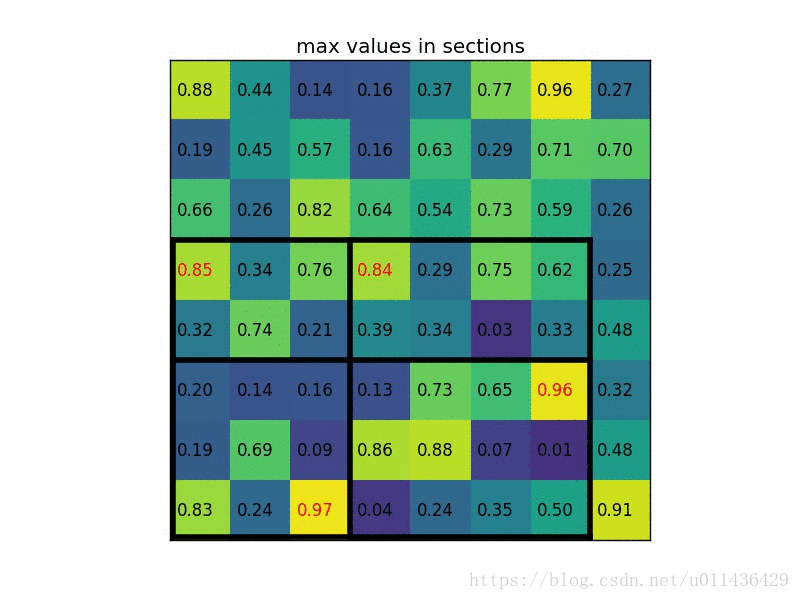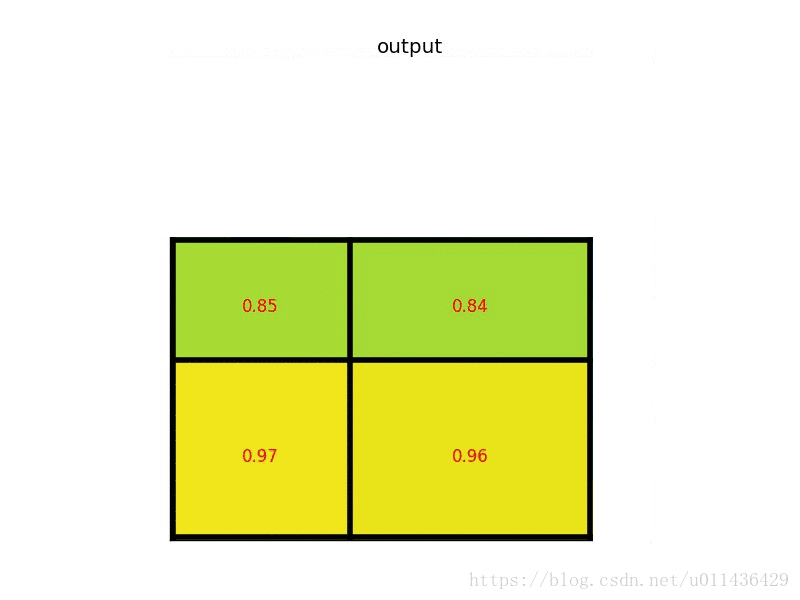
如上实例中显示了对一个 ROI 的处理过程,对于不同大小的 ROI,该方法处理可以得到相同尺寸 (2 x 2) 的输出,在此案例中 region proposals 是 5 x 7 大小的,在 pooling 之后需要得到 2 x 2 的,所以在 5 x 7 的特征图划分成 2 x 2 的时候不是等分的,行是 5/2,第一行得到 2,剩下的那一行是 3,列是 7/2,第一列得到 3,剩下那一列是 4。
ROI Pooling 与 SPP 的区别:
通过上面的介绍,可以看到两者起到的作用是相同的,把不同尺寸的特征输入转化为相同尺寸的特征输出。SPP 针对同一个输入使用了多个不同尺寸的池化操作,把不同尺度的结果拼接作为输出;而 ROI Pooling 可看作单尺度的 SPP,对于一个输入只进行一次池化操作。
Fast RCNN 对 RCNN 的改进:
ROI Pooling 的加入,使得 Fast RCNN 相比于 RCNN 在两个方面有了较大的改善:
1、由于 ROI Pooling 可接受任意尺寸的输入,warp 操作不再需要,这有效避免了物体的形变扭曲,保证了特征信息的真实性
2、不需要对每个 proposal 都提取特征,采用映射方式从整张图片的 feature map 上获取 ROI feature 区域
除了上述两点,从之前给出的结构图的对比也可以看出还有一个比较明显的改进:
3、RCNN 中在获取到最终的特征后先采用 SVM 进行类别判断,再进行 bounding-box 的回归得到位置信息。整个过程是个串行的流程,这极大地影响了网络的检测速度。Fast R-CNN 中则将 Classification 和 Regression 的任务合二为一,变成一个 multi-task 的模型,实现了特征的共享也进一步提升了速度。
参考博客:https://blog.csdn.net/u011436429/article/details/80279536
https://www.jianshu.com/p/9db81f1bb439
https://blog.csdn.net/qq_35586657/article/details/97885290

若有收获,就点个赞吧
0 人点赞
