Python
对于不少机器学习的爱好者来说,训练模型、验证模型的性能等等用的一般都是sklearn模块中的一些函数方法。
极值检测
数据集当中存在着极值,这个是很正常的现象,市面上也有很多检测极值的算法,而sklearn中的EllipticalEnvelope算法值得一试,它特别擅长在满足正态分布的数据集当中检测极值,代码如下
import numpy as npfrom sklearn.covariance import EllipticEnvelope# 随机生成一些假数据X = np.random.normal(loc=5, scale=2, size=100).reshape(-1, 1)# 拟合数据ee = EllipticEnvelope(random_state=0)_ = ee.fit(X)# 新建测试集test = np.array([6, 8, 30, 4, 5, 6, 10, 15, 30, 3]).reshape(-1, 1)# 预测哪些是极值ee.predict(test)
output
array([ 1, 1, -1, 1, 1, 1, -1, -1, -1, 1])
在预测出来哪些数据是极值的结果当中,结果中“-1”对应的是极值,也就是30、10、15、30这些结果
特征筛选(RFE)
在建立模型当中,筛选出重要的特征,对于降低过拟合的风险以及降低模型的复杂度都有着很大的帮助。Sklearn模块当中递归式特征消除的算法(RFE)可以非常有效地实现上述的目的,它的主要思想是通过学习器返回的coef_属性或者是feature_importance_属性来获得每个特征的重要程度。然后从当前的特征集合中移除最不重要的特征。在剩下的特征集合中不断地重复递归这个步骤,直到最终达到所需要的特征数量为止。
来看一下下面这段示例代码
from sklearn.datasets import make_regressionfrom sklearn.feature_selection import RFECVfrom sklearn.linear_model import Ridge# 随机生成一些假数据X, y = make_regression(n_samples=10000, n_features=20, n_informative=10)# 新建学习器rfecv = RFECV(estimator=Ridge(), cv=5)_ = rfecv.fit(X, y)rfecv.transform(X).shape
output
(10000, 10)
以Ridge()回归算法为学习器,通过交叉验证的方式在数据集中去掉了10个冗余的特征,将其他重要的特征保留了下来。
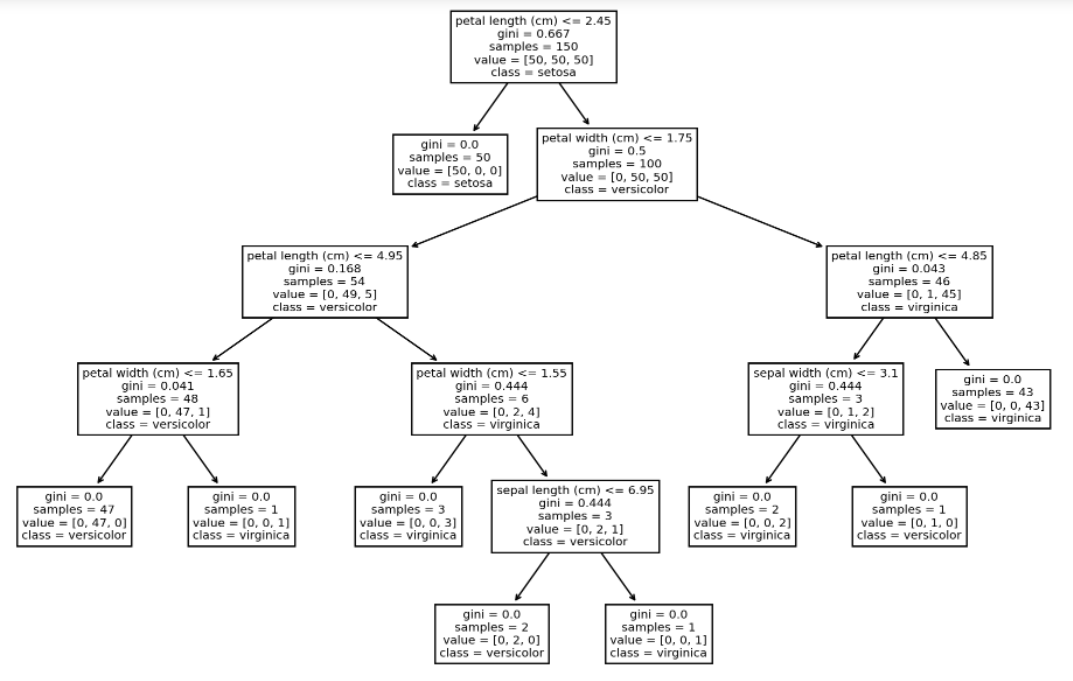
决策树的绘制
相信对不少机器学习的爱好者来说,决策树算法是再熟悉不过的了,要是同时能够将其绘制成图表,就可以更加直观的理解它的原理与脉络,来看一下下面的这个示例代码
from sklearn.datasets import load_irisfrom sklearn.tree import DecisionTreeClassifier, plot_treeimport matplotlib.pyplot as plt%matplotlib inline# 新建数据集,用决策树算法来进行拟合训练df = load_iris()X, y = iris.data, iris.targetclf = DecisionTreeClassifier()clf = clf.fit(X, y)# 绘制图表plt.figure(figsize=(12, 8), dpi=200)plot_tree(clf, feature_names=df.feature_names,class_names=df.target_names);
HuberRegressor回归
数据集当中要是存在极值会大大降低最后训练出来模型的性能,大多数的情况下,可以通过一些算法来找到这些极值然后将其去除掉,当然这里还有介绍的HuberRegressor回归算法提供了另外一个思路,它对于极值的处理方式是在训练拟合的时候给予这些极值较少的权重,当中的epsilon参数来控制应当是被视为是极值的数量,值越小说明对极值的鲁棒性就越强。具体请看下图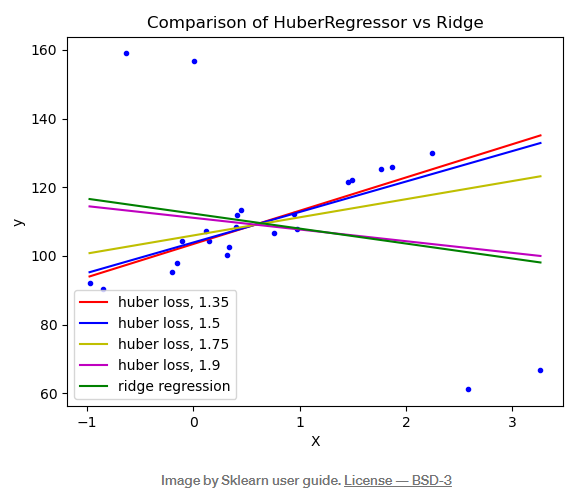
当epsilon的值等于1.35、1.5以及1.75的时候,受到极值的干扰都比较小。该算法具体的使用方法以及参数的说明可以参照其官方文档。
https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.HuberRegressor.html
特征筛选 SelectFromModel
另外一种特征筛选的算法是SelectFromModel,和上述提到的递归式特征消除法来筛选特征不同的是,它在数据量较大的情况下应用的比较多因为它有更低的计算成本,只要模型中带有feature_importance_属性或者是coef_属性都可以和SelectFromModel算法兼容,示例代码如下
from sklearn.feature_selection import SelectFromModelfrom sklearn.ensemble import ExtraTreesRegressor# 随机生成一些假数据X, y = make_regression(n_samples=int(1e4), n_features=50, n_informative=15)# 初始化模型selector = SelectFromModel(estimator=ExtraTreesRegressor()).fit(X, y)# 筛选出重要的模型selector.transform(X).shape
output
(10000, 9)

若有收获,就点个赞吧
0 人点赞
