深度学习
两个问题:
(1)深度学习中batch size的大小对训练过程的影响是什么样的?
(2)有些时候不可避免地要用超大batch,比如人脸识别,可能每个batch要有几万甚至几十万张人脸图像,训练过程中超大batch有什么优缺点,如何尽可能地避免超大batch带来的负面影响?
面试版回答
在不考虑Batch Normalization的情况下,先给个自己当时回答的答案吧(相对来说学究一点):
(1) 不考虑bn的情况下,batch size的大小决定了深度学习训练过程中的完成每个epoch所需的时间和每次迭代(iteration)之间梯度的平滑程度。(batchsize只能说影响完成每个epoch所需要的时间,决定也算不上吧。根本原因还是CPU,GPU算力吧。瓶颈如果在CPU,例如随机数据增强,batch size越大有时候计算的越慢。)
对于一个大小为N的训练集,如果每个epoch中mini-batch的采样方法采用最常规的N个样本每个都采样一次,设mini-batch大小为b,那么每个epoch所需的迭代次数(正向+反向)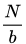 , 因此完成每个epoch所需的时间大致也随着迭代次数的增加而增加。
, 因此完成每个epoch所需的时间大致也随着迭代次数的增加而增加。
由于目前主流深度学习框架处理mini-batch的反向传播时,默认都是先将每个mini-batch中每个instance得到的loss平均化之后再反求梯度,也就是说每次反向传播的梯度是对mini-batch中每个instance的梯度平均之后的结果,所以b的大小决定了相邻迭代之间的梯度平滑程度,b太小,相邻mini-batch间的差异相对过大,那么相邻两次迭代的梯度震荡情况会比较严重,不利于收敛;b越大,相邻mini-batch间的差异相对越小,虽然梯度震荡情况会比较小,一定程度上利于模型收敛,但如果b极端大,相邻mini-batch间的差异过小,相邻两个mini-batch的梯度没有区别了,整个训练过程就是沿着一个方向蹭蹭蹭往下走,很容易陷入到局部最小值出不来。
总结下来:batch size过小,花费时间多,同时梯度震荡严重,不利于收敛;batch size过大,不同batch的梯度方向没有任何变化,容易陷入局部极小值。
(2)(存疑,只是突发奇想)如果硬件资源允许,想要追求训练速度使用超大batch,可以采用一次正向+多次反向的方法,避免模型陷入局部最小值。即使用超大epoch做正向传播,在反向传播的时候,分批次做多次反向转播,比如将一个batch size为64的batch,一次正向传播得到结果,instance级别求loss(先不平均),得到64个loss结果;反向传播的过程中,分四次进行反向传播,每次取16个instance的loss求平均,然后进行反向传播,这样可以做到在节约一定的训练时间,利用起硬件资源的优势的情况下,避免模型训练陷入局部最小值。
通俗版回答
那么可以把第一个问题简化为一个小时候经常玩的游戏:
深度学习训练过程:贴鼻子
训练样本:负责指挥的小朋友们(观察角度各不一样)
模型:负责贴的小朋友
模型衡量指标:最终贴的位置和真实位置之间的距离大小
由于每个小朋友站的位置各不一样,所以他们对鼻子位置的观察也各不一样。(训练样本的差异性),这时候假设小明是负责贴鼻子的小朋友,小朋友A、B、C、D、E是负责指挥的同学(A, B站在图的右边,C,D, E站在左边),这时候小明如果采用:
- 每次随机询问一个同学,那么很容易出现,先询问到了A,A说向左2cm,再问C,C说向右5cm,然后B,B说向左4cm,D说向右3cm,这样每次指挥的差异都比较大,结果调过来调过去,没什么进步。
- 每次随机询问两个同学,每次取询问的意见的平均,比如先问到了(A, C),A说向左2cm,C说向右5cm,那就取个均值,向右1.5cm。然后再问(B, D),这样的话减少了极端情况(前后两次迭代差异巨大)这种情况的发生,能更好更快的完成游戏。
- 每次全问一遍,然后取均值,这样每次移动的方向都是所有人决定的均值,这样的话,最后就是哪边的小朋友多最终结果就被很快的拉向哪边了。(梯度方向不变,限于极小值)
科学版回答
实验环境:1080ti * 1 Pytorch 0.4.1
超参数:SGD(lr = 0.02, momentum=0.5) 偷懒没有根据batch size细调
先创建一个简单的模型:
from torch.nn import *import torch.nn.functional as Fclass SimpleModel(Module):def __init__(self):super(SimpleModel, self).__init__()self.conv1 = Conv2d(in_channels=1, out_channels=10, kernel_size=5)self.conv2 = Conv2d(10, 20, 5)self.conv3 = Conv2d(20, 40, 3)self.mp = MaxPool2d(2)self.fc = Linear(40, 10)def forward(self, x):in_size = x.size(0)x = F.relu(self.mp(self.conv1(x)))x = F.relu(self.mp(self.conv2(x)))x = F.relu(self.mp(self.conv3(x)))x = x.view(in_size, -1)x = self.fc(x)print(x.size())return F.log_softmax(x, dim=1)
然后把MINST加载出来训练一下:
import timeimport torchimport torch.nn as nnimport torch.nn.functional as Fimport torch.optim as optimimport osfrom torchvision import datasets, transformsfrom simple_model import SimpleModelos.environ['CUDA_VISIBLE_DEVICES'] = "0"use_cuda = torch.cuda.is_available()batch_size = 6lr = 1e-2# MNIST Datasettrain_dataset = datasets.MNIST(root='./data/',train=True,transform=transforms.ToTensor(),download=True)test_dataset = datasets.MNIST(root='./data/',train=False,transform=transforms.ToTensor())# Data Loader (Input Pipeline)train_loader = torch.utils.data.DataLoader(dataset=train_dataset,batch_size=batch_size,shuffle=True)test_loader = torch.utils.data.DataLoader(dataset=test_dataset,batch_size=batch_size,shuffle=False)model = SimpleModel()optimizer = optim.SGD(model.parameters(), lr=lr, momentum=0.5)if use_cuda:model = nn.DataParallel(model).cuda()iter_losses = []def train(epoch):model.train()total_loss = 0compution_time = 0e_sp = time.time()for batch_idx, (data, target) in enumerate(train_loader):if use_cuda:data = data.cuda()target = target.cuda()b_sp = time.time()output = model(data)loss = F.nll_loss(output, target)optimizer.zero_grad()loss.backward()optimizer.step()compution_time += time.time() - b_sp# optimizer.step()epoch_time = time.time() - e_spprint('Train Epoch: {} \t Loss: {:.6f}\t epoch time: {:.6f} s\t epoch compution time: {:.6f} s'.format(epoch, total_loss / len(train_loader), epoch_time, compution_time))return total_loss / len(train_loader)model.eval()with torch.no_grad():test_loss = 0correct = 0for data, target in test_loader:if use_cuda:data = data.cuda()target = target.cuda()output = model(data)# sum up batch losstest_loss += F.nll_loss(output, target).item()# get the index of the max log-probabilitypred = output.data.max(1, keepdim=True)[1]correct += pred.eq(target.data.view_as(pred)).cpu().sum()test_loss /= len(test_loader)print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(test_loss, correct, len(test_loader.dataset),100. * correct / len(test_loader.dataset)))return test_loss, 100. * correct.item() / len(test_loader.dataset)if __name__ == "__main__":for epoch in range(1, 10000):train_l = train(epoch)val_l, val_a = test()def test():
迭代速度
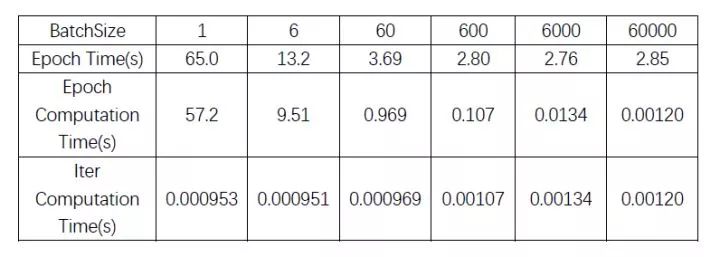
感觉之前做的实验有点不太科学,重新捋了一下思路,把时间计算的代码也放到了前面的代码之中,有兴趣的同学也可以自己做一下看看。
(表中 Epoch Time是在此batch size下完成一个epoch所需的所有时间,包括加载数据和计算的时间,Epoch Computation Time抛去了加载数据所需的时间。)
(时间确实是有偏量,上面的数据可以大体做个参考,要做科学考究的话,还是要多做几次实验求均值减少偏差。)
其实纯粹cuda计算的角度来看,完成每个iter的时间大batch和小batch区别并不大,这可能是因为本次实验中,反向传播的时间消耗要比正向传播大得多,所以batch size的大小对每个iter所需的时间影响不明显,未来将在大一点的数据库和更复杂的模型上做一下实验。(因为反向的过程取决于模型的复杂度,与batchsize的大小关系不大,而正向则同时取决于模型的复杂度和batch size的大小。而本次实验中反向的过程要比正向的过程时间消耗大得多,所以batch size的大小对完成每个iter所需的耗时影响不大。)
完成每个epoch运算的所需的全部时间主要卡在:1. load数据的时间,2. 每个epoch的iter数量。因此对于每个epoch,不管是纯计算时间还是全部时间,大体上还是大batch能够更节约时间一点,但随着batch增大,iter次数减小,完成每个epoch的时间更取决于加载数据所需的时间,此时也不见得大batch能带来多少的速度增益了。
梯度平滑程度
再来看一下不同batch size下的梯度的平滑程度,选取了每个batch size下前1000个iter的loss,来看一下loss的震荡情况,结果如下图所示: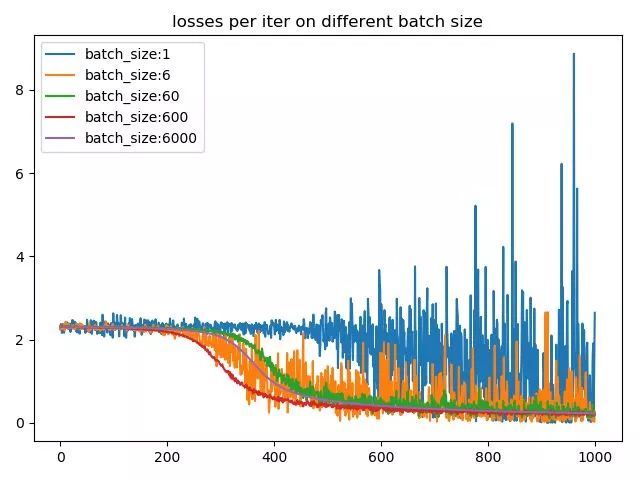
如果感觉这张图不太好看,可以看一下这张图: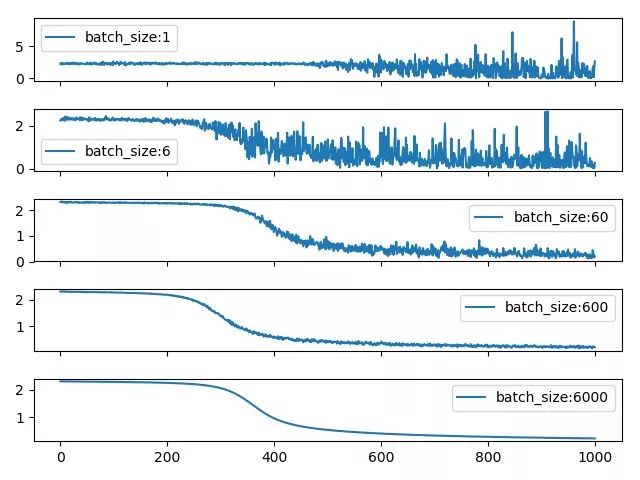
由于现在绝大多数的框架在进行mini-batch的反向传播的时候,默认都是将batch中每个instance的loss平均化之后在进行反向传播,所以相对大一点的batch size能够防止loss震荡的情况发生。从这两张图中可以看出batch size越小,相邻iter之间的loss震荡就越厉害,相应的,反传回去的梯度的变化也就越大,也就越不利于收敛。同时很有意思的一个现象,batch size为1的时候,loss到后期会发生爆炸,这主要是lr=0.02设置太大,所以某个异常值的出现会严重扰动到训练过程。这也是为什么对于较小的batchsize,要设置小lr的原因之一,避免异常值对结果造成的扰巨大扰动。而对于较大的batchsize,要设置大一点的lr的原因则是大batch每次迭代的梯度方向相对固定,大lr可以加速其收敛过程。
收敛速度
在衡量不同batch size的优劣这一点上,选用衡量不同batch size在同样参数下的收敛速度快慢的方法。
下表中可以看出,在minst数据集上,从整体时间消耗上来看(考虑了加载数据所需的时间),同样的参数策略下 (lr = 0.02, momentum=0.5 ),要模型收敛到accuracy在98左右,batchsize在 6 - 60 这个量级能够花费最少的时间,而batchsize为1的时候,收敛不到98;batchsize过大的时候,因为模型收敛快慢取决于梯度方向和更新次数,所以大batch尽管梯度方向更为稳定,但要达到98的accuracy所需的更新次数并没有量级上的减少,所以也就需要花费更多的时间,当然这种情况下可以配合一些调参策略比如warmup LR,衰减LR等等之类的在一定程度上进行解决,但也不会有本质上的改善。
不过单纯从计算时间上来看,大batch还是可以很明显地节约所需的计算时间的,原因前面讲过了,主要因为本次实验中纯计算时间中,反向占的时间比重远大于正向。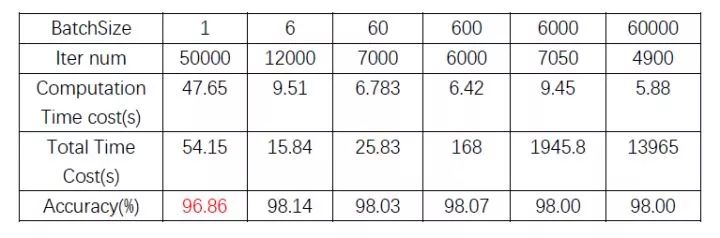
(一直觉得直接比较不同batch size下的绝对收敛精度来衡量batch size的好坏是没有太大意义的,因为不同的batch size要配合不同的调参策略用才能达到其最佳效果,而要想在每个batch size下都找到合适的调参策略那可太难了,所以用这种方法来决定batch size未免有点武断。)
一次正向,多次反向
这部分在pytorch上进行了实验,但发现pytorch在backward中加入retain_graph进行多次反向传播的时候,时间消耗特别大,所以尽管采用一次正向,多次反向的方法,减少了超大batch size收敛到98的accuracy所需的iteration,但由于每个iteration时间消耗增加,所以并没有带来时间节省,后续还要探究一下原因,再重新做一下实验,然后再贴结果,给结论。
做了几次实验,基本失败,一个大batch分成10份反向传播,基本等同于lr放大10倍。大batch还是要配合着更复杂的lr策略来做,比如warmup,循环lr,lr衰减等等。
实验的漏洞
为了保证独立变量,在实验中不同batch设置了同样的lr,然后比较收敛速度,这样是不公平的,毕竟大batch还是要配合更大的初始lr,所以后续还要做一下实验,固定每个batch size, 看lr的变化对不同batch size收敛素的的影响。

若有收获,就点个赞吧
0 人点赞
