决策树
以贷款申请客户风险的例子,假设搜集到的客户资料包含两个特征:
- 逻辑型的特征“有无支票账户”
- 数值型的特征“当前欠款总额”
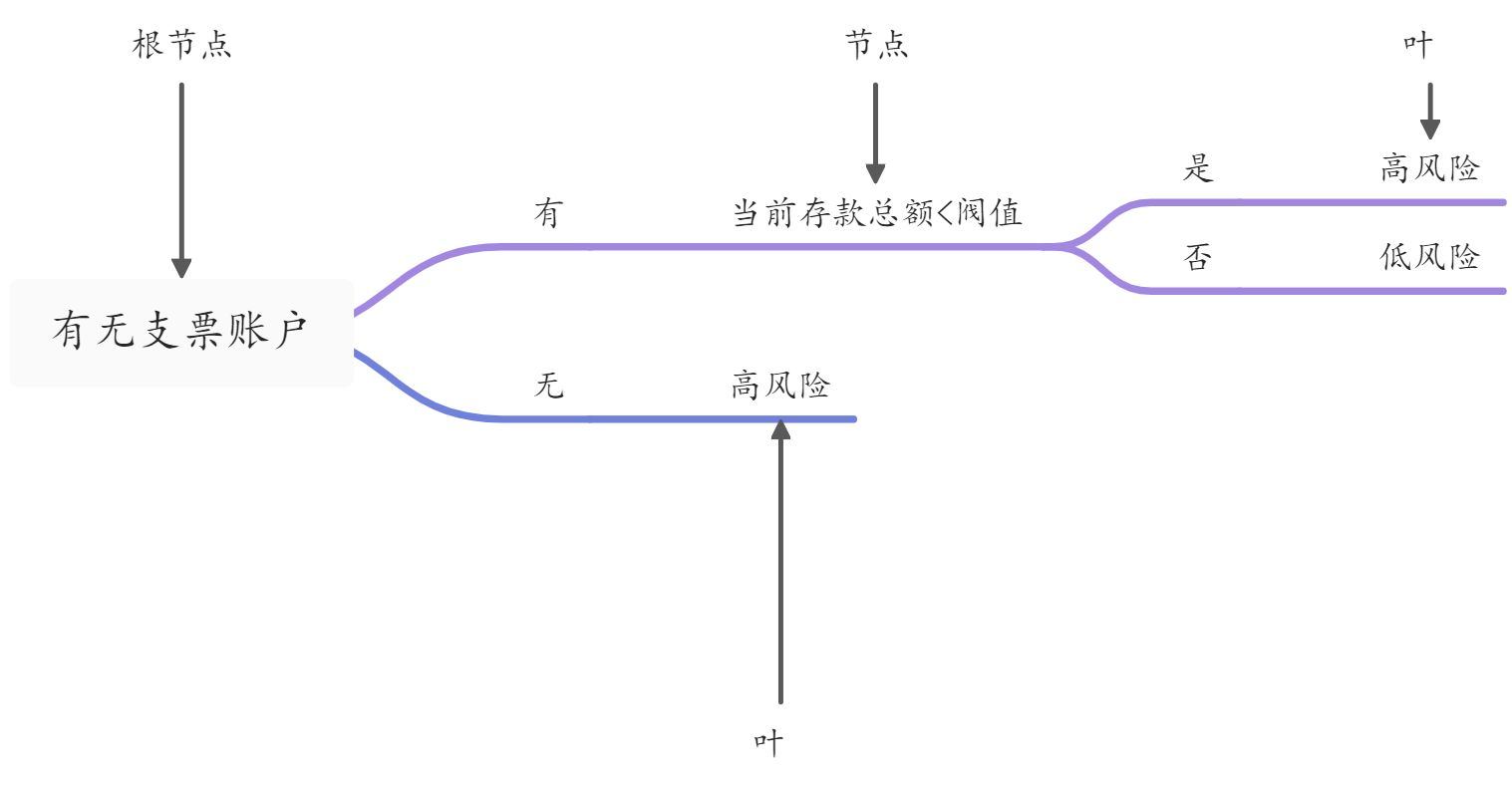
决策树:对特征的条件判断,达到各个目标“叶”,实现分类任务。
◇采用哪些特征作为节点
◇各节点具体的条件表达式
建好决策树模型→模型应用
利用已知风险分类数据作为训练集来训练、建立模型
分类任务决策树建模过程
- 计算数据的纯度;
- 选择一个候选划分;
- 计算划分后数据的纯度;
- 对所有的特征重复第2步和第3步;
- 选择使纯度增加最大的特征作为当前的节点,分别对分支计算数据纯度,再对剩下的特征重复第2步开始的过程;
- 当达到预先设定的树深度、或所有特征都遍历完,或者分支下全部数据属于同一类别时,建模完成。
纯度衡量
☆基尼系数
☆信息嫡☆基尼系数
在D数据集中,K分类的基尼系数定义为:
:第i类在数据集中出现的概率,可以由第i类个体的个数除以数据集中个体总数来计算
☆越小,纯度越高,最小值为0;
☆越大,纯度越低,最大值为,例如对于二分类情况最大值就是
| 总数 | 25 |
|---|---|
| 高风险 | 10 |
| 低风险 | 15 |
引入特征“有无支票账户”
| 无支票账户 | 有支票账户 | |
|---|---|---|
| 高风险 | 8 | 2 |
| 低风险 | 2 | 13 |
引入特征:“婚姻状况”
| 已婚 | 未婚 | |
|---|---|---|
| 高风险 | 5 | 5 |
| 低风险 | 7 | 8 |
:::info 选择使纯度增加最大的特征为节点
所以这里选择有无支票而不是婚姻状态。 ::: 可以再对剩下的节点进行搜索,使分支基尼系数下降最多的特征进行划分,作为下一级的节点,依次类推,直到满足以下三个条件时
- 直到达到事先设定的最大树深度,
- 或所有的特征都已遍历完,
- 或分支下数据全部属于同一类,无须再分。
scikit-learn库中有DecisionTreeClassifier对象可以实现决策树模型。
以一个德国的银行信用数据为例,以他来构建决策树。
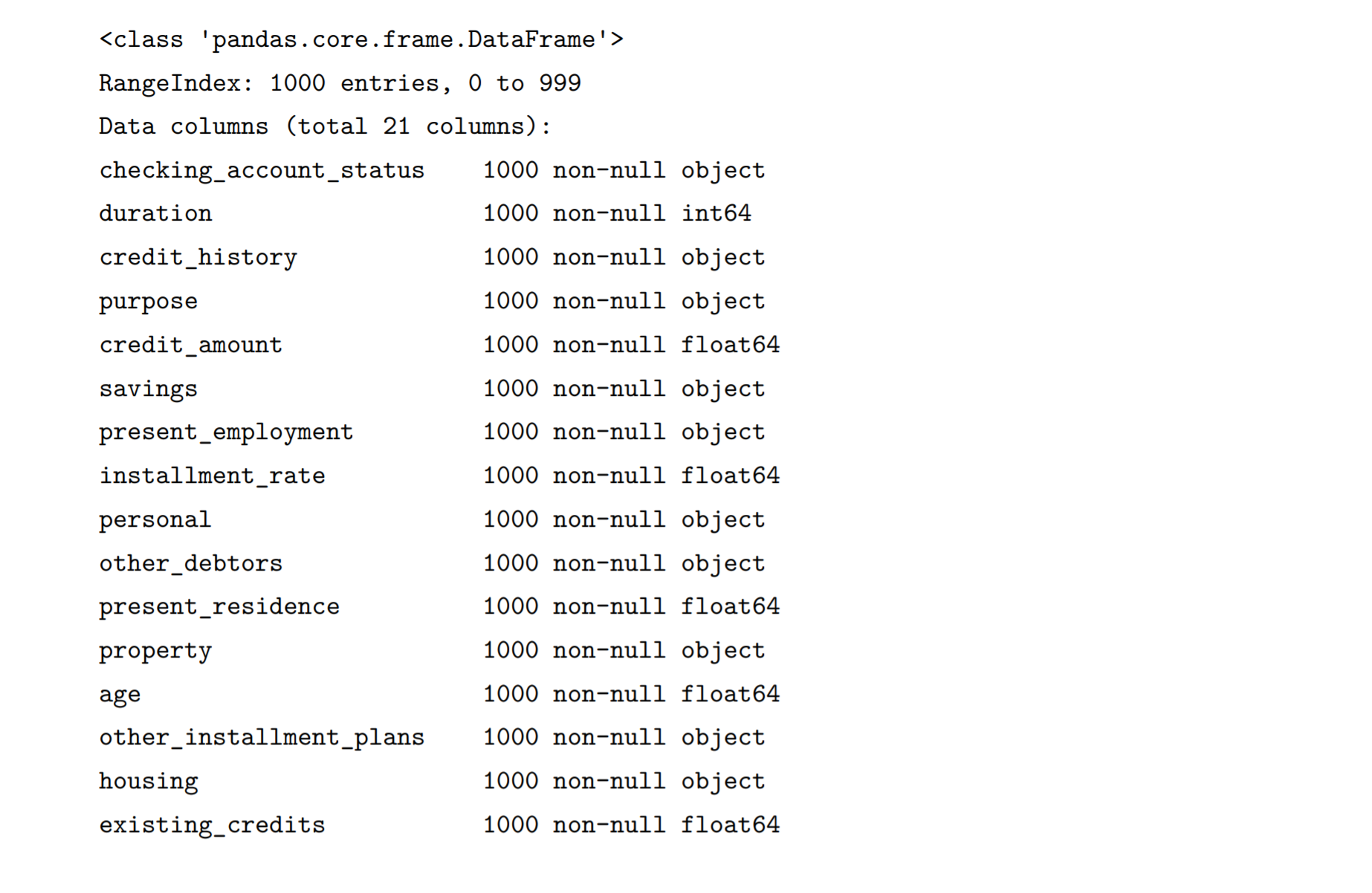
import pandas as pdimport numpy as npfrom scipy import statsfrom matplotlib import pyplot as pltmy_data = pd.read_csv("C:\Python\Scripts\my_data\german_credit_data_dataset.csv")#,dtype=str)print(my_data.info())
使用 checking_account_status(有无支票账户)、credit_amount (当前欠款金额)、 personal (个人性别与婚姻状况)这几种特征,选好特征后,构造好训练模型的特征和目标数据
from sklearn.model_selection import train_test_splitfrom sklearn.tree import DecisionTreeClassifierfeature_col=['checking_account_status','personal']X=my_data[['customer_type','credit_amount']] #for n,my_str in enumerate(feature_col):my_dummy=pd.get_dummies(my_data[[my_str]],prefix=my_str)X=pd.concat([X,my_dummy],axis=1)XX_feature=['credit_amount','checking_account_status_A14','personal_A91','personal_A92','personal_A93','personal_A94']XX=X[XX_feature]Y=X['customer_type']X_train,X_test,Y_train,Y_test=train_test_split(XX,Y,test_size=0.2,random_state=0)my_tree=DecisionTreeClassifier(max_depth=3)my_tree.fit(X_train,Y_train)print('分类结果为:',my_tree.predict(X_test),'\n')print('平均准确率为:',my_tree.score(X_test,Y_test))
通过feature_importances_属性可以获得在各个特征在分类任务中的重要性。
pd.DataFrame({'feature':XX.columns,'importance':my_tree.feature_importances_})
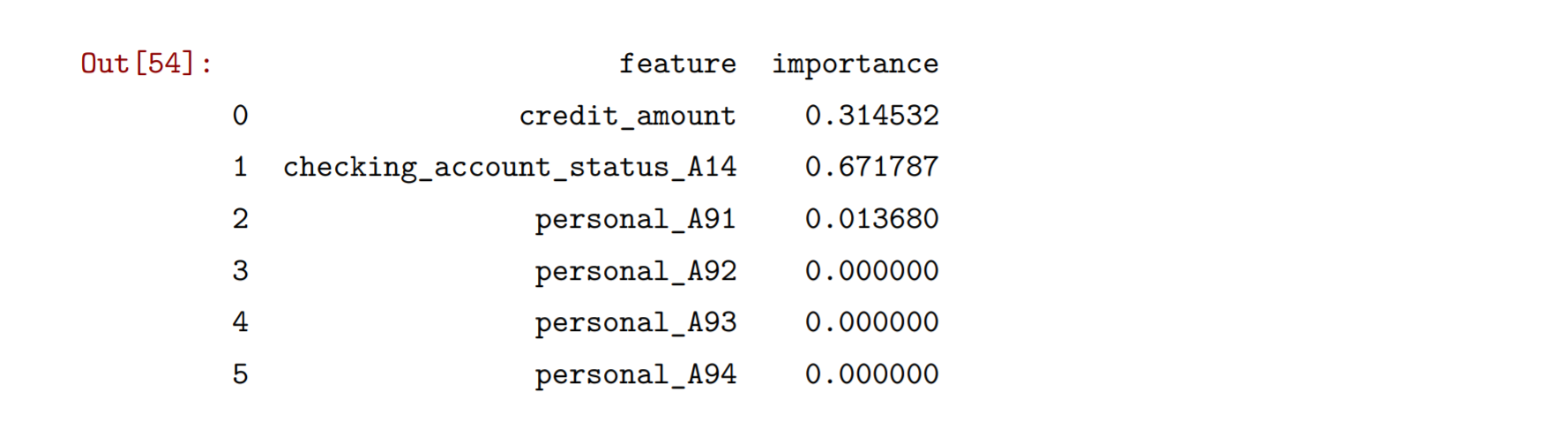
可以看到这个模型中有无支票账户是重要的特征,而个人性别与婚姻状态是重要性最低的。
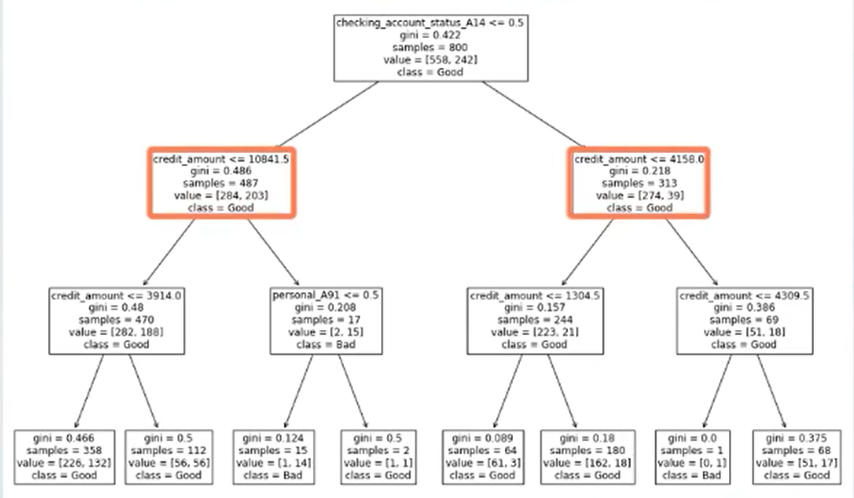
在最新版的sklearn库中支持可视化决策树结果
from sklearn import treeimport matplotlib.pyplot as pltplt.figure(figsize=(18,12))tree.plot_tree(my_tree,fontsize=12,feature_names=XX.columns,class_names=['Good','Bad'])plt.savefig('my_tree')
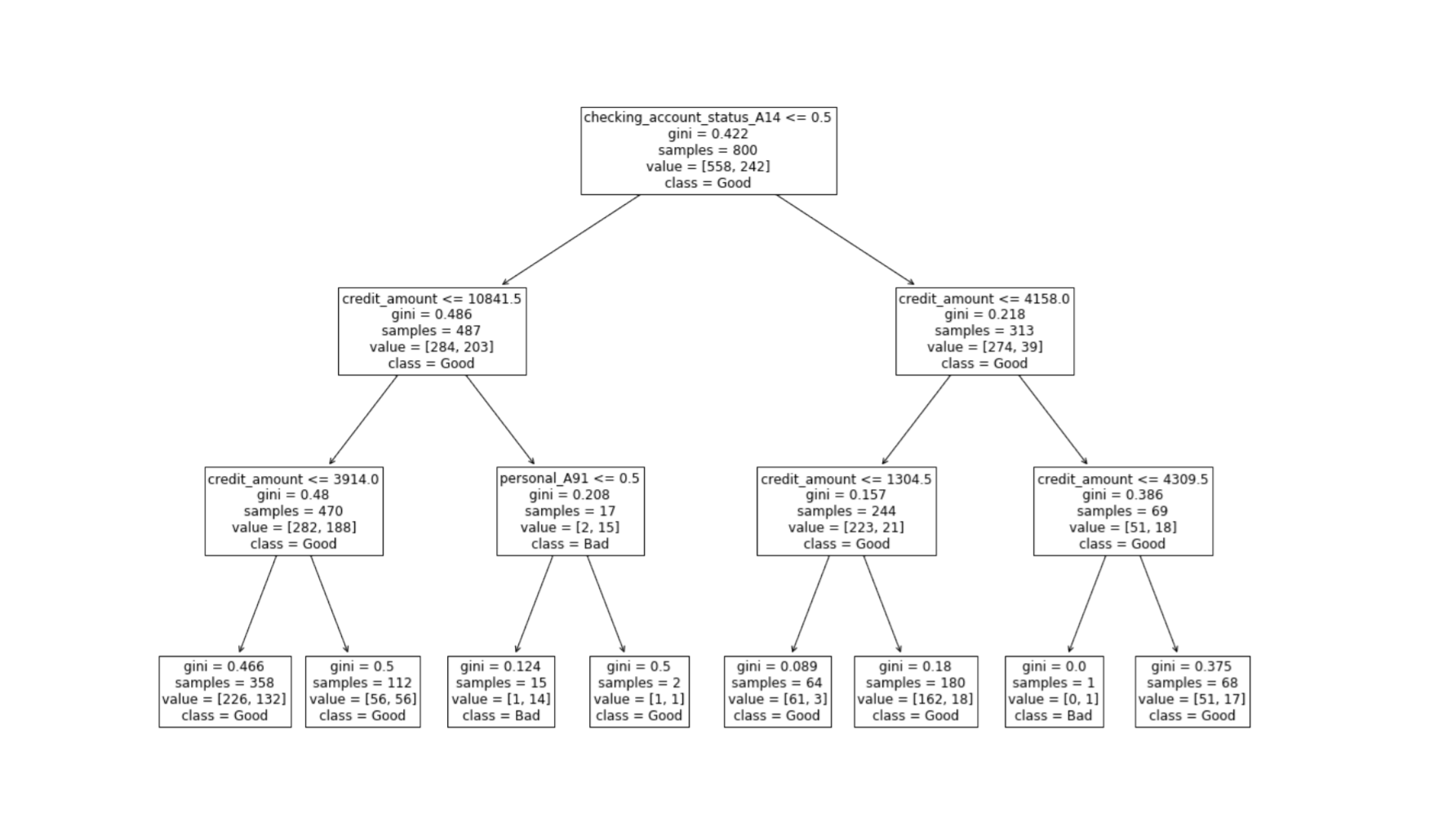
决策树
◇用于分类任务
◇用于回归任务:输出数值型结果
主要区别:在建模过程中,不是以Gini系数等为划分选择原则而是以最小化平均平方误差MSE为原则。

若有收获,就点个赞吧
0 人点赞
