线性回归
回归
回归:建立因变量y和自变量x之间的函数关系
y:希望被预测或被解释的变量,目标或响应;
x:预测变量,一般指容易获得的样本特征;
截距
回归系数
预测值
观测值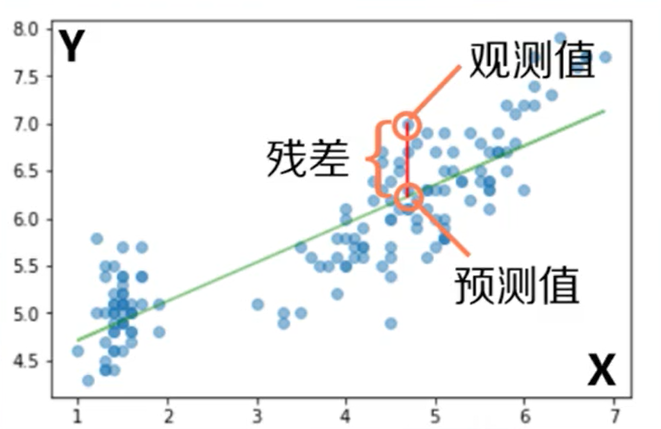
:残差(选择直线的依据)
通过残差平方和最小可以转换为求一阶导数的零点
回归直线使残差平方和最小的直线,且通过点
,RMSE与y有相同单位或量纲;
这个求回归线的方法也叫最小二乘法。
:::info
Sklearn库
—linear_model模块
—LinerRegression对象
可以用来做线性回归。
:::
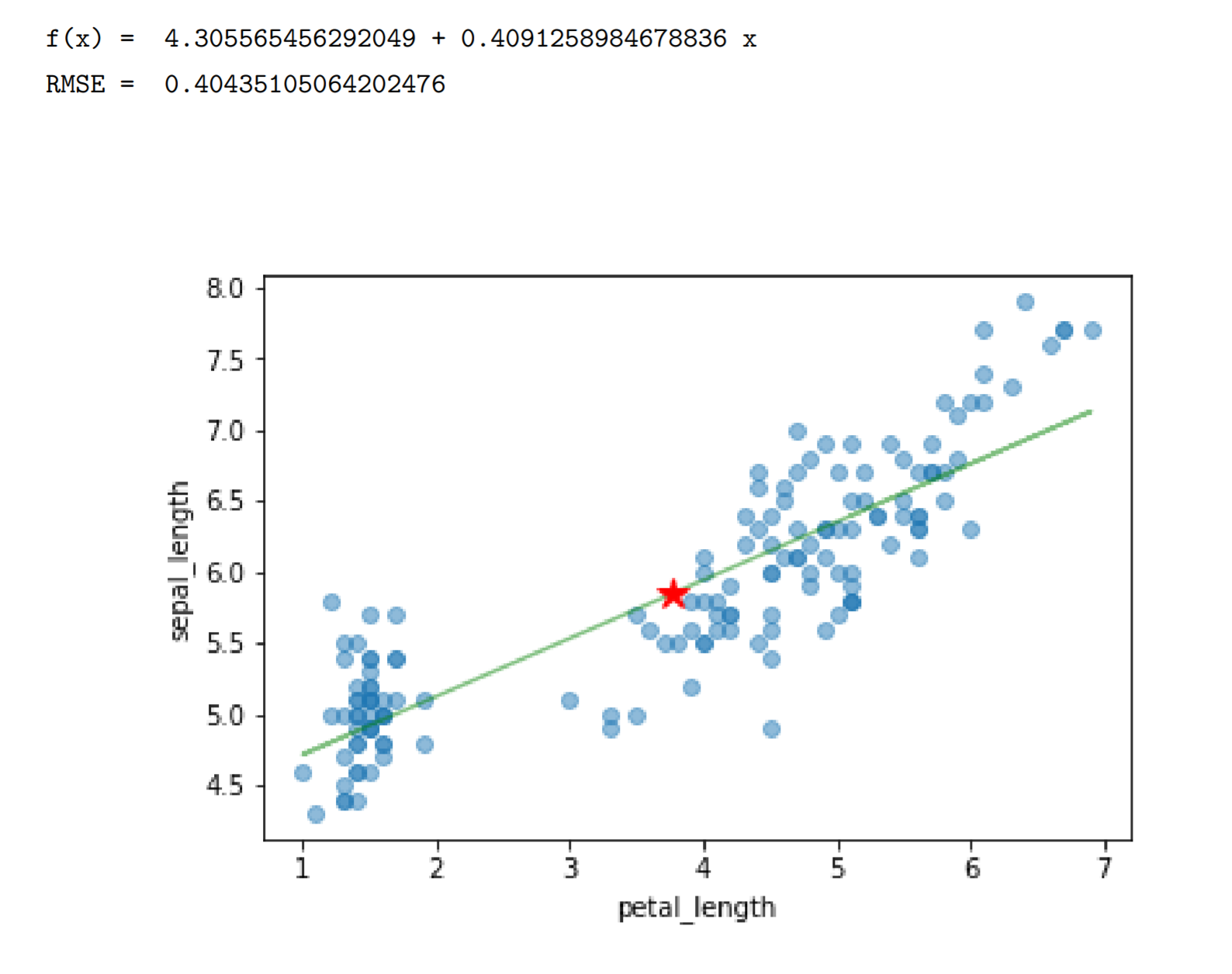
import pandas as pdimport numpy as npfrom scipy import statsfrom matplotlib import pyplot as pltfrom sklearn.linear_model import LinearRegressionfrom sklearn import metricsmy_iris=pd.read_csv('C:\Python\Scripts\my_data\iris.csv',sep=',',decimal='.',header=None,names=['sepal_length','sepal_width','petal_length','petal_width','target'])feature_cols='petal_length'# feature_cols='sepal_width'x=my_iris[[feature_cols]]y=np.array(my_iris['sepal_length'])plt.plot(x,y,'o',alpha=0.5)linreg=LinearRegression()linreg.fit(x,y)print('f(x) = ',linreg.intercept_,'+',linreg.coef_[0],'x')pred_y=linreg.predict(x)plt.plot(x,pred_y,'g',alpha=0.5)plt.plot(np.array(x).mean(),y.mean(),'r*',ms=12)plt.gca().set_xlabel(feature_cols)plt.gca().set_ylabel('sepal_length')print('RMSE = ',np.sqrt(metrics.mean_squared_error(y,pred_y)))print('\n')
如何评价回归模型的好与不好?
给出不重复的样本,总是能找到一条回归线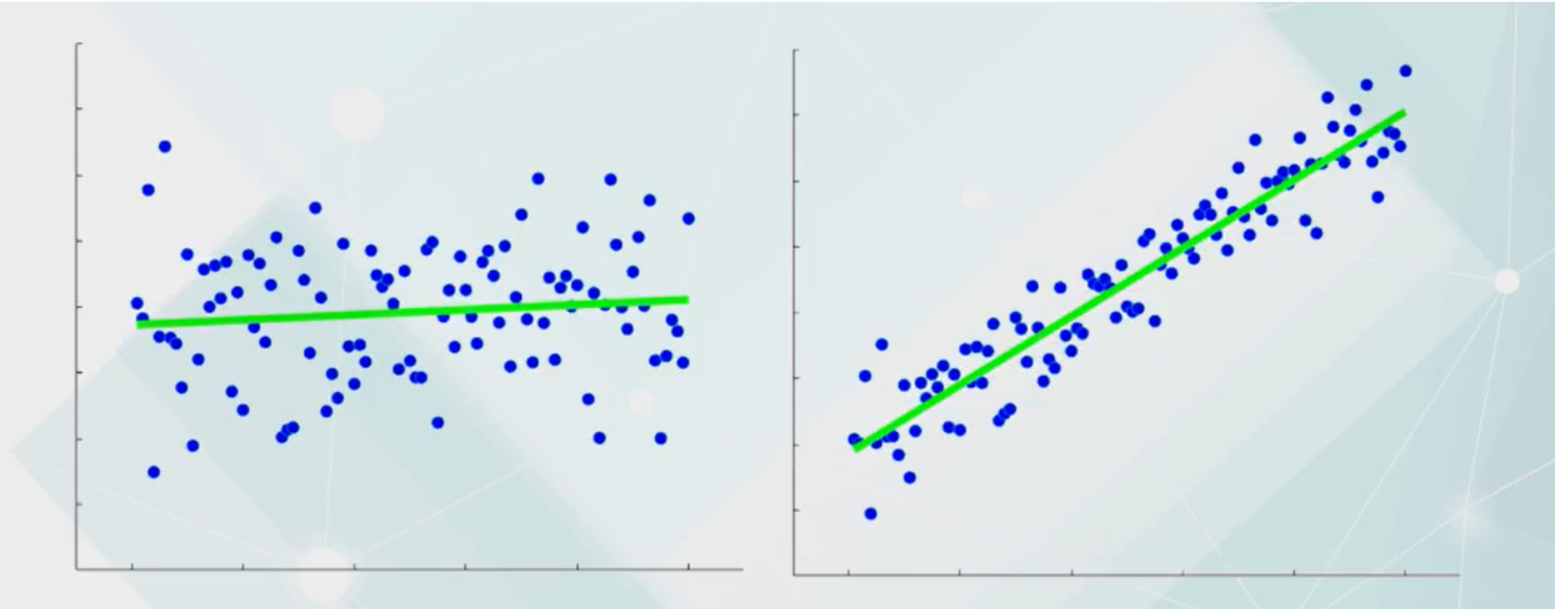
但是找到的这条回归线真的有意义吗?此时就需要引入回归效果评价参数。
定义:回归平方和与样本的总平方和之比,也等于1减去残差平方和和总平方和之比。
总平方和:样本相对于样本均值的总离差。
回归平方和:由于回归函数所引入的样本相对于均值的离差,属于样本变异性中可以被回归模型解释的部分。
意义:用模型可解释部分与总离差比较,取值在0到1间。
>越靠近1,模型可解释成分越多,模型性能越好;
>越靠近0,性能越不好;
查看刚刚模型的r_square
print('r_square = ',linreg.score(x,y))
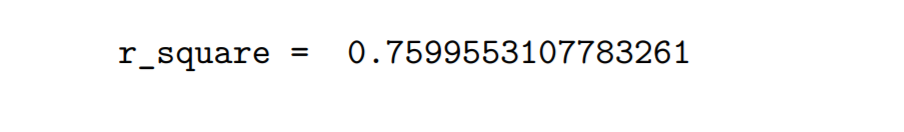
线性回归与线性相关
| 线性相关分析 | 线性回归分析 |
|---|---|
| 线性相关系数反映两个变量的耦合程度,其中两个变量的地位平等,不能用一个变量去预测另一个。 | 强调回归函数的确定,直接建立起两个变量间的函数关系,以期用x去预测y。 |
| 取值:[-1,1] | 取值:[0,1] |
print(my_iris[[feature_cols,'sepal_length']].corr())print('\n')r=np.array(my_iris[[feature_cols,'sepal_length']].corr()[['sepal_length']].iloc(0)[0])print('r = ',r)print('square of r = ',r**2)

这里可以看到petal_length和sepal_length的相关系数为0.87,他的平方正好是之前求出的r_square。
| —元线性回归 | x有一列特征 |
|---|---|
| 多元线性回归 | x有多列特征 |
| 特征越多→模型越复杂→过拟合 |
过拟合:模型只在建模的数据上性能好,一旦面对新数据性能就非常糟糕。
建模的目的是用模型去预测新的数据。所以过拟合的问题是一定要避免的,先保留这个问题。
逻辑回归——二分类的实现
办法:在线性回归的基础上,对输出所在的连续区间做阈值划分。
如:规定模型输出值低于阈值属于一类,高于阈值则属于另一类。
用量化特征预测某事发生的概率。概率取值区间:[0,1]
Logistic回归
Logistic回归的图像
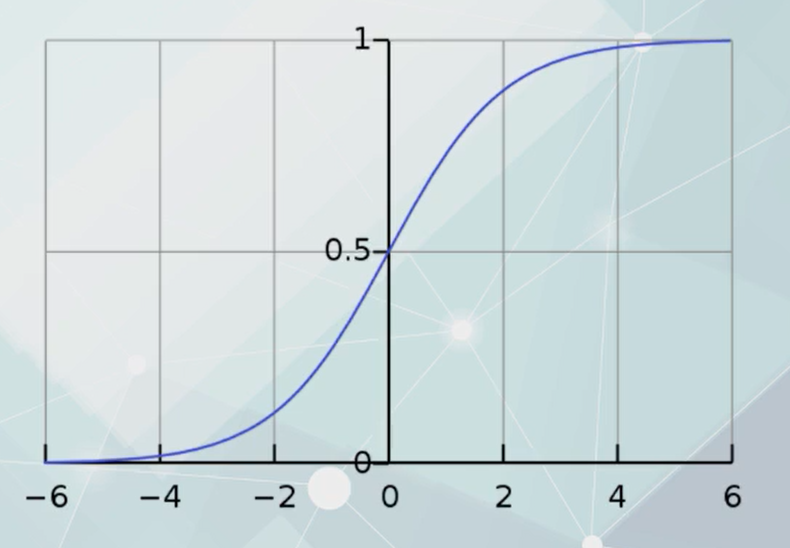
Logistic回归函数
Logistic输出:预测变量-某事件的发生概率
输入t是样本特征的线性函数作为自变量。
引入另一个概念Odds:
某事件发生的概率,记作P;
该事件的几率:该事件发生的概率与不发生的概率之比。
对log(Odds)做线性回归:
import pandas as pdimport numpy as npfrom matplotlib import pyplot as plttable=pd.DataFrame({'prob':[0.01,0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,0.99]})table['odds']=table['prob']/(1-table['prob'])table['log-odds']=np.log(table['odds'])table
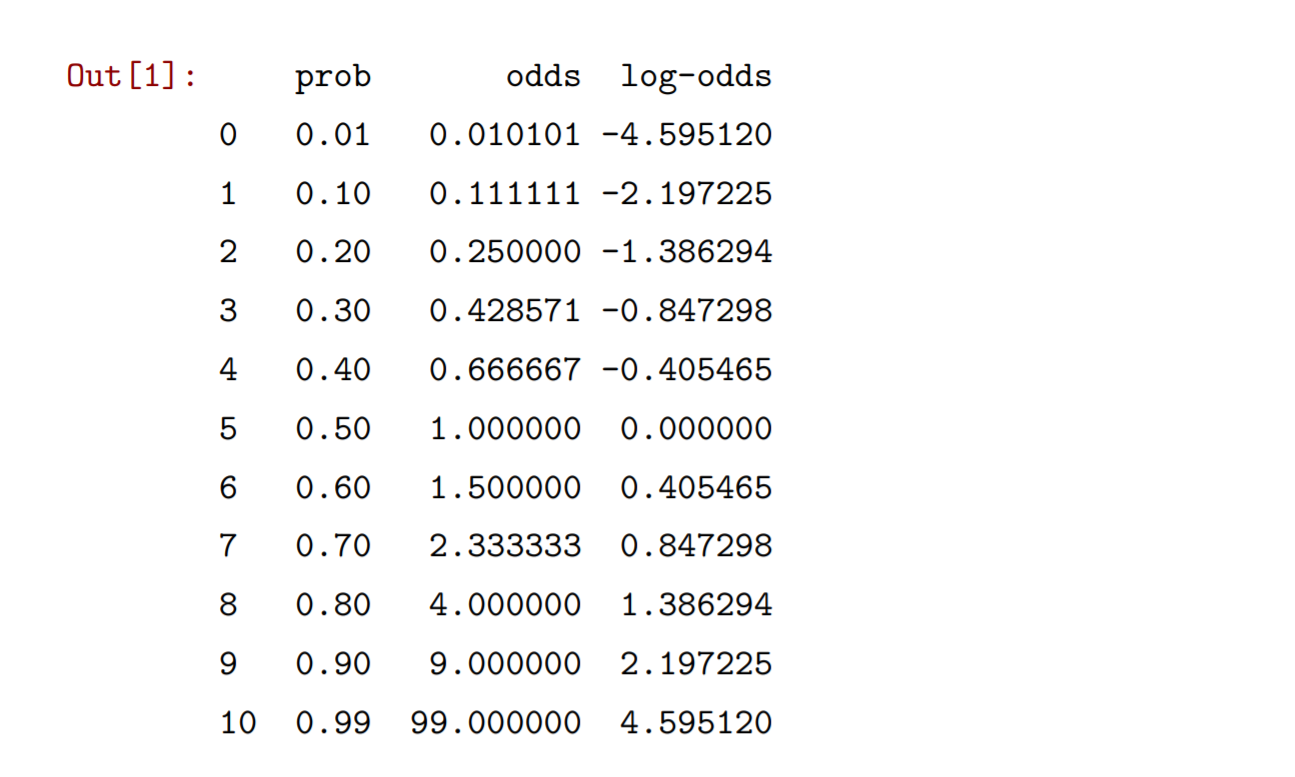
通过结果可以看到几率都是正数,而对数几率则有正有负,并且关于.0,0.5对称。还可以画出三个变量的曲线
#plt.subplot(2,2,1)plt.plot(table['prob'],'g')plt.plot(table['odds'],'y')plt.plot(table['log-odds'],'m')plt.legend({'probability','Odds','log_odds'})plt.ylim([-6,6])
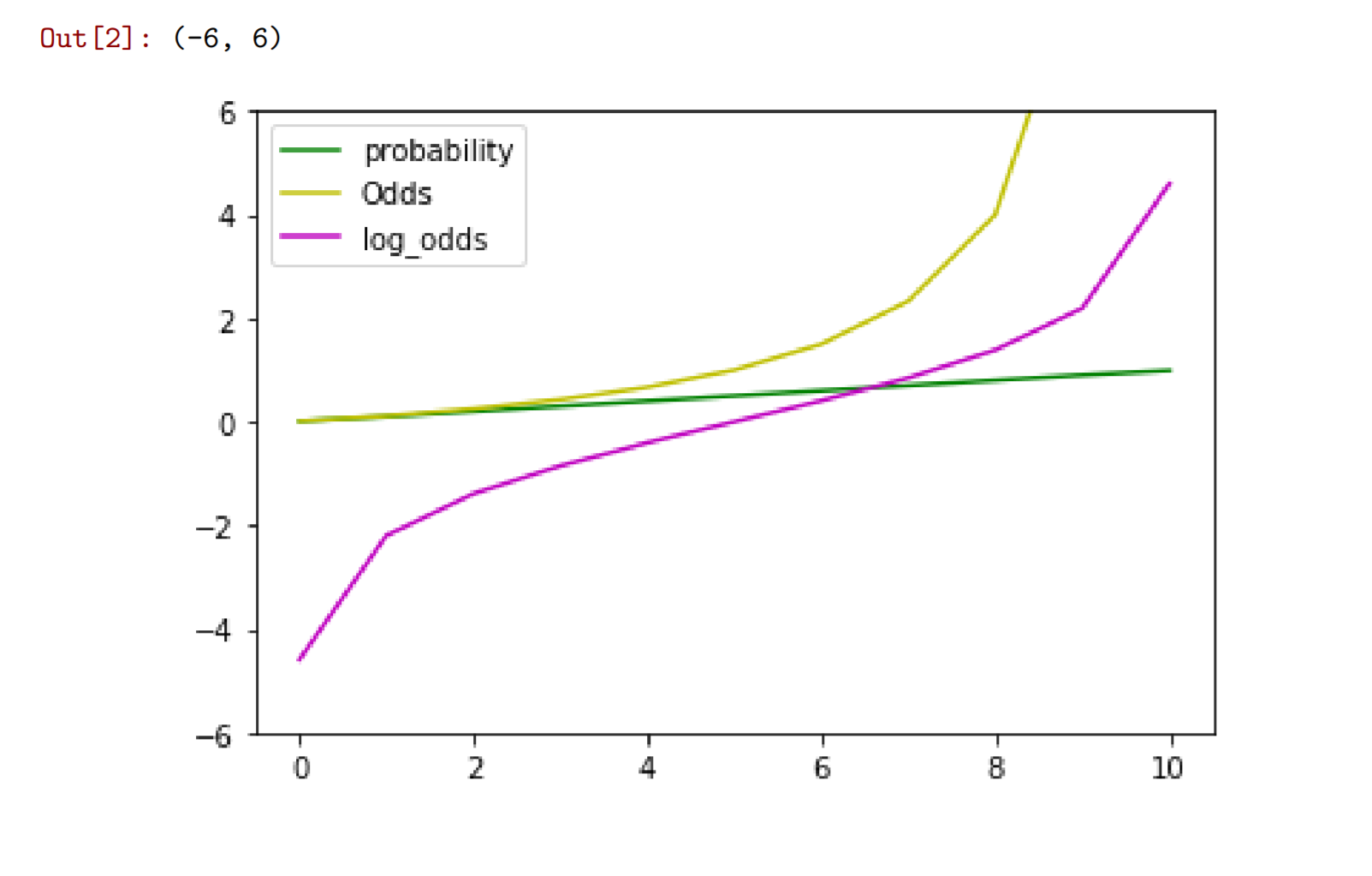
对数几率的值域:
基于样本的特征构建线性函数,函数值对应事件的对数几率。
:::success Logistic回归就是对几率做线性回归。 ::: 优化准则:极大化所有样本的对数似然函数。
:::info
sklearn库
—linear_model模块
一LogisticRegression对象
可以做Logistic回归
:::
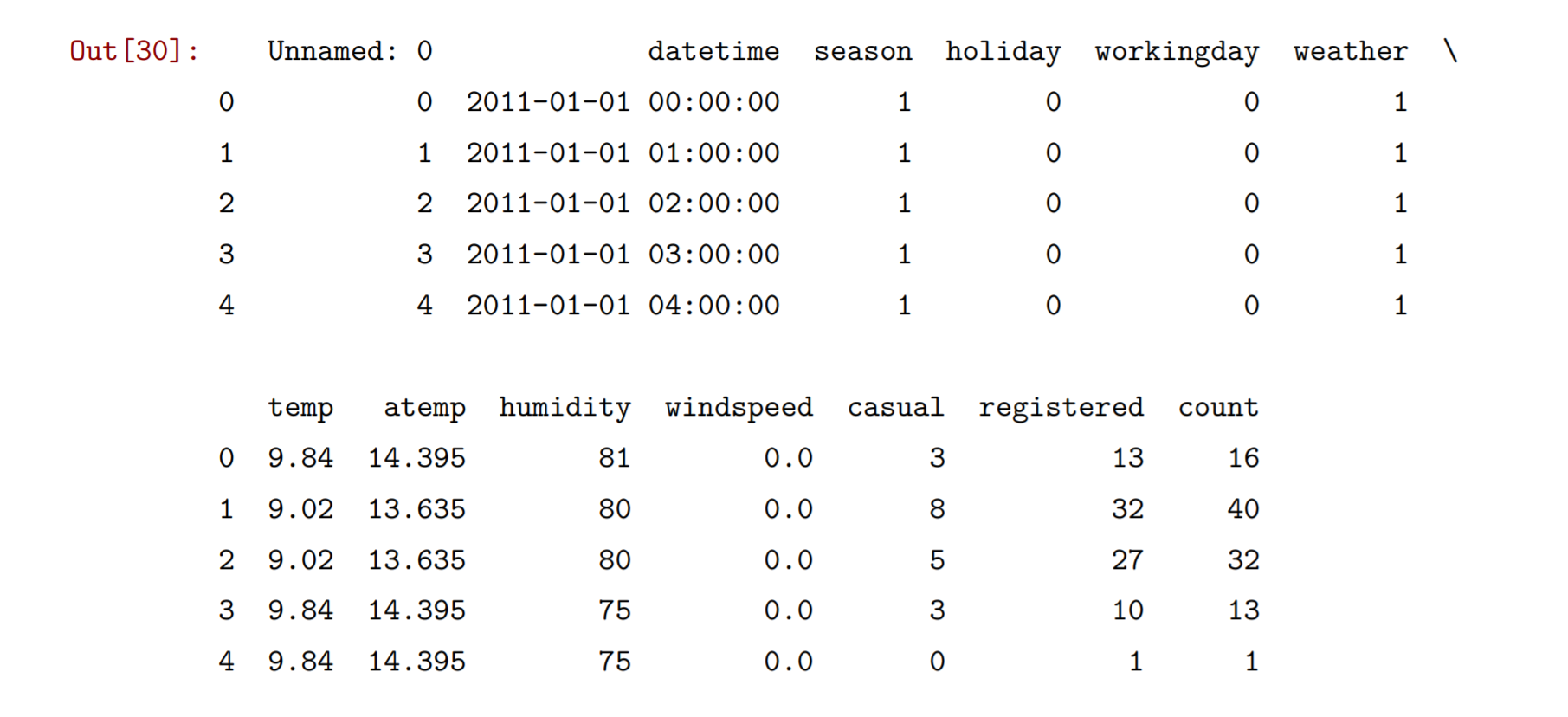
import pandas as pdimport numpy as npimport matplotlib.pyplot as pltfrom sklearn.linear_model import LogisticRegressionfrom sklearn import metricsfrom scipy import statsfrom sklearn.model_selection import train_test_splitbikes=pd.read_csv("C:\Python\Scripts\my_data\\bikeshare.csv")# 注意\b 是转义字符,表示退格,所以\\表示\本身print(bikes.shape)

bikes.head()
阶段1:建模
训练集:建立模型时给模型的数据。
阶段2:模型应用
测试集:模型建立后,用来测试模型性能的数据。
feature_cols=['temp']x=bikes[feature_cols]bikes['above_average']=bikes['count']>=bikes['count'].mean()y=bikes['count']>=bikes['count'].mean()x_train,x_test,y_train,y_test=train_test_split(x,y)logreg=LogisticRegression()logreg.fit(x_train,y_train)#print((y_test.values))print(pd.DataFrame(np.transpose([y_test.values,logreg.predict(x_test)]),columns={'真实值','预测值'}))print('\n')print('分类准确率是:',logreg.score(x_test,y_test)) # 评分函数


对于四季非数值型数据数据的处理,可以做one-hot编码
| 特征取值\编码 | 编码_1 | 编码_2 | 编码_3 | 编码_4 |
|---|---|---|---|---|
| 1 | 1 | 0 | 0 | 0 |
| 2 | 0 | 1 | 0 | 0 |
| 3 | 0 | 0 | 1 | 0 |
| 4 | 0 | 0 | 0 | 1 |
四位二进制码,编码长度=类别个数
可以将四季转换为4位的二进制编码。可以使用Pandas中的 get_dummies 函数进行四季的one-hot编码转换。
bikes.groupby('season').above_average.mean().plot(kind='bar')when_dummies=pd.get_dummies(bikes['season'],prefix='season_')when_dummies.head()
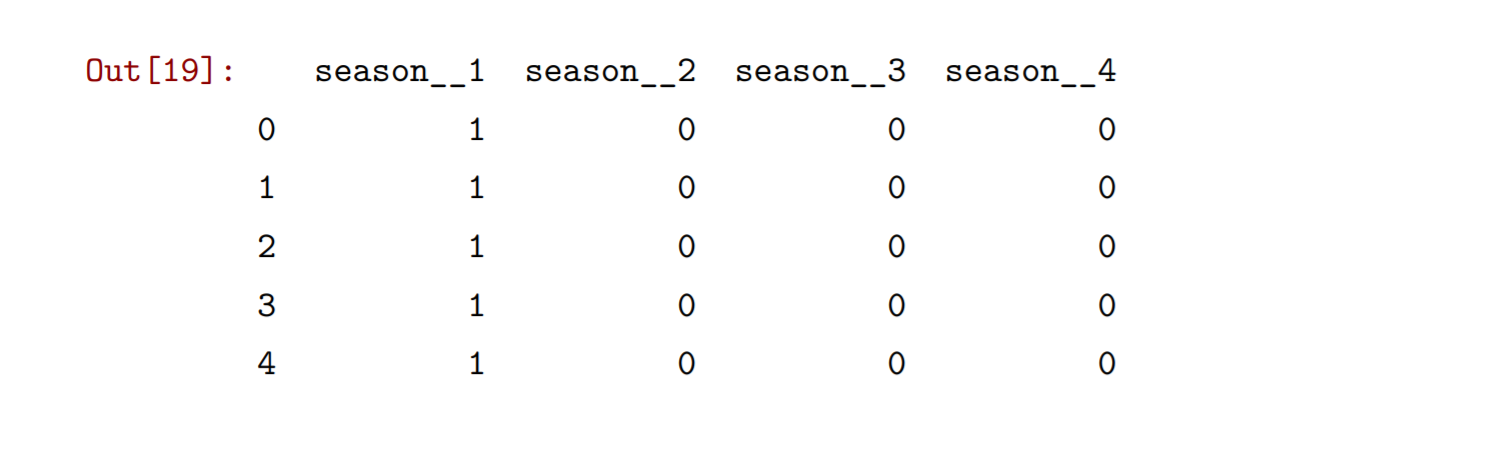
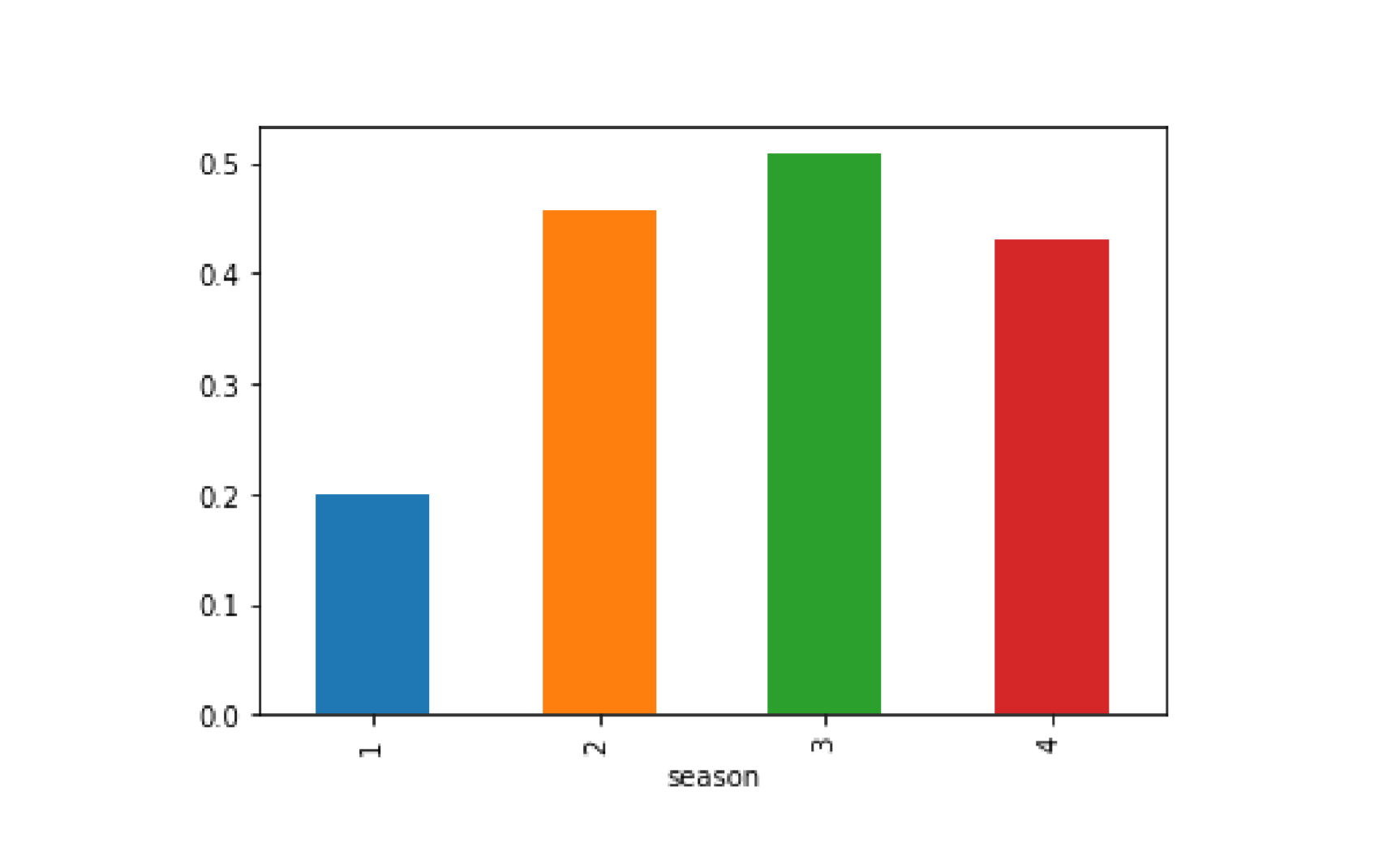
使用转换后四季的编码重新构建Logistic回归模型
when_dummies=when_dummies.iloc[:,1:] # 去除第一列when_dummies.head()#new_bike=pd.concat([bikes[['temp','humidity']],when_dummies],axis=1)new_bike=pd.concat([bikes[['temp']],when_dummies],axis=1)x=new_bikex_train,x_test,y_train,y_test=train_test_split(x,y)logreg=LogisticRegression()logreg.fit(x_train,y_train)y_pred=logreg.predict(x_test)#print(y_pred)print('用气温、季节同时作为预测自变量,预测的准确率为:',logreg.score(x_test,y_test))

逻辑回归的评价依据
分类的准确率,即准确分类的样本数除以样本容量。

若有收获,就点个赞吧
0 人点赞
