数据挖掘 Seaborn 回归分析
导读: Seaborn就是让困难的东西更加简单。它是针对统计绘图的,一般来说,能满足数据分析90%的绘图需求。Seaborn其实是在matplotlib的基础上进行了更高级的API封装,从而使得作图更加容易,同时它能高度兼容numpy与pandas数据结构以及scipy与statsmodels等统计模式。
本文主要介绍回归模型图lmplot、线性回归图regplot,这两个函数的核心功能很相似,都会绘制数据散点图,并且拟合关于变量x,y之间的回归曲线,同时显示回归的95%置信区间。
另一个是线性回归残差图residplot,该函数绘制观察点与回归曲线上的预测点之间的残差图。
数据准备
所有图形将使用股市数据—中国平安sh.601318历史k线数据。
使用模块及数据预处理
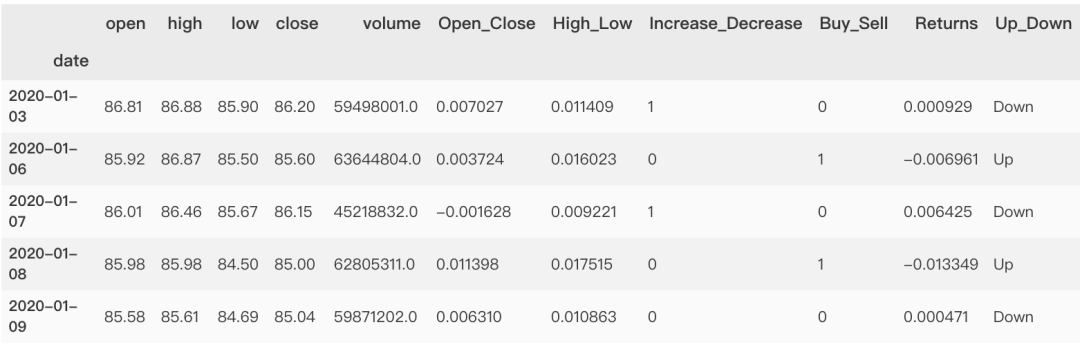
import numpy as npimport matplotlib.pyplot as pltimport pandas as pdimport seaborn as snsimport baostock as bsbs.login()result = bs.query_history_k_data('sh.601318',fields = 'date,open,high, low,close,volume',start_date = '2020-01-01',end_date = '2021-05-01',frequency='d')dataset = result.get_data().set_index('date').applymap(lambda x: float(x))bs.logout()dataset['Open_Close'] = (dataset['open'] - dataset['close'])/dataset['open']dataset['High_Low'] = (dataset['high'] - dataset['low'])/dataset['low']dataset['Increase_Decrease'] = np.where(dataset['volume'].shift(-1) > dataset['volume'],1,0)dataset['Buy_Sell_on_Open'] = np.where(dataset['open'].shift(-1) > dataset['open'],1,0)dataset['Buy_Sell'] = np.where(dataset['close'].shift(-1) > dataset['close'],1,0)dataset['Returns'] = dataset['close'].pct_change()dataset = dataset.dropna()dataset['Up_Down'] = np.where(dataset['Returns'].shift(-1) > dataset['Returns'],'Up','Down')dataset = dataset.dropna()dataset.head()
一、回归模型图lmplot
lmplot是一种集合基础绘图与基于数据建立回归模型的绘图方法。通过lmplot可以直观地总览数据的内在关系。显示每个数据集的线性回归结果,xy变量,利用'hue'、'col'、'row'参数来控制绘图变量。可以把它看作分类绘图依据。
同时可以使用模型参数来调节需要拟合的模型:order、logistic、lowess、robust、logx。
线性回归
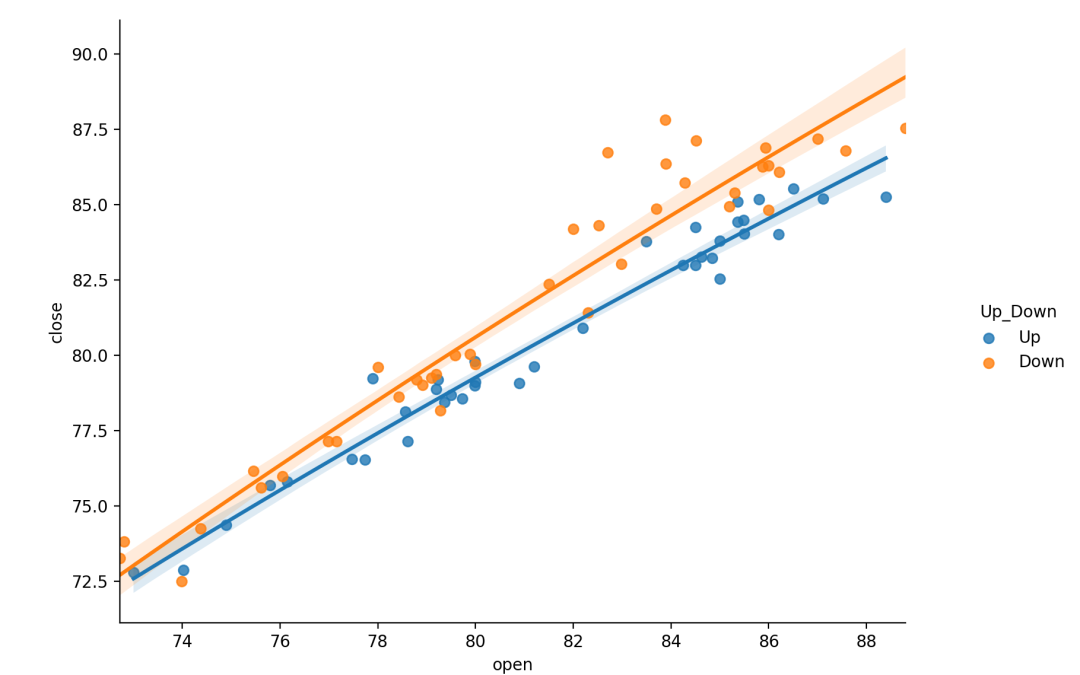
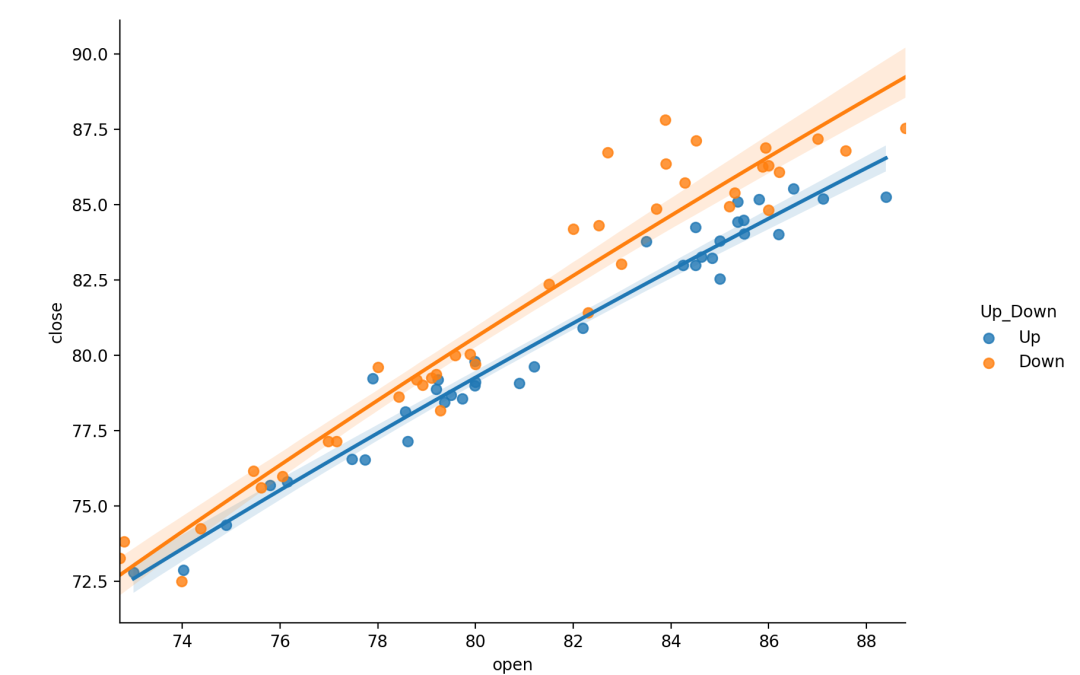
lmplot绘制散点图及线性回归拟合线非常简单,只需要指定自变量和因变量即可,lmplot会自动完成线性回归拟合。回归模型的置信区间用回归线周围的半透明带绘制。lmplot支持引入第三维度进行对比,例如设置hue="species“。
sns.lmplot(x="open",y="close",hue="Up_Down",data=dataset)
局部加权线性回归
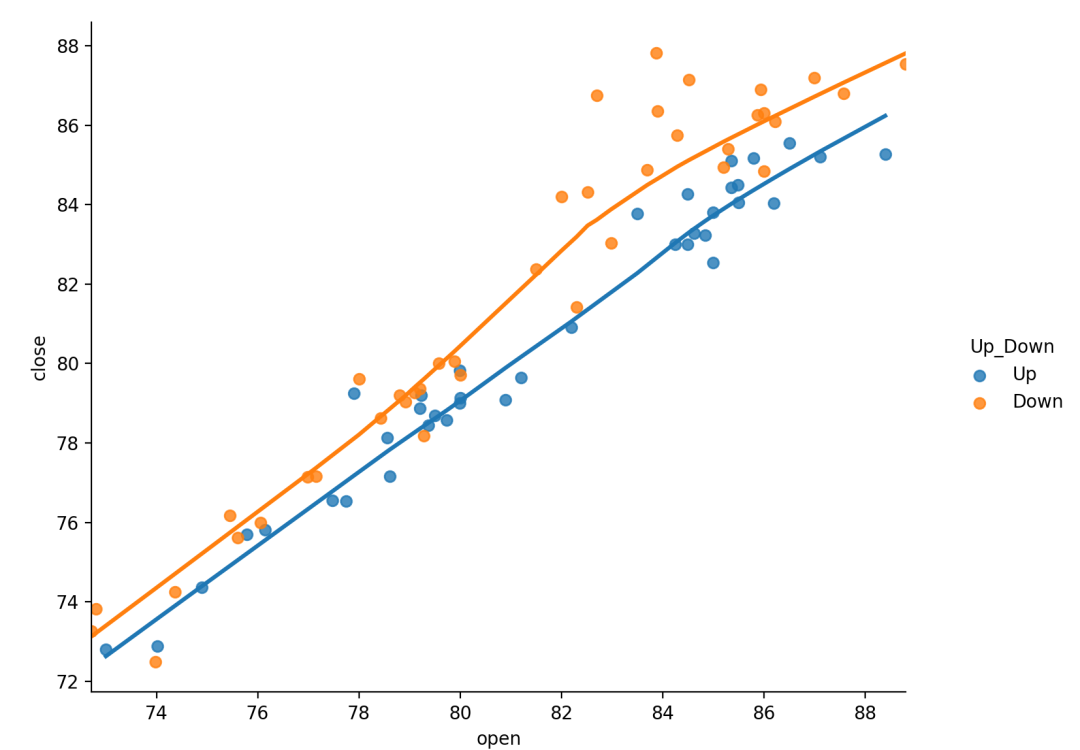
局部加权回归散点平滑法(locally weighted scatterplot smoothing,LOWESS),是一种非参数回归拟合的方式,其主要思想是选取一定比例的局部数据,拟合多项式回归曲线,以便观察到数据的局部规律和趋势。通过设置参数lowess=True。
局部加权线性回归是机器学习里的一种经典的方法,弥补了普通线性回归模型欠拟合或者过拟合的问题。其原理是给待预测点附近的每个点都赋予一定的权重,然后基于最小均方误差进行普通的线性回归。局部加权中的权重,是根据要预测的点与数据集中的点的距离来为数据集中的点赋权值。当某点离要预测的点越远,其权重越小,否则越大。
局部加权线性回归的优势就在于处理非线性关系的异方差问题。lowess bool, 可选如果为True,使用统计模型来估计非参数低成本模型(局部加权线性回归)。这种方法具有最少的假设,尽管它是计算密集型的,因此目前根本不计算置信区间。
sns.lmplot(x="open",y="close",hue="Up_Down",lowess=True,data=dataset)
对数线性回归模型
通过设置参数logx完成线性回归转换对数线性回归,其实质上是完成了输入空间x到输出空间y的非线性映射。
对数据做一些变换的目的是它能够让它符合所做的假设,能够在已有理论上对其分析。对数变换(log transformation)是特殊的一种数据变换方式,它可以将一类理论上未解决的模型问题转化为已经解决的问题。logx: bool, 可选如果为True,则估计y ~ log(x)形式的线性回归,在输入空间中绘制散点图和回归模型。注意x必须是正的。
sns.lmplot(x="open",y="close",hue="Up_Down",data=dataset,logx=True)
稳健线性回归
在有异常值的情况下,它可以使用不同的损失函数来减小相对较大的残差,拟合一个健壮的回归模型,传入robust=True。
稳健回归是将稳健估计方法用于回归模型,以拟合大部分数据存在的结构,同时可识别出潜在可能的离群点、强影响点或与模型假设相偏离的结构。
稳健回归是统计学稳健估计中的一种方法,其主要思路是将对异常值十分敏感的经典最小二乘回归中的目标函数进行修改。经典最小二乘回归以使误差平方和达到最小为其目标函数。因为方差为一不稳健统计量,故最小二乘回归是一种不稳健的方法。
不同的目标函数定义了不同的稳健回归方法。常见的稳健回归方法有:最小中位平方法、M估计法等。hue, col, row: strings定义数据子集的变量,并在不同的图像子集中绘制height: scalar, 可选定义子图的高度col_wrap: int, 可选设置每行子图数量n_boot: int, 可选用于估计的重采样次数ci。默认值试图平衡时间和稳定性。ci: int in [0,100]或None, 可选回归估计的置信区间的大小。这将使用回归线周围的半透明带绘制。置信区间是使用bootstrap估算的;
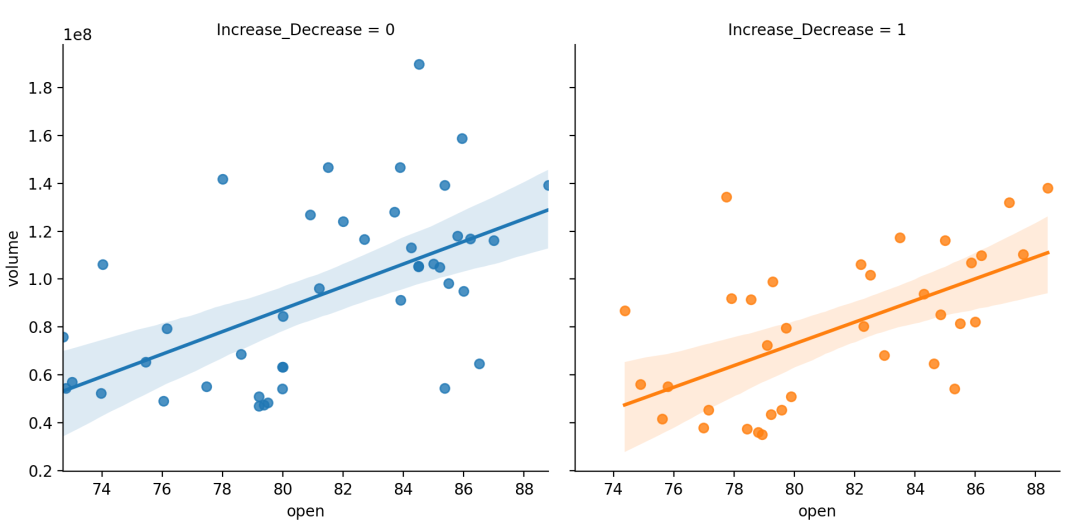
robustbool, 可选如果为True,则用于statsmodels估计稳健的回归。这将消除异常值的权重。并且由于使用引导程序计算回归线周围的置信区间,可能希望将其关闭获得更快的迭代速度(使用参数ci=None)或减少引导重新采样的数量(n_boot)。
sns.lmplot(x="open",y="volume",data=dataset,hue="Increase_Decrease",col="Increase_Decrease",# col|hue控制子图不同的变量speciescol_wrap=2,height=4,robust=True)
多项式回归
在存在高阶关系的情况下,可以拟合多项式回归模型来拟合数据集中的简单类型的非线性趋势。通过传入参数order大于1,此时使用numpy.Polyfit估计多项式回归的方法。
多项式回归是回归分析的一种形式,其中自变量x和因变量y之间的关系被建模为关于x的次多项式。多项式回归拟合x的值与y的相应条件均值之间的非线性关系,表示为,被用于描述非线性现象。
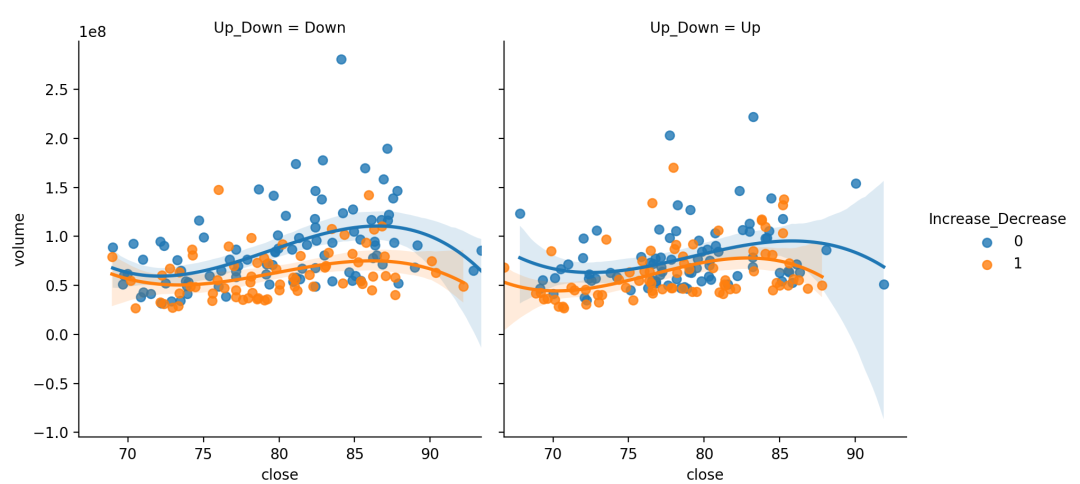
虽然多项式回归是拟合数据的非线性模型,但作为统计估计问题,它是线性的。在某种意义上,回归函数在从数据估计到的未知参数中是线性的。因此,多项式回归被认为是多元线性回归的特例。order: int, 可选多项式回归,设定指数
sns.lmplot(x="close",y="volume",data=dataset,hue="Increase_Decrease",col="Up_Down", # col|hue控制子图不同的变量speciescol_wrap=2, # col_wrap控制每行子图数量height=4, # height控制子图高度order=3 # 多项式最高次幂)
逻辑回归
Logistic回归是一种广义线性回归,logistic回归的因变量可以是二分类的,也可以是多分类的,但是二分类的更为常用,也更加容易解释,多类可以使用softmax方法进行处理。
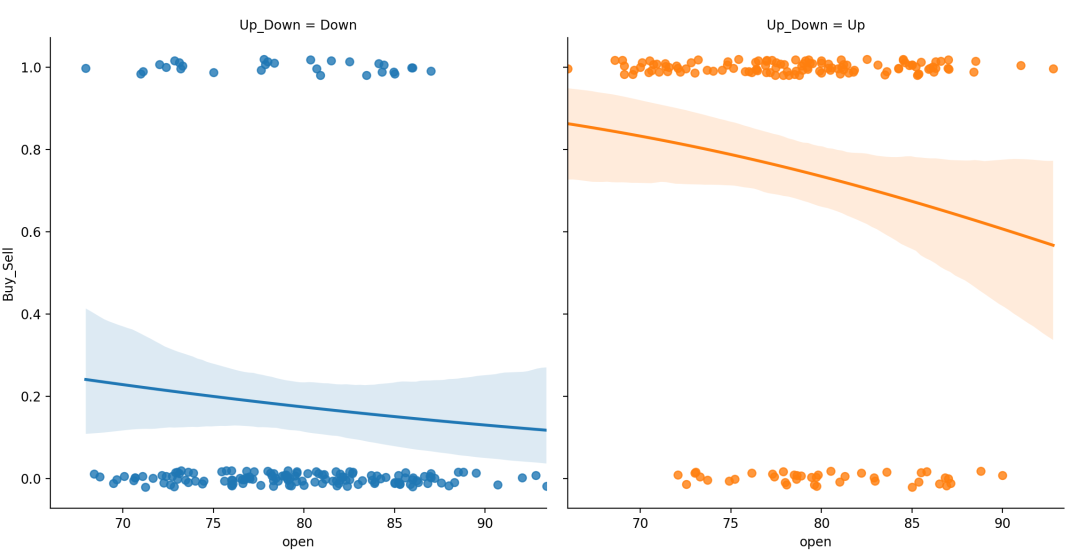
实际中最为常用的就是二分类的logistic回归。{x,y}_jitterfloats, 可选在x或y变量中加入这个大小的均匀随机噪声。对回归拟合后的数据副本添加噪声,只影响散点图的外观。这在绘制取离散值的变量时很有用。logistic bool, 可选如果为True,则假定y是一个二元变量,并使用统计模型来估计logistic回归模型。并且由于使用引导程序计算回归线周围的置信区间,您可能希望将其关闭获得更快的迭代速度(使用参数ci=None)或减少引导重新采样的数量(n_boot)。
# 制作具有性别色彩的自定义调色板pal = dict(Up= "#6495ED", Down= "#F08080")# 买卖随开盘价与涨跌变化g = sns.lmplot(x= "open", y= "Buy_Sell", col= "Up_Down", hue= "Up_Down",data=dataset,palette=pal,y_jitter= .02, # 回归噪声logistic= True)# 逻辑回归模型
二、线性回归图regplot
Lmplot()与regplot()与两个函数之间的主要区别是regplot()接受变量的类型可以是numpy数组、pandas序列(Series)。或者直接对data传入pandas DataFrame对象数据。而lmplot()的data参数是必须的,且变量必须为字符串。
线性回归
绘制连续型数据并拟合线性回归模型。fit_reg bool,可选如果为True,则估计并绘制与x和y变量相关的回归模型。ci int in [0,100]或None,可选回归估计的置信区间的大小。这将使用回归线周围的半透明带绘制。置信区间是使用自举估算的;对于大型数据集,建议将此参数设置为"None",以避免该计算。scatter bool,可选如果为True,则绘制一个散点图,其中包含基础观察值(或x_estimator值)。
# 绘制线性回归拟合曲线f, ax = plt.subplots(figsize=(8,6))sns.regplot(x="Returns",y="volume",data=dataset,fit_reg=True,ci = 95,scatter=True,ax=ax)
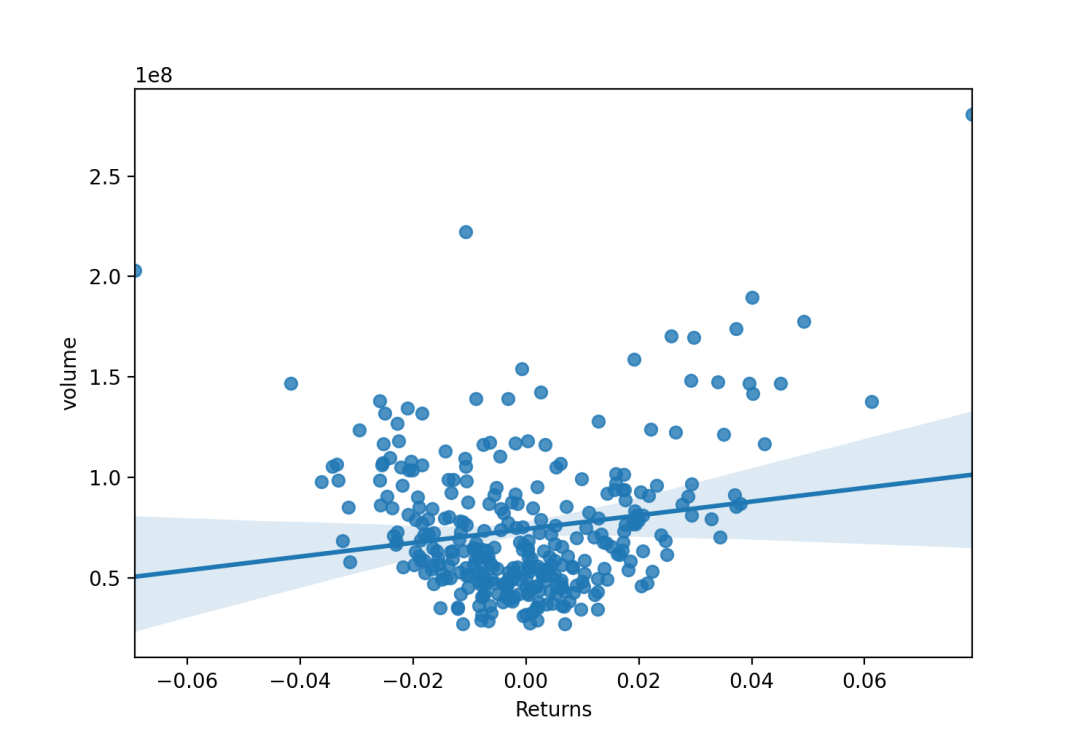
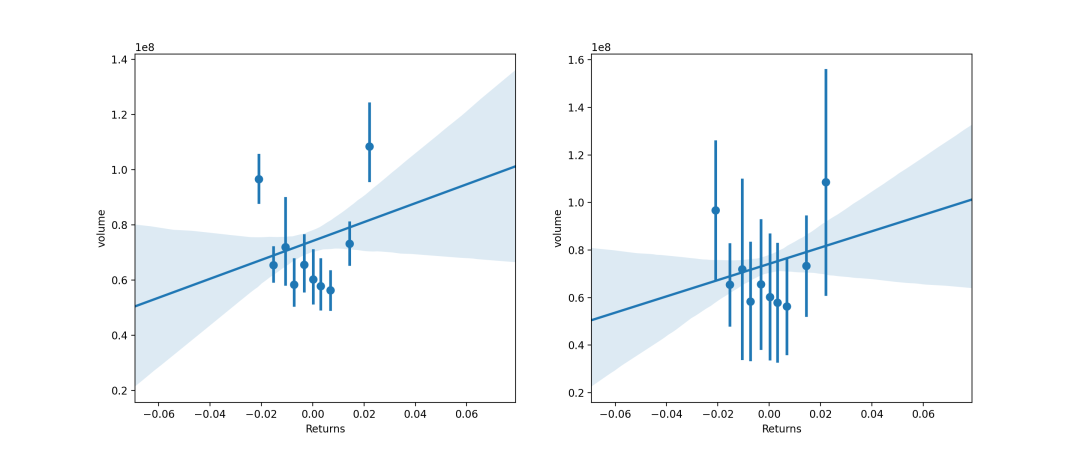
除了可以接受连续型数据,也可接受离散型数据。将连续变量离散化,并在每个独立的数据分组中对观察结果进行折叠,以绘制中心趋势的估计以及置信区间。x_estimatorcallable映射向量->标量,可选 将此函数应用于的每个唯一值,x并绘制得出的估计值。当x是离散变量时,这很有用。如果x_ci给出,该估计将被引导,并得出一个置信区间。x_binsint或vector,可选 将x变量分为离散的bin,然后估计中心趋势和置信区间。这种装箱仅影响散点图的绘制方式;回归仍然适合原始数据。该参数可以解释为均匀大小(不必要间隔)的垃圾箱数或垃圾箱中心的位置。使用此参数时,表示默认x_estimator为numpy.mean。x_ci“ ci”,“ sd”,[0,100]中的int或None,可选 绘制离散值的集中趋势时使用的置信区间的大小x。如果为"ci",则遵循ci参数的值 。如果为”sd”,则跳过引导程序,并在每个箱中显示观测值的标准偏差。
f, ax = plt.subplots(1,2,figsize=(15,6))sns.regplot(x="Returns",y="volume",data=dataset,x_bins=10,x_ci="ci",ax=ax[0])# 带有离散x变量的图,显示了唯一值的方差和置信区间:sns.regplot(x="Returns",y="volume",data=dataset,x_bins=10,x_ci='sd',ax=ax[1])
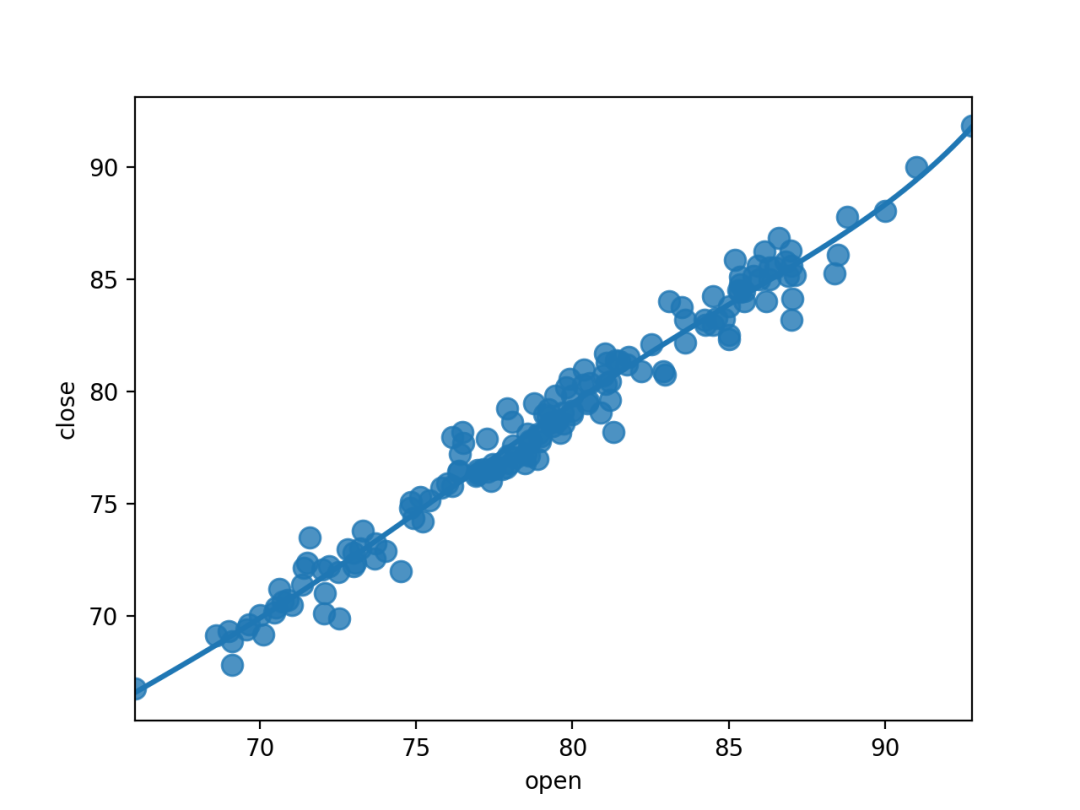
多项式回归
order: int, 可选多项式回归,设定指数
sns.regplot(x="open",y="close",data=dataset.loc[dataset.Up_Down == "Up"],scatter_kws={"s": 80},order=5, ci=None)
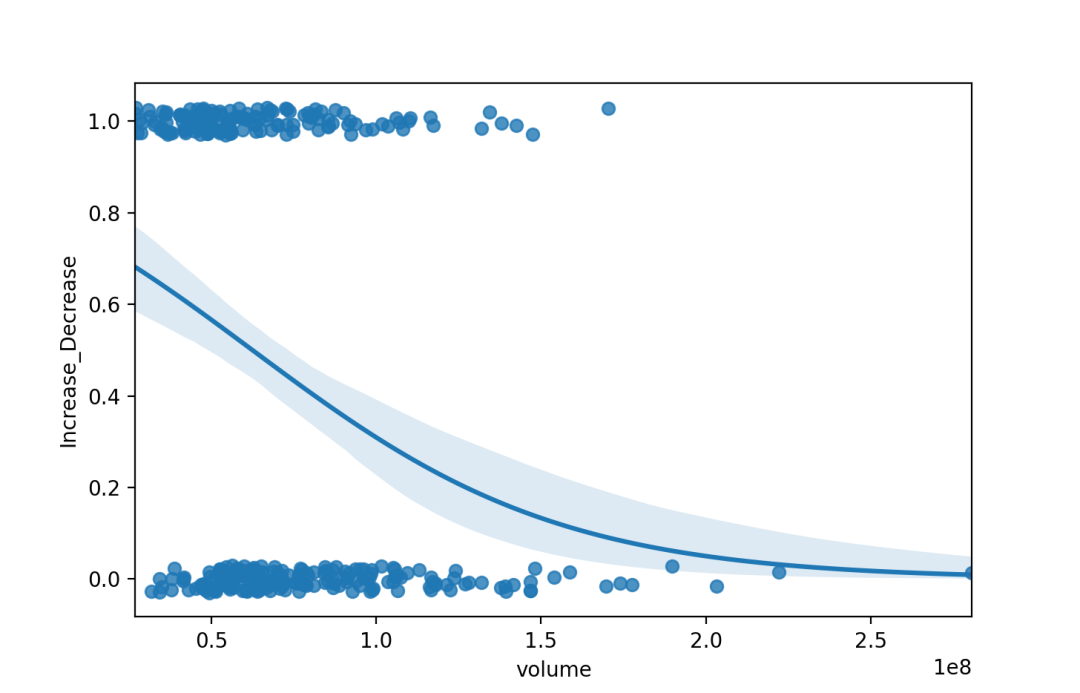
逻辑回归
{x,y}_jitterfloats, 可选将相同大小的均匀随机噪声添加到x或y 变量中。拟合回归后,噪声会添加到数据副本中,并且只会影响散点图的外观。在绘制采用离散值的变量时,这可能会有所帮助。n_bootint, 可选用于估计ci的bootstrap重样本数。默认值试图平衡时间和稳定性。
sns.regplot(x= "volume",y= "Increase_Decrease",data=dataset,logistic=True,n_boot=500,y_jitter=.03,)
对数线性回归
logx bool, 可选如果为True,则估计y ~ log(x)形式的线性回归,但在输入空间中绘制散点图和回归模型。注意x必须是正的,这个才能成立。
sns.regplot(x="open",y="volume",data=dataset.loc[dataset.Up_Down == "Up"],x_estimator=np.mean,logx=True)
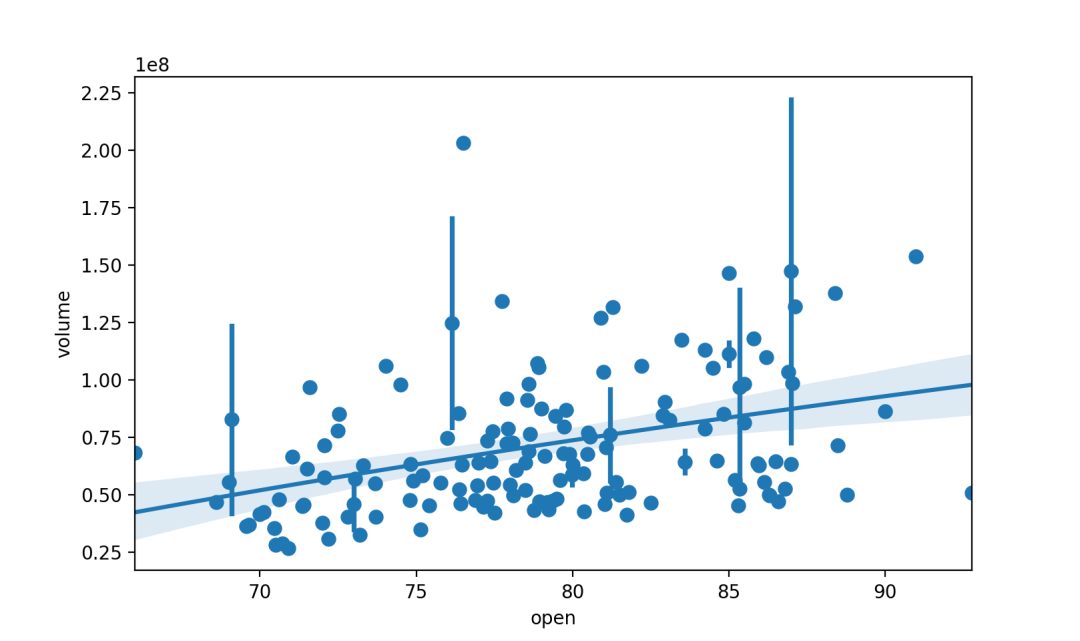
稳健线性回归
robust 布尔值,可选拟合稳健的线性回归。
sns.regplot(x="open",y="Returns",data=dataset.loc[dataset.Up_Down == "Up"],scatter_kws={"s": 80},robust=True, ci=None)
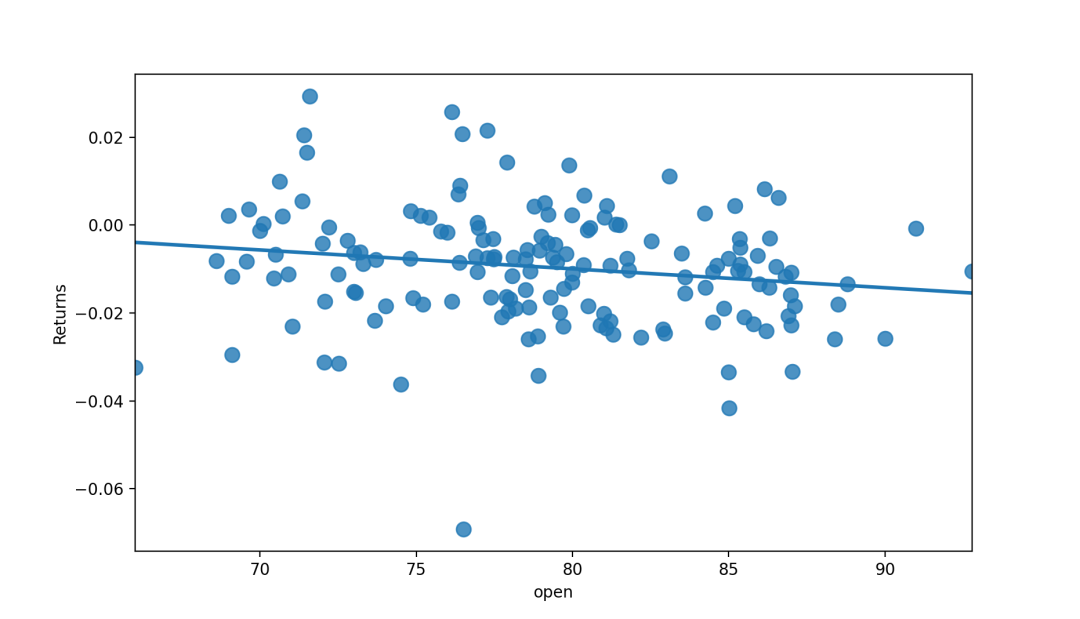
三、线性回归残差图residplot
residplot()用于检查简单的回归模型是否拟合数据集。它拟合并移除一个简单的线性回归,然后绘制每个观察值的残差值。通过观察数据的残差分布是否具有结构性,若有则这意味着当前选择的模型不是很适合。
线性回归的残差
此函数将对x进行y回归(可能作为稳健或多项式回归),然后绘制残差的散点图。可以选择将最低平滑度拟合到残差图,这可以帮助确定残差是否存在结构lowess布尔值,可选在残留散点图上安装最低平滑度的平滑器。
# 拟合线性模型后绘制残差,lowess平滑x=dataset.openy=dataset.Returnssns.residplot(x=x, y=y,lowess=True,color="g")
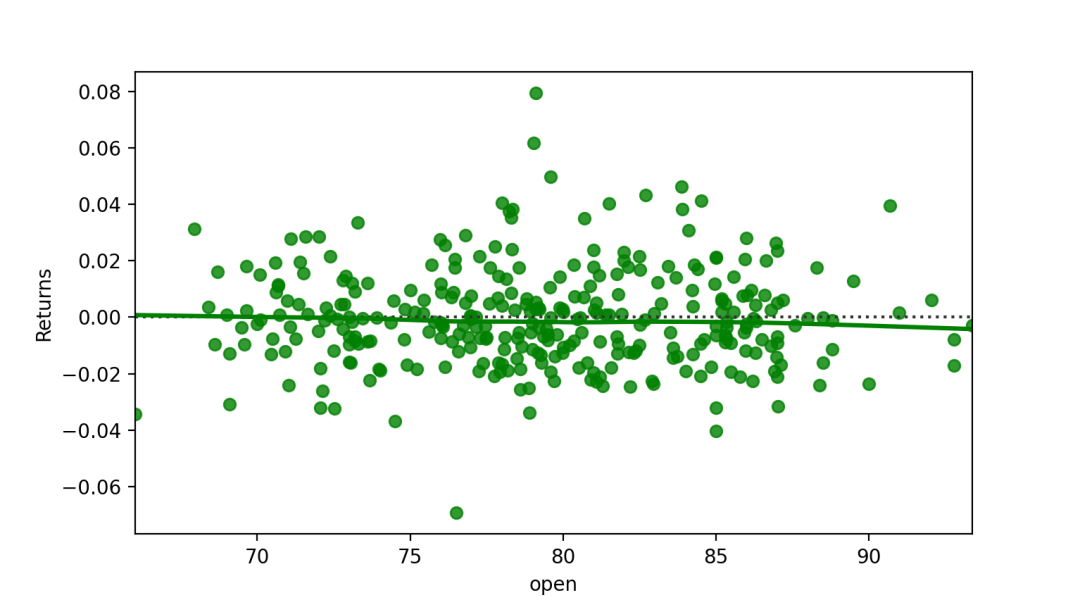
稳健回归残差图
robust bool,可选计算残差时,拟合稳健的线性回归。
sns.residplot(x="open",y="Returns",data=dataset.loc[dataset.Up_Down == "Up"],robust=True,lowess=True)
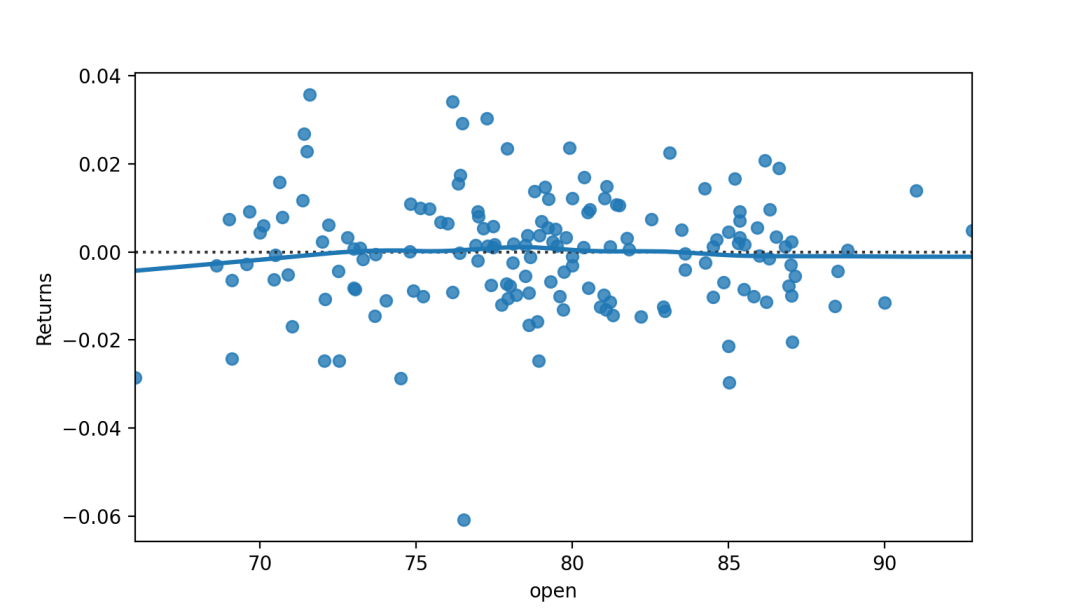
多项式回归残差图
orderint,可选计算残差时要拟合的多项式的阶数。
sns.residplot(x="open",y="close",data=dataset.loc[dataset.Up_Down == "Up"],order=3,lowess=True)
四、其他背景中添加回归
jointplot
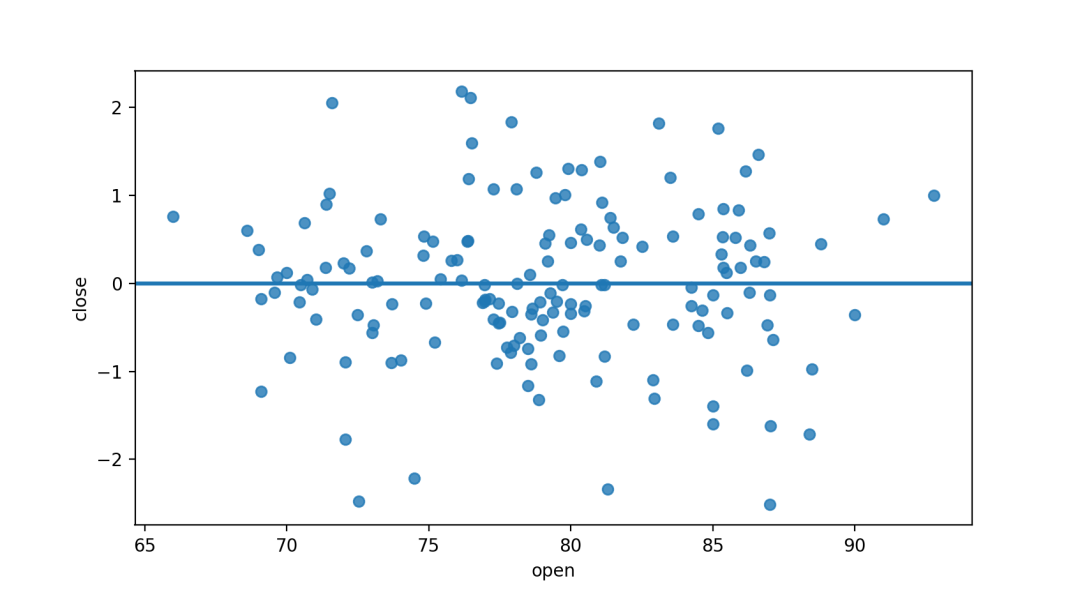
jointplot()函数在其他更大、更复杂的图形背景中使用regplot()。jointplot()可以通过kind="reg"来调用regplot()绘制线性关系。
sns.jointplot("open","Returns",data=dataset,kind='reg')# 设置kind="reg"为添加线性回归拟合#(使用regplot())和单变量KDE曲线
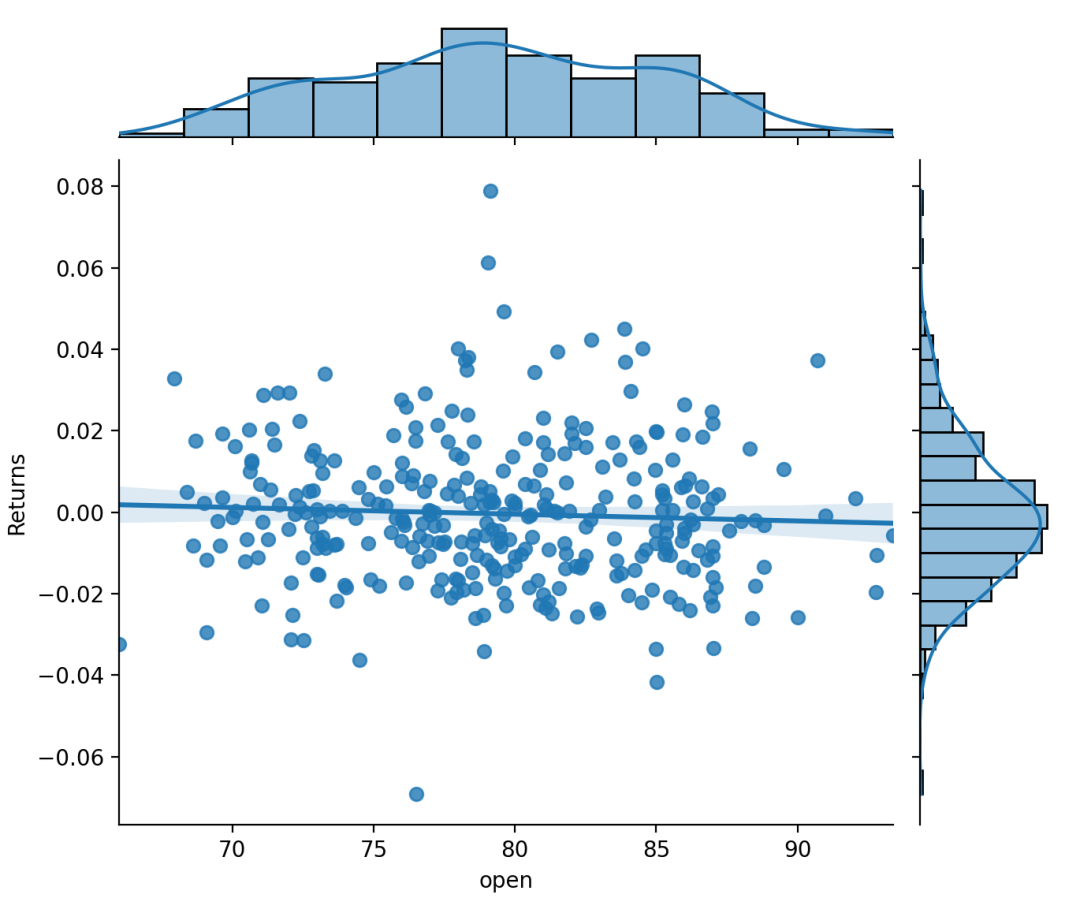
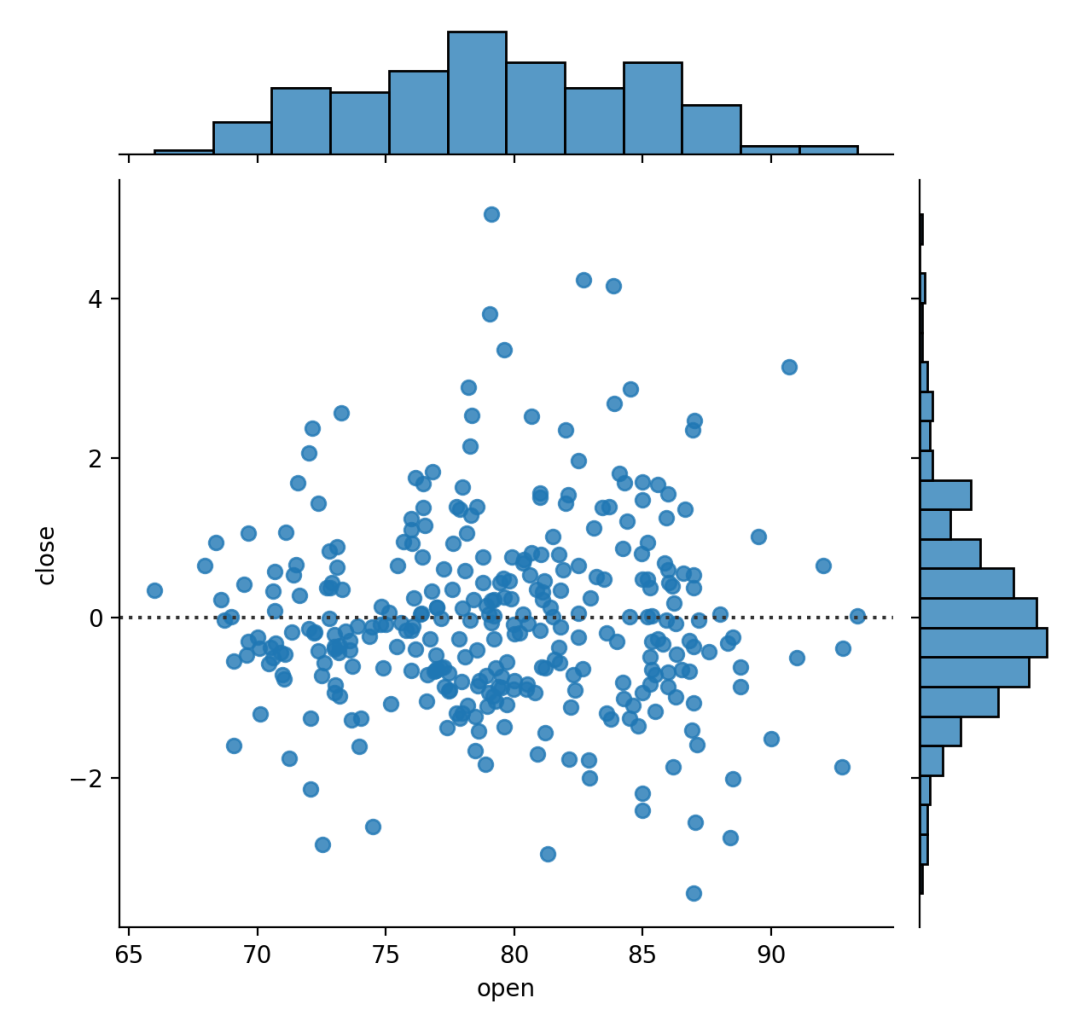
jointplot()可以通过kind="resid"来调用residplot()绘制具有单变量边际分布。sns.jointplot(x="open",y="close",data=dataset,kind="resid")
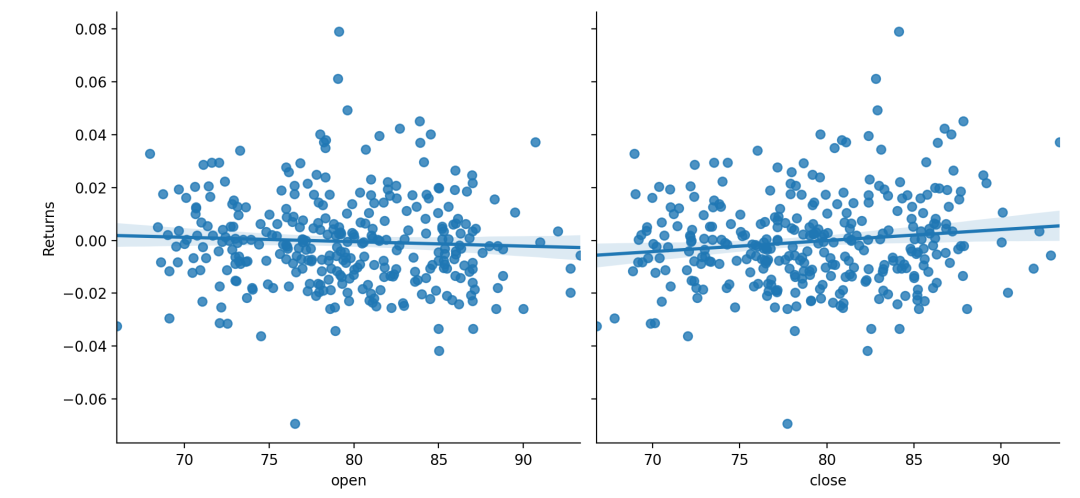
pairplot
给pairplot()传入kind="reg"参数则会融合regplot()与PairGrid来展示变量间的线性关系。注意这里和lmplot()的区别,lmplot()绘制的行(或列)是将一个变量的多个水平(分类、取值)展开,而在这里,PairGrid则是绘制了不同变量之间的线性关系。
sns.pairplot(dataset,x_vars=["open", "close"],y_vars=["Returns"],height=5,aspect=.8,kind="reg");

若有收获,就点个赞吧
0 人点赞
