基本概念
数据:传感器采集到的各种物理、生物、化学指标等等各种可记录、可表征的数量、性质都是数据。现实中某种事物或事物间关系数量或性质的表征与记录,都称之为数据。
大数据(Big Data)的4V特点
体量大( high Volume )
速度快时效高( high Velocity )
类型繁多( high Variety )
价值密度低( High Veracity )
数据分析的三大变革
随机样本→全体数据【相对的】
精确性→混杂性【不能OR不必?】
因果关系→相关关系
| 应用层面 | 有一定适用性 |
|---|---|
| 科学层面 | 并未获得学术届一致认可 |
数据科学
定义
应用科学的方法、流程、算法和系统从多种形式的结构化或非结构化数据中提取知识和洞见的交叉学科。 ——维基百科
数据科学的范畴
- 搜集
- 存储
- 分类
- 处理
- 分析
-
数据科学项目中的人员
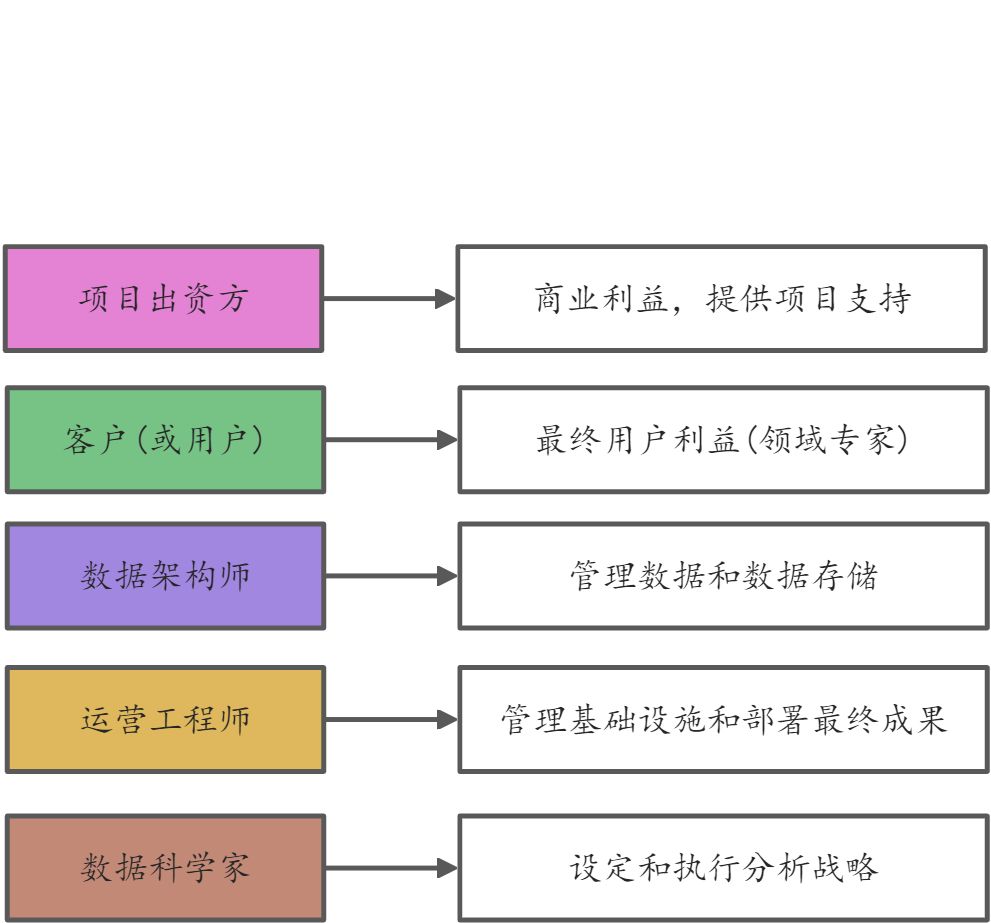
数据科学家的职责 设定项目战略
- 挑选数据源及工具
- 保证客户知悉
- 技术层面工作(数据的检查、处理、分析、评价)
-
数据科学项目的典型流程
问题的确定
用户层面
出资方的动机和需求?
-
数据科学层面
现实问题的抽象化描逑预测?
分类?打分或排名?聚类?关联?特征化?制定目标
应用层面
- 模型(数据科学)层面
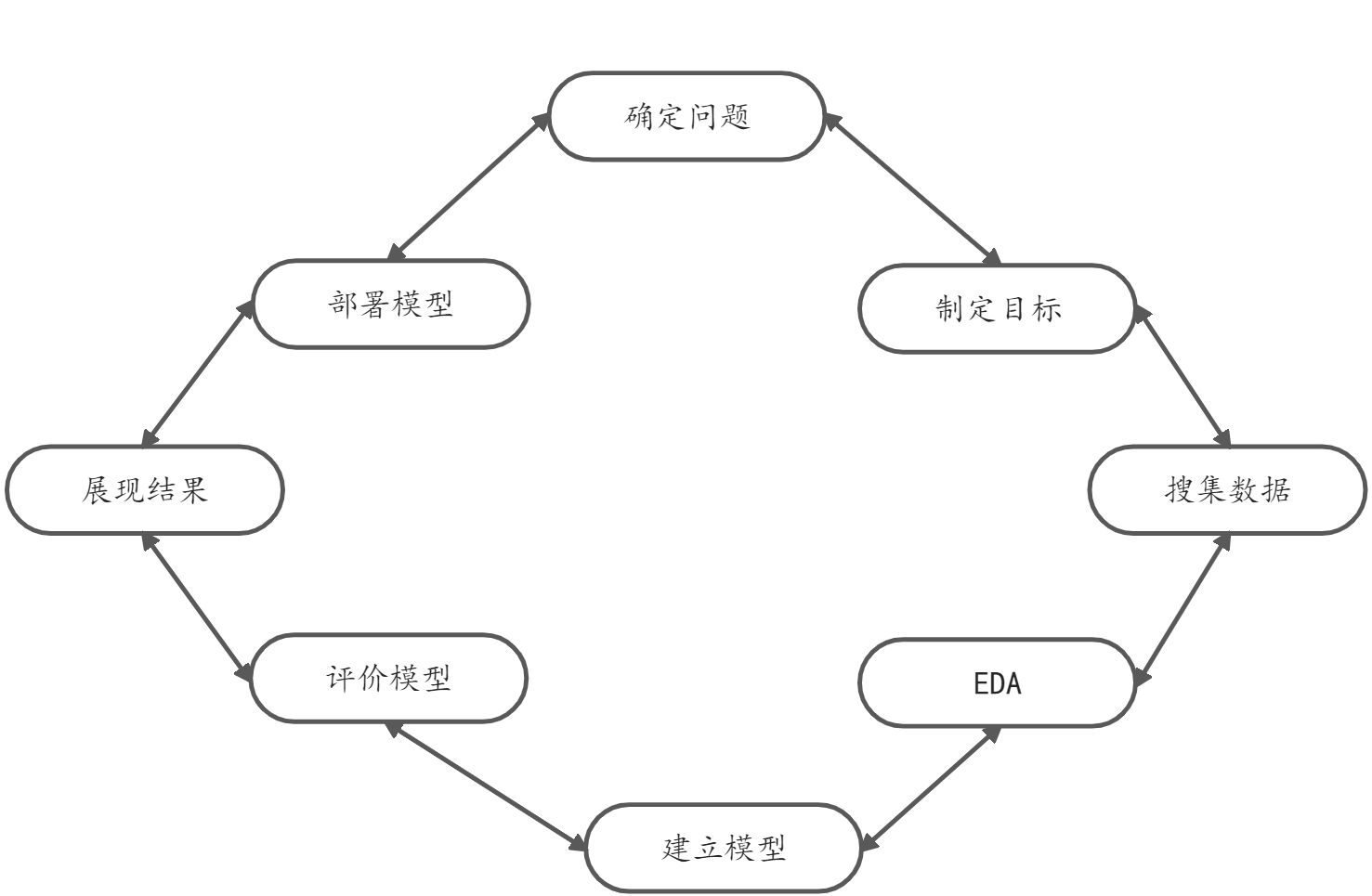
收集数据
第二步设计并实施实验
我能得到什么数据?
有助于解决问题吗?
数据量是多少?
数据质量如何?
探索性数据分析(简称EDA)
建立模型(分析)
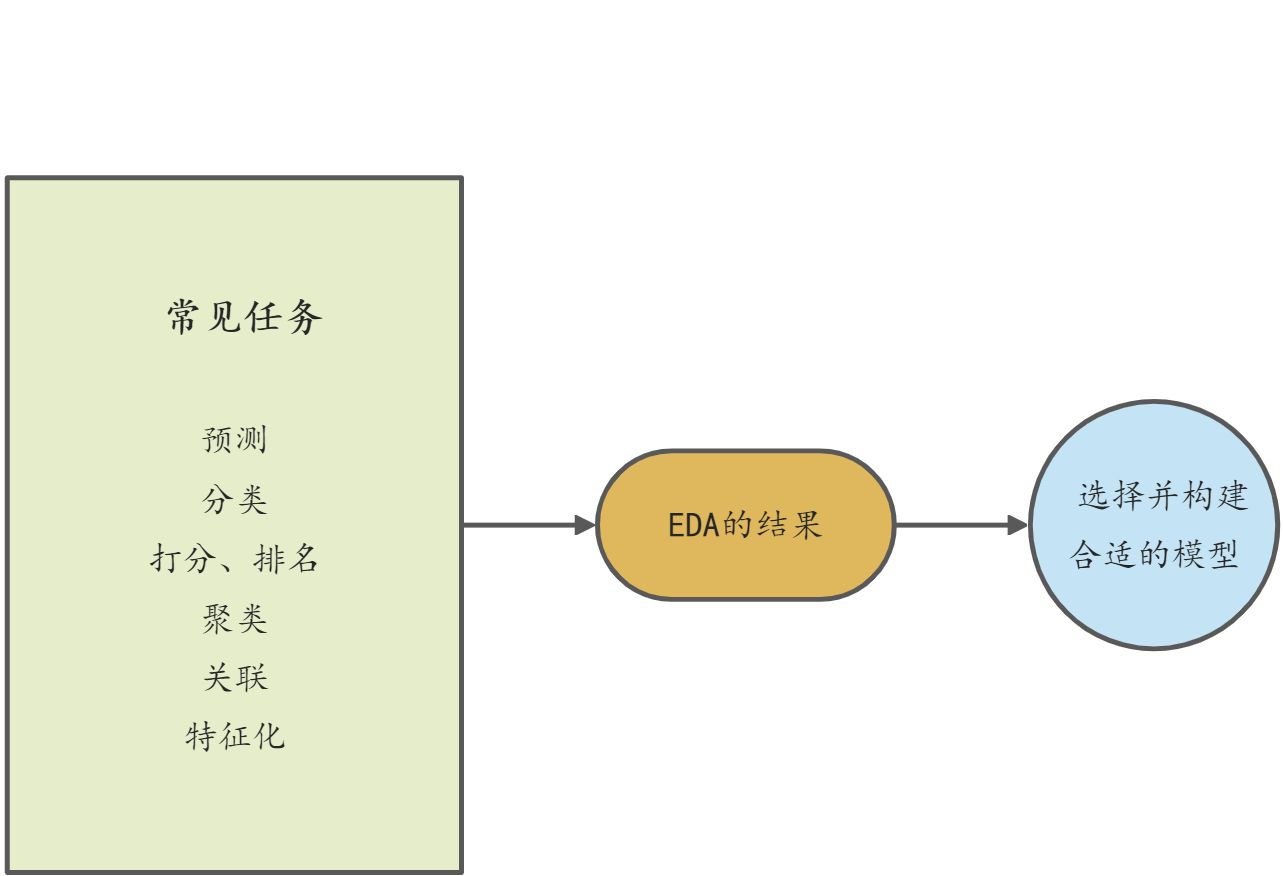
常见的模型
- 统计学模型
- 回归(线性、Logistic )
- 贝叶斯分类器
- 神经网络
- 随机森林
评价模型
混淆矩阵
ROC曲线和AUC
统计检验p-value
置信区间
专业领域指标指标做到多少算是可接受呢?
有效的数据科学模型评价指标需优于以往实现、同类任务的模型所实现的指标
不了解以往工作的情况下→至少要优于空模型【最简单的模型】的指标展现结果
部署模型
Python数据科学常用的库
SciPy:科学算法如线性代数、信号与图像处理、优化、FFT;
Pandas:特有数据结构;
Scikit-learn:预处理、监督/无监督学习、模式选择、验证和误差指标;
Matplotlib:绘图。
数据的导入与准备
NumPy.loadtxt方法
①将指定文件中的数据加载到数组
②支持纯文本文件,如后缀名为txt文件和csv文件
③返回NumPy的ndarray多维数组
④—般用来加载数据类型一致的数据文件
#loadtxtimport numpy as npx=np.loadtxt('C:\Python\Scripts\my_data\global-earthquakes.csv', delimiter=',')# 注意调用方法时的参数传递语法print(type(x))print(x.shape)print('\n')print(x[:2,:3]) #ndarray 的二维切取x_int=np.loadtxt('global-earthquakes.csv', delimiter=',', dtype=int)print('\n')print(x_int[:2,:3])
loadtxt读取电子表格数据并以二维数组(矩阵)的形式返j默认电子表格中原始数据类型是一致的。
不一致时?则尝试转换成一致,不成功则会报错。
Pandas.read_csv方法
面对数据并不统一的电子表格数据则更倾向于Pandas.read_csv方法,Pandas.read_csv方法会将电子表格文件中数据转换为Pandas的DataFrame结构。
#read_csvimport pandas as pddata=pd.read_csv('C:\Python\Scripts\my_data\iris.csv',header=None,names=['sepal_len','sepal_wid','petal_len','petal_wid','target'])print(type(data))print('\n')print(data.head())print('\n')
获取在线文件——使用Python自带的urllib模块
urllib.request.urlopen方法
import urllibtarget_page='https://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets/binary/a1a'a2a=urllib.request.urlopen(target_page)from sklearn.datasets import load_svmlight_filex_train, y_train = load_svmlight_file(a2a) # 这里是 Python 风格的多重赋值print (x_train.shape, y_train.shape)print(x_train[:1][:100]) #x_train 是个稀疏矩阵,返回的是矩阵中非零元素的位置print(type(x_train))print('\n')print(y_train[:10])print(type(y_train))
非结构化数据的格式化处理
对于非结构化的数据,要处理成结构化便于处理的表格形式。
# 文本信息结构化示例from sklearn.datasets import fetch_20newsgroupsmy_news=fetch_20newsgroups(categories=['sci.med']) # 下载医学新闻数据集print(type(my_news),'\n')print(twenty_sci_news.data[0],'\n')from sklearn.feature_extraction.text import CountVectorizercount_vect=CountVectorizer()word_count=count_vect.fit_transform(my_news.data) # 返回一个稀疏矩阵对象print(type(word_count))print(word_count.shape,'\n')print(word_count[0]) # 第一行上非零元素的坐标(元组表示)以及频次word_list=count_vect.get_feature_names()for n in word_count[0].indices:print(word_list[n],'\t appears ', word_count[0,n],'times') # 打印第一篇新闻的字频情况
对大数据的读取
数据量过大时,应该以连续流的方式流入,而非一次性加载
import pandas as pdmy_chunk=pd.read_csv('C:\Python\Scripts\my_data\iris.csv',header=None,names=['c1','c2','c3','c4','c5'],chunksize=20)print(type(my_chunk))# 注意规定 chunksize 后,返回的数据类型不再是 DataFrame# 而是一个可迭代的 TextFileReader 对象# 它保存了若干个 chunk 位置,但只有当被迭代器指到时,才会真正把对应的数据块读入到内存for n,chunk in enumerate(my_chunk): # 枚举函数既返回元素序号,又返回每个元素print(chunk.shape)if n <= 2:print(chunk) # 每一个 chunk 又是一个 DataFrameprint('\n')if n <= 2:print(my_chunk.get_chunk(1),'\n')#get_chunk 函数是从当前位置起获取指定大小的数据块,返回也是 dataframe#get_chunk 会改变迭代器指针
csv包中的reader函数和DictReader函数也可以实现小块数据的迭代
import numpy as npimport pandas as pdimport csvwith open('C:\Python\Scripts\my_data\iris.csv','r') as my_data_stream:#with 命令保证后面缩进的命令块执行完毕后文件会关闭# 用 open 命令以只读方式打开文件,创建的文件对象保存在 my_data_stream 中# 用 csv.reader 对给定的文件对象读取,一次读取文件中的一行,作为列表对象# 这里的 reader 返回的是迭代器对象my_reader=csv.reader(my_data_stream,dialect='excel')for n,row in enumerate(my_reader):if n<=5:print(row) # 可见每个 row 都是一个列表print(type(row),'\n')
import numpy as npimport pandas as pdimport csvdef batch_read(filename, batch=5): # 注意自定义函数的语法with open(filename,'r') as data_stream:#with 命令保证后面缩进的命令块执行完毕后文件会关闭# 用 open 命令以只读方式打开文件,创建的文件对象保存在 data_stream 中batch_output=list() # 初始化 batch_output 列表# 用 csv.reader 对给定的文件对象读取,一次读取文件中的一行,作为列表的一个元素# 这里的 reader 返回的是迭代器对象for n,row in enumerate(csv.reader(data_stream,dialect='excel')):# 枚举函数返回包含行号和行内容的元组#for 循环遍历 reader 返回的列表if n>0 and n%batch==0:#yield 属生成器,类似于 return,但可迭代复用,# 下句把 batch_output 列表转换为 ndarray 返回yield(np.array(batch_output))batch_output=list() # 重置 batch_outputbatch_output.append(row) # 更新 batch_outputyield(np.array(batch_output)) # 返回最后的几行for batch_input in batch_read('C:\Python\Scripts\my_data\iris.csv',batch=7):# 注意允许修改默认参数print(batch_input)print('\n')
探索性数据分析
EDA目的探索性数据分析,简称EDA
- 初步了解数据集
- 验证初步假设
- EDA的基本流程与常用方法
- EDA后的数据处理与清洗
- 必要补充
EDA的流程
- 数据检查与预处理
数据检查:数据的规模与特征的数据类型及意义
预处理∶缺失处理
异常处理冗余处理
- 数据的初步分析
import pandas as pdmy_data = pd.read_csv("C:\Python\Scripts\my_data\Titanic.csv")my_dataprint(my_data.info()) # 这里可以看到,dataframe 的 info 方法能返回对数据的一些总结<class 'pandas.core.frame.DataFrame'>RangeIndex: 891 entries, 0 to 890Data columns (total 12 columns):PassengerId 891 non-null int64Survived 891 non-null int64Pclass 891 non-null int64Name 891 non-null objectSex 891 non-null objectAge 714 non-null float64SibSp 891 non-null int64Parch 891 non-null int64Ticket 891 non-null objectFare 891 non-null float64Cabin 204 non-null objectEmbarked 889 non-null objectdtypes: float64(2), int64(5), object(5)memory usage: 83.6+ KB
数据类型的判断以及后期的作用
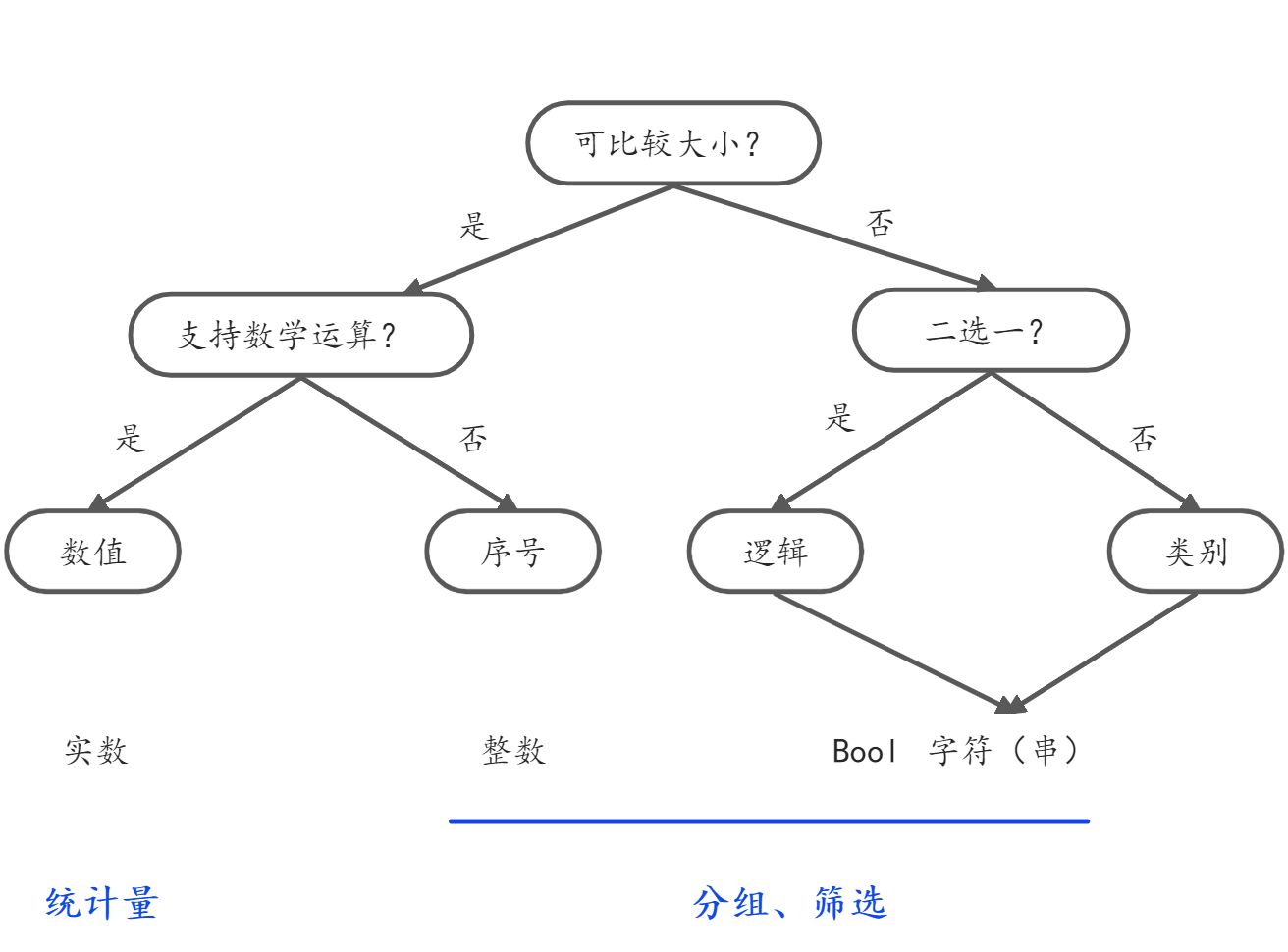
数据的问题
数据有缺失吗?要如何处理?
数据有明显异常吗?怎么处理?
数据有冗余吗?怎么处理?缺失数据(用NaN来表示)
直接丢弃?
dataframe.dropna函数(样本容量大,缺失信息少)import pandas as pdimport numpy as npmy_data = pd.read_csv("C:\Python\Scripts\my_data\Titanic.csv")my_data.head(15)# 设置参数axis=0则丢弃所有有Nan的行my_fil_data1=my_data.dropna(axis=0)my_fil_data1.head(7)# 设置参数axis=0则丢弃所有有Nan的列my_fil_data2=my_data.dropna(axis=1)my_fil_data2.head(7)
做特定的替代?
dataframe.fillna方法(样本容量小,无法承受信息进一步缺失,将缺失值进行替换处理) ```python mean_Age=int(my_data[[‘Age’]].mean()[0]) my_dict={‘Age’:mean_Age,’Cabin’:’haha’} my_fil_data3=my_data.fillna(my_dict) my_fil_data3.head(7)
如果不用固定值来填充缺失项,fillna还提供用邻近值来填充的选择。
method=’ffill’表示使用缺失值之前的有效值进行填充
my_fil_data4=my_data.fillna(method=’ffill’) my_fil_data4.head(7)
method=’bfill’表示使用缺失值之后的有效值进行填充
my_fil_data5=my_data.fillna(method=’bfill’) my_fil_data5.head(7)
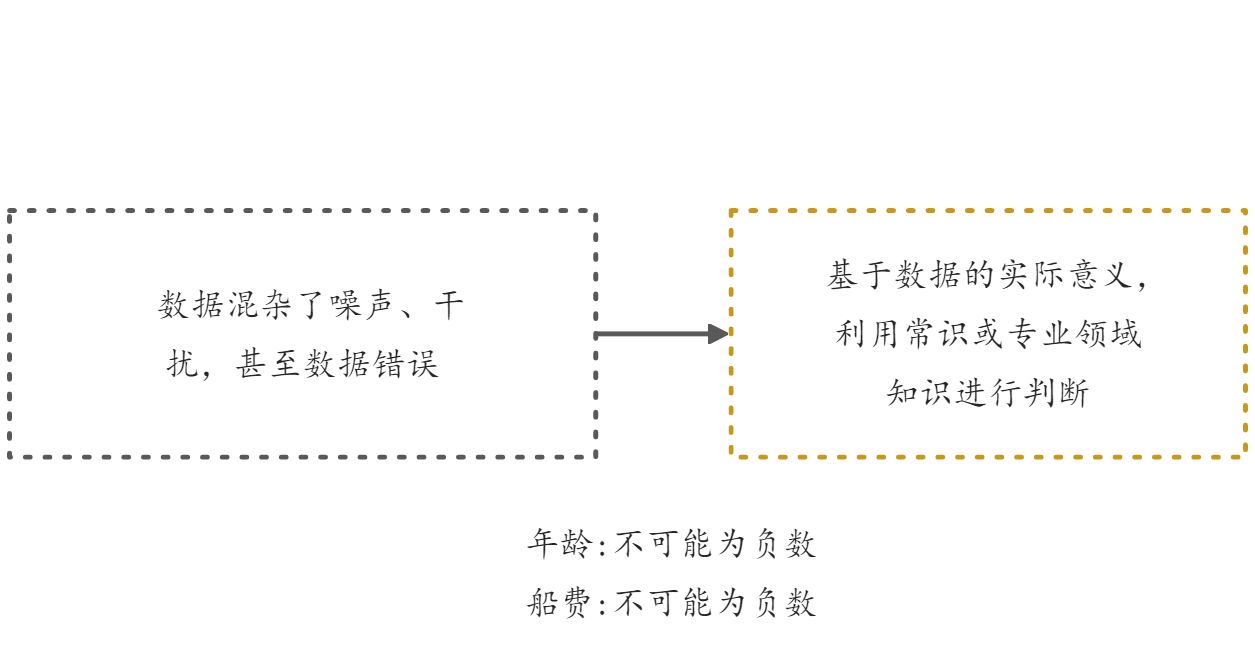<a name="OxPIu"></a>#### 服从正态分布的数据:z-score(无量纲)<br />Z-score >3怀疑异常<a name="D1udO"></a>#### 不服从正态分布的数据使用四分位距方法处理q1——第1个四分位数<br />q3——第3个四分位数<br />——四分位距<a name="FSBVS"></a>### 异常值| 情况 | 处理方法 || --- | --- || 确定是出错的数据 | 丢弃和替换 || 不能肯定是错误 | 增加样本容量 |①确保样本能尽量真实反映总体<br />②减小异常值对于结果的影响<a name="GZqJr"></a>### 数据冗余数据中含有重复值,冗余数据在存储和计算中消耗更多的资源,并不能因此而提升性能,因此最好去除。```pythonimport pandas as pdstudent_scores=pd.DataFrame({'姓名':['张三']*3+['李四']*3+['王五']*3,'成绩':[10,10,10,8,8,8,5,5,5]})student_scores# duplicated()方法可以判断重复情况student_scores.duplicated()# drop_duplicates()可以直接删除重复值my_fil_data5=student_scores.drop_duplicates()my_fil_data5
不同特征出现冗余的情况
比如年收入是月平均收入的12倍,这两个特征是重复的,必须删除一个
如果一个特征可以通过将另一个特征线性变换得到,那么这两个特征就是重复的,可以去掉一个。
判断冗余特征常用方法——线性相关分析
判断冗余特征常用方法:线性相关分析使用Dataframe.corr函数
当method=pearson时,直接求线性相关系数
- 线性相关系数接近1或-1,则说明两个特征存在强的线性相关或反相关,有着较大的冗余;
线性相关系数等于0,则说明两个特征间没有线性相关性。
# 求鸢尾花数据每两个特征之间的相关性import pandas as pdimport numpy as npmy_data = pd.read_csv("C:\Python\Scripts\my_data\iris.csv",header=None,names=['sepal_length','sepal_width','petal_length','petal_width','target'])print(my_data.corr(method='pearson'))sepal_length sepal_width petal_length petal_widthsepal_length 1.000000 -0.109369 0.871754 0.817954sepal_width -0.109369 1.000000 -0.420516 -0.356544petal_length 0.871754 -0.420516 1.000000 0.962757petal_width 0.817954 -0.356544 0.962757 1.000000
数据的描述性统计
描述性统计
不对数据做任何预先地猜想,实事求是地分析样本数据是怎样的。
描述性统计结果→思考→形成一些初步结论或假设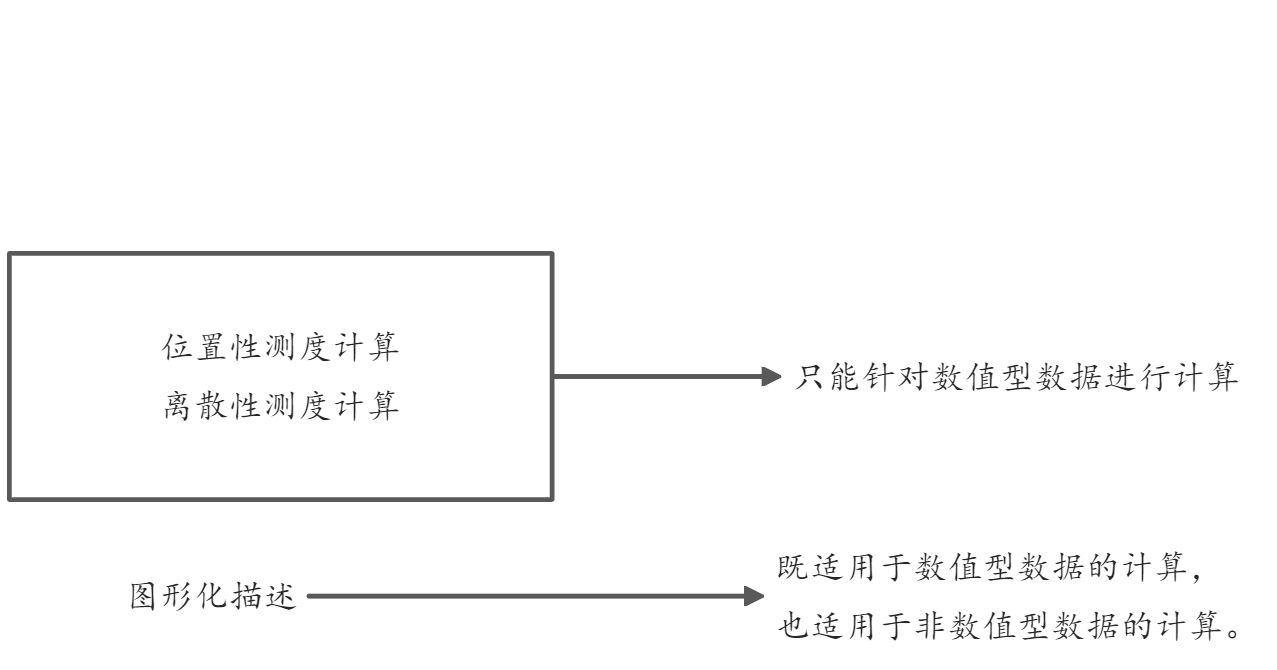
位置性测度计算
位置性测度主要用来反映样本集合的中心成员或特定成员在所考察的数域或空间中的位置。
算术平均( arithnetic mean )
- 定义:所有考察的样本值求统计平均。
- 算术平均容易受样本中的极端值影响。
- 中位数( median )
- 定义:将所有样本按数值从小到大或从大到小排序以后,最中间位置的一个数,或者两个数的平均。
- 中位数对极端值不敏感,但是对于中位数以外的所有值也都不敏感。
- p百分位数( quantiles )
- 定义:是将所有样本值按从小到大的顺序排好,排序在第p%的样本取值。第p个百分位数记为Vp→样本中有且仅有p%的观察值小于等于Vp
- 常用的p百分位数( quantiles )
- 第10百分位数
- 第25百分位数(又称第1四分位数)
- 第75百分位数(又称第3个四分位数)
- 第90百分位数
- 第50百分位数(中位数)
- 众数( mode )
- 定义:样本集中出现次数最多的那个值。(众数可能只有一个,也可能出现两个甚至更多)
```java
位置性测度
import pandas as pd import numpy as np my_data = pd.read_csv(“C:\Python\Scripts\my_data\Titanic.csv”) print(‘对 Fare 的位置性测度统计结果:’) print(‘均值:\t\t’,my_data[[‘Fare’]].mean()[0])mean 这里返回的是 series,可以用方括号序号来访问,下同
print(‘中位数:\t’,my_data[[‘Fare’]].median()[0]) print(‘第 25 个百分位数:’,my_data[[‘Fare’]].quantile(q=0.25)[0])q 参数指明第几个百分位数,默认值是 0.5
print(‘众数:\t\t’,my_data[[‘Fare’]].mode().values[0,0])mode 返回的是 dataframe,所以用 dataframe 的 values 属性获取值
values 本身是 ndarray,所以用二维数组的方式访问
- 定义:样本集中出现次数最多的那个值。(众数可能只有一个,也可能出现两个甚至更多)
```java
对 Fare 的位置性测度统计结果: 均值: 32.204207968574636 中位数: 14.4542 第 25 个百分位数: 7.9104 众数: 8.05
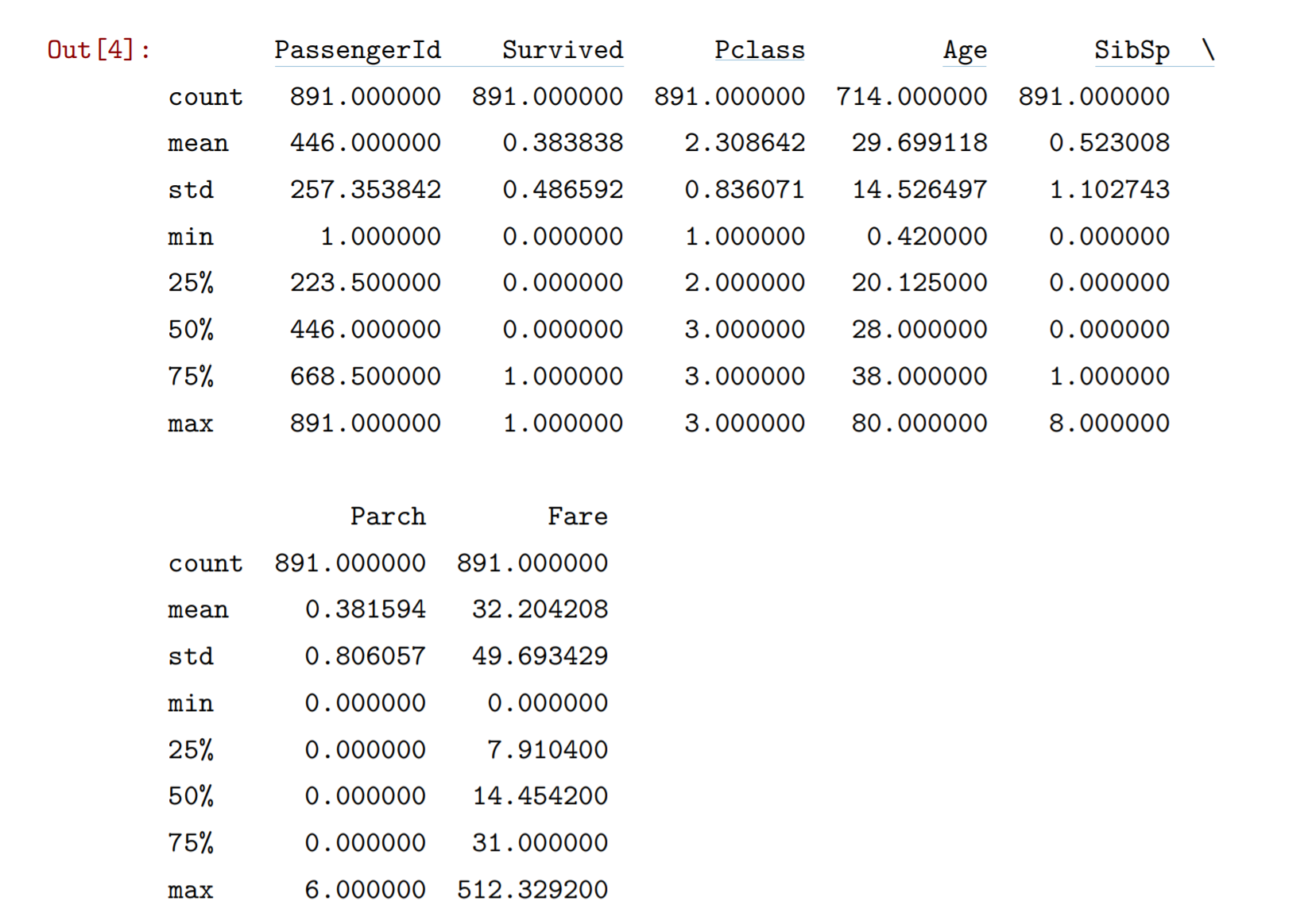
<a name="MNpea"></a>#### 离散性测度- 极差- 方差- 标准差- 变异系数极差( range ):指集合中最大与最小值之间的差异。<br />方差( variance ):对集合中所有样本值相对于均值的偏差的平方求近似平均。<br />标准差( Standard Deviation ):方差的平方根称为标准差。<br />方差与标准差可以总体衡量集合中数据偏离均值的程度。<br />在不同的物理量之间,方差或标准差是不好直接做比较的<br />变异系数( coefficient of variation,CV ) ——```java# 离散性测度print('对 Fare 的离散性测度统计结果:')print('变化范围:\t [',my_data[['Fare']].min()[0],'\t',my_data[['Fare']].max()[0],']')print('极差:\t\t',my_data[['Fare']].max()[0]-my_data[['Fare']].min()[0])print('方差:\t\t',my_data[['Fare']].var()[0])print('标准差:\t',my_data[['Fare']].std()[0])print('变异系数:\t',my_data[['Fare']].std()[0]/my_data[['Fare']].mean()[0])对 Fare 的离散性测度统计结果:变化范围: [ 0.0 512.3292 ]极差: 512.3292方差: 2469.436845743116标准差: 49.6934285971809变异系数: 1.5430725278408497# describe函数:对dataframe中所有用数值保存的特征(无论是整数还是浮点数),一次性计算多个常用的描迹性统计量。# print(my_data[['Fare']].describe())my_data.describe()
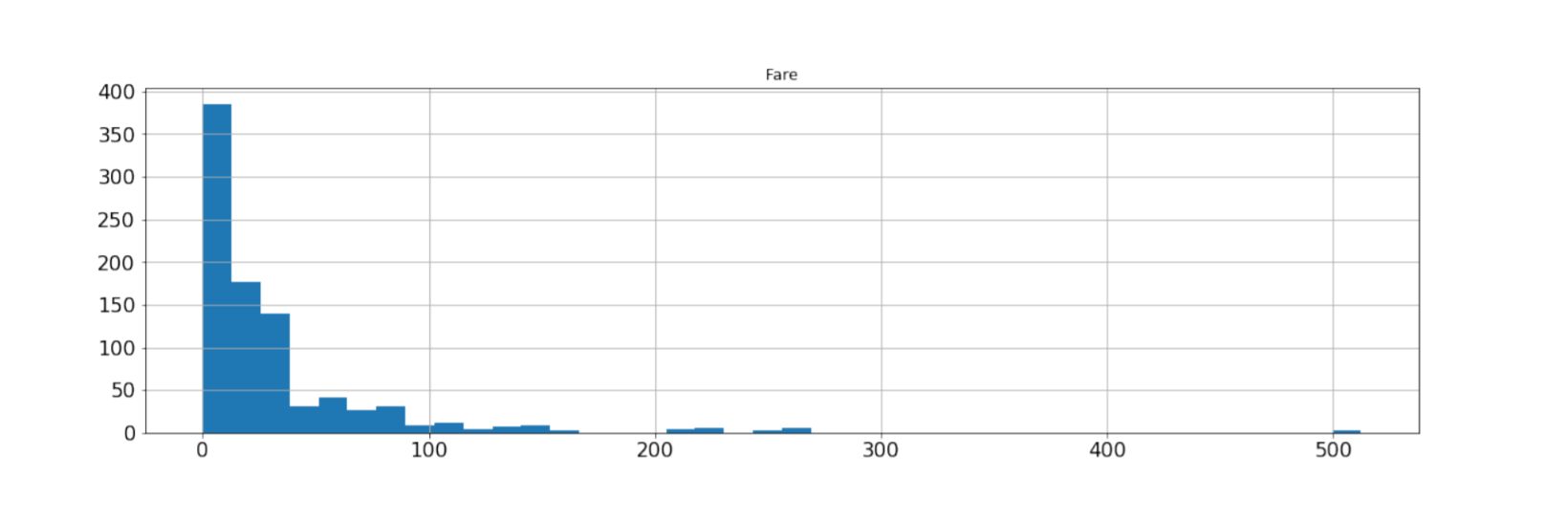
图形化方式:直方图和箱型图
直方图:一种反映数据分布的柱状统计图。
将数据分组,记录样本在每个组中出现的频数。
X轴———观测参数,分组( bin,通常保持一致)
Y轴———对应分组中的样本个数
my_data[['Fare']].hist(bins=40,figsize=(18,5),xlabelsize=16,ylabelsize=16)
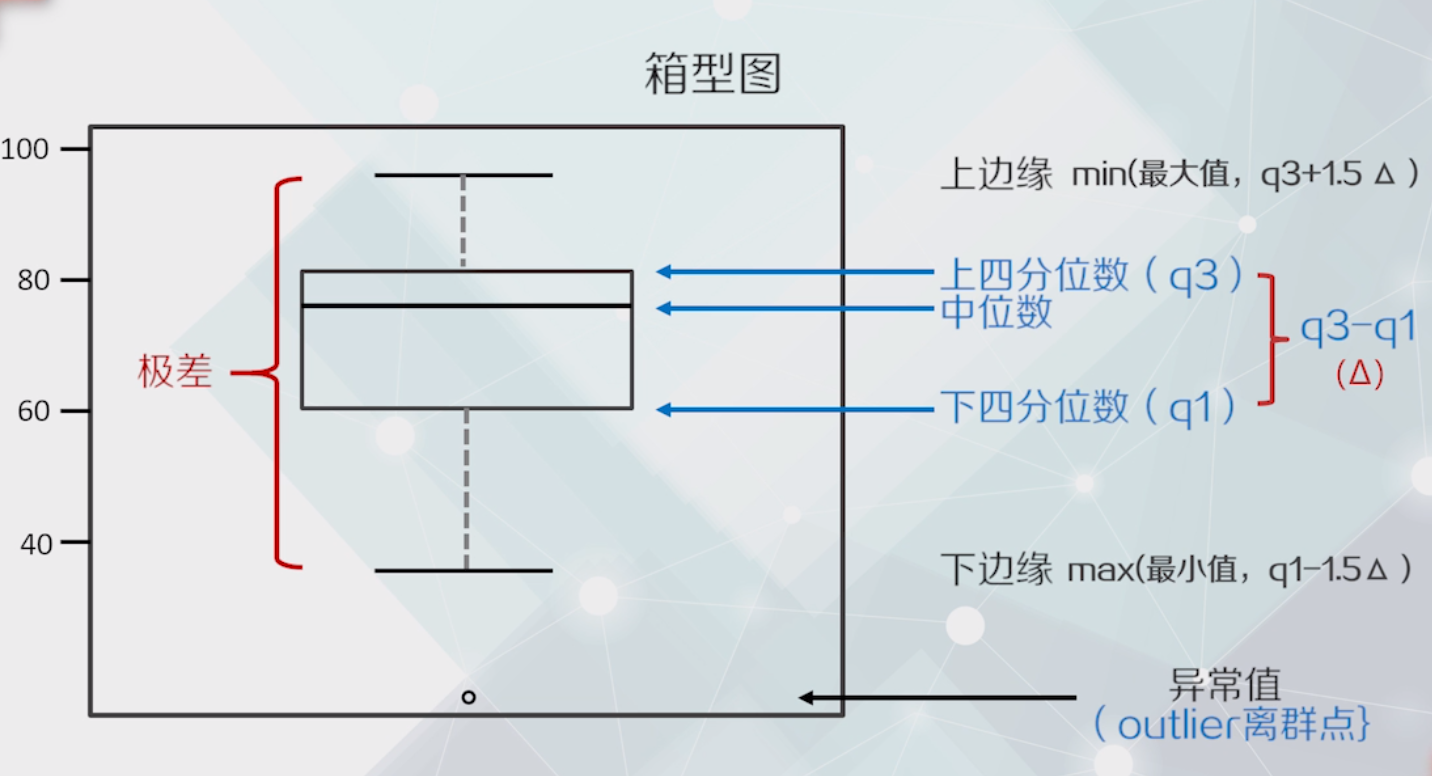
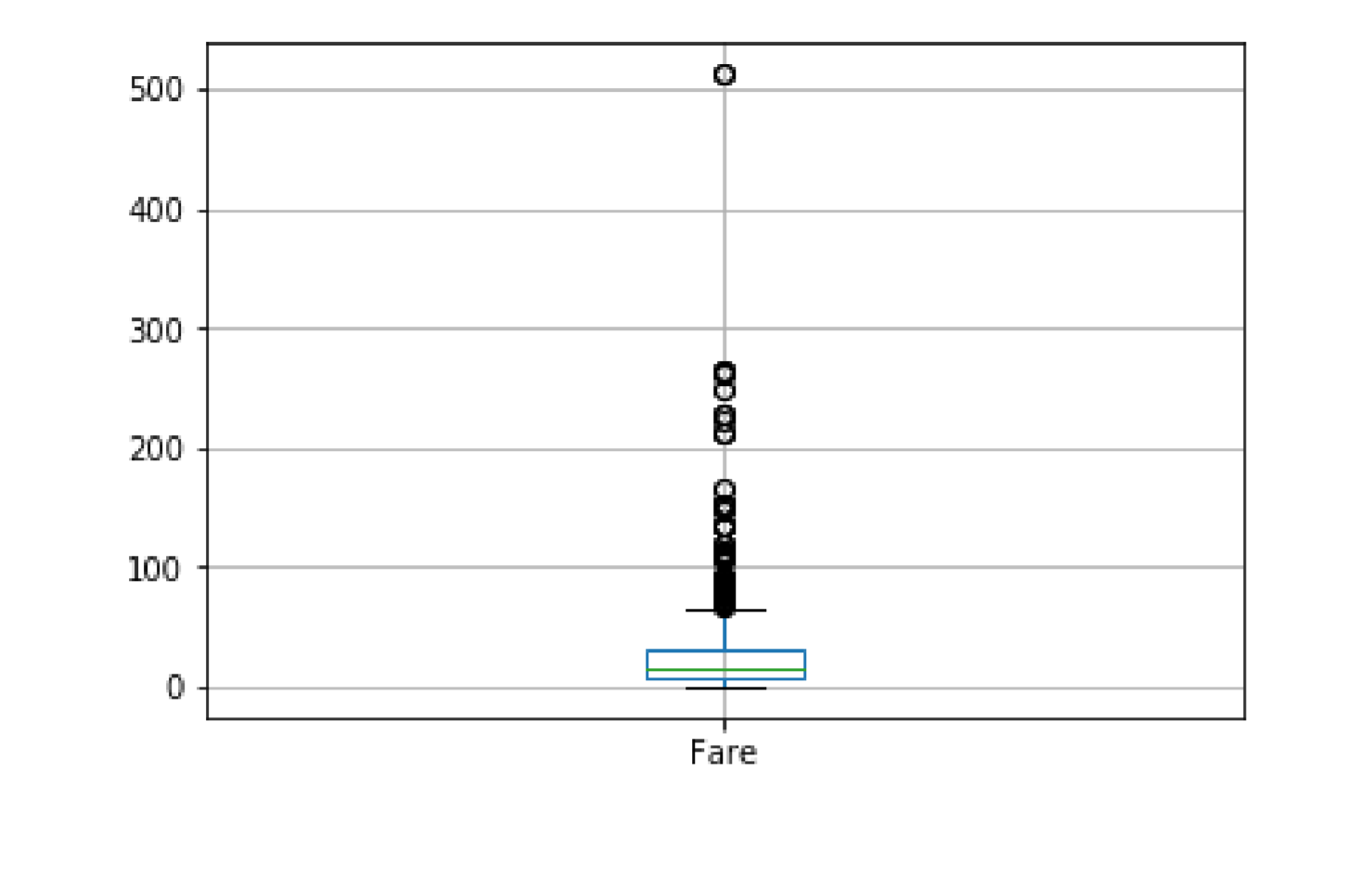
箱型图
my_data[['Fare']].boxplot()
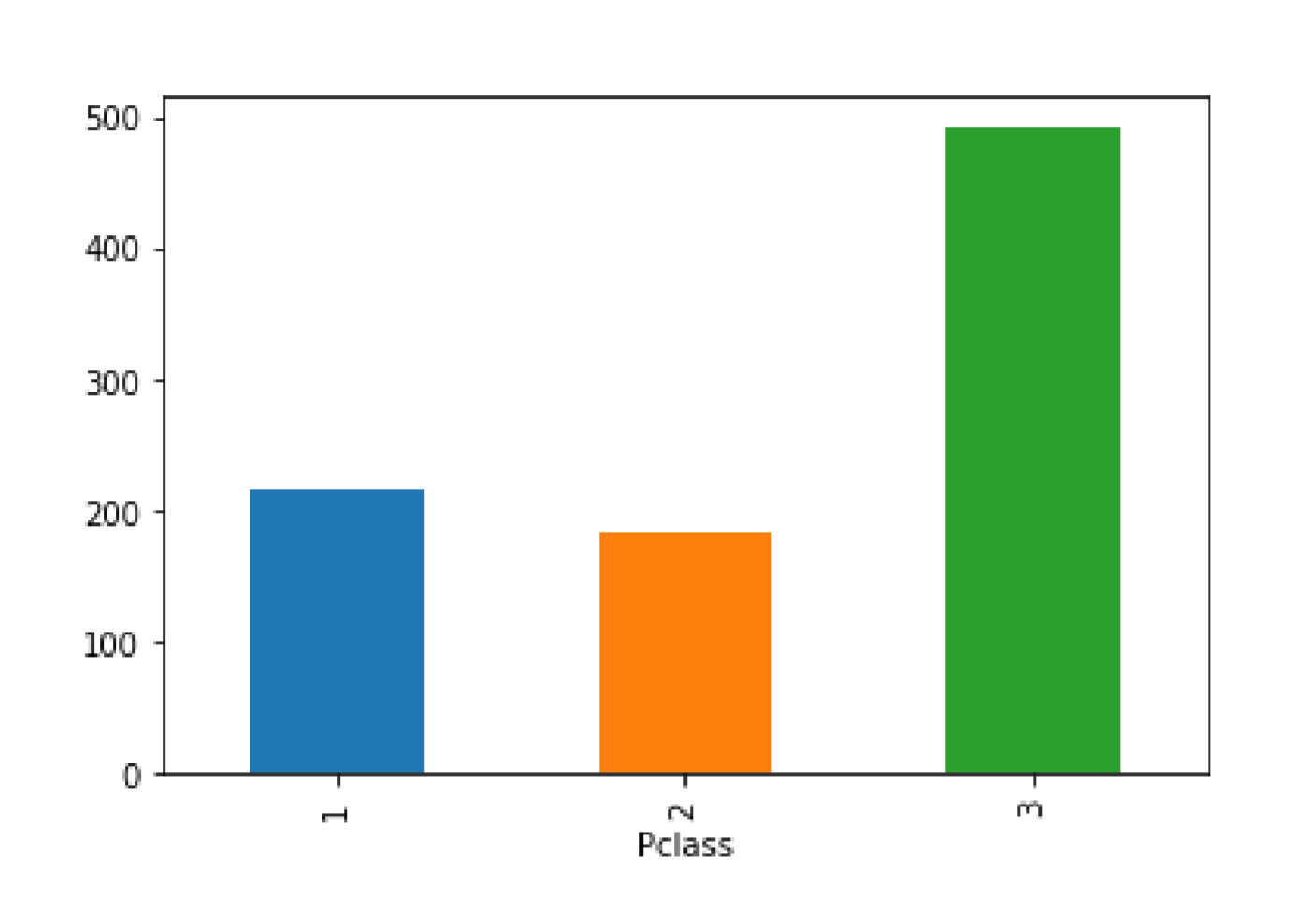
非数值型的特征
分组→对各组进行频次统计→绘制与直方图类似的柱状图
# 看数据在不同组的分布import pandas as pdimport numpy as npfrom matplotlib import pyplot as pltmy_data = pd.read_csv("C:\Python\Scripts\my_data\Titanic.csv")my_plot_data=my_data[['Pclass']].groupby(['Pclass']).size()print(my_plot_data)my_plot_data.plot(kind='bar')
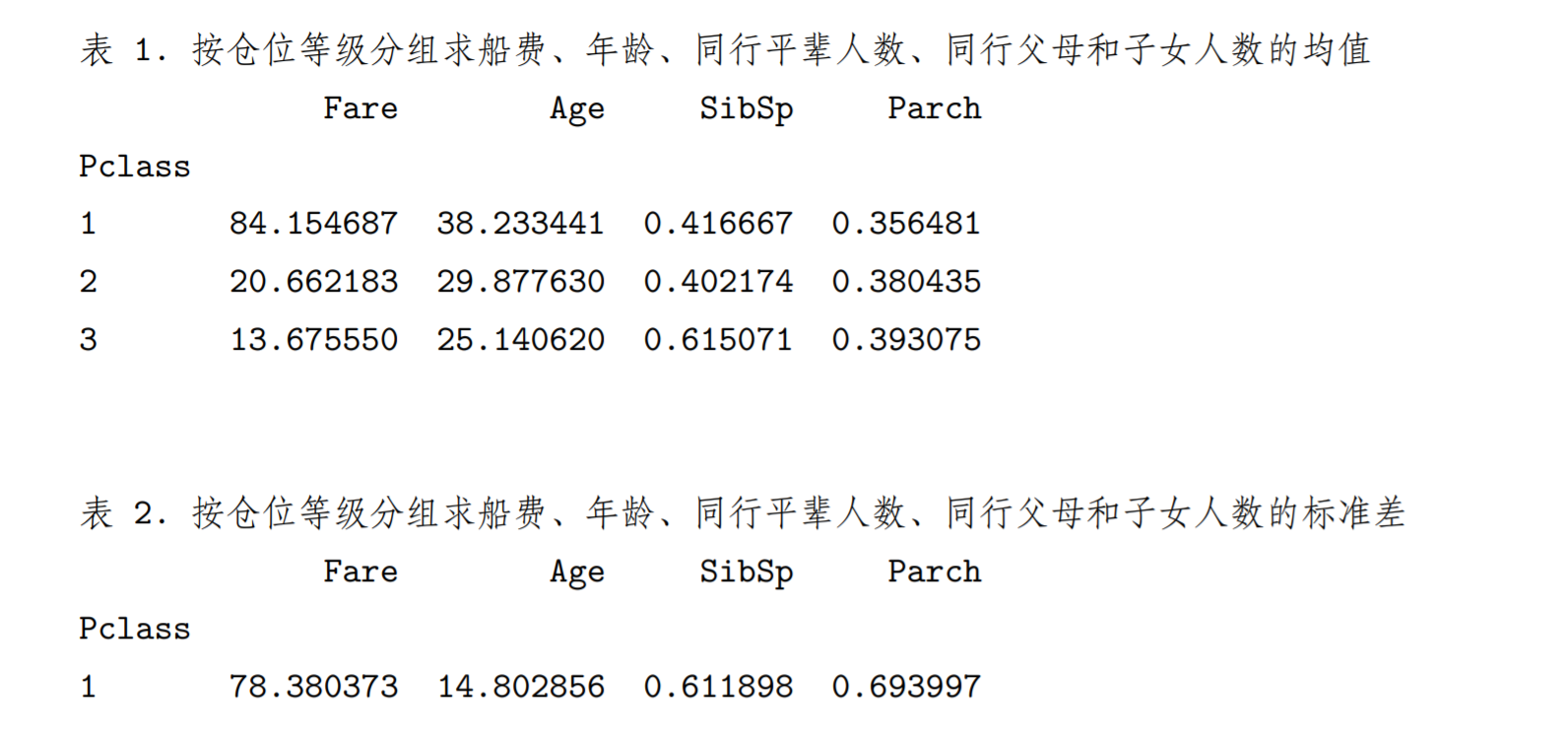
# 分组统计print('表 1. 按仓位等级分组求船费、年龄、同行平辈人数、同行父母和子女人数的均值')print(my_data[['Fare','Age','SibSp','Parch','Pclass']].groupby(['Pclass']).mean())print('\n\n表 2. 按仓位等级分组求船费、年龄、同行平辈人数、同行父母和子女人数的标准差')print(my_data[['Fare','Age','SibSp','Parch','Pclass']].groupby(['Pclass']).std())
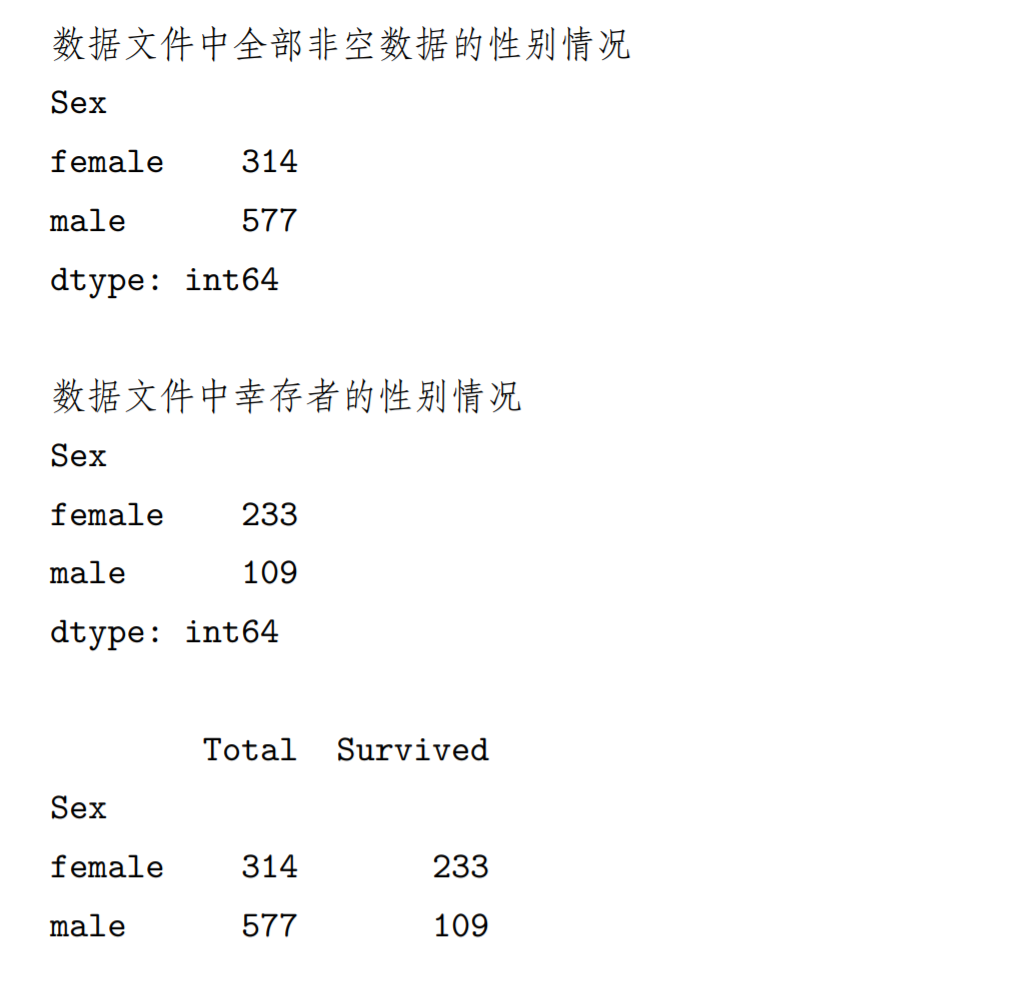
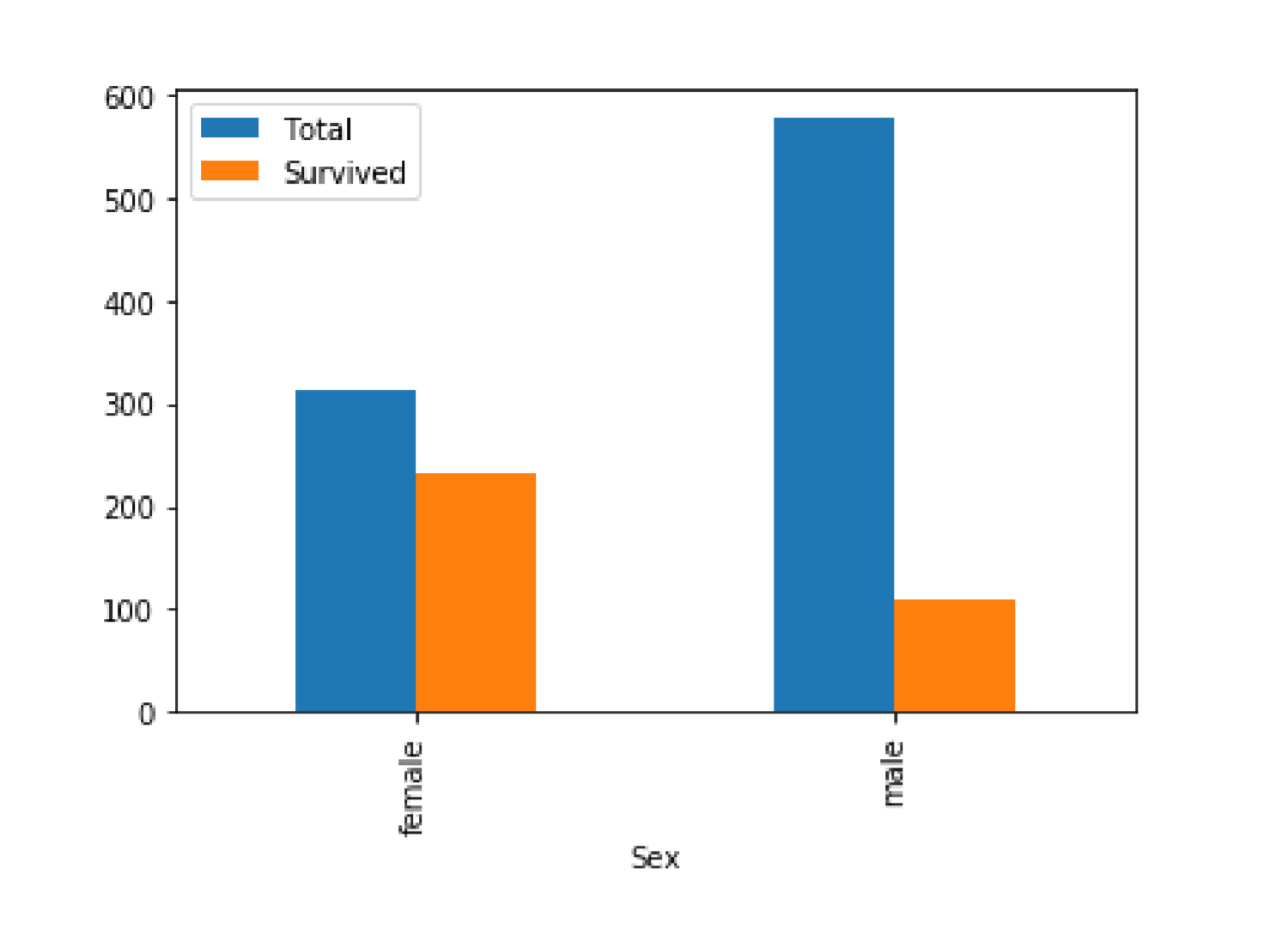
# 借助分组、筛选的图形化描述gender_dst_org=my_data[['Sex']].groupby(['Sex']).size()print('数据文件中全部非空数据的性别情况')print(gender_dst_org,'\n')my_filter=my_data[my_data.Survived==1] #dataframe 的数据筛选gender_dst_srv=my_filter[['Sex']].groupby(['Sex']).size()print('数据文件中幸存者的性别情况')print(gender_dst_srv,'\n')my_tmp=pd.concat([gender_dst_org,gender_dst_srv],axis=1)# 数据连接,axis=1 表示增加列my_plot_data=my_tmp.rename(columns={0:'Total',1:'Survived'}) # 列重命名print(my_plot_data)my_plot_data.plot(kind='bar')
散点图
import pandas as pdimport numpy as npmy_data=dmy_data = pd.read_csv("C:\Python\Scripts\my_data\iris.csv",header=None,names=['sepal_length','sepal_width','petal_length','petal_width','target'])# my_data.head(5)my_set=set(my_data['target']) # 创建一个类别名集合print(my_set)my_set_list=list(my_set) #set 不能直接访问其元素,转换成 list 后可以访问colors=list()palette={my_set_list[0]:"red",my_set_list[1]:"green",my_set_list[2]:"blue"}# 字典,给三种类别对应散点图中的三种 marker_color# print(my_data['target'])for n,row in enumerate(my_data['target']): # 根据类别为每个样本设置绘图颜色colors.append(palette[my_data['target'][n]])#print(colors)# 对 my_data 中的数值型数据,每两个特征绘制散点图scatterplot=pd.plotting.scatter_matrix(my_data,alpha=0.3,figsize=(10,10), diagonal='hist',color=colors,marker='o',grid=True)

若有收获,就点个赞吧
0 人点赞
