准备
数据可视化是指以图形或表格的形式显示信息。成功的可视化需要将数据或信息转换成可视的形式,以便能够借此分析或报告数据的特征和数据项或属性之间的关系。可视化的目标是形成可视化信息的人工解释和信息的意境模型。
导入相关模块
import numpy as npimport matplotlib.pyplot as pltimport pandas as pdimport yfinance as yfyf.pdr_override()
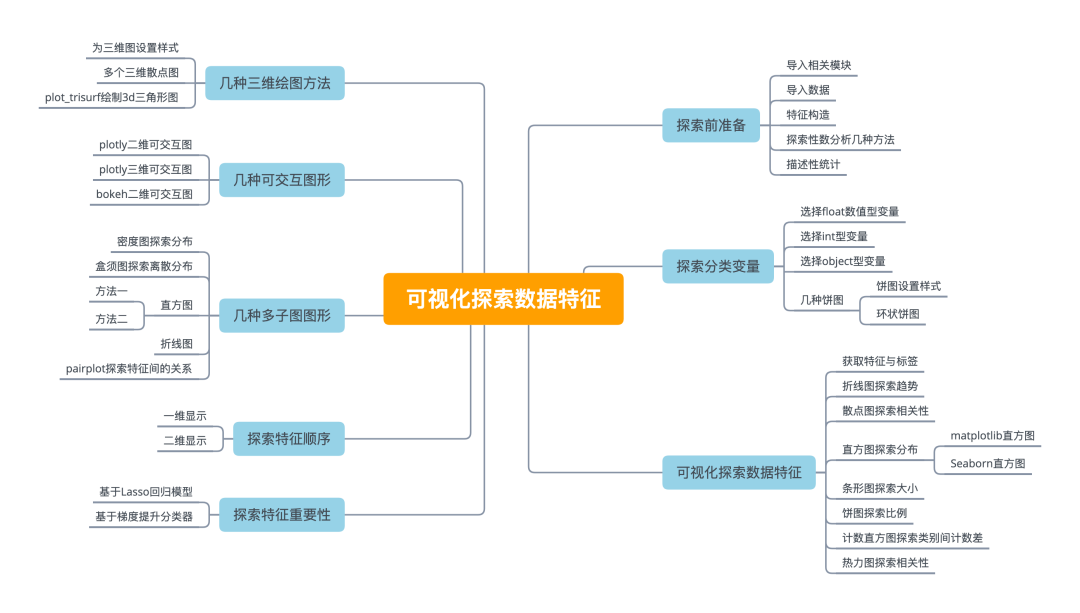
导入数据
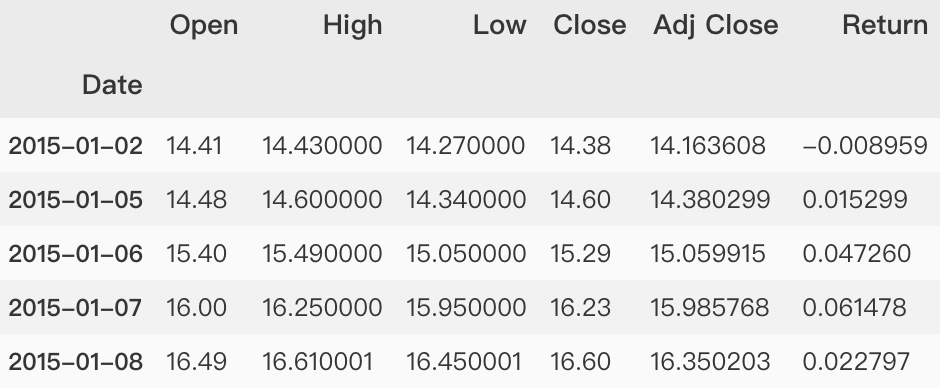
symbol = 'TCEHY'start = '2015-01-01'end = '2021-03-31'# 获取数据dataset = yf.download(symbol,start,end)# 查看列dataset.head()
特征构造
dataset['Increase/Decrease'] = np.where(dataset['Volume'].shift(-1) > dataset['Volume'],1,0)dataset['Buy_Sell_on_Open'] = np.where(dataset['Open'].shift(-1) > dataset['Open'],1,-1)dataset['Buy_Sell'] = np.where(dataset['Adj Close'].shift(-1) > dataset['Adj Close'],1,-1)dataset['Return'] = dataset['Adj Close'].pct_change()dataset = dataset.dropna()dataset['Class'] = np.where(dataset['Return'].shift(-1) > dataset['Return'],'Increase','Decrease')
pct_change()表示当前元素与先前元素的相差百分比,当指定periods=n,表示当前元素与先前n个元素的相差百分比。
探索性数分析几种方法
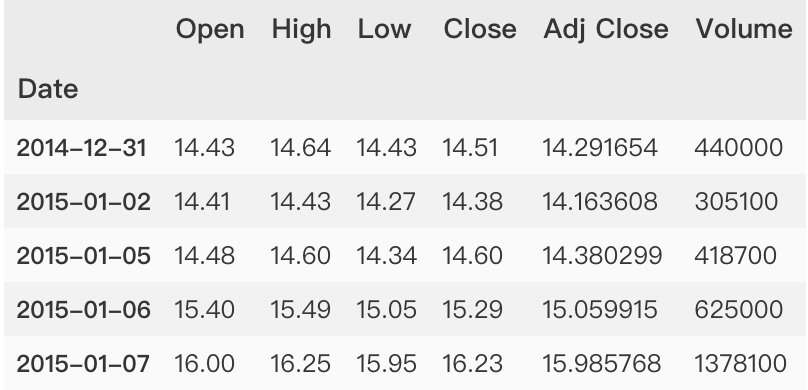
print("Exploratory Data Analysis")print("Dataset information")print(dataset.info(memory_usage='deep',verbose=False))print(dataset.info())print("Data type:")print(dataset.dtypes)print("Check unique values without NaN")print(dataset.nunique())print("Data shape:")print(dataset.shape)print("Data columns Names:")print(dataset.columns)print("Check for NaNs:")print(dataset.isnull().values.any())print("How many NaN it has in each columns?")print(dataset.isnull().sum())print("Data Statistics Summary:")print(dataset.describe())
描述性统计
>>> dataset.describe().T
可视化探索数据特征
获取特征与标签
X = dataset[['Open','High','Low','Adj Close']]Y = dataset.index
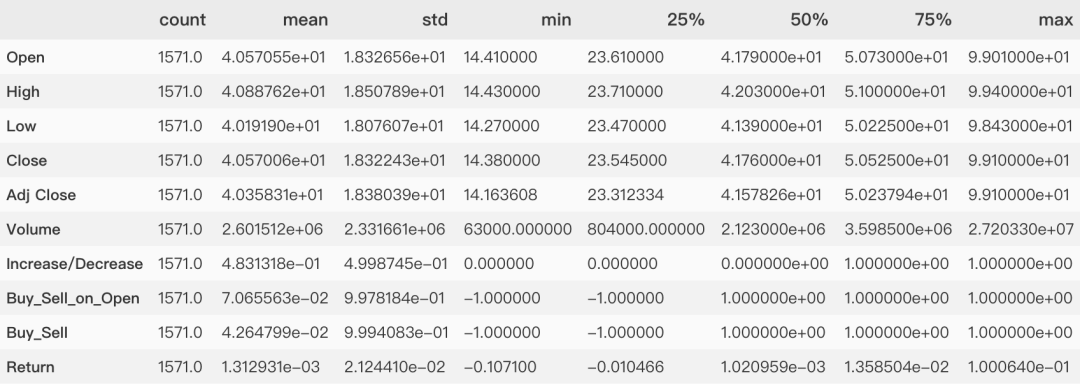
折线图探索趋势
plt.figure(figsize=(10,8))plt.plot(X)plt.title('Stock Line Chart')plt.legend(X)
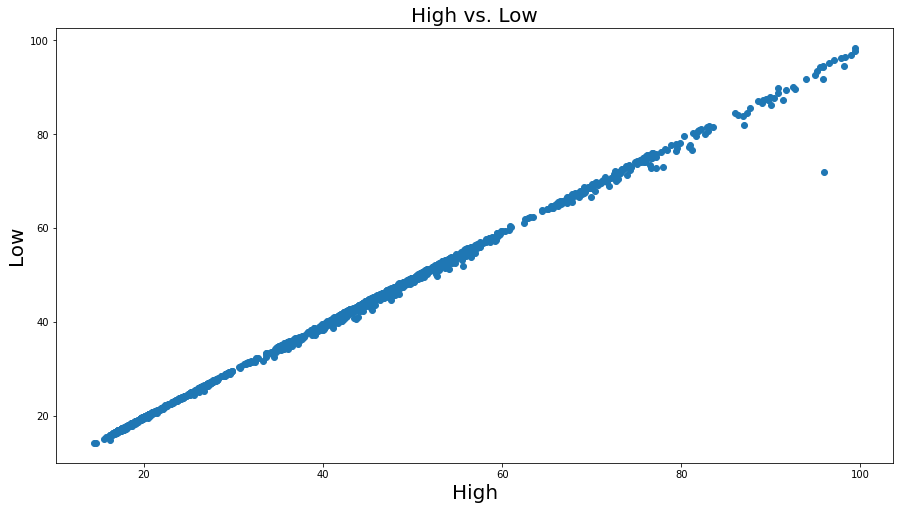
散点图探索相关性
散点图使用数据对象两个属性对值作为x和y坐标轴,每个数据对象都作为平面上对一个点绘制。
plt.figure(figsize=(10,8))plt.scatter(dataset['High'], dataset['Low'])plt.title("High vs. Low", fontsize=20)plt.xlabel("High", fontsize=20)plt.ylabel("Low", fontsize=20)
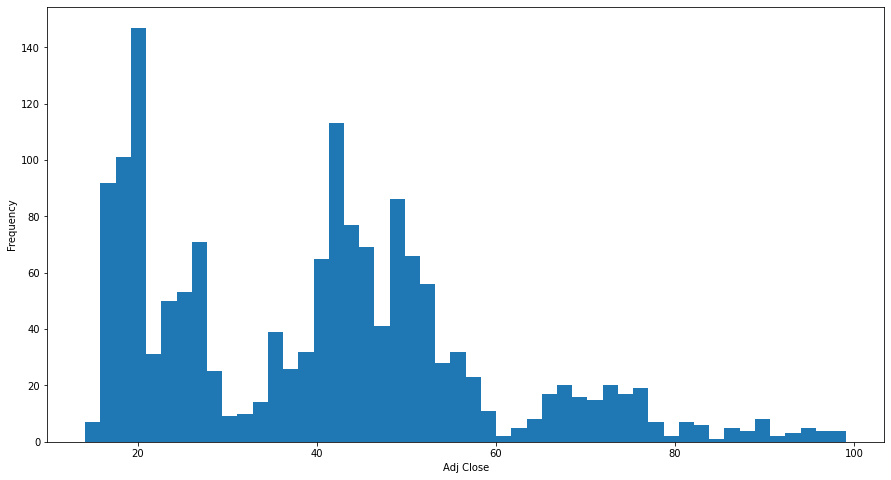
直方图探索分布
直方图是数值数据分布的精确图形表示。直方图通过将可能的值分散到箱中,并显示落入每个箱中到对象数,显示属性值到分布。
对于分类属性,每个值在一个箱中,如果值过多,则使用某种方法将值合并。对于连续属性,将值域划分成箱(通常是等宽)并对每个箱中对值计数。
一旦有了每个箱对计数,就可以构造条形图,每个箱用一个条形表示,并且每个条形对面积正比于落在对应区间对值对个数。如果所有对区间都是等宽对,则所有对条形对宽度相同,并且条形对高度正比于落在对应箱中值对个数。
matplotlib直方图
plt.figure(figsize=(10,8))plt.hist(dataset['Adj Close'], bins = 50)plt.xlabel("Adj Close")plt.ylabel("Frequency")
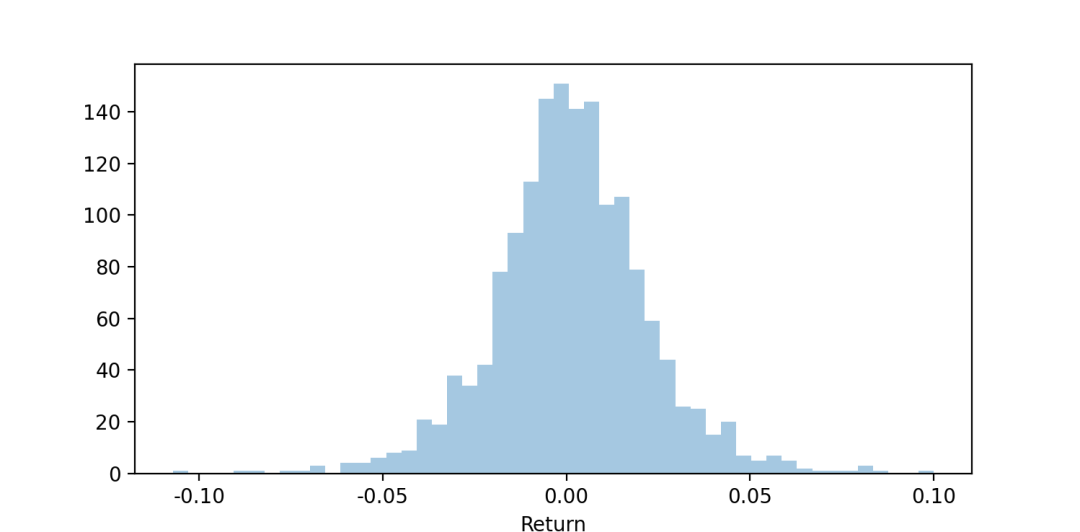
Seaborn直方图
sns.distplot(X['Return'],# 不显示核密度估计图kde = False)
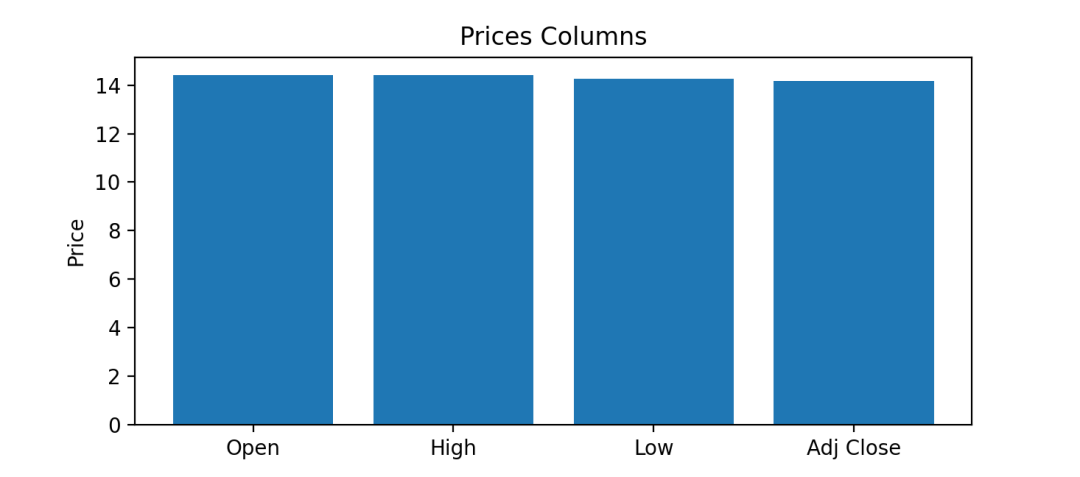
条形图探索大小
条形图(bar chart),也称为柱状图,是一种以长方形的长度为变量的统计图表,长方形的长度与它所对应的变量数值呈一定比例。
plt.figure(figsize=(10,8))labels = ['Open','High','Low','Adj Close']y_positions = range(len(labels))plt.bar(y_positions, X.iloc[0])plt.xticks(y_positions, labels)plt.ylabel("Price")plt.title("Prices Columns")
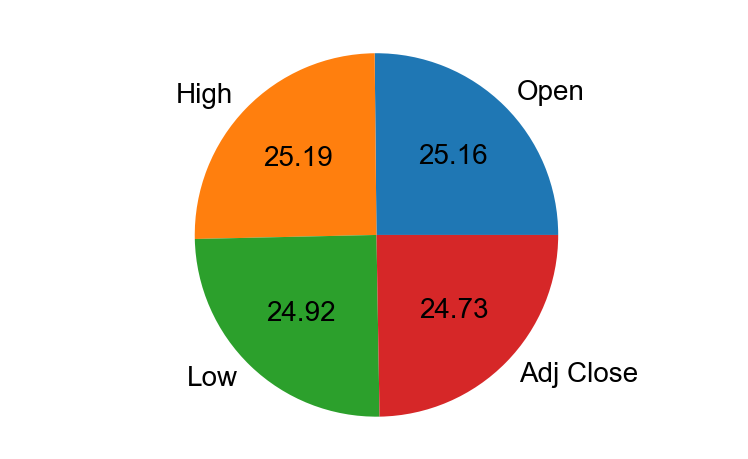
饼图探索比例
饼图直接以图形的方式直观形象地显示各个组成部分所占比例。
饼图类似于直方图,但通常用于具有相对较少的值的分类属性。饼图使用圆但相对面积显示不同值对相对频率,而不是像直方图那样使用条形图对面积或高度。
sizes = X.iloc[0]labels = ['Open','High','Low','Adj Close']plt.figure(figsize=(10,8))patches,l_text,p_text=plt.pie(sizes,labels = labels,autopct = "%.2f")#改变文本的大小#方法是把每一个text遍历。调用set_size方法设置它的属性for t in l_text:t.set_size(30)for t in p_text:t.set_size(20)plt.axes().set_aspect("equal")
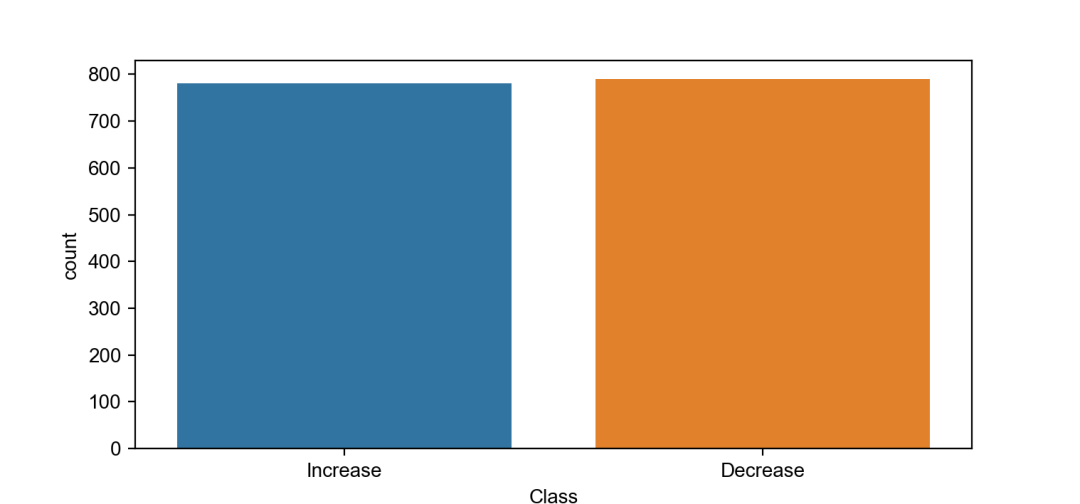
计数直方图探索类别间计数差
>>> sns.countplot(x="Class",data=dataset)>>> dataset.loc[:,'Class'].value_counts()Decrease 790Increase 781Name: Class, dtype: int64
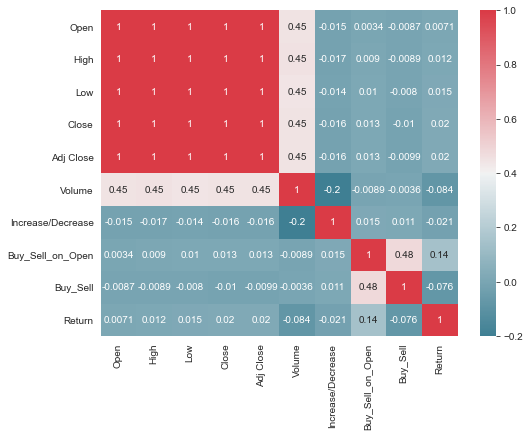
热力图探索相关性
数据分析中常用热力图做相关性分析。使用热力图表达会更加的明显地看出数据表里多个特征两两的相似度。下图表达相关性颜色越红的相关性越大,颜色越青的相关性越小。
sns.set_style('white')cmap = sns.diverging_palette(220, 10, as_cmap=True)plt.figure(figsize=(8, 6))sns.heatmap(dataset.iloc[:dataset.shape[0]].corr(),annot = True,cmap = cmap)
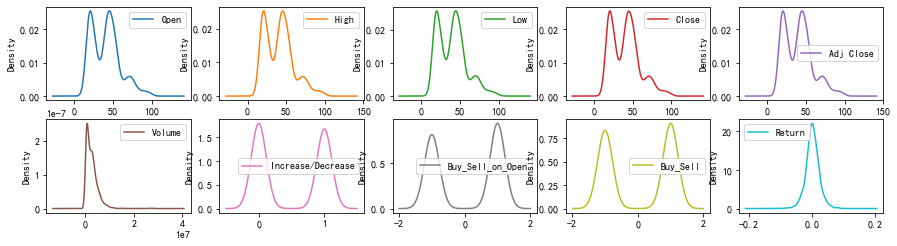
几种多子图图形
密度图探索分布
密度图是可视化连续型随机变量分布的利器,分布曲线上的每一个点都是概率密度,分布曲线下的每一段面积都是特定情况的概率。
dataset.plot(kind='density',subplots=True,layout=(5,5),sharex=False,figsize=(15,10))
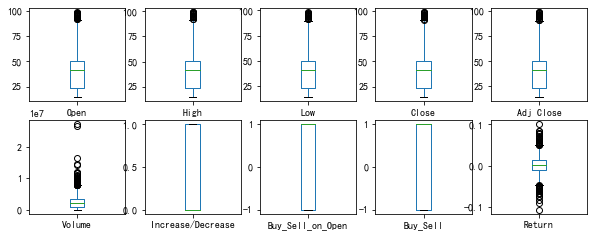
盒须图探索离散分布
箱形图Box plot又称为盒须图、盒式图、盒状图或箱线图,是一种用作显示一组数据分散情况资料的统计图。因型状如箱子而得名。
箱形图最大的优点就是不受异常值的影响,可以以一种相对稳定的方式描述数据的离散分布情况。
# 盒须图dataset.plot(kind='box',subplots=True,layout=(5,5),sharex=False,sharey=False,figsize=(10,10))
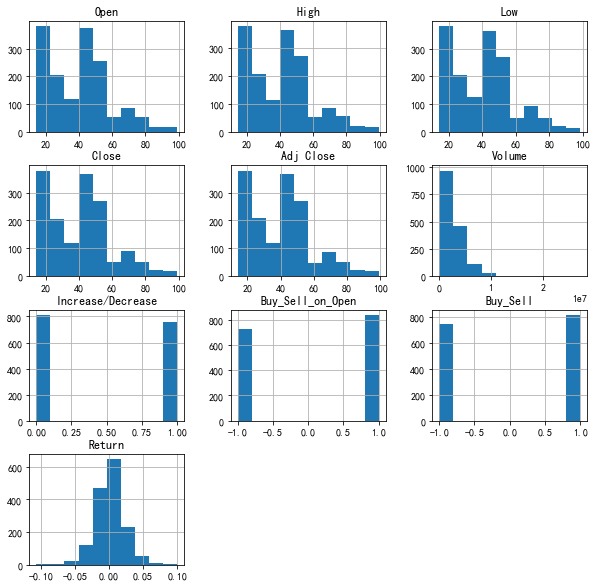
直方图
直方图是一种对数据分布情况的图形表示,是一种二维统计图表,它的两个坐标分别是统计样本和该样本对应的某个属性的度量,以长条图(bar)的形式具体表现。因为直方图的长度及宽度很适合用来表现数量上的变化,所以较容易解读差异小的数值。
分组数据字段(统计结果)映射到横轴的位置,频数字段(统计结果)映射到矩形的高度,分类数据可以设置颜色增强分类的区分度。
方法一
使用DataFrame的plot方法绘制图像会按照数据的每一列绘制一条曲线,默认按照列columns的名称在适当的位置展示图例,比matplotlib绘制节省时间,且DataFrame格式的数据更规范,方便向量化及计算。
dataset.plot(kind='hist',subplots=True,layout=(4,4),sharex=False,sharey=False,figsize=(10,10))

方法二
DataFrame.hist函数在DataFrame中的每个系列上调用matplotlib.pyplot.hist(),每列产生一个直方图。
dataset.hist(figsize=(10,10))plt.show()
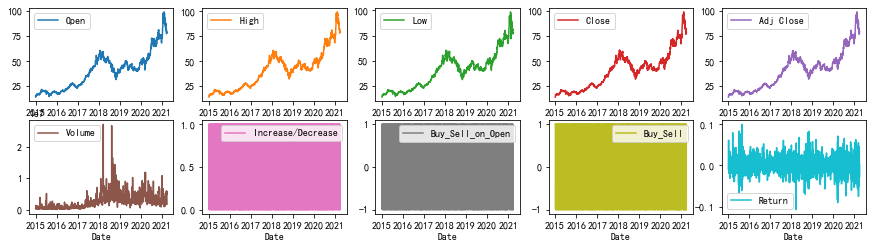
折线图
dataset.plot(kind='line',subplots=True,layout=(5,5),sharex=False,sharey=False,figsize=(15,10))plt.show()
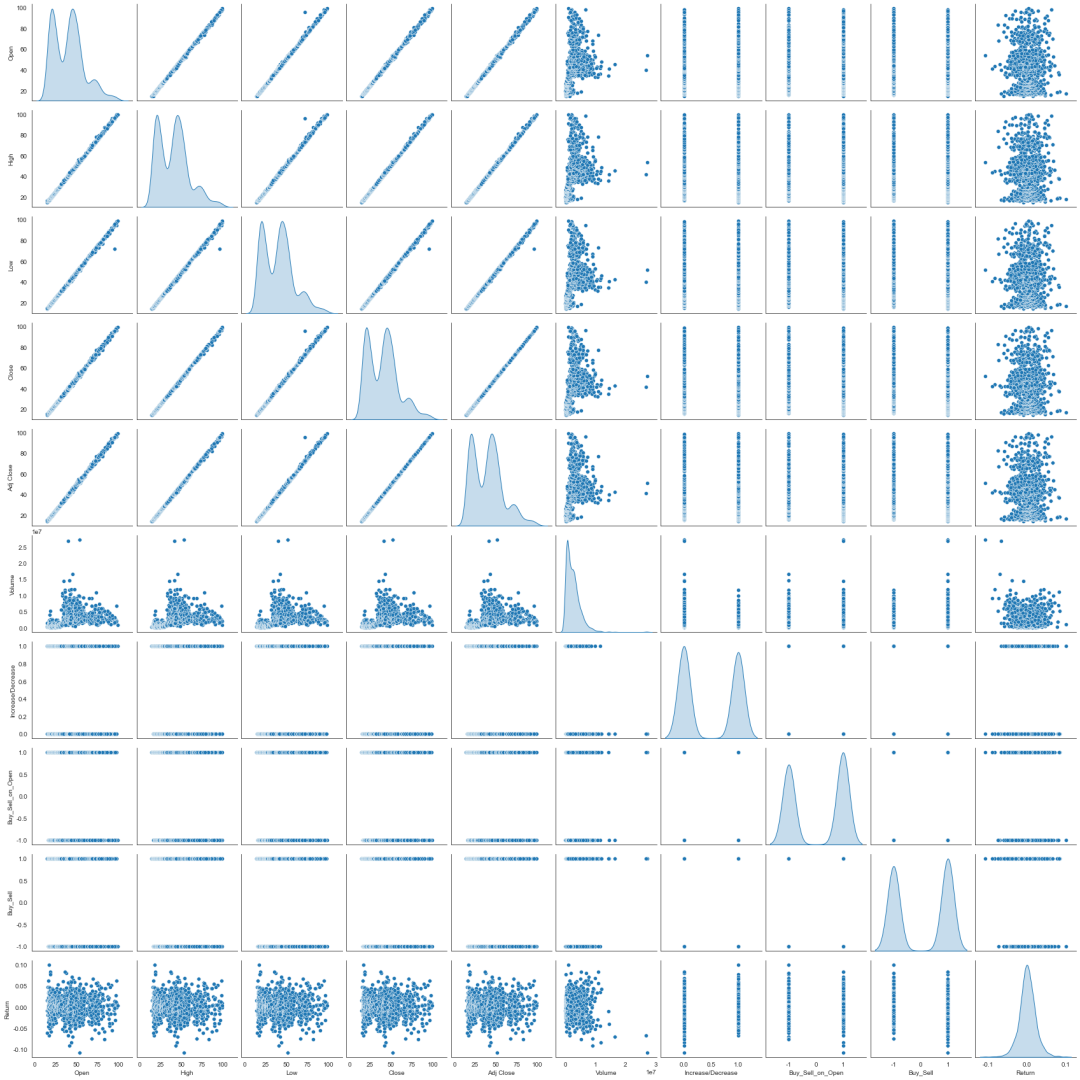
pairplot探索特征间的关系
当你需要对多维数据集进行可视化时,最终都要使用矩阵图pair plot。如果想画出所有变量中任意两个变量之间的图形,用矩阵图探索多维数据不同维度间的相关性非常有效。
sns.pairplot(dataset,diag_kind='kde',size=2.4)
几种可交互图形
plotly二维可交互图
plotly和经典Matplotlib最大的不同是plotly可以生成交互式的数据图表。Matplotlib生成的图示静态的图,而plotly是动态的图,具体方式是plotly可以生成一个html网页,该网页基于js支持数据交互(点击、缩放、拖拽)等等交互操作。
import plotlyimport chart_studioimport chart_studio.plotly as pyimport plotly.graph_objs as gochart_studio.tools.set_credentials_file(username='QuantPython',api_key='bWmf0mKJlNViBrOjDQbE')trace = go.Candlestick(x=dataset.index,open=dataset.Open,high=dataset.High,low=dataset.Low,close=dataset.Close)data = [trace]py.iplot(data, filename='simple_candlestick')
plotly三维可交互图
x = dataset['Low']y = dataset['High']z = dataset['Adj Close']trace1 = go.Scatter3d(x=x,y=y,z=z,mode='markers',marker=dict(size=12,color=z, # 将颜色设置为所需值的数组/列表colorscale='YlGnBu',opacity=0.8))data = [trace1]layout = go.Layout(margin=dict(l=0,r=0,b=0,t=0))fig = go.Figure(data=data, layout=layout)py.iplot(fig, filename='3d-scatter-colorscale')

bokeh二维可交互图
bokeh是一款针对现代Web浏览器呈现功能的交互式可视化库。bokeh通过Python(或其他语言)以快速简单的方式为超大型或流式数据集提供高性能交互的漂亮而且结构简单的多功能图形。
from bokeh.io import show, output_notebookfrom bokeh.plotting import figureoutput_notebook()# 创建一个带有标题和轴标签的新折线图p = figure(plot_width=400, plot_height=400)p.line(dataset.index, dataset['Adj Close'])# show出结果show(p)
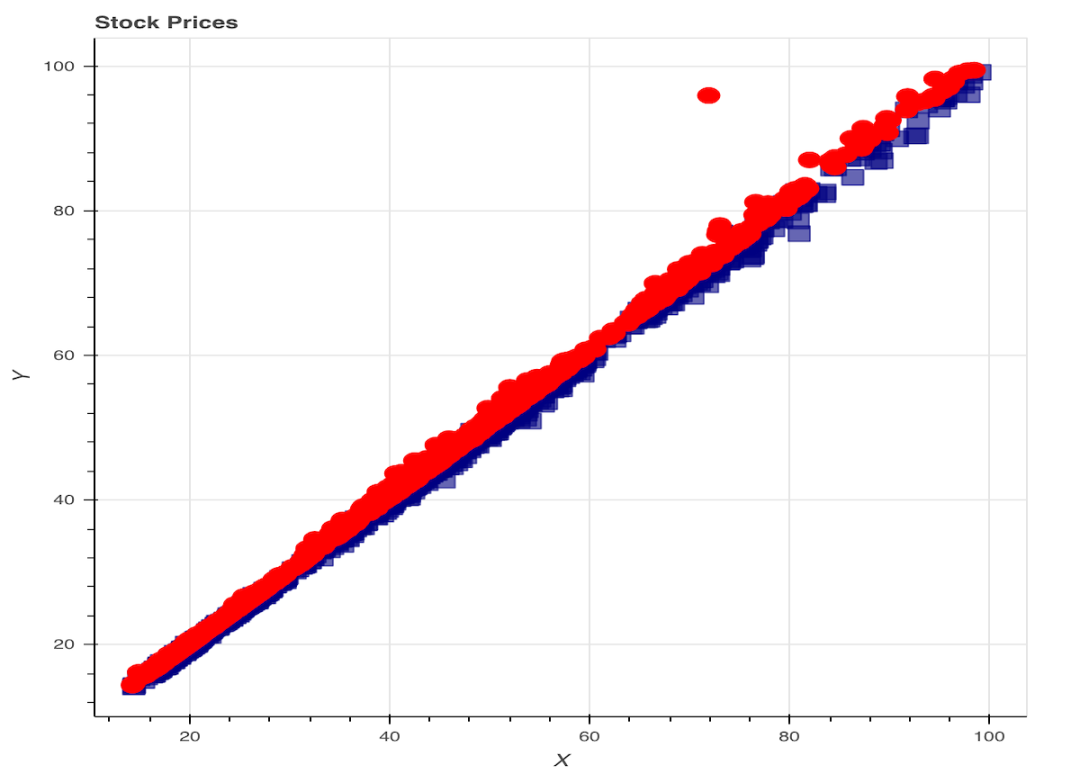
# 创建一个带有标签的空白图形p = figure(plot_width = 600, plot_height = 600,title = 'Stock Prices',x_axis_label = 'X', y_axis_label = 'Y')# 示例数据squares_x = dataset['Open']squares_y = dataset['Adj Close']circles_x = dataset['Low']circles_y = dataset['High']# 添加正方形p.square(squares_x, squares_y, size = 12, color = 'navy', alpha = 0.6)# 添加环形p.circle(circles_x, circles_y, size = 12, color = 'red')# 设置输出方式output_notebook()show(p)
几种三维绘图方法
Matplotlib创建Axes3D主要有两种方式,一种是利用关键字projection=’3d’来实现,另一种则是通过从mpl_toolkits.mplot3d导入对象Axes3D来实现,目的都是生成具有三维格式的对象Axes3D。
#方法一,利用关键字from matplotlib import pyplot as pltfrom mpl_toolkits.mplot3d import Axes3D#定义坐标轴fig = plt.figure()ax1 = plt.axes(projection='3d')#ax = fig.add_subplot(111,projection='3d')#这种方法也可以画多个子图#方法二,利用三维轴方法from matplotlib import pyplot as pltfrom mpl_toolkits.mplot3d import Axes3D#定义图像和三维格式坐标轴fig=plt.figure()ax2 = Axes3D(fig)
使用%matplotlib notebook使得3d图变得可交互。
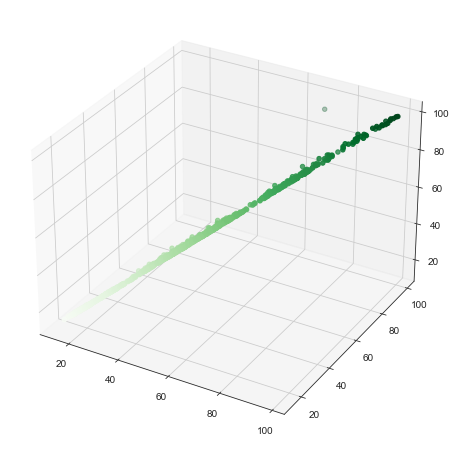
# 三维散乱点数据zdata = dataset['Adj Close']xdata = dataset['Low']ydata = dataset['High']# 可以使用ax.plot3D和ax.scatter3D函数创建3d图ax.scatter3D(xdata, ydata, zdata, c=zdata, cmap='Greens')
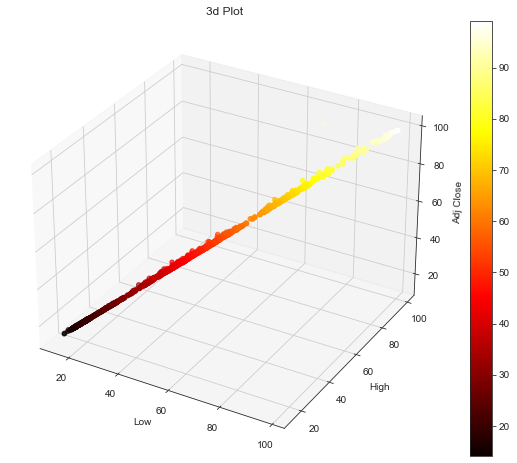
为三维图设置样式
x = dataset['Low']y = dataset['High']z = dataset['Adj Close']# 创建画布fig = plt.figure(figsize=(10,8))ax = fig.add_subplot(111, projection='3d')# 绘制3d图pnt3d=ax.scatter(x,y,z,c=z)cbar=plt.colorbar(pnt3d)ax.set_title('3d Plot')ax.set_xlabel('Low')ax.set_ylabel('High')ax.set_zlabel('Adj Close')plt.show()
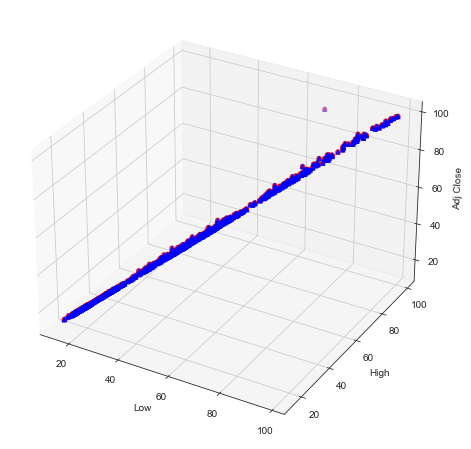
多个三维散点图
# 创建3d画布fig =plt.figure(figsize=(10,8))ax = fig.add_subplot(111, projection='3d')n = 100# 绘制散点图for c, m, zl, zh in [('r', 'o', -50, -25), ('b', '^', -30, -5)]:x = dataset['Low']y = dataset['High']z = dataset['Adj Close']ax.scatter(x, y, z, c=c, marker=m)ax.set_xlabel('Low')ax.set_ylabel('High')ax.set_zlabel('Adj Close')plt.show()
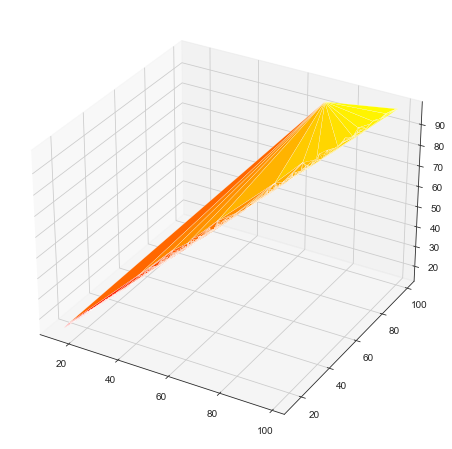
plot_trisurf绘制3d三角形图
x = dataset['Low']y = dataset['High']z = dataset['Adj Close']# 创建画布fig =plt.figure(figsize=(10,8))ax = fig.gca(projection='3d')# 绘制3d三角形图ax.plot_trisurf(x, y, z, cmap='autumn', linewidth=0.2)plt.show()ax.set_xlabel('Low')ax.set_ylabel('High')ax.set_zlabel('Adj Close')plt.show()
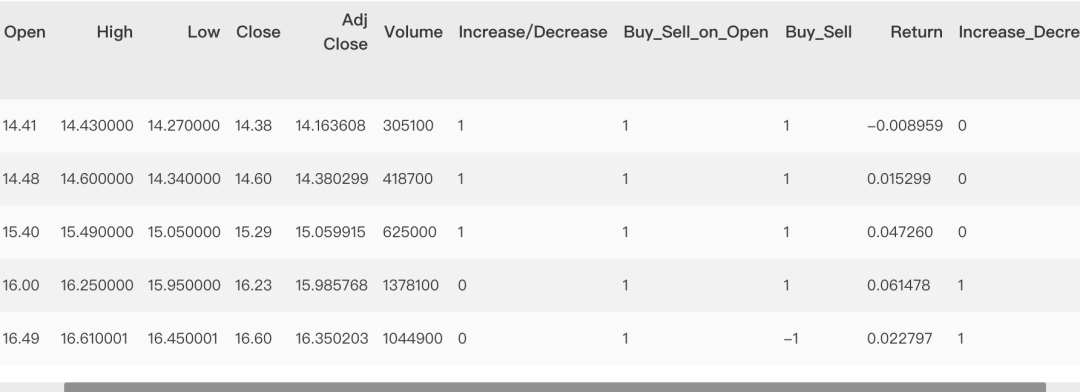
# Class 是一个分类型变量# 将其转换为数字df_dummies = pd.get_dummies(dataset['Class'])del df_dummies[df_dummies.columns[-1]]df_new = pd.concat([dataset, df_dummies], axis=1)del df_new['Class']df_new = df_new.rename(columns={"Decrease":"Increase_Decrease"})df_new.head()
探索特征顺序
features = dataset[['Open', 'High', 'Low', 'Volume','Increase/Decrease', 'Buy_Sell_on_Open','Buy_Sell', 'Return']]X = featuresy = dataset['Adj Close']
本文使用Yellowbrick来做特征排序。Yellowbrick是一个机器学习可视化库,主要依赖于sklearn机器学习库,能够提供多种机器学习算法的可视化,主要包括特征可视化,分类可视化,回归可视化,回归可视化,聚类可视化,模型选择可视化,目标可视化,文字可视化。
Yellowbrick API是专门为与scikit-learn配合使用而专门设计的。因此只需使用与scikit-learn模型相同的工作流程,导入可视化工具,实例化它,调用可视化工具的fit()方法,然后为了渲染可视化效果,调用可视化工具的show()方法。
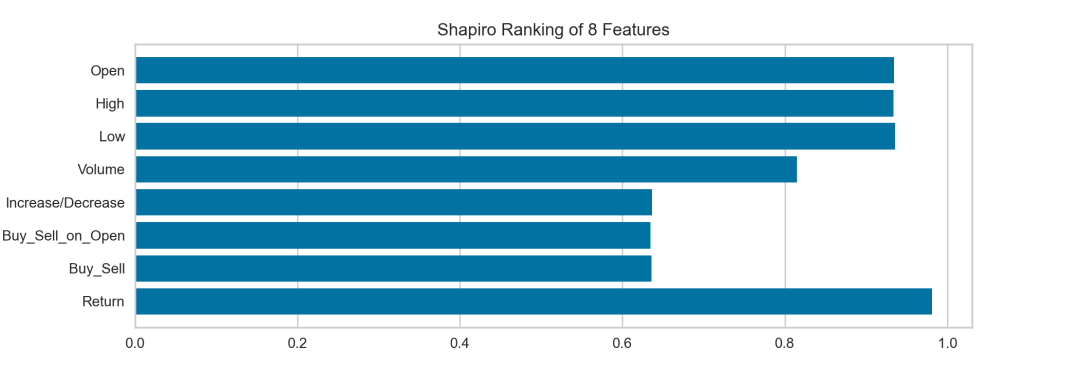
一维显示
from yellowbrick.features import Rank1D# 用Sharpiro排序算法实例化1D可视化器visualizer = Rank1D(algorithm='shapiro')visualizer.fit(X, y)# 可视化器训练数据visualizer.transform(X)# Draw/show/poof数据visualizer.poof()
二维显示
作为特征选择的一部分,希望识别彼此具有线性关系的特征,可能会在模型中引入协方差并破坏OLS(指导移除特征或使用正则化)。可以使用Rank Features visualizer计算所有特征对之间的Pearson相关性。
from yellowbrick.features import Rank2D# 用协方差排序算法实例化可视化工具visualizer = Rank2D(algorithm='covariance')visualizer.fit(X, y)visualizer.transform(X)visualizer.poof()
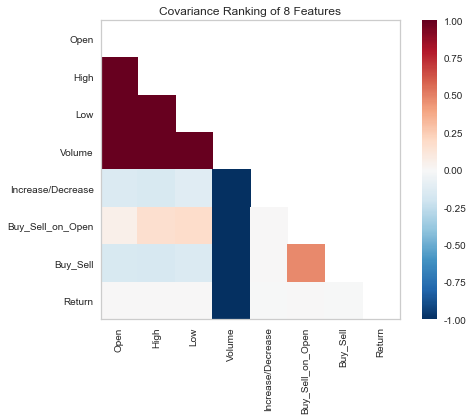
以上结果显示了特征对之间的皮尔逊相关性,这样网格中的每个像元都代表了两个特征,这些特征在x和y轴上按顺序标识,并且颜色显示了相关性的大小。皮尔逊相关系数为1.0表示变量对之间存在强的正线性关系,值-1.0表示强的负线性关系(零值表示无关系)。因此,可以寻找深红色和深蓝色框以进一步识别。
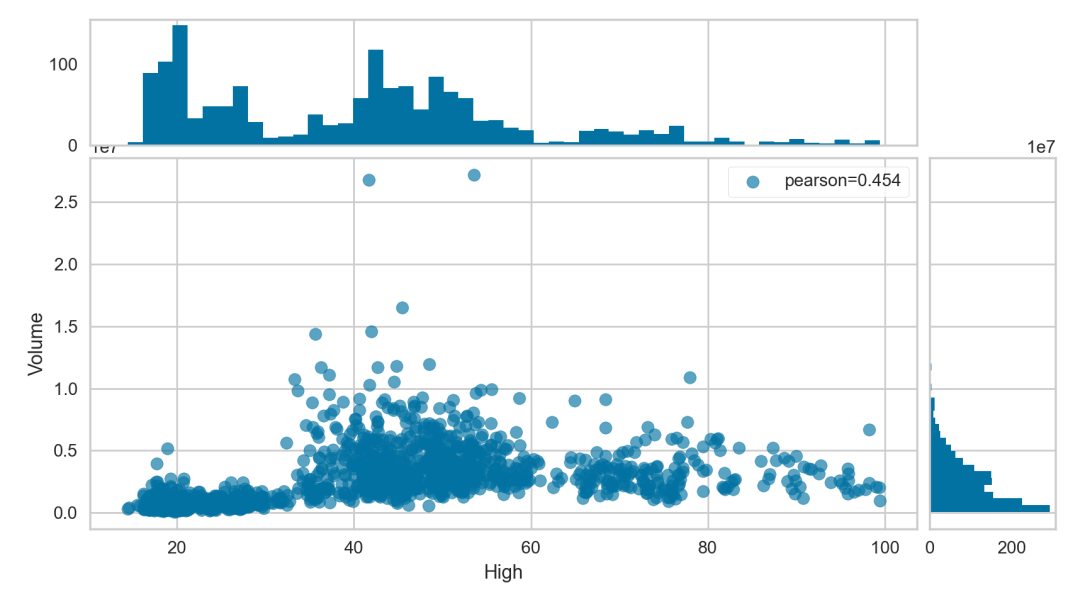
在此图表中,我们看到这些特征High与Volume具有很强的相关性。使用直接数据可视化JointPlotVisualizer检查这些关系。
from yellowbrick.features import JointPlotVisualizervisualizer = JointPlotVisualizer(columns=['High', 'Volume'])visualizer.fit_transform(X, y)visualizer.show()
探索特征重要性
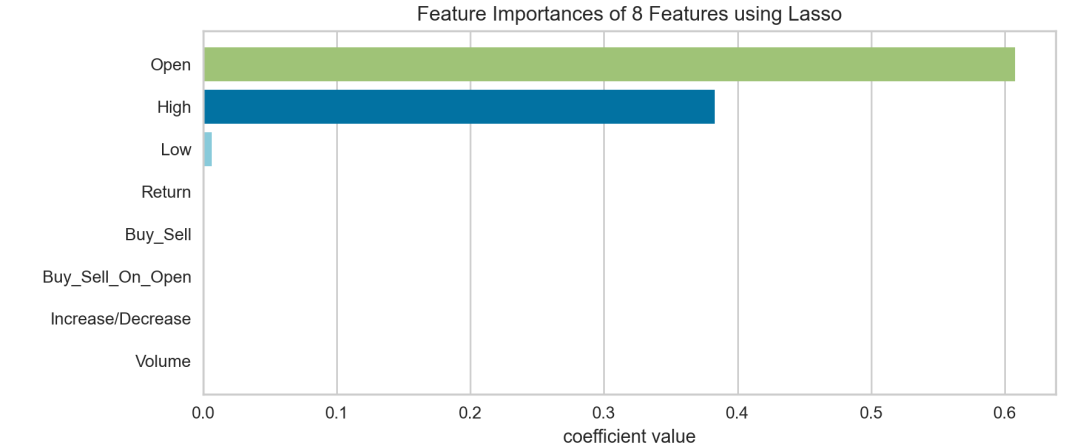
基于Lasso回归模型
from sklearn.linear_model import Lassofrom yellowbrick.features import FeatureImportances# 创建一个新的画布fig = plt.figure()ax = fig.add_subplot()# 特征标题大小写,用于更好地显示和创建可视化工具的特性labels = list(map(lambda s: s.title(), features))viz = FeatureImportances(Lasso(),ax=ax,labels=labels,relative=False)viz.fit(X, y)viz.poof()
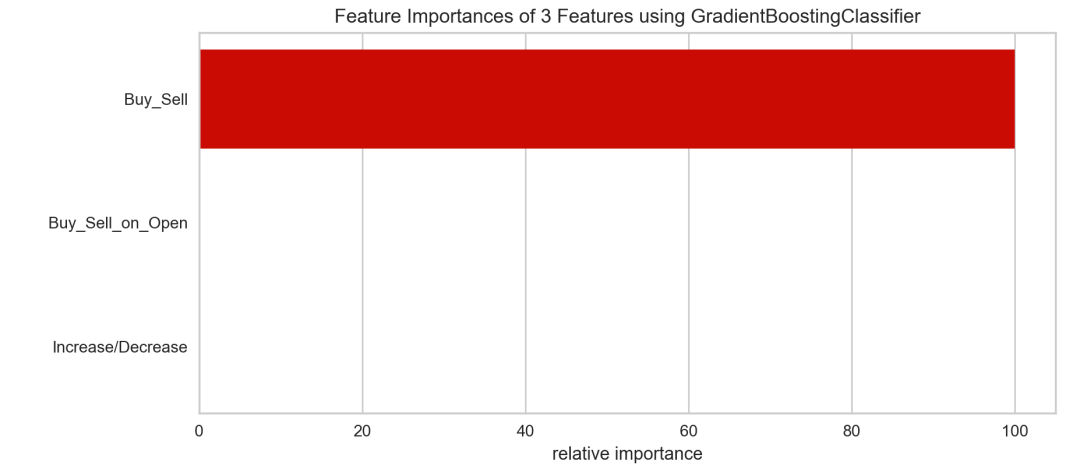
基于梯度提升分类器
from sklearn.ensemble import GradientBoostingClassifierfrom yellowbrick.features import FeatureImportances# 数据不能是连续型X = dataset[['Increase/Decrease', 'Buy_Sell_on_Open', 'Buy_Sell']]y = dataset['Buy_Sell']# 创建一个新的画布fig = plt.figure()ax = fig.add_subplot()# 特征重要性viz = FeatureImportances(GradientBoostingClassifier(), ax=ax)viz.fit(X, y)viz.poof()
探索分类变量
X = dataset[['Open', 'High', 'Low', 'Volume', 'Increase/Decrease', 'Buy_Sell_on_Open', 'Buy_Sell', 'Return']]Y = dataset['Adj Close']X.dtypes
Open float64High float64Low float64Volume int64Increase/Decrease int32Buy_Sell_on_Open int32Buy_Sell int32Return float64dtype: object
选择float数值型变量
dataset_float = dataset.select_dtypes(include=['float']).copy()dataset_float.head()
选择int型变量
dataset_int = dataset.select_dtypes(include=['int']).copy()dataset_int.head()
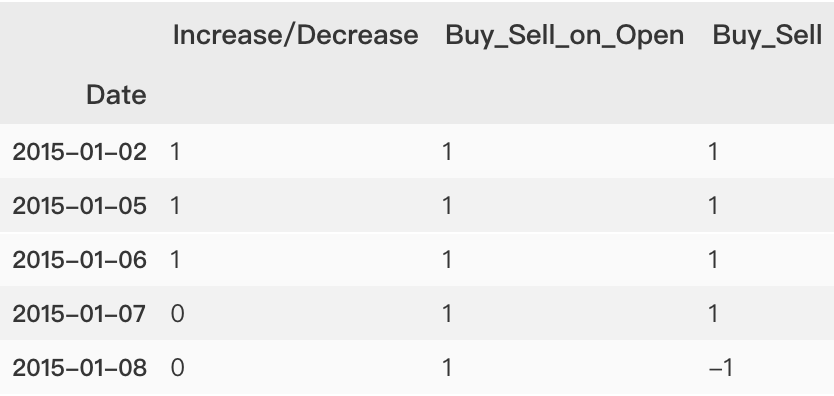
选择object型变量
dataset_object = dataset.select_dtypes(include=['object']).copy()dataset_object.head()
| Class | |
|---|---|
| Date | |
| 2015-01-02 | Increase |
| 2015-01-05 | Increase |
| 2015-01-06 | Increase |
| 2015-01-07 | Decrease |
| 2015-01-08 | Decrease |
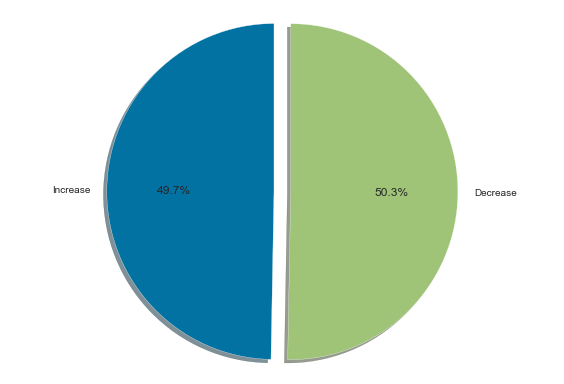
几种饼图
Increase = dataset_object[dataset_object=='Increase'].count().sum().astype(float)Decrease = dataset_object[dataset_object=='Decrease'].count().sum().astype(float)new_dataset_object = [Increase, Decrease]labels = ['Increase', 'Decrease']colors = ['g', 'r']# 只"explode"第二个饼片explode = (0, 0.1)fig1, ax1 = plt.subplots()ax1.pie(new_dataset_object,explode=explode,labels=labels,autopct='%1.1f%%',shadow=True,startangle=90)# 相等的长宽比确保饼图以圆的形式绘制ax1.axis('equal')plt.tight_layout()plt.show()
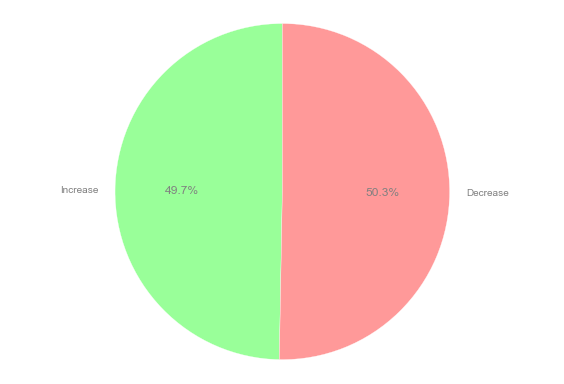
饼图设置样式
new_dataset_object = [Increase, Decrease]labels = ['Increase', 'Decrease']colors = ['#99ff99','#ff9999']fig1, ax1 = plt.subplots()patches, texts, autotexts = ax1.pie(new_dataset_object,colors = colors,labels=labels,autopct='%1.1f%%',startangle=90)for text in texts:text.set_color('grey')for autotext in autotexts:autotext.set_color('grey')ax1.axis('equal')plt.tight_layout()plt.show()
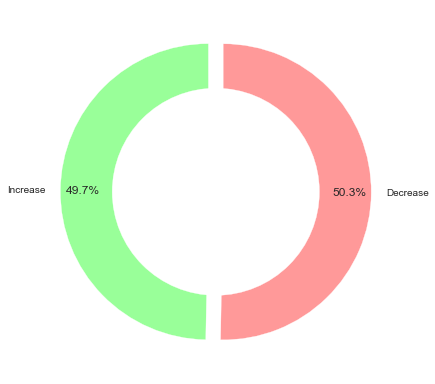
环状饼图
new_dataset_object = [Increase, Decrease]labels = ['Increase', 'Decrease']colors = ['#99ff99','#ff9999']explode = (0.05,0.05)plt.pie(new_dataset_object,colors = colors,labels=labels,autopct='%1.1f%%',startangle=90,pctdistance=0.85,explode = explode)# 画环状图centre_circle = plt.Circle((0,0),0.70,fc='white')fig = plt.gcf()fig.gca().add_artist(centre_circle)ax1.axis('equal')plt.tight_layout()plt.show()

若有收获,就点个赞吧
0 人点赞
